腾讯云自主可控数据库TDSQL的架构演进
在数字化时代,作为基础软件,数据库的自主可控对于企业的数据安全、业务稳定具有重要意义。只有实现“自主可控”才能从根本上保证信息安全,尤其是涉及重大安全的政府和金融领域,对数据安全的要求进一步加强。因此,在互联网安全上升至国家战略层面的背景下,如何在底层基础数据库层面实现自主可控成为云计算厂商不断追求的目标。
基于微信支付 / 红包的复杂业务场景,腾讯一直致力于实现数据库的自主可控,保证数据强一致性、高可用和水平扩展。实际上,腾讯推出的 TDSQL(TencentDistributed SQL) 金融级分布式数据库,在对内支撑微信红包业务的同时,对外也正在为中国金融行业技术自主可控分布式数据库解决方案
作为国内首家互联网银行,微众银行背后的 IT 基础架构抛弃了传统的 IOE,完全采用了互联网分布式架构。从 2014 年开始,腾讯云开始为微众银行提供核心交易数据库解决方案。TDSQL 在微众银行作为交易核心 DB,部署超过 800 个节点,承载全行所有 OLTP 业务。由于完全采用互联网架构,相比传统的 IOE 方案,微众银行在 IT 成本上大幅节约。同时,互联网架构的高伸缩性,使得微众银行的服务能力具备很高的弹性,足以轻松应对普惠金融场景下的潮涌。
“2017 年微众银行将每个账户的运营成本降至平均只有 6 元人民币,仅为内地传统银行的 1/10,相比国际银行则更低,只有其成本的 2% 至 5%。” 微众银行副行长兼 CIO 马智涛说。
目前 TDSQL 已正式通过腾讯金融云对外输出金融级分布式数据库产品服务,除了微众银行,腾讯分布式数据库 TDSQL 还支撑着华通银行、华夏银行、潍坊银行、内蒙金谷农商银行、北京人寿、爱心人寿等众多银行和保险公司的互联网核心生产系统。并已经为超过 500+ 的政企和金融机构提供数据库的公有云及私有云服务,客户覆盖银行、保险、证券、互联网金融、计费、第三方支付、物联网、互联网 +、政务等领域,得到了客户及行业的一致认可。
那么在市场业务环境变化的场景下,TDSQL 是如何实现自主可控和技术迭代的呢?下面我们从 TDSQL 的架构演进来具体分析。
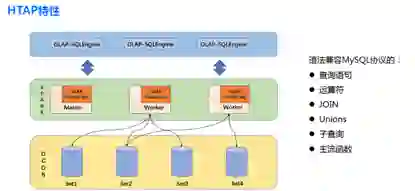
从架构上讲,TDSQL 是 Shared-Nothing 架构的分布式数据库;从部署方式来讲,TDSQL 是一款支持多租户的云数据库;从能力上讲,TDSQL 比当前流行 HTAP 更进一步,它重新定义了一种综合型的数据库解决方案,也可以分配 Noshard 实例、分布式实例和分析性实例,同时支持 JSON/RockDB 等方案。当然,TDSQL 最主要的特点在于其具备 shard 架构能力。
在 2004 年,腾讯充值、财付通等业务爆发发展,但那时腾讯和所有的创业公司有个共同点—“穷”,在这样的背景下,TDSQL 逐步诞生了,所以腾讯金融类业务从一开始就没有 IOE。
因为期间经历了业务层对拆分的滥用,主从数据不一致导致的数据准确性问题,以及上百台设备集群的管理问题等。
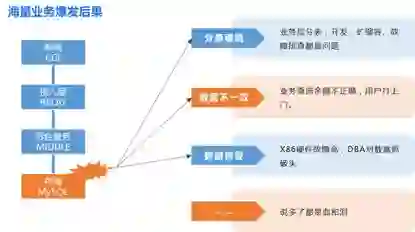
所以,从 08 年开始,团队决定重构 TDSQL 解决方案,针对金融类业务的特点,列出以下几个要点:
数据强一致的要求
数据库集群的可用性、稳定性和容灾要求要达到银行标准
业务无需拆分超大表,数据库自动拆分
接入要简单,老业务改造要小,必须兼容 MySQL 协议
符合并高于金融行业信息安全监管要求
