不“丢脸”实现人脸识别,使用TiFGAN合成音频 | AI Scholar Weekly

大数据文摘专栏作品
作者:Christopher Dossman
编译:云舟
呜啦啦啦啦啦啦啦大家好,还记得那位在中国向工程师们教授AI的美国老师Christopher Dossman吗?大数据文摘与他取得了联系,并且有幸邀请他开设了专栏。从本周起,由Chris精心打造的AI Scholar Weekly栏目终于要和大家见面了。
AI Scholar Weekly是AI领域的学术专栏,致力于为你带来最新潮、最全面、最深度的AI学术概览,一网打尽每周AI学术的前沿资讯,文末还会不定期更新AI黑镜系列小故事。
周一更新,做AI科研,每周从这一篇开始就够啦!
本周关键词:CNN可视化,Web ML应用,面部图像检索,基于DL的恶意软件对抗测试平台,音频合成
使用Net2Vis为CNN创造可直接发布的可视化方案

Net2Vis的主要目标是通过使用巧妙的可视化编码来遵循视觉语法规则,从而提高CNN的可读性。它还通过层积累结合了层抽象,大大降低了网络体系结构的复杂性。通过这种方法,我们可以实现连贯、清晰的可视化方案设计。此外,Net2Vis可以更及时地完成工作,在时间层面上大大优于之前的同类方法。
潜在应用与效果
像Net2Vis这样的方法可以让研究人员很容易地建立CNN的可视化效果图,并且减少CNN可视化的模糊性。另一方面,如果这个方法能够广泛应用于所有网络结构的可视化之中,读者们就能够在不学习特定论文使用的可视化语言的情况下理解CNN的可视化结果,从而减少理解错误的可能。
原文:
https://arxiv.org/abs/1902.04394v1
代码:
https://github.com/viscom-ulm/Net2Vis
使用TensorsCone框架开发安全的ML Web应用程序
如果你想开发鲁棒性强且十分安全的机器学习(ML)应用程序,Tensorscone会是一个不错的选择,它是一个基于IntelSGX的面向硬件的安全机器学习框架。TensorsCone在不影响准确性的前提下提供了透明性和高水平的性能。与以前实现数据隐私和完整性的模型不同,TensorsCone的设计和体系结构是基于TensorFlow的,并且同时支持培训和分类。
该框架使用了IntelSGX的先进技术,能够为部署在不受信任的Web基础设施上的任何ML应用程序提供强大的保密性和完整性。目前,TensorsCone已经通过几个基准以及实际应用程序进行了评估,并表现出了强大的效率和安全性。
潜在应用与效果
TensorsCone是ML工程师的福音,因为它可以帮助他们在不牺牲准确性和性能的情况下开发和执行针对私有和敏感数据的ML应用程序。此外,TensorsCone基于TensorFlow这一最流行的ML框架,所以它可以支持各种未修改的现有ML应用程序。
原文:
https://arxiv.org/abs/1902.04413v1
改善极端激烈运动的深姿态估计
这一方法使用运动后数据来改善对极端激烈运动的深度人体姿态估计。它采用旋转增强技术对输入数据进行增强,并对每帧进行多次姿态估计。此后,最一致的姿态和动作被重建为平滑姿态。对该模型的系统测试表明,对于极端激烈的动作和不规律的姿态来说,该模型能够有效提高估计的综合质量。
潜在应用与效果
这种深度姿态估计算法可以在各种激烈的人体运动捕捉和虚拟动作的修改中得到应用,这在过去是非常困难的。后数据增强方法也可以有效地用于许多HCI、UI和体育科学软件。此外,该方法还启发了DNN技术在ML领域之外的应用。
原文:
https://arxiv.org/abs/1902.04250v1
基于CMH-ECC技术的高效人脸图像检索

