旷视首席科学家孙剑:深度学习变革视觉计算

孙剑从视觉智能、计算机摄影学以及AI计算3个方面介绍了计算机视觉研究领域的变革。
作者 | 张栋
AI科技评论按:7月12日-7月14日,2019第四届全球人工智能与机器人峰会(CCF-GAIR 2019)于深圳正式召开。
峰会由中国计算机学会(CCF)主办,雷锋网、香港中文大学(深圳)承办,深圳市人工智能与机器人研究院协办,得到了深圳市政府的大力指导,是国内人工智能和机器人学术界、工业界及投资界三大领域的顶级交流博览盛会,旨在打造国内人工智能领域极具实力的跨界交流合作平台。
7月14日,「智慧城市·视觉智能」专场正式拉开帷幕,本专场全面围绕“未来城市级视觉AI的发展方向”这一主题展开。
会上,旷视首席科学家、研究院院长、西安交通大学人工智能学院院长孙剑带来了题为《深度学习变革视觉计算》的精彩分享。
孙剑从视觉智能、计算机摄影学以及AI计算3个方面介绍了计算机视觉研究领域的变革。
他首先回顾了深度学习发展历史,深度学习发展到今天并不容易,过程中遇到了两个主要障碍:
第一,深度神经网络能否很好地被训练。在深度学习获得成功之前曾被很多人怀疑,相比传统的机器学习理论,深度学习神经网络的参数要比数据大10倍甚至上百倍;
第二,当时的训练过程非常不稳定,论文即使给出了神经网络训练方法,其他研究者也很难把结果复现出来。
这些障碍直到2012年才开始慢慢被解除。
孙剑认为,深度学习和传统机器学习最大的差别是,随着数据量越来越大,使用更大的神经网络就有可能超越人类性能。
而具体到计算平台上,目前包括云、端、芯上的很多硬件上都可以部署智能,技术发展趋势是如何自适应地根据计算平台做自动模型设计。在这方面,旷视提出了Single Path One-Shot NAS的模型搜索新方法,它分为两步:
第一步是训练一个SuperNet,是一个超网络,包含我们想搜索的子网络,先训SuperNet所有的权重;
第二步是搜索Sub-Nets子网络,好处是第二步不需要训练,非常高效。整个模型搜索时间只是正常训练时间的1.5-2倍,但可以得到非常好的效果。目前在多个测试集上得到了领先的结果。
此外,为了构建核心技术,旷视还打造了自研的人工智能框架Brain++,包括具备多中心、强大算力的Brain++ Infrastructure,公司全员使用的深度学习引擎Brain++ Engine,以及整合最新模型搜索的AutoML技术;同时,旷视还有人工智能数据标注和管理平台Data++,借助算法辅助数据清洗和标注。

旷视首席科学家、研究院院长、西安交通大学人工智能学院院长孙剑
以下是孙剑博士大会现场演讲内容,雷锋网作了不改变原意的整理及编辑:
孙剑:谢谢大家,今天非常高兴来到本次盛会,会议的火爆程度比去年高很多。这次Talk的主题是回顾深度学习对计算机视觉研究带来的变化。
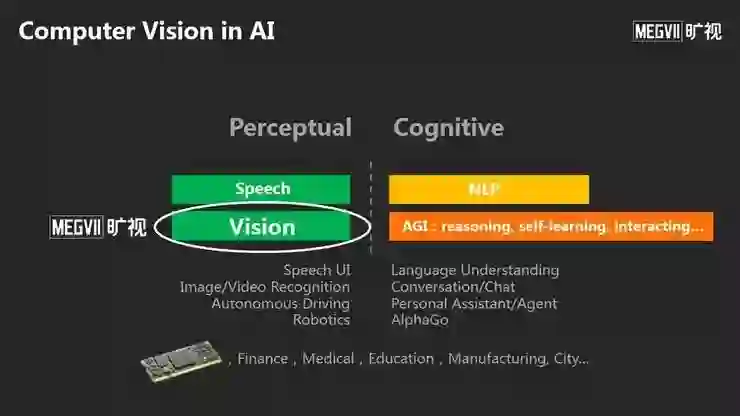
我们知道,计算机视觉在人工智能里占有非常重要的地位。人工智能可分为感知、认知两大部分,语音、自然语言、视觉是人工智能的三大支柱。我用不同的颜色表示不同方向的技术突破和落地程度。

旷视成立之初一直致力于计算机视觉研究,其发展如此兴盛的原因与我们周围存在的海量摄像头有关。
我们知道,摄像头作为一种重要载体,有非常多的应用场景,这也是今天计算机视觉领域有非常多公司的原因之一。
今天的分享主要分为三个方面,这也是深度学习引入计算机视觉后,对我们的研究带来的三大变革:
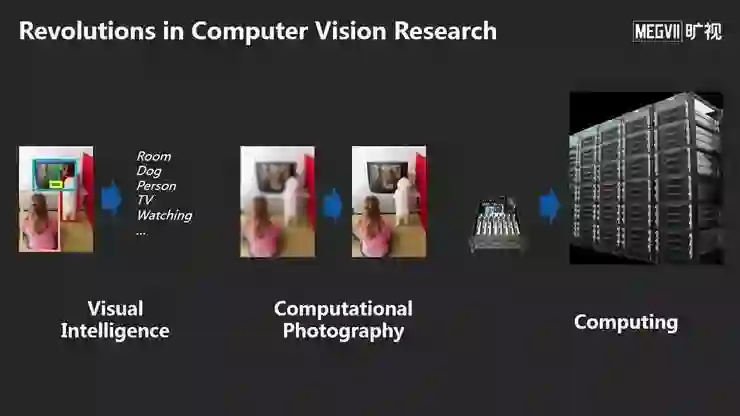
第一,视觉智能是回答了机器如何理解一张照片或者视频,这方面的研究发生了哪些变化?
第二,计算机摄影学研究如何从输入图像生成另一幅我们期望的图像,这个领域发生了哪些变化?
第三,今天的AI计算发生了哪些变化?
视觉智能