整体来说,TDSQL 是由决策调度集群 /GTM,SQLEngine、数据存储层等核心组件组成的,其每个模块都基于分布式架构设计,可以实现快速扩展,无缝切换,实时故障恢复等,通过这一架构,TDSQL 的 Noshard、Shard、TDSpark 实例可以混合部署在同一集群中。并且使用简单的 x86 服务器,可以搭建出类似于小型机、共享存储等一样稳定可靠的数据库。
在架构上,TDSQL 的核心思想只有两个:数据的复制(replica)和分片(sharding),其它都是由此衍生出来的。其中,
replica 配合故障的检测和切换,解决可用性问题;
sharding 配合集群资源调度、访问路由管理等,解决容量伸缩问题。
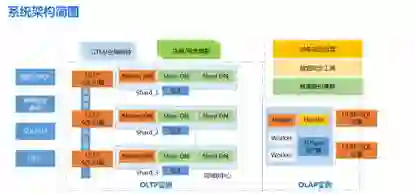
同时,因 replica 引入了数据多副本间的一致性问题和整体吞吐量下降的问题,而 sharding 的引入也会带来一定的功能约束。在最终实现上,TDSQL 由 Scheduler、Gateway、Agent 三个核心组件加上 MySQL 组成,其中:
Scheduler 是管理调度器,内部又分为 zookeeper 和 scheduler server;
Gateway为接入网关,多个网关组成一个接入层;
Agent 是执行代理,与 MySQL 实例一起,构成数据节点。多个数据节点构成服务单元 SET。
相比单机版的 MySQL,TDSQL 的优势主要体现在集群维度,包括容灾、高一致性、高弹性等。
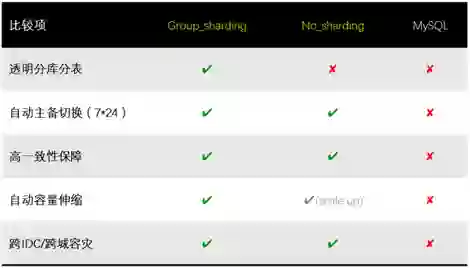
注:✔ 支持,✘不支持, ○不适用
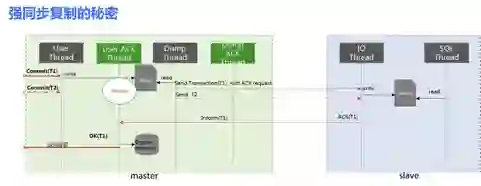
在金融行业,银行、风控、渠道等第三方通常通过读写分离方式来查询数据,而在互联网行业,由于 x86 相对较高的故障率,导致数据可能经常性的出现错乱、丢失场景。为了解决这个问题,就必须要求主从数据的强一致和良好的读写分离策略。其关键在于,如何实现强同步复制技术。
由于 MySQL 的半同步和 Galera 模式不仅对性能的损耗是非常大的,而且数据同步有大量毛刺,这给金融业务同城双中心或两地三中心架构容灾架构带来了极大的挑战。
为什么会这样呢?从 1996 年的 MySQL3.1.1.1 版本开始,业务数据库通常跑在内网,网络环境基本较好,因此 MySQL 采用的是每个连接一个线程的模型,这套模型最大的好处就是开发特别简单,线程内部都是同步调用,只要不访问外部接口,支撑每秒几百上千的请求量也基本够用,因为大部分情况下 IO 是瓶颈。
但随着当前硬件的发展,尤其是 ssd 等硬件出现,IO 基本上不再是瓶颈,如再采用这套模型,并采用阻塞的方式调用延迟较大的外部接口,则 CPU 都会阻塞在网络应答上了,性能自然上不去。
因此,TDSQL 引入线程池,将数据库线程池模型 (执行 SQL 的逻辑) 针对不同网络环境进行优化,并支持组提交方案。例如,在 binlog 复制方案上,我们将复制线程分解:
1、任务执行到写 binlog 为止,然后将会话保存到 session 中,接着执行下一轮循环去处理其它请求了,这样就避免让线程阻塞等待应答
2、MySQL 自身负责主备同步的 dump 线程会将 binlog 立即发送出去,备机的 io 线程收到 binlog 并写入到 relaylog 之后,再通过 udp 给主机一个应答
3、在主机上,开一组线程来处理应答,收到应答之后找到对应的会话,执行下半部分的 commit,send 应答,绑定到 epoll 等操作。绑定到 epoll 之后这个连接又可以被其它线程检测到并执行。
