破解梵蒂冈秘密档案,这个AI认识中世纪手写拉丁文
伊瓢 发自 凹非寺
量子位 报道 | 公众号 QbitAI
用AI识别文字并不是什么难事。
但如果文字是手写的呢?如果文字是古文呢?
这听起来就有点难度了。有一个叫 In Codice Ratio 的项目正在尝试把梵蒂冈秘密档案转录为可供查询的电子版。
梵蒂冈秘密档案:古欧洲八卦集散中心
梵蒂冈秘密档案是罗马教廷的代代教皇们留下的历史卷宗,收藏在梵蒂冈城内专门的档案馆里。由于记录了超过12个世纪的信息,收藏梵蒂冈秘密档案的书架排成一排大概有53英里长,可以说信息量巨大了。

这些档案里记录了不少八卦。比如档案里收录了一封英国贵族们在1530年写给教皇克莱门特七世的信,要求教皇让英格兰国王亨利八世和一直没有生出儿子的凯瑟琳王后的离婚。

还有一些政界的故事。档案中有一封成吉思汗的孙子贵由大汗给教皇英诺森四世的回信。教皇希望教廷与元朝平等相处,贵由大汗却一脸懵逼:你是在搞笑么?快带着你们欧洲的国王们来臣服我们,不然会挨打哦。

另外档案中还有一些科技文艺界人物与教廷的通信,伏尔泰、莫扎特都给教廷写过信,甚至米开朗基罗还给教廷写信,要求尽快支付自己被拖欠了三个月的工资。
梵蒂冈秘密档案记录了如此多历史轶事,但这些内容对普通人甚至学者都是不可企及的。教廷的一般规矩是在75年后公开档案,但是这长达53英里的书架上的档案中,只有几毫米厚的文档被扫描为电子版,而其中转录成文字格式的少之又少。符合条件的学者如果需要查询档案,需要亲自跑到梵蒂冈,办好手续后在53英里的档案中一页一页的翻。

如此麻烦的查阅方式让档案的价值难以被挖掘。所以,In Codice Ratio项目组决定用AI+OCR(Optical Character Recognition,光学字符识别)技术转录这53英里的梵蒂冈秘密档案。
拼图分割法:让OCR识别连体字
用OCR来识别文字并不是什么新鲜技术,识别英文等字母文字的时候,OCR技术把有一定间距的符号识别为一个个的字母,再依据其形状判断是哪个字母,然后把字母转录为ASCII码,所以文档就变成了方便搜索查阅的电子版。
OCR虽然可以方便的识别印刷文字,但对于梵蒂冈秘密档案这类手写文字却无能为力。比如下面这一段13世纪早期、用卡罗琳小写体撰写的文字:

由于传统OCR技术是把单词分割成一个个字母来识别的,所以对于这类连体字,OCR无法识别字母。有人想出了一个方案,直接让OCR去识别一个个的单词,但是,如何让OCR掌握成千上万的拉丁文单词呢?大概需要一个排的中世纪拉丁文专家来辨认不同单词的图形。
除了请专家辨认单词外,还有更简单的方法帮助OCR识别手写字母,只要找实习生就可以搞定了。
我们知道,无论中文还是英文,连体字中粗的部分是笔画,细的部分是笔尖移动造成的虚线,并不是笔画的一部分。根据这个原则,In Codice Ratio的专家们发明了新的方法——拼图分割法。拼图分割法改变了传统OCR把单词分成字母的传统方式,而是是把连在一起的单词按照笔画分隔开,系统根据笔画来判断是哪个字母,比如这样:

之后,就要让识别系统判断对错:识别出的字母,哪些是真正的字母,哪些是虚线的误判。
这个工作交给高中生做都可以。于是,In Codice Ratio项目组找了一些高中生,根据高中生们对手写体的判断,教给识别系统哪些字母是对的,哪些字母认错了。
比如字母g。下面图中,绿色部分是正确的手写字母g,而红色部分是识别系统错判的字母g,学生们从最下方的选项中选出正确的字母g,投喂给识别系统,从而教会系统什么是真正的字母g。22个中世纪拉丁文字母都学会之后,这个识别系统就成为了一个能认识手写体中世纪拉丁文的AI。
clear or dear?
现在的AI版OCR终于能像人类一样识别连体字了。但是,别忘了总有一些字连人类自己都认不出来。
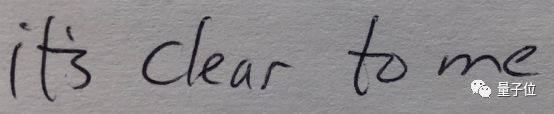
这张图上写的是“it’s clear to me”还是“it’s dear to me”呢?由于字母d和字母cl的笔画完全一样,OCR和人类都难以分清。而在中世纪拉丁文中,这种状况更为普遍。
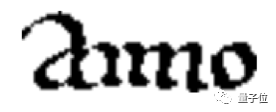
看这个词,第一个字母是a,最后一个字母是o,但中间的字母难以辨认。所以,这个单词是aimo、amio、aniio、ainio、aiino还是aiiiio?
都不是,正确答案是anno,拉丁文中表示“年”的单词。和人类一样,拼图分割AI识别出了a和o,但是难以判断中间的四条竖线是什么字母。
为了解决这个问题,In Codice Ratio 团队找了包含150万个拉丁文单词的电子文档,分析了里面的字母组合,借以教给OCR一些拼写常识——比如拉丁文中是没有iiii这种字母组合的,nn更为常见。
准确率高达96%
经过这样的技术改进之后,拥有AI能力的OCR终于可以开始阅读梵蒂冈秘密档案了。In Codice Ratio 团队让OCR转录了18000页档案。不过,转录结果不是特别成功,大约三分之一的文本中出现了错误,这让正常人难以阅读。
不过,对于其中字母的识别,这套OCR系统准确率高达96%,并且用到的技术方法完全可以拿来识别除拉丁文之外的其他文献。经过对AI更专业的训练后,它可以识别各大文明的古代文献并电子化。
所以,为了给AI提升难度,青铜铭文了解一下?

— 完 —
加入社群
量子位AI社群16群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot6入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot6,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态




