清华大学史元春教授《自然动作交互的编-解码优化方法》

史元春
清华大学计算机系教授
“长江学者”特聘教授
今天我报告的题目是《自然动作交互的编-解码优化方法》。
我是清华大学计算机系的教授,我们系有五个研究所,其中一个研究所叫做“人机交互与媒体集成研究所”,我在这个所;2018年,清华大学成立了人工智能研究院,其中一个研究中心是“智能人机交互研究中心”,我是这个中心的主任。清华还是比较重视人机交互研究的。
人机交互,是人机之间信息交换相关的理论和技术的研究,与今天无所不在的、人人都在使用的计算机的交互接口最直接相关。从主机、个人到PC、桌面计算,以及移动/穿戴和普适计算时代,交互模式发生了划时代的变化,当然交互模式变迁的节奏没有那么快,和摩尔定律相比还是很慢的,我大致给了差不多20年的变化周期,从CUI(命令行)到现在大量使用的使得计算机能广泛普及的GUI(图形用户界面),以及今天希望人人都很方便使用的NUI(自然用户界面),都用了大概20年的时间。正在到来的普适计算场景,计算的嵌入现实世界,如今天大会叫做“智周万物”,万物都成为计算的感知或交互的平台,希望的交互模式应该是更自然和更智能的。

这张图下部表上对比的内容信息量很大,我只简单列了一下keyword。
第一行是计算机如何感知人或感知了人在做什么,因为人机之间信息交换首先要感知人的交互的意图和需求。怎么感知?最早的如纸带机,直接用机器的语言打孔,CUI能在键盘敲命令和参数,用机器指令给的也是命令和参数,只不过机器是更直接的01编码。GUI,就可以用鼠标的指点动作表达命令和参数。在今天移动,手机和各种各样穿戴设备上,有更广、更符合人的自然行为的一些方式,包括语音的可用;更多场景下使用的是触感界面上直接的手指点击动作来代替鼠标,也就是不需要操控输入设备。未来可能界面没有一个显式存在的界面,可能空中很多设备、传感器都是我们交互的接口。交互方式的改变,能看到一个趋势,就是越来越符合人的自然行为,不需要学习、不需要很复杂的操纵输入设备。
最后一行,我们能看出,能使用这些交互模式的应用也是越来越广泛,并且使用范围从科学计算、计算控制、办公应用到越来越多个人和日常的应用。这里想告诉大家的是,人机交互其实是为我们计算模式的改变奠定了一个基本的界面和操纵的基础,它也是我们操作系统的组成部分。
在移动和普适计算时代,自然交互中人的交互行为、动作在这里希望被计算机直接理解成为命令和参数来参与交互意图的表达和交互任务的执行。因此,自然动作交互就成为人机交互,以及视觉、语音这些方面研究的一个关键词。
自然动作交互有多种形式,穿戴的与生理信号相关的采集,像现在很热的AR/VR眼镜,需要有更多的动作表达。
实际上从desktop、touchpad就可以在二维空间上表示动作了。三维,活动范围和表达能力复杂性,以及信息的承载能力有更大的扩展,也有更多的期望。
自然动作交互涉及到哪些问题?
自然动作交互是人可以脱离传统的工具,以不需要特定的设备,甚至不需要所谓视觉注意力更多的参与就可以进行交互界面、交互命令的表达。我们的行为更多是基于人的肌肉记忆形成的习惯,而不需要一个刻意的学习过程。所以这是一种很典型的机器来适应人的一种交互模式,也是所谓“自然”的来源。同时也有显然的劣势,也都是和优势有关的。这里牵涉到各种传感设备,传感技术是否有利于获取交互动作,并且能够很准确获取动作意图,并具有扩展性。
人机交互是一个交叉学科的研究领域,会研究很多人的性能和能力。交互对人的能力的需求非常像一个退步,而不是进步。什么意思?图形用户界面其实给了人极小的记忆负担,只需要一个能力,会操作鼠标就行,到了触屏手机,扔掉鼠标会动手指就行。而对内容的访问,需要人有一定结构化的理解,比如数据内容和应用内容大概是树形的结构,必须访问路径要正确,不正确就到不了,因此有更多搜索技术的出现,让你可以直接到达。
但是人能够表达和记住的动作并没有那么多,所以反而成为它的一个劣势。因此在2010年,如微软出了Kinect,有很多宣传,研究也很热,觉得真的自然交互界面已经出现了。但是,当年人机交互很有名的Norman教授,他有一个标题叫做《自然用户界面并不自然》的文章,谈的基本就是以上一些问题。优势和劣势同时都存在,这个存在是由于对人的行为,以及对感知的能力和识别的能力共存的一些问题。
举一个例子。现在已经有这样的电视,电视上有深度摄像头,类似Kinect,如给一个电视命令,如果现在开着电视有一个电话进来,通常要静音。我们可以很“自然”地做给电视一个捂嘴的动作,作为“静音”指令。还有大量我们愿意表达的动作、与任务相关的动作,到底哪些命令和参数可以用动作表达出来,并且有传感器来识别,有算法来准确理解人的意图?