改造后,使得 TDSQL 可以应对复杂的网络模型。当然,深入了解过 MySQL 同步机制的朋友可能会发现上述方案还有小缺陷:当主机故障,binlog 没有来得及发送到远端,虽然此时不会返回给业务成功,备机上不存在这笔数据,然而在主机故障自愈后,主机会多出来这笔事务的数据。解决方法是对新增的事务根据 row 格式的 binlog 做闪回,这样就有效解决了数据强一致的问题。
2018 年初,英特尔技术团队使用 sysbench 测试方案,在跨机房、相同机型、网络和参数配置和高并发下测试,TDSQL 强同步复制平均性能是 MySQL5.7 异步复制的 1.2 倍。
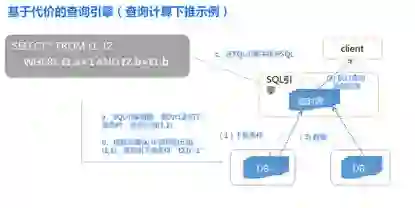
当前大多数分布式数据库都设计的是基于规则的查询引擎 (RBO),这意味着,它有着一套严格的使用规则,只要你按照它去写 SQL 语句,无论数据表中的内容怎样,也不会影响到你的“执行计划”,但这意味着该规则复杂的数据计算需求不“敏感”。虽然金融业务都有自己的数据仓库,然而也会经常需要在 OLTP 类业务中执行事务、JOIN 甚至批处理。
TDSQL 在 SQLENGINE 实现了基于代价的查询引擎 (CBO),SQL 经过 SQLENGINE 的词法,语法解析,语义分析和 SQL 优化之后,会生成分布式的查询计划,并根据数据路由策略(基于代价的查询引擎)进行下推计算,最后对汇总的数据返回给前端。
而作为分布式的计算引擎,在存储与计算引擎相分离的情况下,非常重要的一环就是如何将计算尽量下推的下面的数据存储层。因此 TDSQL 的 SQLENGINE 在经过大量业务打磨后,实现了基于 shard key 下推,索引条件下推,驱动表结果下推,null 下推,子查询下推, left join 转化成 inner join 等多达 18 种下推优化手段,尽量降低数据在多个节点传输带来的压力,以提供更好的分布式查询的能力,支撑金融交易的关联操作。
金融行业对事务处理的需求极高,转账、扣费,无一不是使用事务,而腾讯是少数几个将分布式事务处理,分布式 JOIN 用于金融核心系统的企业。
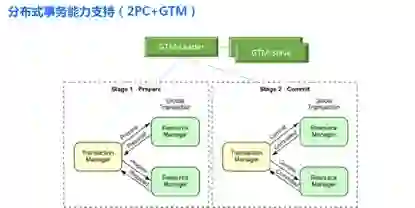
TDSQL 仍然是通过经典的 XA 两阶段提交加两阶段封锁协议实现了强分布式事务的语义,以支撑金融场景对事务管理的需求。在使用语法上与 MySQL 完全一样,即后端的分布式事务处理对业务使用方是完全不感知,以保证兼容性。
在二阶段提交实现上,在 begin 的时候从 GTM 获取全局递增的事务 ID,然后在参与事务的各个子节点通过这个事务 ID 开启事务,进行各种 DML 操作,提交的时候先对各个子节点执行 prepare。当 prepare 成功之后,再更新全局事务 ID 的事务状态,同时获取到一个新的事务 ID 作为提交的事务 ID 对各个子事务进行异步并行化的提交,提供更好的事务操作性能。
当前 GTM 以一主两从的方式运行,主从节点底层通过 raft 协议进行数据的同步以及主从切换,内部交互以及对外通讯均基于 grpc 协议。当前 TDSQL 的 GTM 组件性能完全可以满足金融业务需求:
全局时间戳:≈180w - 190w TPS,8 Clients,主节点 CPU 跑满情况下(24core),内存消耗约 23GB;
递增序列号:≈750w - 780w TPS,8 Clients,10 万个 key,主节点 CPU 跑满情况下 ,内存 消耗约 30GB;
从节点资源消耗:因为所有请求均由 Leader 节点完成响应,从只负责接受来自于 主节点的 raft 数据同步请求,并且 从节点上不缓存任何数据,因此 CPU 和 内存消耗都在极低的程度;因此,一般场景下,通常 GTM 与调度决策集群可以混合部署,极大的节省了物理设备成本。