研究人员提出了一种新的深度纠错交叉模式散列(Error-Corrected Deep Cross-Modal Hashing : CMH-ECC)模型,该模型使用位图来描述某些面部属性,在给定需要查询的属性后,数据库系统就会完成相关的面部图像检索。基于两个标准开源数据集的测试结果表明,该模型优于传统的图像检索算法。
虽然目前的人脸图像检索方法取得了令人印象深刻的效果,但事实上,它们仍然缺乏有效的程序来细化图像搜索中的人脸属性。该模型中采用纠错码,通过深度跨模式散列法减少了汉明距离,从而提高了检索效率。
此外,CMH-ECC使用点向数据执行面部图像检索,而无需使用成对或三倍的训练数据,这使得它可以扩展到非常巨大的数据集。
潜在应用与效果
通过新的CMH-ECC模型,研究人员、设计人员和开发人员现在可以检索精确匹配和经过改进的面部图像。该模型也可能是向下一代基于面部图像的ML应用程序进化的开始。这有可能改善基于摄像头的安全系统。
原文:
https://arxiv.org/abs/1902.04139v1
对目标检测模型的训练进行简单、通用的调整以提高精度
研究人员最近研究了对模型训练进行通用调整这一课题,这可以在不增加计算开销的情况下提高对象检测模型的性能。测试结果表明,在每个人工智能工程师都做过的目标检测训练中,这些调整可以提高大约5%的绝对精度。
首先,研究人员探索了一种对象检测的混合技术,并识别出了在多个对象检测任务中有助于保持空间变换的特殊性质。由此,他们提出了一个可以应用于任何对象检测任务的视觉连贯的混合方法。第二,他们全面探索了如学习率调度、权重下降和批处理规范等细节。最后,通过逐步将该训练提升方法集成到训练单级和多级目标的检测模型中,他们研究了该方法的有效性。
潜在应用与效果
叠加和实现这些调整意味着研究人员可以轻松地训练目标探测器模型,同时不产生额外的计算成本。这样的研究也有助于科学家和工程师们开发出更有效的目标检测算法。
原文:
https://arxiv.org/abs/1902.04103v1
用于物联网系统强对抗性样本的测试框架
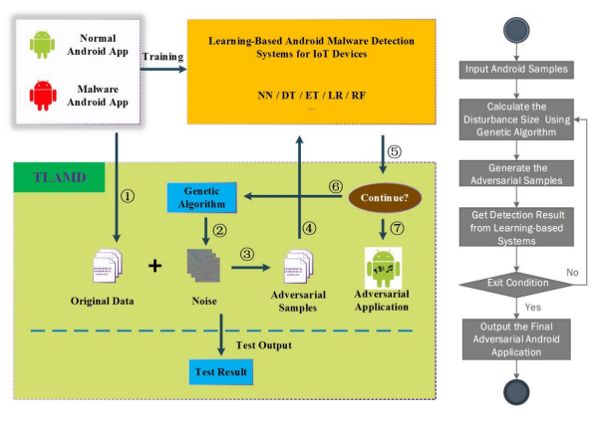
人工智能安全领域的学者和研究人员说,物联网恶意软件检测系统的鲁棒性是非常重要的,因此我们需要一个框架来测试它。鉴于目前生成对抗性样本的方法大多需要训练模型参数,而且大多数都局限于图像数据,研究人员提出了一个基于学习的物联网设备Android恶意软件检测系统(Testing Framework for Learning-based Android Malware Detection: TLAMD)的测试框架,以帮助抵御物联网设备的对抗性样本。
如果框架测试结果显示恶意软件检测系统无法抵御对抗性样本,那么这就说明系统需要加强。TLAMD致力于生成有效的对抗性样本,这是一个没有模型参数知识的测试框架的核心内容。
潜在应用与效果
通过整合遗传算法和特定的技术改进,TLAMD可以为物联网Android应用程序创建具有近100%成功率的对抗性样本,并且支持黑盒系统测试。这对ML安全分析师和开发人员来说是一个好消息,因为该方法显示出了开发用于物联网设备的基于学习的Android恶意软件检测算法的希望和巨大潜力。
原文:
https://arxiv.org/abs/1902.04238v1
在不“丢脸”的情况下实现人脸识别

