用基于 TensorFlow 的强化学习在 Doom 中训练 Agent

本文原标题 Reinforcement learning with TensorFlow,作者为 Justin Francis,全文由雷锋字幕组编译。原文链接:http://t.cn/RQfsmzE
深度强化学习(或者增强学习)是一个很难掌握的一个领域。在众多各式各样缩写名词和学习模型中,我们始终还是很难找到最好的解决强化学习问题的方法。强化学习理论并不是最近才出现的。实际上,一部分强化学习理论可以追溯到 1950 年代中期(http://t.cn/RQIvvDn )。如果你是强化学习的纯新手,我建议你先看看我前面的文章《介绍强化学习和 OpenAI Gym》(http://t.cn/RK97gKa )来学习强化学习的基础知识。
深度强化学习需要更新大量梯度。有些深度学习的工具 ,比如 TensorFlow(https://www.tensorflow.org/ ) 在计算这些梯度的时候格外有用。 深度强化学习也需要可视化状态来表现得更抽象,在这方面,卷积神经网络表现最好。在这篇雷锋网译文中, 我们将会用到 Python, TensorFlow 和强化学习库 Gym(https://github.com/openai/gym ) 来解决 3D 游戏 Doom 里医药包收集的环境,想获得全部版本的代码和需要安装的依赖,请访问我们的 GitHub (http://t.cn/RQIvaN8 )和这篇文章的 Jupyter Notebook(http://t.cn/RQIvaN8 )。
翻译 / 林立宏 文加图
校对 / Julia
整理 / 凡江
环境探测
在这个环境中,玩家将扮演一个站在强腐蚀性水中的人,需要找到一条收集医药包并且安全离开的道路。
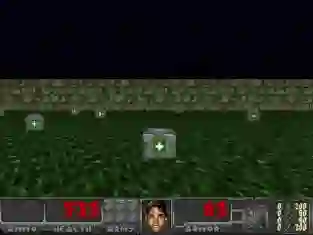
图 1. 环境, Justin Francis 提供
我们能够解决这个问题的一种强化学习方法是——结合基准算法的强化学习。这种强化会简单点,它仅仅需要来自当前环境行为下的状态和奖励数据。强化也被称为一种策略梯度方法,因为它仅仅评估和更新了智能体的策略。策略是当前状态下智能体会表现出的行为。 例如,在游戏 pong(类似于打乒乓球)中, 一个简单的策略是: 如果这个球以一定的角度移动,那么最好的行为是对应这个角度移动挡板。除了用卷积神经网络来评估给定状态下的最好的策略,我们也用到相同的网络根据给定状态来评估价值或者预测长期的奖励 。
首先,我们会用 Gym 定义我们的环境

在让 Agent 学习之前,我们看这个是观察一个随机挑选的 Agent 的基准,很明显我们还有很多需要学习的地方。
图 2. 随机代理, Justin Francis 提供
设置我们的学习环境
强化学习被认为是学习中的蒙特卡洛方法,这意味着这个 Agent 将会在整个行为过程中收集数据并且在行为结束后开始计算。在我们的例子中,我们将会收集多种行为来训练它。我们将会把我们的环境训练数据初始化为空,然后逐步添加我们的训练数据。