Marvin Minsky是人工智能领域的奠基者。他在研究人工智能之初,曾研究一个计算机视觉问题:将一个摄像头对着一堆积木用机械臂去抓取,以及让机器堆放的和人摆放的一样。
他招了几个实习生希望能在几个月就完成这个项目,但是几年后都没有太大进展。这说明计算机视觉是个非常难的课题。
计算机视觉研究虽然场景很多,至今可以归类为几个问题:分类、检测、分割以及将前三者用于视频序列的识别工作。
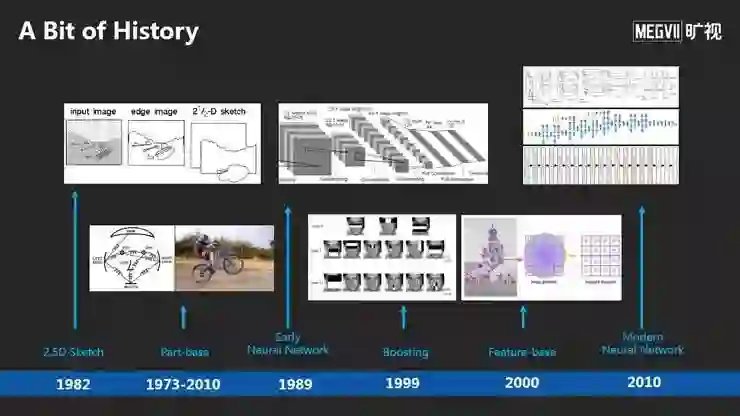
计算机视觉尤其是语义理解核心是如何在计算机中表示一张照片,以至于可以操作它、理解它,用它做各种各样的应用。最早期的研究包括David Marr提出的 2.5D Sketch, 和Part-base的表示。
90年代的神经网络主要用来做做字符识别、人脸检测。2000年左右,类似Boosting的机器学习方法第一次引入学习特征。
2000年后最好的方法是Feature-base,从一张图中抽取很多局部的特征,编码成一个非常长的向量。2010年深度学习后,神经网络给我们带来了更强大的视觉表示方法。

深度神经网络有两个特征:
首先,它是对一张图片做映射,映射到一个高维空间的向量上;它由非常长的非线性变换组成,进来的信号进行多次非线性变换,直到人们得到想要的图像表示。
第二,这个非线性变换中的所有参数都是根据监督信号全自动学习的,不需要人工设计。
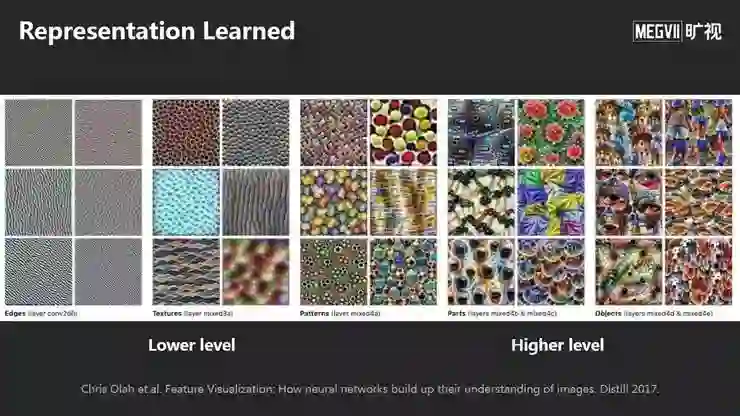
这是一个可视化工作,展示了神经网络在前面一些层学到了类似边缘、角点或纹理等初级模式,在后面一些层学到越来越多的语义模式例如物体或物体部分。整体学到了分层结构的表示。
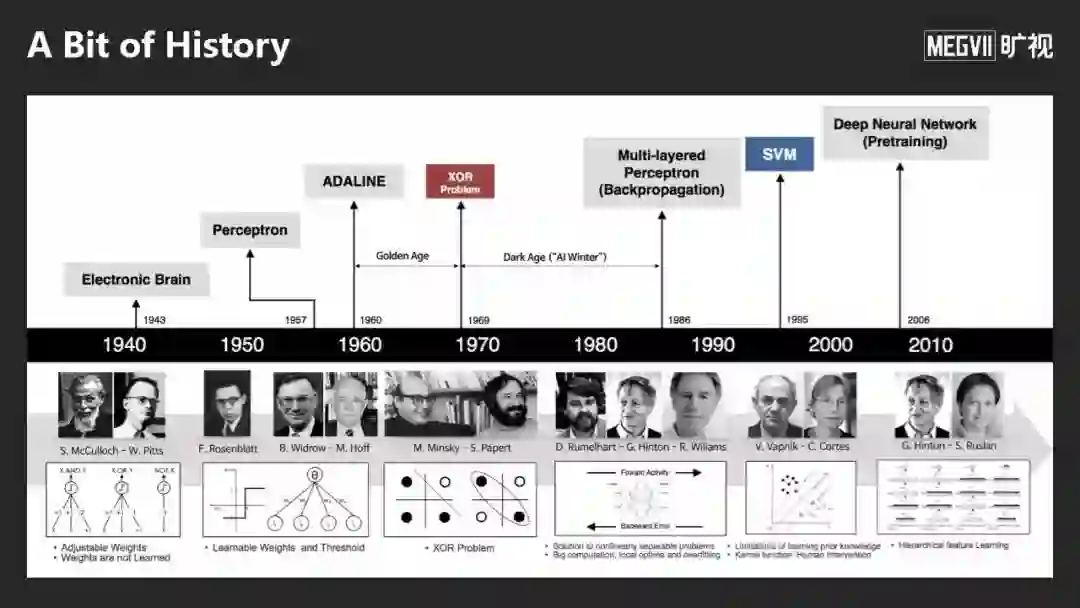
深度学习走到今天经历了很多的坎坷,直到2010年才重新占据了统治性地位,发展过程中主要遇到了两个障碍:
第一,深度神经网络能否很好地被训练。在今天深度学习成功之前很多人是不相信的。按照传统的机器学习理论,深度学习神经网络的参数比训练数据要大10倍甚至上百倍,如何很好地学习出来,很多人不相信。
第二,当时的训练过程非常不稳定,论文报了深度学习或者神经网络训练的方法,别人很难把结果复现出来。作为一名导师,很难鼓励他的学生从事这方面研究。
这两个障碍直到2012年开始慢慢地被解除。
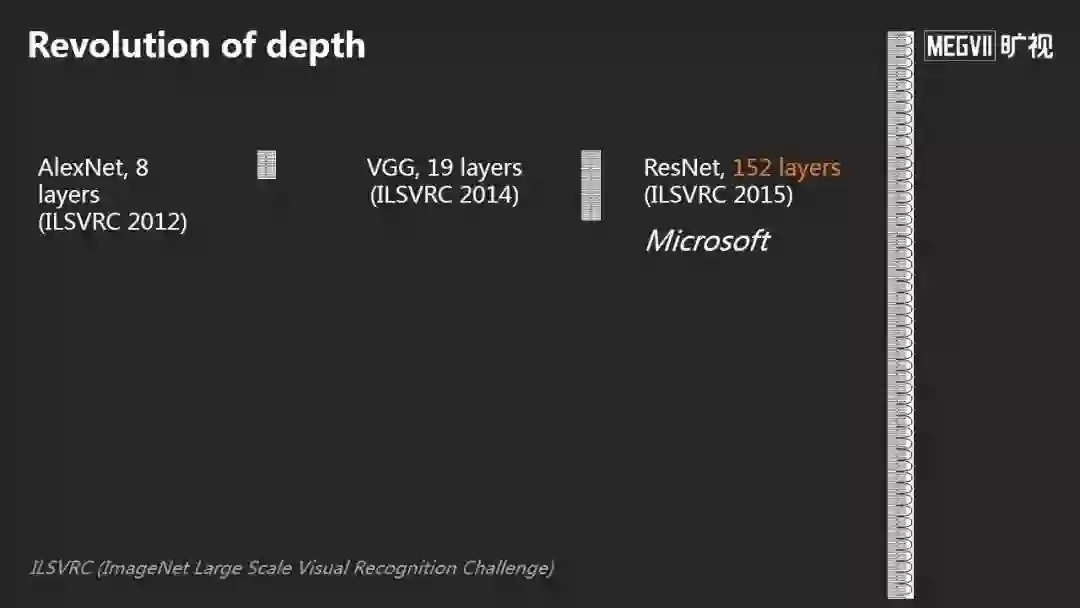
从2012年AlexNet,一个8 Layers的神经网络,后来有VGG, 一个19 Layers的神经网络,到了2015年,我们提出了152 Layers的神经网络。随着网络层数的增加与数据的增多,我们第一次在ImageNet数据集上让机器超越了人类。
从ImageNet数据集建立,到打破人类的性能大概用了5-6年时间。我想当初李飞飞教授团队完全没有想象到可以这么快,机器的能力超过人的能力。