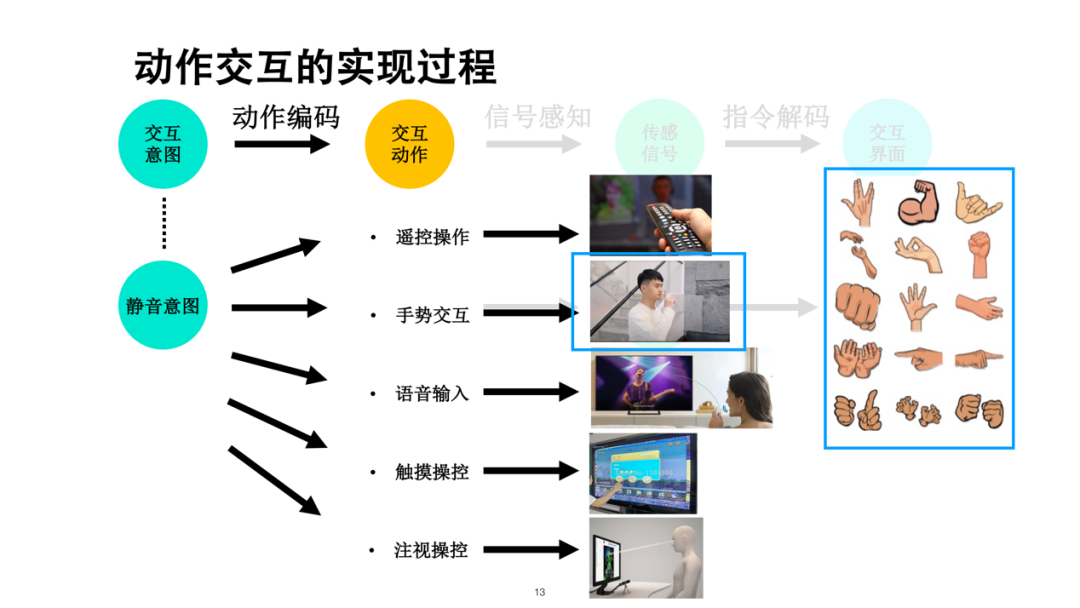
以上例为例,可以看到动作交互有这样一个过程,要对动作编码。后面要有传感信号,要有对传感得到信号的理解。上图表示一个命令意图可以根据不同接口设计很多不同的动作,比如设计某一个手势,其实有很大的设计空间。
理解相关动作有一个解码过程。编码的目的是要有自然;解码是识别问题,要准确。什么叫做自然编码?我们希望形意合一,动作和任务、命令能够在认知和行为上达到统一。意图识别强调的准确性是指交互意图,而不是这个数据有多高的统计性。
在研究中,动作交互看作是一个编码和解码的过程,下面分别举例讲一下动作编码和动作解码。其实编-解码也不是孤立的,而是相关的。
• 编码
自然编码需要解决低成本问题,比如怎么知道有这样一个动作,这个动作是什么?这个例子是,如果你在手机上画个圈,可以把这个照相机调出来,如果不知道就不会用,只会到菜单里搜,用户难发现。第二,完成动作的成本,如果定义手势是这样的,对应编码空间很大。所谓形意合一是能够做到语义的映射,易于发现,可以完成,并且很容易记忆。因为人对手势的记忆空间实际上非常小,并且与任务相关。
下面是一个具体实现案例。

在VR里,总有任务中要选取操作的对象,通常出现一系列菜单,让你用手势去选,效率不高。我们可以做到把人已有的对操控对象有关的动作做出来,就可以自动拿到这样的对象。如果是玩游戏,比如弓箭、叉、枪,做握持它的动作,这样的映射及识别就没有什么记忆和表达成本。如果是在空中菜单中选取,还是比较复杂的过程,而这个可以比较自然和直接。
其实手的表达力丰富,同时也是资源最稀缺的,我们需要用手干别的。因此在动作编码中还有其他很多身体行为都可以表达。