接下来我们定义一些训练我们的神经网络过程中将会用到的超参数。

Alpha 是我们的学习率, gamma 是奖励折扣率。奖励折扣是在给定智能体奖励历史的情况下评估未来可能的奖励的一种方法。如果奖励折扣率趋向于 0,那么 Agent 只需要关注当前的奖励而不需要去考虑未来的奖励。我们可以写一个简单的函数来评估某个行为下的一系列奖励,下面是代码:
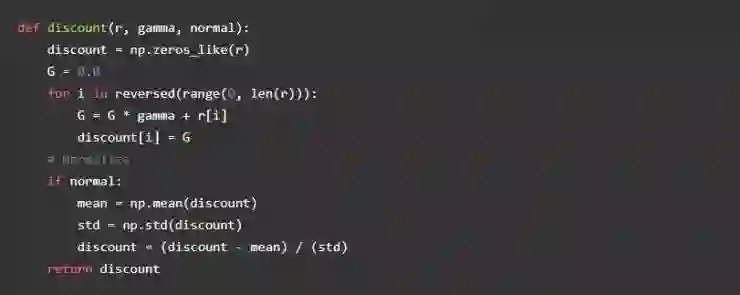
计算奖励:
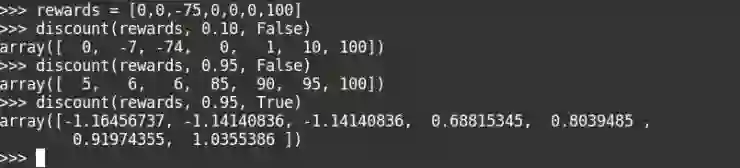
你可以看到这些高折扣率的,由于后面有大的奖励,中间的大的负奖励就被忽视了。我们还可以给我们的折扣奖励添加正规化,来确保我们的奖励范围保持在一定范围内。这在解决 doom 环境中非常重要的。
给定状态下我们的价值函数会一直将不断地试图接近折扣奖励。
建立卷积神经网络
下一步,我们将建立卷积神经网络来接收状态,然后输出对应动作的可能性和状态值。我们会有三个可以选择的动作:向前、后左和向右。这个近似策略的设置和图像分类器是一样的,但是不同的是输入代表的是一个类的置信度,我们输出会表示一个特定动作的置信度。对比于大的图像分类模型,使用了增强学习,简单的神经网络会更好。
我们会使用 convnet ,和之前使用的著名 DQN 算法是类似的,我们的神经网络会输入一个压缩大小为 84X84 像素的图像,输出一个 16 卷积 4 跨度的 8X8 内核,跟随 32 个卷积 4 跨度的 8X8 内核,以一个完全连接的 256 层级的神经元结束。对于卷积层,我们会使用 VALID 填充,会极大缩小图像的大小。
我们的近似策略和我们的值策略,都会使用同样的卷积神经元网络去计算他们的值。
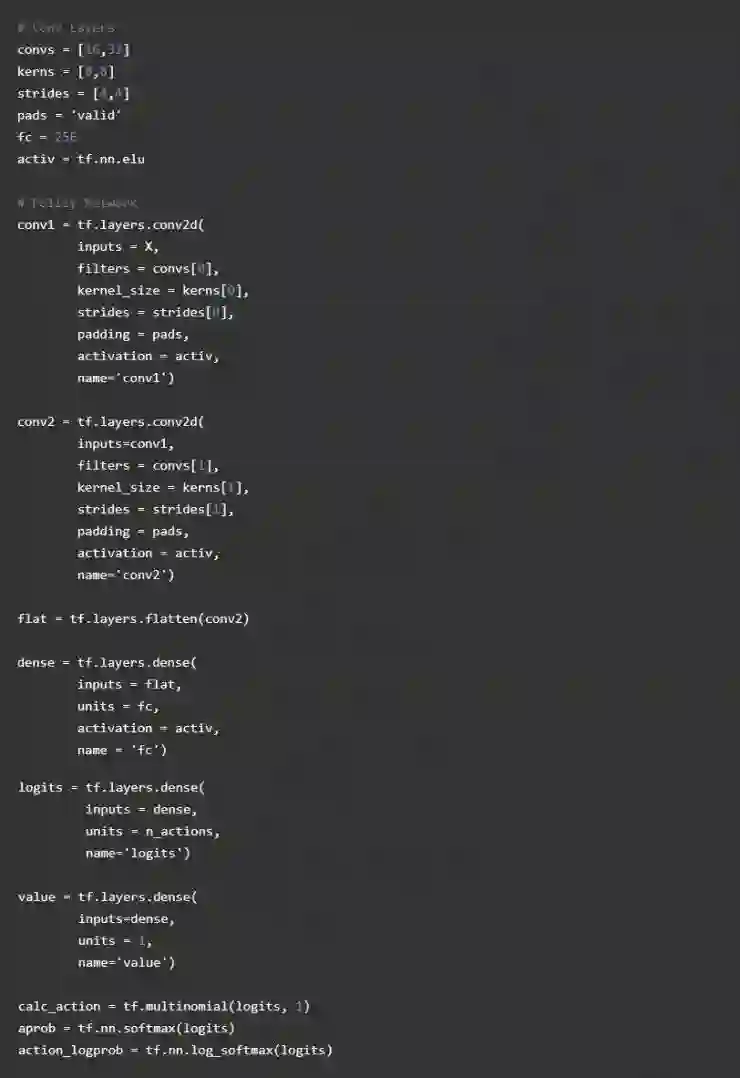
在深度学习中,权重初始化是非常重要的,tf.layers 默认会使用 glorot uniform intializer,就是我们熟知的 xavier 初始化,来初始化权重。如果你用了太大的偏差来初始化权重的话,Agent 会有有偏差,如果用了太小的偏差表现的极为随机。理想的状况是一开始的表现为随机,然后慢慢改变权重的值去最大化奖励。在增强学习中,这被称为勘探和开采,是因为初始的时候 Agent 会表现为随机探索环境,然后随着每个的更新他会把可能的行为慢慢朝向能够获得好的奖励的动作去靠。
计算和提高性能
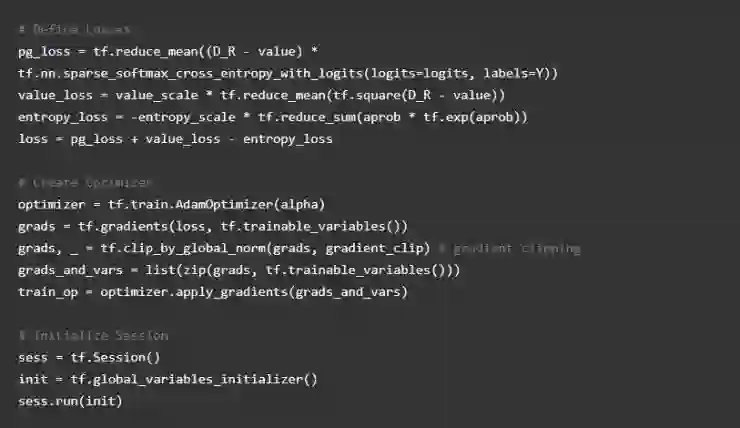
现在我们建立了模型,但是我们要怎样让它开始学习呢?解决方法很简单。我们想要改变神经网络的权重来提高我们采取动作的置信度,改变多少则是基于如何准确估量我们的价值的基础上。总体上,我们需要最小化我们的损失。
在 TensorFlow 上面实现,计算我们的策略损失可以使用 sparse_softmax_cross_entropy 函数(http://t.cn/RQIPRc7 )。稀疏意味着我们的行为标签是单个整数,而 logits 是我们最终的未激活的策略输出。这个函数计算了 softmax 和 log 损失。这使得执行的动作的置信度接近 1,损失接近 0。
然后,我们将交叉熵损失乘以贴现奖励与我们的价值近似值的差值。 我们使用常见的平均误差损失来计算我们的价值损失。然后我们把损失加在一起来计算我们的总损失。
训练 Agent
我们现在已经准备好去训练 Agent 了。我们使用当前的状态输入到神经网络中,通过调用 tf.multinomial 函数获取我们的动作,然后指定该动作并保留状态,动作和未来的奖励。我们存储新的 state2 作为我们当前的状态,重复这样的步骤直到该场景的结束。然后我们加上状态,动作和奖励数据到一个新的列表中,然后我们会用这些输入到网络中,用于评估批次。
根据我们的初始权重初始化,我们的 Agent 最终应该以大约 200 个训练循环解决环境,平均奖励 1200。OpenAI 的解决这个环境的标准是在超过 100 次试验中能获取 1000 的奖励。允许 Agent 进一步训练,平均能达到 1700,但似乎没有击败这个平均值。这是我的 Agent 经过 1000 次训练循环:
图 3. 1,000 遍后,Justin Francis 提供
为了更好的测试 Agent 的置信度,在给定任意帧图像你需要将状态输入到神经网络中并观察输出。这里,当遇到墙的时候,Agent 有 90% 的置信度这个需要采取向右是最好的动作,当接下来的图像在右边时候,Agent 有 61% 的置信度得到向前是最好的动作。