我们当时做152 Layers网络经常被问一个问题:为什么这个网络是152 Layers?我们确定的回答是当时内存就可以装这么多层。
去年一个朋友给了一个更好的答案:8乘以19等于152。AlexNet是8层,VGG网络是19层,所以ResNet是152层。
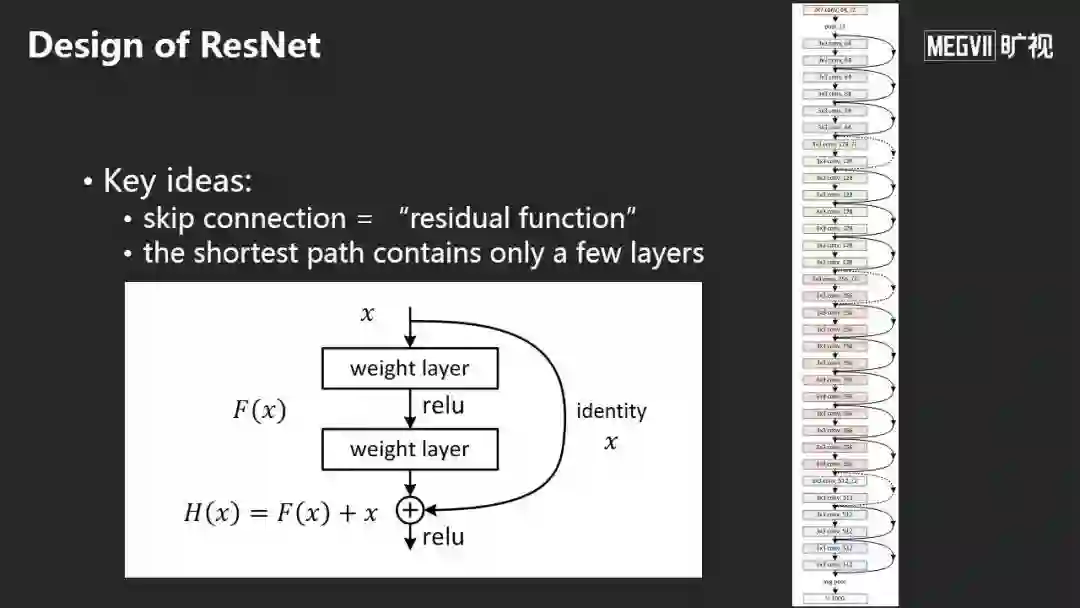
ResNet的核心思想是加入跳层连接,不要学习直接的映射而是学习残差映射,这样非常有利于训练或优化。
ResNet出来后,同行给了各种各样的解释。这是我比较相信的解释:而非ResNet很容易表示0映射,即输入信号和输出很接近0;而ResNet很容易表示Identity映射,即输入信号和输出很接近,直观的理解是当一个网络非常深时,相邻的变化越来越小。这种参数化的形式更利于学习,以至于我们神经网络的优化更容易。