举例,EarTouch(视频)。这个看起来是我们给盲人做的一项技术,如何用人的耳朵和手机之间的动作来做到直接命令的输入。视频中这是一个真的盲人同学。手机给盲人有一定的读屏功能,但是盲人通常会双手被占用,很多场景中就不能使用手了;同时耳机也不能用,因为盲人要用耳朵来观察周围的情况。新的方式是人手拿着这个手机既可以听,又可以用耳朵和触屏之间做特定的动作,实际上这几个动作很容易被掌握,研究结果也有相应的证明。
具体动作设计,移动、旋转和敲击几类基本动作对于盲人很容易掌握,对于明眼人很多时候也不需要把视力都付诸在交互任务上。
• 解码
这是大家都非常熟悉的一个问题,是一个识别问题,但是对于交互来说,动作交互最难的问题是有意动作和无意动作很难区分,就是说不能都来一个开始的词、开始的动作才可以做有意动作,所以这个界限需要算法来自动识别。
我们在研究中提出要用自然动作基本运动单元的自相关性,比如时间和空间特征,以及时间在有意动作和无意动作前后速度和角度的变化特征,复合动作的时序概率,可以用来进行意图推理。
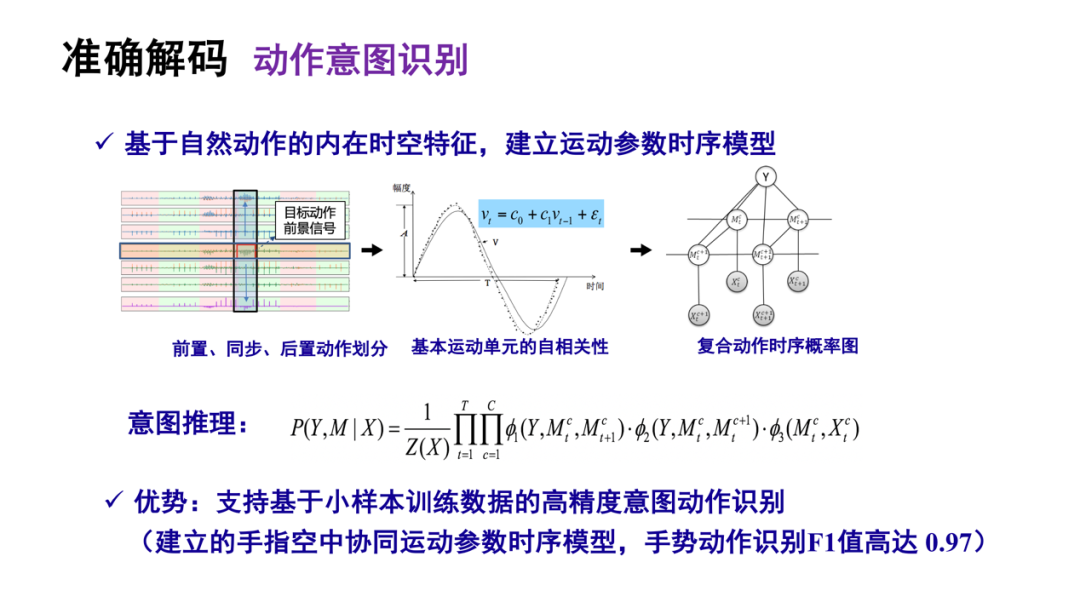
作为方法验证,我们对人的最复杂动作,手指上的运动按这套解码原理可以做到F1值高达0.97。这段video解释了几十年前设想的空中打字,准确率可以达到百分之百。如果机器学习了一个特定人打字姿态,可以把几个基本运动单元,10个手指每个关键的基本运动单元的相关性计算在模型里,所以可用的信息量比较大,有助于我们把特征准确地提取出来。