图 4. 状态比较,Justin Francis 提供
仔细思考一下,你可能会认为,61%的信心似乎是一个明显的好动作,这并不是那么好,那你就是对的了。我怀疑我们的 Agent 主要是学会了避免墙壁,而且由于 Agent 只收到幸存的奖励,它不是专门试图拿起医药包。随手捡起医药包,使得生存时间更长。在某些方面,我不会认为这个 Agent 是完全智能的。Agent 也几乎无视了左转。Agent 用了一个简单的策略,它已经会自我学习,还挺有效的。
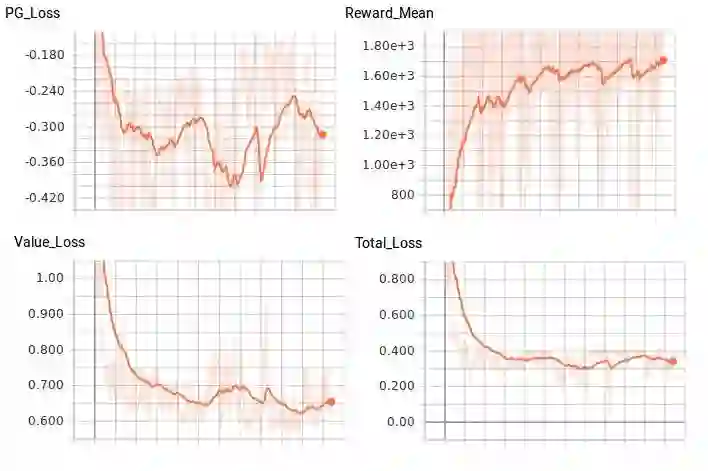
图 5. 损失和奖励比较,Justin Francis 提供
深入一步
现在,我希望你现在理解了策略梯度方法的基础知识。更优的 Actor-Critic 方法、 A3C 或者 PPO,这些都是推动策略梯度方法进步的基石。增强模型不考虑状态转换,操作值或 TD 错误,也可以用于处理信用分配的问题。要解决这些问题,需要多个神经网络和更多的智能训练数据。还有很多方式可以用来提高性能,比如调整超参数。通过一些小的修改,你可以使用相同的网络去解决更多的 Atari 游戏问题。去试试吧,看看效果如何!
(原作者注:这篇文章是由 O'Reilly 和 TensorFlow. See our statement of editorial independence 合作完成。)



CCF ADL 系列又一诚意课程
两位全球计算机领域 Top 10 大神加盟
——韩家炜 & Philip S Yu
共 13 位专家,覆盖计算机学科研究热点
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
强化学习在生成对抗网络文本生成中扮演的角色(Role of RL in Text Generation by GAN)
▼▼▼