这里列出深度学习之前遇到的很多困难:
数据、计算力不够;
如何初始化网络的方式;
如何使用非线性单元等。
ResNet补充了一点:网络结构应当对优化更友好。综合这些在深度学习方面的各种进展,今天每个人都可以很好地重现结果,做出高度可重复的实验。
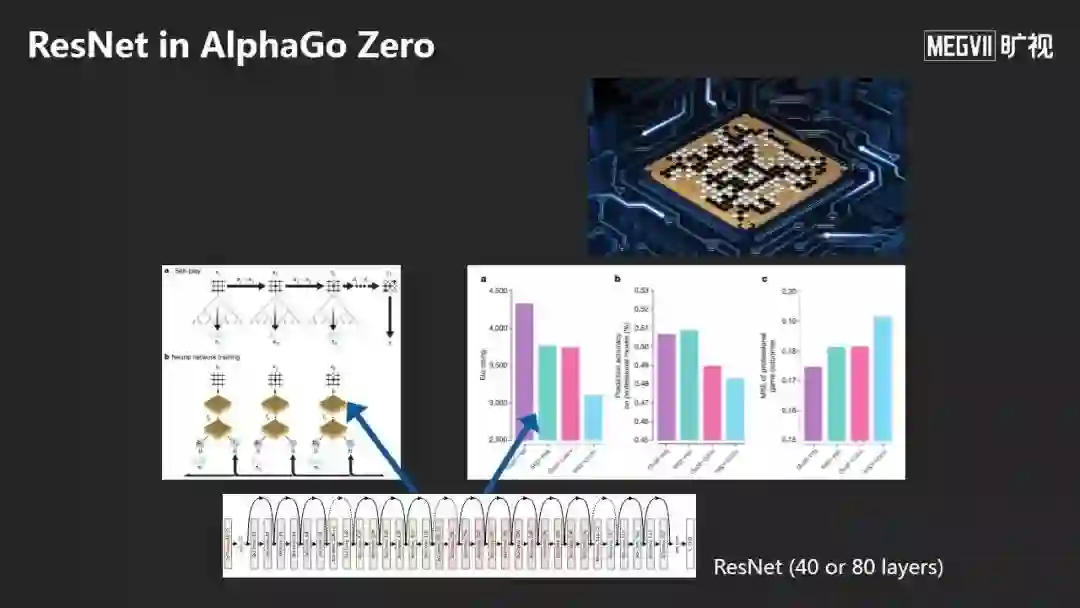
深度学习的映射能力非常强大,ResNet去年被用到AlphaGo Zero 中,他们用一个40或者80 Layers的ResNet,来预测棋子应该放置的位置。下棋这么复杂的映射都可以被一个简单的ResNet很好地学到,说明了其映射能力之强。
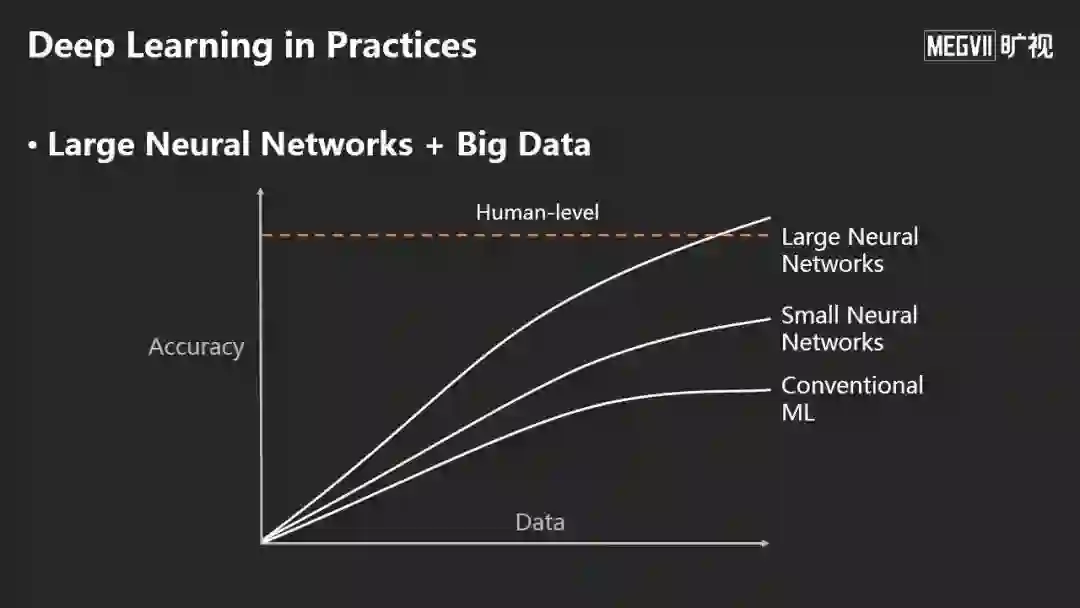
在实际过程中,在有监督学习问题上,深度学习和传统机器学习最大的差别在于:随着数据量越来越大,如果用更大的网络,很有可能超越人类的性能。
旷视第一个云服务的产品——Faceplusplus.com,提供了各种计算机视觉API,服务了全世界的开发者。
我们另一个产品是FaceID.com,它是目前最大的第三方身份认证平台,由于它远超人类的能力,目前服务于包括互联网金融、银行客服、交通出行等领域。
上述讨论的产品主要应用在云上,不用太考虑计算速度和神经网络的大小。云端模型的目标是突破认知边界,看我们能做得多好。
但是在线下场景,很多应用需要在移动端或手机上运行。在移动端这个计算平台上,有两个代表性的神经网络设计可以参考:
一个是Google的MobileNet系列;
一个是旷视ShuffleNet系列。
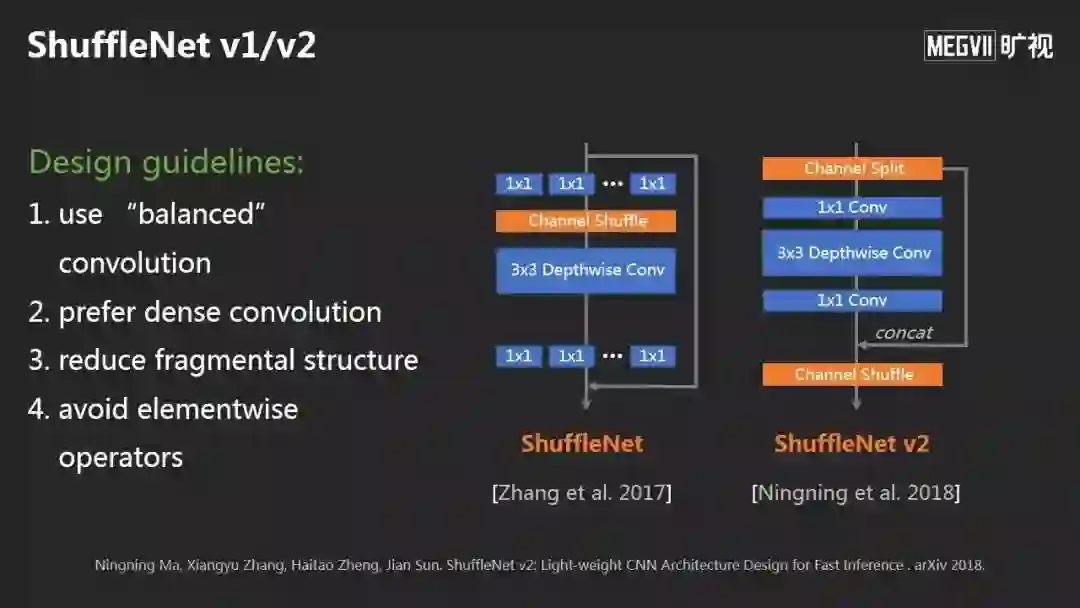
ShuffleNet有V1和V2版本,核心是提出了一套设计原理:比如让卷积更平衡;尽量不要产生分支;降低整体结构的碎片化,避免逐元素操作。
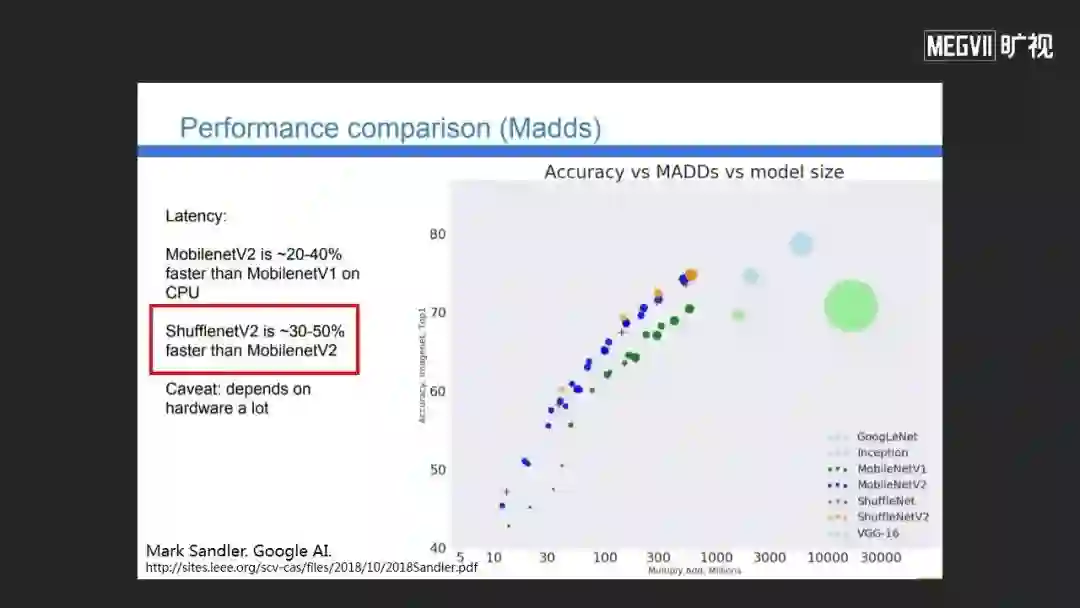
我们的ShuffleNet V2设计性能非常出色。这是Google AI团队给出评测报告,他们评测ShuffleNet V2在实际运行速度上经常比MobileNet V2快30-50%。
由此旷视助力国内全部一线手机厂商,做出了第一款2D人脸解锁手机、第一款3D结构光人脸识别解锁手机、第一款红外人脸解锁手机等。
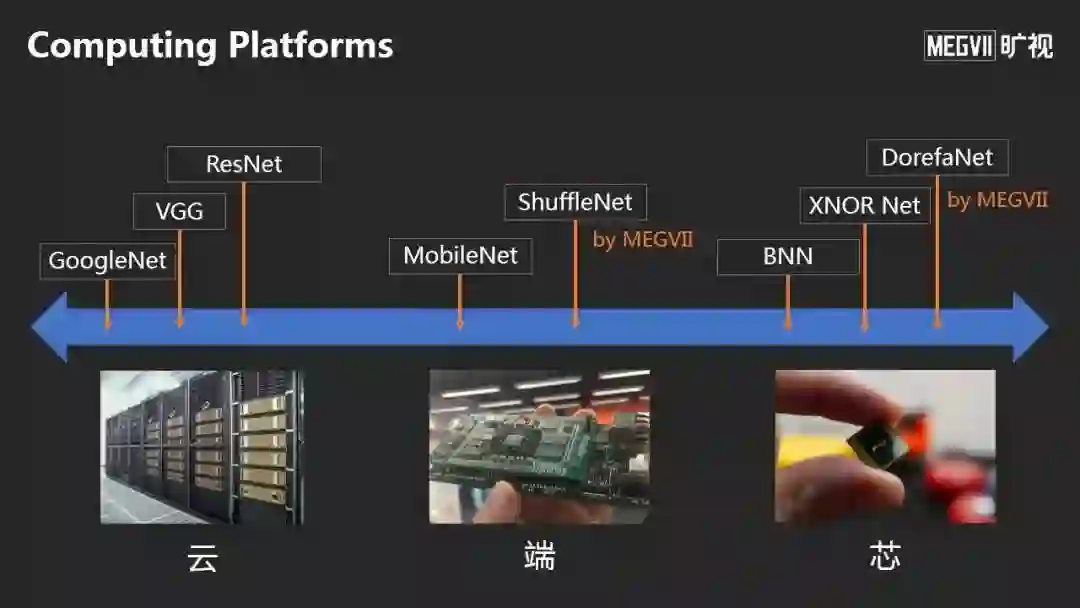
随着端上对功耗要求更低、面积体积更小,所以需要进一步研究如何把神经网络在芯片上高效运行。
因此出现了以低比特表示为代表的一系列工作,包括DorefaNet(旷视首先提出),在低比特运算方面,这是第一个提出将权重、激活向量、和梯度都进行低比特化的工作。

