CIKM2022 | CROLoss: 一种推荐系统中检索模型的可定制损失函数

链接:https://arxiv.org/abs/2208.02971
在大规模推荐场景中,针对资源有限的情况下准确地检索出前N个相关的候选者是至关重要的。为了评估这类检索模型的性能,Recall@N,即在前N个排名中检索到的正样本的频率,其已被广泛使用。然而,大多数应用在传统检索模型的损失函数,如softmax交叉熵、triplet loss和成对对比损失,并不能直接优化Recall@N这一指标。此外,那些传统的损失函数不能针对每个应用所需的特定检索规模N进行定制,因此可能导致性能的提升是有限的。
假设商品 是从用户-商品集合 中提取的正样本,商品 是用户𝑢的负样本集合。针对于分类任务的softmax 交叉熵损失函数如下:
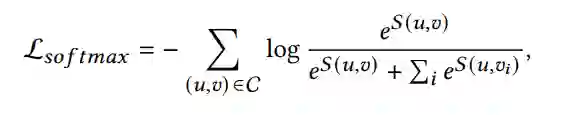
针对于成对排序任务的bpr损失函数如下:

针对于包含边界的成对排序任务的triplet损失函数如下:
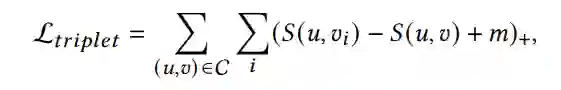
然而,上述损失函数没有直接考虑召回指标的建模。针对以上问题,本文提出了一种可定制的Recall@N优化损失(ROLoss),其是一个可以直接优化Recall@N指标的损失函数,并且可以针对不同的𝑁进行定制。另外,所提出的CRLoss定义了一个更普遍的损失函数空间,涵盖了大多数传统的损失函数的特例。通过在两个公共基准数据集上评估CRLoss。结果表明,在两种数据集的检索规模N的不同选择下,CROLoss比传统损失函数取得了SOTA的结果。CROLoss已经被部署到在线电子商务广告平台上,为期14天的在线A/B测试表明,CROLoss带来了4.75%的业务收入的大幅增长。
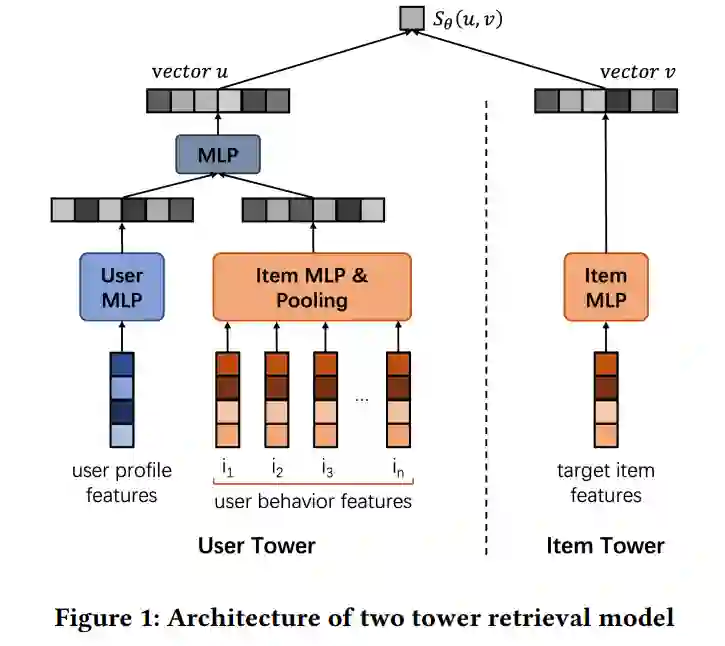
本文基于被广泛使用的双塔召回模型作为其基本模型。
在本文中,首先以成对样本比较的形式重写Recall@N指标(从公式5-7)。通过利用成对比较核函数𝜙,该目标函数被导出为可微的损失函数空间。