TDSQL 除了提供计算下推,分布式事务等特性,也针对 OLAP 需求演进了 TDSpark 特性。简单来说,是将 SQLEngine 基于 OLAP 场景做了修改,保留原生的 MySQL 协议接入能力。因此业务继续可以通过访问 MySQL 的渠道接入到 OLAP-SQLEngine,OLAP-SQLEngine 在这个时候不是将分布式的查询计划直接下推到各个数据库节点,而是引入一个中间层,目前是采用 SPARKSQL, 通过 SPARKSQL 强大的计算能力能显著提升复杂 SQL 的执行性能。另外为了确保分析操作与在线的 OLTP 业务隔离,我们 TDSQL 的数据层为每份数据增加 1 个 watch 主数据库的数据异步节点,确保分析操作与在线业务操作不互相影响。
数据安全和容灾是金融类业务的命脉,而 TDSQL 现已经应用在多个银行、保险的公有云或私有云环境。符合国家等级保护信息安全要求,通过银保监会相关审核,获得了包括 ISO,SOC 等国内和国际标准。
而在容灾能力方面,TDSQL 可以支持:
同城数据强一致下的双活:当前腾讯公有云和金融云有大量的客户都选择了类似方案。
主从读写分离的异地多活:该方案适用于应用完全不做任何改造,就可以实现跨城多活的能力。当前 TDSQL 很多客户不想对业务改造,但是又想具备跨城多活和切换的能力,通常选择这个方案。
多主的异地多活架构,并支持双向同步:通过应用层根据用户维度做了区分之后,可以使得多套 TDSQL 数据库分别承载不同的业务进行读写事务访问,实现完全的多活能力,但是如果业务系统无法保证调度安全和数据的区分,可能存在数据异常的风险。
多主的异地多活架构,多套主从架构:综合了前面两种架构,实现了完全的异地多活 + 读写分离的能力,并且即使业务层路由错误,也不会引起数据异常。当然,对应的应用层也要能配合修改。
当然越高要求对部署的要求约复杂,目前公有云已经提供了前面两种方案可供大家试用。
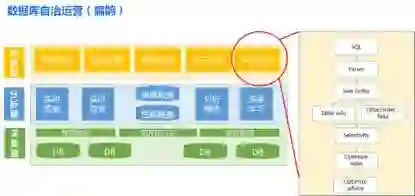
为了保证系统的运行做到一切尽在掌控之中,TDSQL 不仅有完善的管控系统(赤兔)来完成系统的自动化管理,从可用性、安全、效率、成本维度进行全方位管控。还在赤兔中引入了“数据库自治运营”的理念,构建了一套能自我学习的智能检测平台(简称扁鹊)
以 SQL 优化为例,该系统能自动抽象出当前效率最差的若干 SQL,并将这些通过解析 SQL 生成 AST 语法树,分析语法树中表的连接方式和连接字段,然后遍历语法树中的过滤,排序等关键字段,再次分析各字段的区分度,对于区分度较高的字段会提供推荐优化方案,综合字段区分度,过滤规则,表连接顺序等多个因素推提供优化建议。
TDSQL 的自治运营的最终目标是利用公有云庞大的环境进行自我学习和自我进化,做到无需人工干预即可进行更新、调整和修复,从而解放人力、减少人为差错,帮助企业节约管理及经济成本、降低风险。
金融业务涉及国计民生的重点业务,一个小小的 BUG,一个操作失误,就可能影响到数以万计的百姓资产准确性。正因为这样的责任,腾讯云 TDSQL 团队始终坚守则“本心”。
目前,TDSQL 已在北京、深圳、成都三地建立研发团队,并通过 CMMI3 认证,同时在开源社区拥有自己的开源分支。值得一提的是 TDSQL 已获得包括 ISO27001、ISO22301、PCI DSS、SOC 审计,工信部分布式数据库测试,IT168 技术突破大奖,多项国家或国际认证和行业殊荣。并与包括中国人民大学,中国银行等开展产研结合、产用结合,并取得诸多创新成绩。
展望 2019 年,TDSQL 将持续通过产研结合、产用结合的方式进行研发突破,并开放商用更多特性,拥抱开源社区。