在芯片上,比计算最大的问题是内存访问带宽受限,需要内存访问量很大程度压下去,才可能高效运行。

这是我们在2017年推出的第一款基于FPGA的智能相机,我们把DorefaNet放在智能相机里。

2018年,我们把DorefaNet放在了一颗我们与合作伙伴联合研发的ASIC芯片上,提供了比FPGA高非常多的性能。
它不但可以用在手机上,还能用在实时的自动化场景中。右上图是AGV,用来搬运货架或物品,它有两个摄像头,朝下和朝前看,分别做车的导航和避障,类似室内无人车。
摄像头是机械臂的眼睛,它在搬运物体需要实时识别箱子在哪里,在哪里抓取箱子。在自动化流程过程中需要高效、高速地在端上做智能计算。
用了这些芯片的计算方法,可以应用到非常多的智能硬件上。这张图是都是旷视自研的硬件。
在神经网络设计的最新研究方面,目前很热的趋势叫AutoML或者NAS。这是一个很好的网站(automl.org),大家可以在这里看最新的文章。
NAS的问题核心是解一个嵌套的权重训练问题和网络结构搜索问题。
这个问题非常难,需要非常大的计算量。最早Google用增强学习或演化计算方法降低计算量,但计算量依然非常大。

最新流行的方式是用权重分享的方式,比如用Darts或ProxyLess等工作。我们旷视今年年初推出了Single Path One-Shot的新方法,分为两步:

第一步是训练一个SuperNet,这是一个超大的网络,任何子网络是我们想搜索的网络。我们先训SuperNet所有的权重;
第二步是做对SuperNet采样其中的子网络,好处是这一步不需要训练,非常高效,训练时间是正常训练时间的1.5-2倍,可以得到非常好的效果。目前在多个测试集上得到了最好效果。
我们的方法不但可以做图像分类,也可以做物体检测。