这个动作提取在很多应用中都存在,比如现在VR/AR中有很多虚拟空中对象让大家去选,都是看清了再去点,一是时间要慢,因为要先看后点;二是因为人甚至要动头,这样场景要跟着动,这就是眩晕感的来源、问题的来源。因此,我们需要做所谓无视觉参与,就是人的自体感知相对准确度,对这个人的能力进行建模,对于动作的识别和对象的呈现同时来做运动控制偏差的补偿。现在这个算法已经做在AR眼镜上,在准确度一致情况下,访问时间可以缩短30%,同时眩晕感可以明确下降。
动作还有隐式携带的,不是主动进行表达的,但是决定了交互动作的语义,比如有意或无意。大家如果用华为手机,Mate10以后的以及P系列,还有现在的折叠屏手机,用户很容易有误触,这在操作系统的传感系统上要首先解决。比如三星很早推出这样的产品,又把曲面侧边给软件废掉了。从2016年开始,华为的全面屏手机就比较成功;华为还在全球第一个推出外翻式折叠屏,也就是只要抓住这个手机,里外都是屏,如果没有误触检测,一直都会有误触的。所以也用这套方法可以很好地解决误触问题。
不管输编码还是解码,总体上是自然交互动作意图理解,它牵涉到用户心理模型的建立,根据交互意图和交互任务,通过什么样的数据通道可以表达合适的符合人心理模型的动作表达。
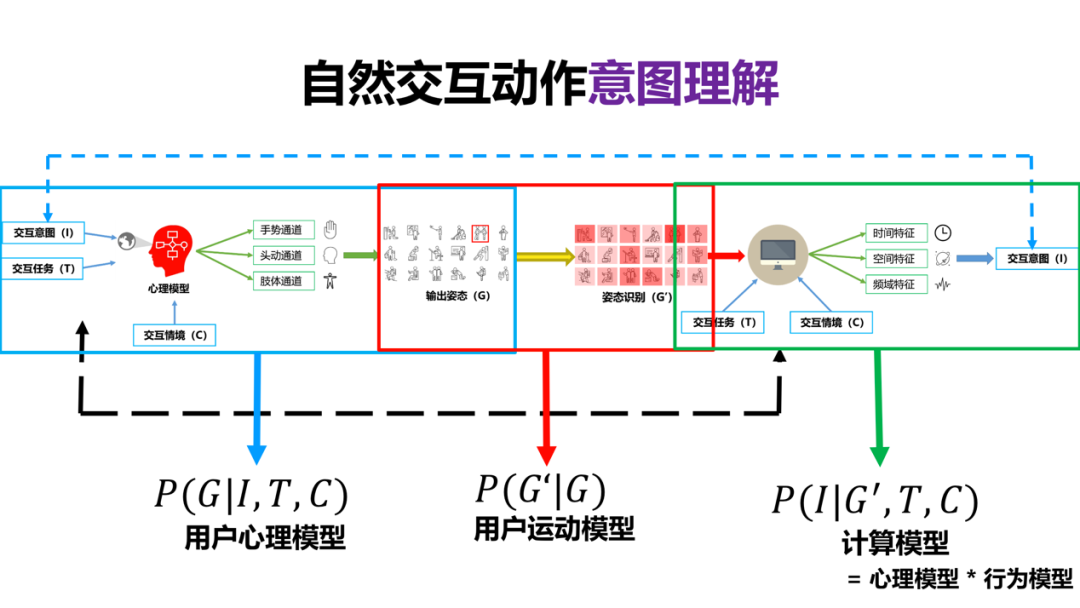
当然运动模型是数据的采集和输出姿态的一致性,最终识别的模型就是一个贝叶斯的推理过程,就是如何把心理和行为模型建立相关的意图识别的计算模型。比如在特定的任务,像打字这个任务就要与语言和触摸模型进行结合,其他动作也是相似的。
最初提到人机交互是要实现在操作系统中UI的服务,在Windows、desktop和移动上都有规范的模式,如WIMP和PWIG, 未来也希望有越来越多好的算法集成到眼镜等新型终端的OS上,尤其是对眼镜和智能家居可能成为必要。
(本报告根据速记整理)