这一研究提出了一种新的面部识别方法,在保持必要面部特征的高视觉质量的基础上,这一算法可以隐藏其他的面部特征量。该算法基于深度神经网络,不改变原有的人脸也不会合成新的人脸,而是采用预先训练的人脸属性转移模型,将人脸属性映射到多个志愿的人脸供体上,实现了自然的人脸外观,同时保证了合成数据中的身份变化。测试结果中该算法对各种图像和视频数据集均表现优异,证明了模型的有效性。
潜在应用与效果
通过这种新的方法,人工智能研究人员可以放心地在不损失原始数据质量的情况下实现人脸识别,并且仍然可以避免可能的人脸识别诉讼。这也有助于提高计算机视觉应用的水平,因为它可以通过在图像/视频生成过程中引入随机性来提高原始数据集的多样性。此外,该方法还可以扩展到头部姿势变化等领域。
原文:
https://arxiv.org/abs/1902.04202v1
采用时频特性的TiFGAN可有效合成音频
生成对抗网络(GANs)在生成建模方面取得了巨大进展,特别是在图像处理和药物发现领域。然而,它们的用途远远超出这些应用的范围。根据这项研究的结果,我们发现GANs还可用于促进有效的自然发声。
通过对一个GAN进行短时傅立叶特征的训练,研究人员已经证明了其在生成TF建模中的潜力。他们提出了一个基于TF的模型——TiFGAN,它利用GANs学习评估TF表示的质量,从而实现了高质量音频的合成。
TiFGAN已经通过了传统模型的测试。它优于当前最先进的GAN生成波形算法,尽管事实上两者和传统模型都实现了类似的网络结构。TiFGAN的计算成本也很低,在模型训练过程中很有可能简化收敛性评估。
潜在应用与效果
这种新的建模方法消除了音频合成中质量下降和失真的问题,真正展示了GANs中休眠的潜力,可以探索和利用这些潜力生成一次性的完整信号,从而实现更有效的音频合成。而且,如果对抗性时频特性的产生可以应用于音频合成,那么这也意味着人工智能研究界开始了一段新的旅程——试图利用GANs更深入、更有效地与人工智能进行音频合成。
原文:
https://arxiv.org/abs/1902.04072v1
AI黑镜——基于AI技术的人伦小故事
家庭相册
我拿着一张旧的家庭照片。它褪了色,有些地方边缘参差不齐,还有一个角被撕破了,但正因为如此,我更喜欢它了。
这张照片中的我还是一个孩子,在海滩上,那时的我和很多其他孩子正在与一只非常友好的金毛猎犬玩耍,我们只相识了一天,但这一天我却记了很多年。
唯一有问题的是照片中的狗和我的记忆出现了偏差,我记得当时和我一起玩耍的是我们自己家养的棕色拉布拉多。当我拿着照片找到妈妈提问时,她回答道:“当时和你玩的确实是这条狗,其实正是那天看你玩得那么开心,我们后来才开始自己养狗的。”
我想说的是,记忆并不是人们想象的那样。如果你和你的朋友或是家人谈论过去,你会发现不同的人对于同一事件的记忆是不同的,在你有机会将记忆与当年的笔记进行比对从而确定其真实性之前,记忆充其量只是一种指引。
很久以前,人们没有照片(也许有些富有的家庭会有肖像画),那时的人们无从回忆。但是后来,每个人都有了一本家庭相册,也就是从那个时候开始,人们渐渐明白对于过去的记忆只是意见的一种,而这种意见是不同的。
然后,我们有了数码摄影、存储和备份,突然间,过去的一切都变成了真实的过去。我们进入了一个手机摄像头,监视器,甚至人体摄像头的时代。在这个信息爆炸的时代,无论这些信息有多重要,想让足够多的人花足够多的时间来研究这些信息都是不可能的。不过,这种图像信息的爆炸只是短暂的繁荣。
现在我们已经能够自动识别图像中的一个物体或一个人了,这事实上距离推测一个物体或人在图像中的样子已经不远了。如果我们能够在图像中插入它,同时又无法识别一个图像中的物体是不是被插入的,那么在未来,当我们面对图像的时候,这副图像中的任何东西,不管是静止的还是移动的,存储的还是实时的,都不能再被认为是可靠的。
当然,一定会有人声称他们能够分辨出不同之处——也许可以从一些像素上分辨出来——但对于一般人来说,对于图像的看法又变回了一个意见问题。
图像证明一切的时代已经过去了。
我们的孩子会成长于一个图像不可靠、不客观、不永恒的世界。我相信以前一切都很好,以后也会很好。但是对于我们这几代人来说,我们已经习惯了相信我们所看到的,相信事情将永远不会改变。我们把记忆储存在这些东西里,直到这些东西使我们失望。
所以我坐在这里,拿着这些家庭照片,它们太老了,太真实了,任何人都不能操纵或伪造,我正试着通过他们唤醒记忆。我相信它们会一直持续下去……

Christopher Dossman是Wonder Technologies的首席数据科学家,在北京生活5年。他是深度学习系统部署方面的专家,在开发新的AI产品方面拥有丰富的经验。除了卓越的工程经验,他还教授了1000名学生了解深度学习基础。
LinkedIn:
https://www.linkedin.com/in/christopherdossman/
英文报道链接:
https://medium.com/@cdossman/ai-scholar-weekly-4-edb73ea47c12
志愿者介绍
后台回复“志愿者”加入我们