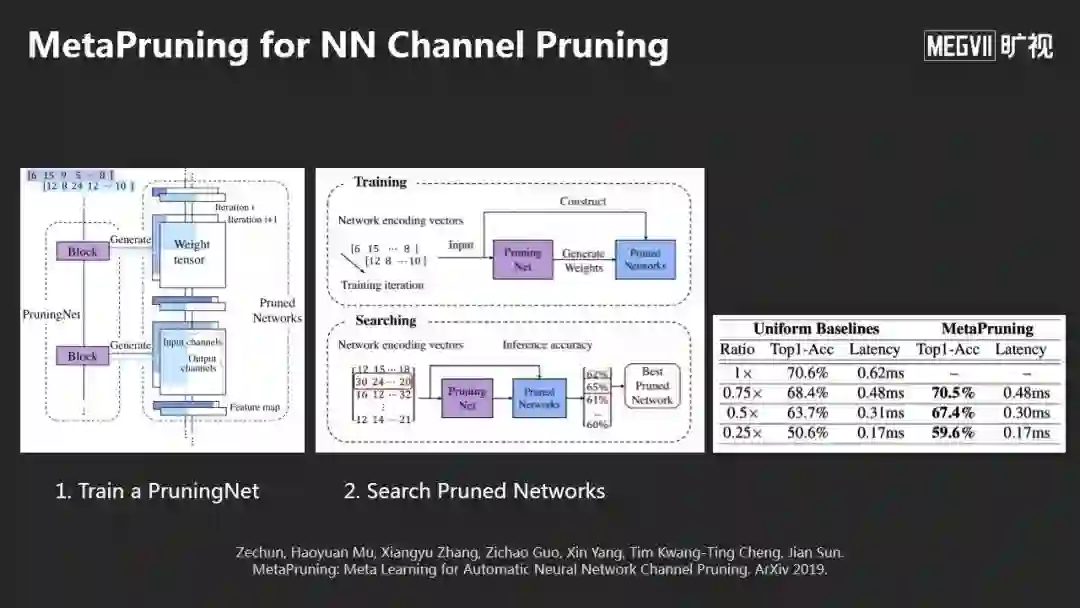
我们的方法还可以用来做模型简化(Pruning),同样可以用SuperNet的方法,先训一个PruningNet,它相当于一个SuperNet,由PruningNet生成很多子网络,得到很多很好的Pruning的效果。
以上是今天的第一部分,说的是视觉智能,我们从Feature的功能化定义,到走向模型的设计,再走到现在的模型搜索。
计算摄影学
第二部分,我想分享以前做了很多年的研究方向——计算摄影学。除了计算智能,计算机视觉中还有一个问题是给输入一个图像,输出是另一个图像。从输入质量比较差的图像(比如模糊、有噪声、光照不好)恢复更好的图像,这就是计算摄影学,也是目前研究很活跃的方向。

计算摄影学以前是怎么做的?这篇(上图)是我们2009年的Dehaze去雾,引入黑通道先验并结合雾的物理产生过程来恢复没有雾的图像,效果非常好,并获得了CVPR 2009最佳论文。

这是我们以前和同事一起做的(上图),如何从一张模糊图像和噪声图像恢复成清晰的图像,这里用了很多传统的反卷积方法。

这是另一问题,被称为图像抠图:左边是输入,右边是输出,目的是把前景精细分离出来。
这是我和今天第一位讲者贾佳亚教授当年联合做的一篇文章(上图)。

这是我和贾佳亚合作的第二篇文章(左上图)。一张图上缺失一部分或者想移除一个人,我们通过交互的方法,上面画一些线;后来我们又利用Patch自然统计的方法,能够做的更好。

总结一下传统的计算摄影学方法:“八仙过海”,每个问题需要寻找不同的假设,每个问题都要单独的去建模和求解。
不同的研究员有不同的方法,好处是你有能力的话可以做出非常有意思的方法,坏处是每一个方法都要独立设计。
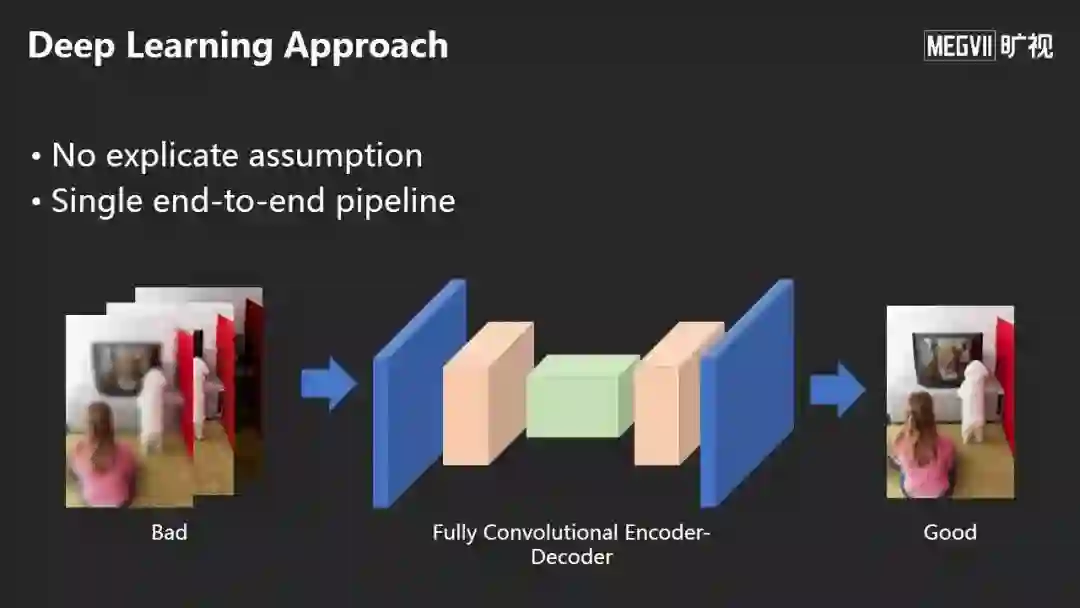
今天的深度学习的方法是抛弃了以前的做法,不需要做任何显式的假设,通过全卷积的Encoder-Decoder输出想要的图像。
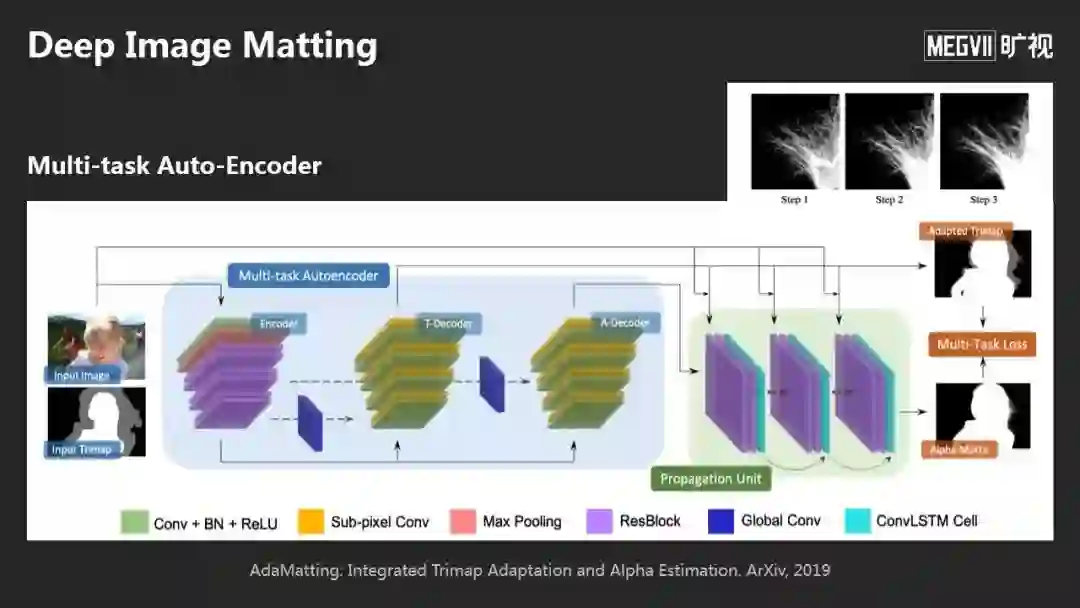
举个例子,关于Image Matting问题,今天的方法是:通过一个多任务的网络,可以直接输出Matting的结果,非常细的毛发都能提取出来。我们的工作在图像Matting最大的两个benchmark上都排名第一。