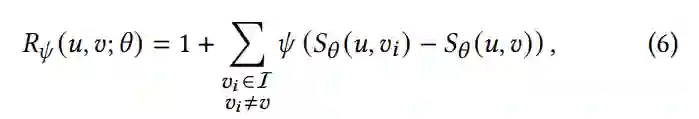
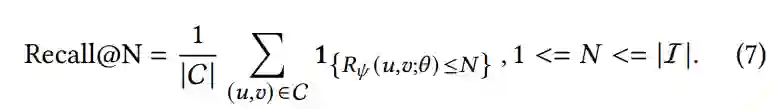
另外还引入了一个权重函数 ,以允许此损失函数可定制为不同的选择𝑁。
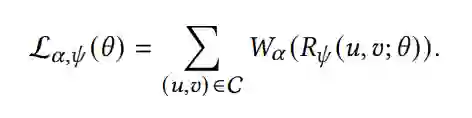
此外,可以证明,所提出的交叉损失函数空间涵盖了传统的交叉熵损失、三元组损失和bpr损失。
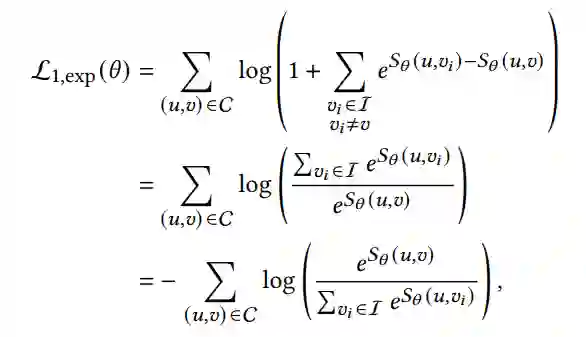
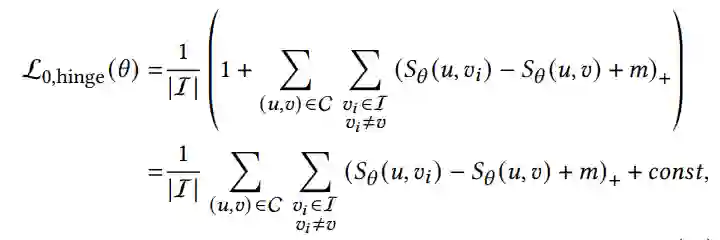
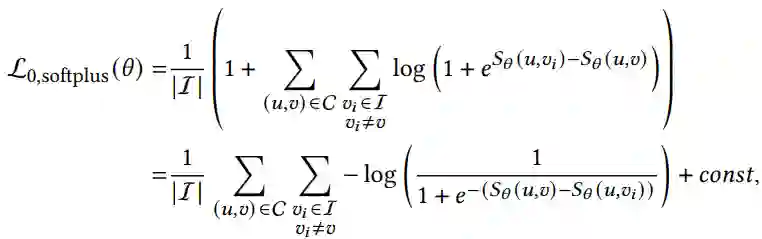
此外,通过分析交叉损失的梯度,发现比较核函数𝜙起着两种不同的作用。
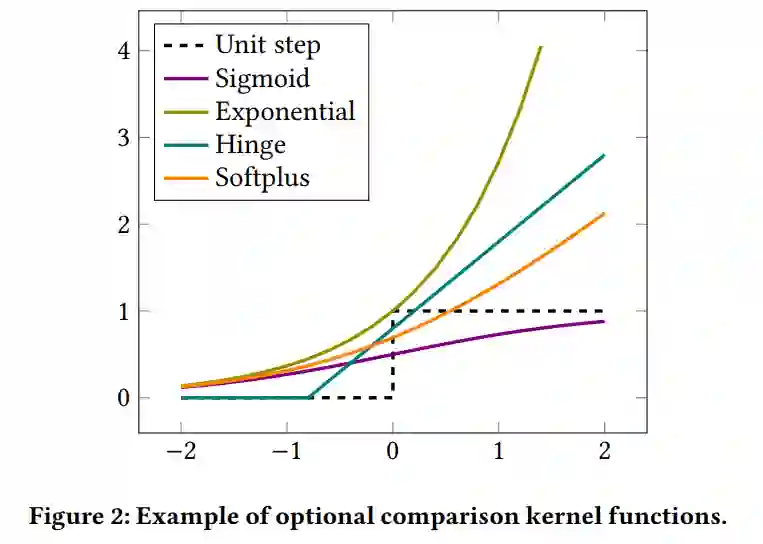
为了进一步改进这个损失函数,其开发了Lambda方法,这是一种基于梯度的方法,允许为这两个角色选择不同的内核𝜙1和𝜙2,并进一步提高系统性能。
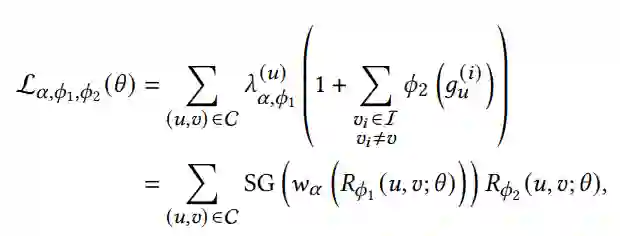
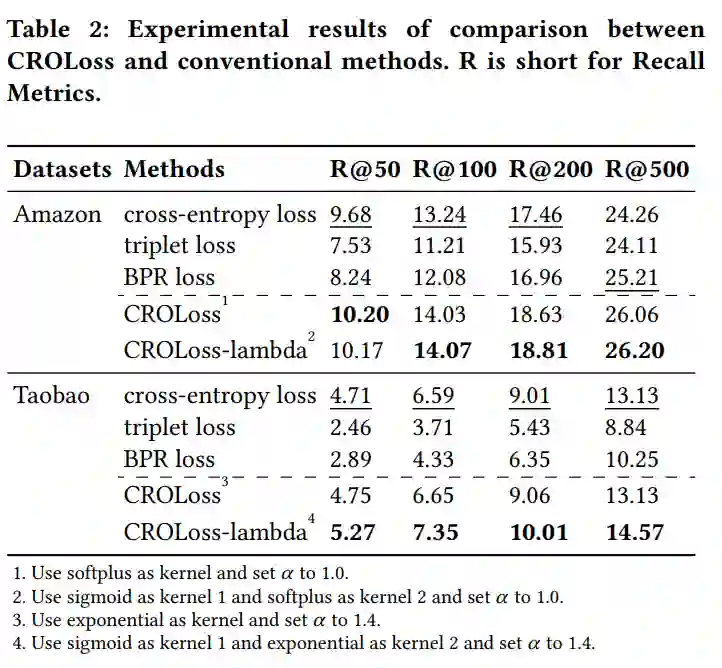
以下为所提损失函数与交叉熵损失、三元组损失、bpr损失的实验对比结果。

欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。