Matting不光可以做图像合成,它还可以用单摄像头就拍出像单反一样的效果。
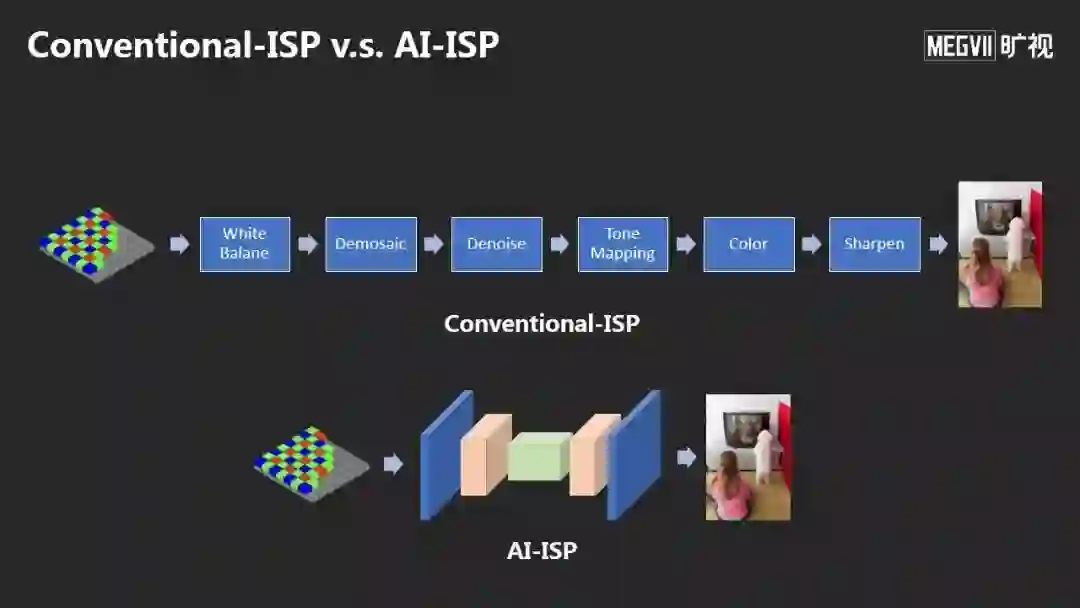
还有一个变革是这对相机里面的图像信号处理器ISP(Image Signal Processor), 上面是传统的图像ISP和图像信号处理流程,后面是AI-ISP,用一个神经网络来做。

左边是之前,右边是之后,AI-ISP可以得到非常好的降噪效果和高质量的图像。
这个方法获得了今年CVPR图像降噪的冠军,同时我们将这个方法应用在OPPO今年最新的旗舰手机OPPO Reno 10倍变焦版的夜摄超画质拍摄技术上。
AI计算
最后我想分享我们在计算上的变革。
左边传统的冯诺伊曼计算架构,服务了我们很多年。但随着数据的日益增大,出现了“冯诺伊曼瓶颈”,指内存和计算单元之间搬运数据的瓶颈。
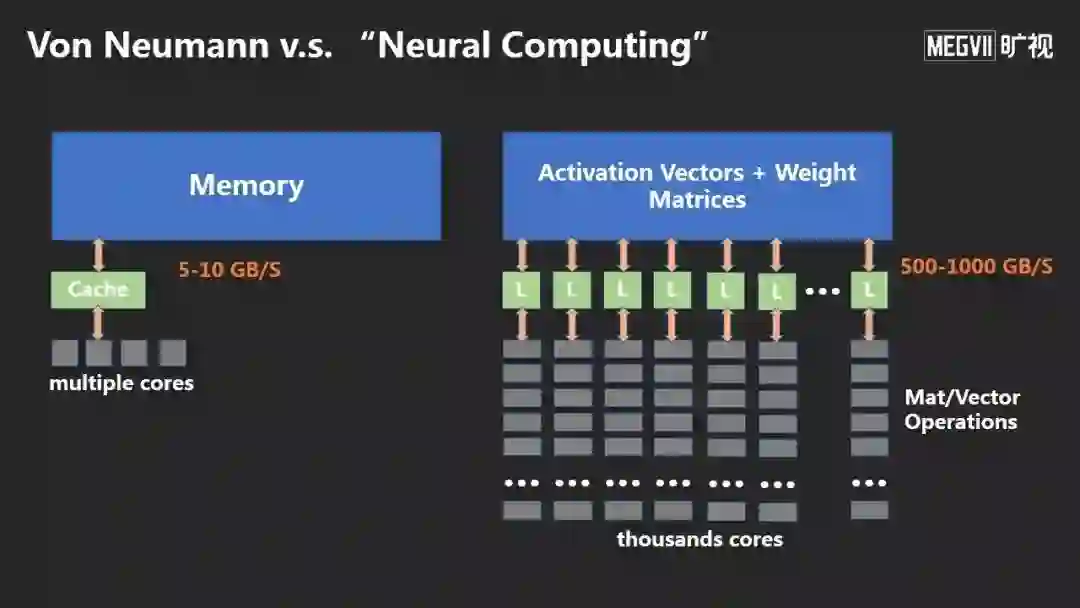
右边是今天神经网络做训练、推理的方法,它突破了这个瓶颈。因为神经网络计算非常简单,基本上只包含向量和矩阵之间的操作,可以避免很多判断和分支,用大规模并行的计算方式消除瓶颈。

虽然摩尔定律慢慢消失了,AI计算能力反而在超指数增长,从2016年10 TFLOPS的算力,现在到几百的TFLOPS。

前期带来的变化是从以前的大规模计算CPU Cloud(大盒子)迁移到了 GPU Box(小盒子)。但是大概2015年后,大家发现这些小盒子也不行,因为我们现在用更大的模型,我们今天在ImageNet上的模型比我们2015年用的大10倍都不止。另外,很多人一起工作时的每人一个小盒子的效率是非常低效的。

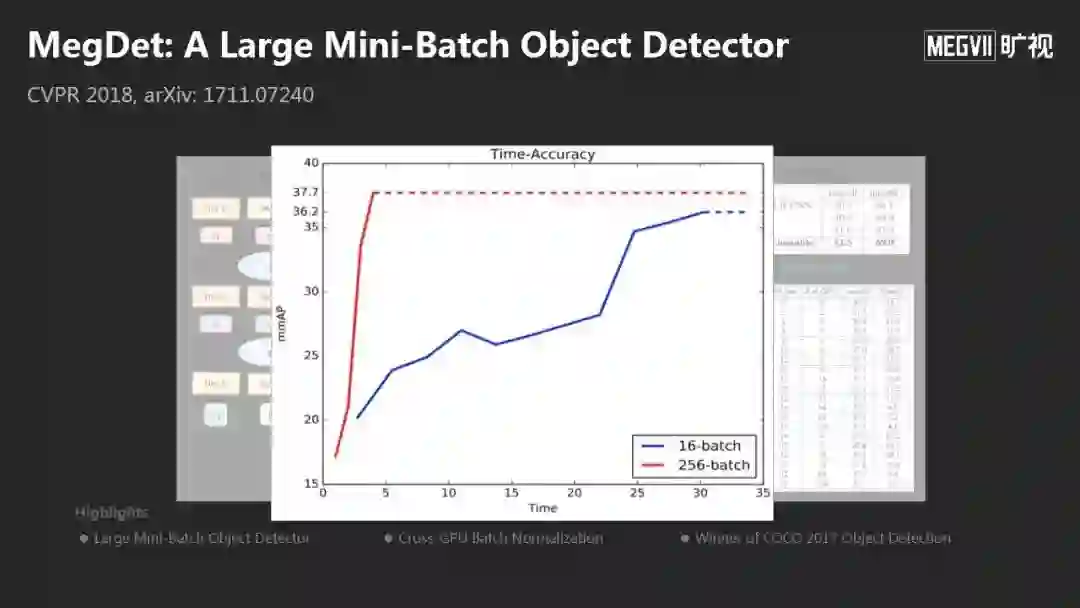
在模型大小方面,物体识别目前最权威的比赛是COCO,2017年我们得到了3项冠军,随着我们更大的模型,效果越来越好。2018年我们有更大的模型,拿下了4项COCO冠军。

这么大的模型,在一个小盒子里是不行的。2018年我们提出一个方法MegDet,结论是你可以用多个计算单元,可以把训练速度非常高效的提高,几乎是线性速度的加速,性能更好,这是模型的变化,是第一个方面。
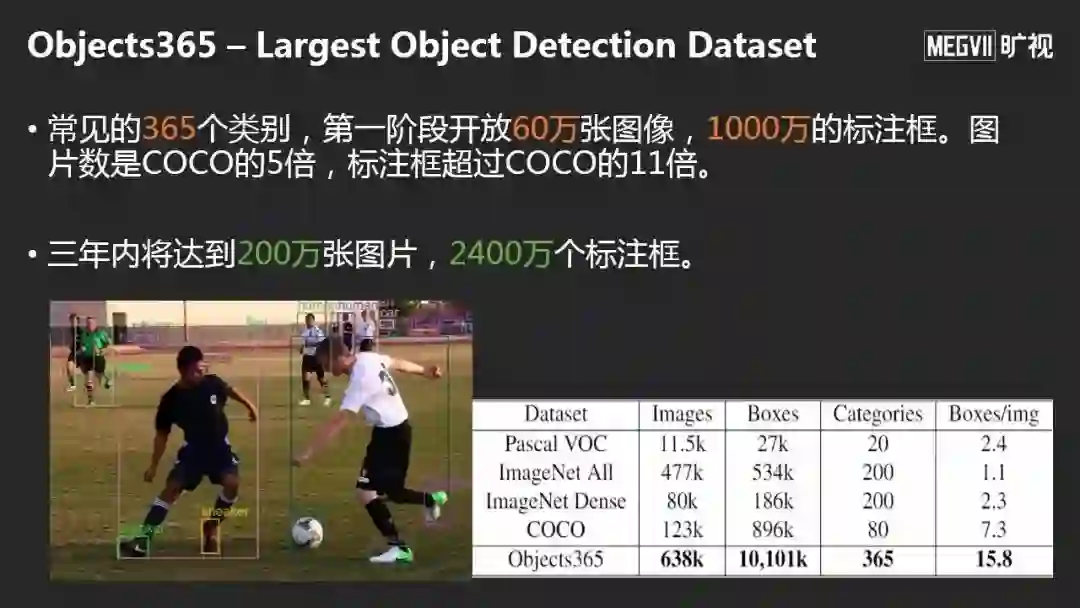
数据的话也会越来越大,这是旷视和北京智源人工智能研究院共同推出的Objects365,第一阶段开源超过1000万的标注框,这是目前世界上最大的检测数据集,不光是数据大,可以真正学到更好的Feature,这是第二方面。
第三方面,如果你的数据非常大无法放在小盒子里,必须放在中心。带来的问题是,如果我们同时训练,传输是很大的问题,
于是,在2015年之后,我们又从小盒子又回到大盒子,但这个大盒子是是GPU或者TPU Cloud。

为了做这件事,旷视自研了我们的AI平台Brain++,底层是物理算力,上面有Engine、Computing,Data,和AutoML。
这个Brain++ Engine是我们自研的深度学习引擎,之前大家用最多的是Caffe、TessorFlow、Pytorch,旷视从2014年研发Brain++ Engine,到现在旷视全员使用已经的版本已经是7.0版本。

据我所知,旷视是所有创业公司中唯一一家自研深度学习引擎并且全员使用的公司。引擎之下是计算环境,包括硬件管理,包括计算存储管理、模型训练支持等。
最后是自动模型搜索,也是在我们引擎中。它需要用大算力才可以把最好的模型搜索出来。
以上是我今天的分享,谢谢大家!







向左滑动,查看本论坛嘉宾
「AI投研邦」将在近期上线CCF GAIR 2019峰会完整视频与各大主题专场白皮书,包括机器人前沿专场、智能交通专场、智慧城市专场、AI芯片专场、AI金融专场、AI医疗专场、智慧教育专场等。「AI投研邦」会员们可免费观看全年峰会视频与研报内容,扫码进入会员页面了解更多,或私信助教小慕(微信:moocmm)咨询。

 点击
阅读原文
,查看
:
旷视发布通用物体检测数据集 Objects365,开启 CVPR 物体检测挑战赛
点击
阅读原文
,查看
:
旷视发布通用物体检测数据集 Objects365,开启 CVPR 物体检测挑战赛




