Embedding技术在房产推荐中的应用

本文概览:
1. 房产业务及推荐介绍
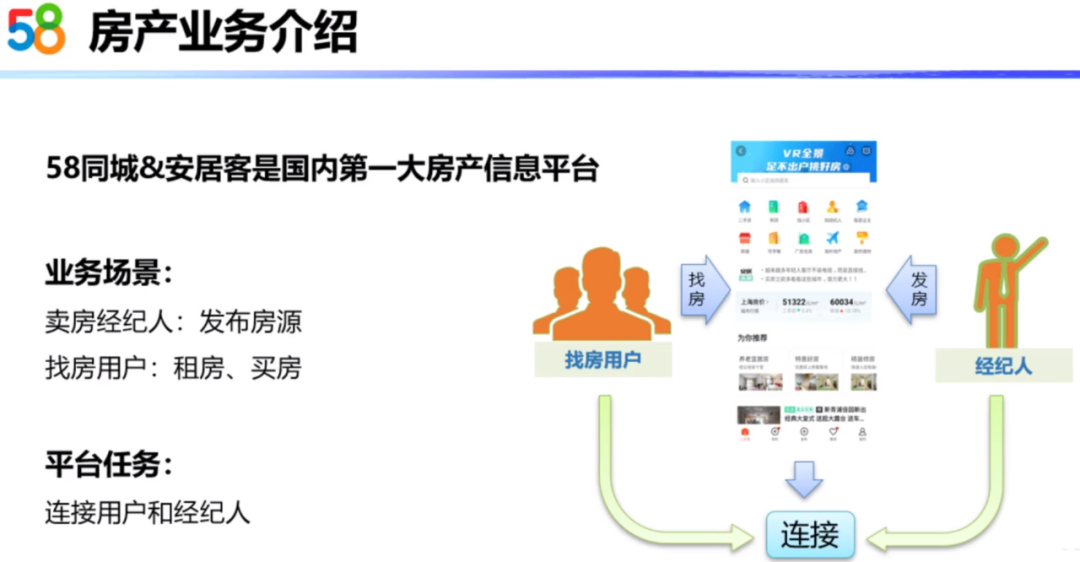
58同城和安居客是国内第一大房产信息平台。作为房产信息平台主要有两种业务场景、两类服务对象。第一类是服务于经纪人,当房产经纪人有卖房需求的时候,可以把房源发布在平台上,平台导入流量进行支持;第二类是服务于找房用户,当用户访问平台的时候,可以浏览到丰富的房源。58同城平台的主要是连接起用户和经纪人,帮助用户找到满意的房子,帮助经纪人卖掉手里的房子。
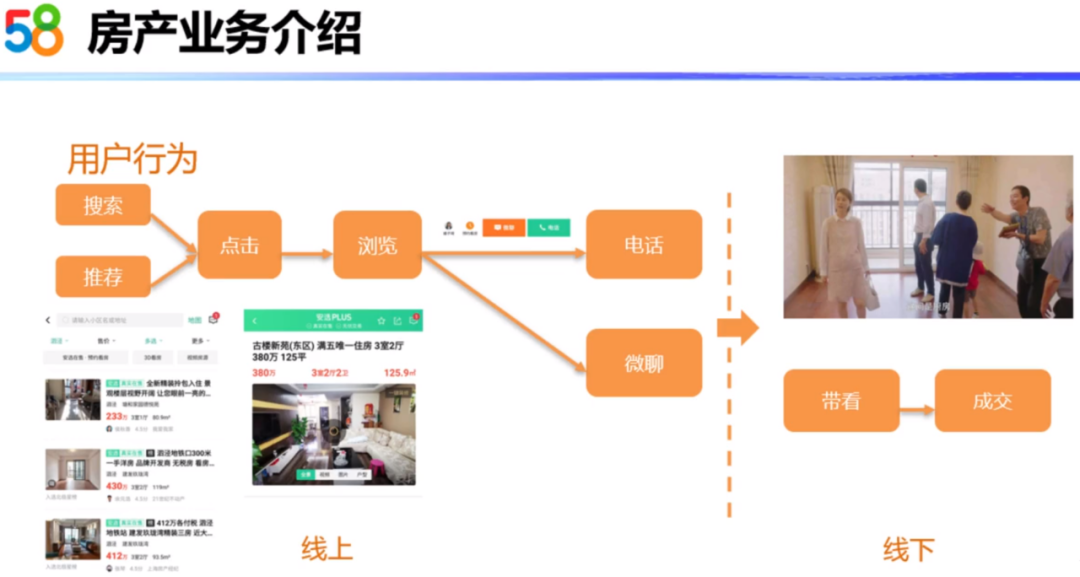
58平台的推荐主要针对的是找房的用户,所以这里重点介绍一下找房用户的行为。当用户有找房需求的时候,可以在房源列表页按照自己的需求进行搜索和筛选房源。同时可以在推荐位浏览到平台推荐的房源,当看到符合自己需求的房源时,可以点击帖子,进入到房源的详情页。如果房源详情页的信息符合自己的找房需求,就可以通过电话或微聊的形式联系发布房源的经纪人。上述的这些行为属于用户的线上行为。当用户和房产经纪人联系后,经纪人可以带着用户看房。如果合适的话,进行最终的成交。这些是属于用户的线下行为。
目前,58技术只能获得用户的线上行为数据,所以后续用于推荐模型的数据主要有用户的点击数据和电话微聊数据。
58房产相关推荐位还是比较丰富的。不同的位置,推荐逻辑也有很大的差异。这里以安居客为例,列举了安居客的5个主要推荐位。第一个场景是首页的推荐位,对于进入首页的用户,先判断用户的类型,或者是判断用户来安居客的目的,是找二手房还是看新房或者是租房,真的这些不同的用户推荐不同的房源。第二个场景是默认列表页,在默认列表页用户已经选定了房产类型,这里针对用户的历史行为给用户推荐一些房源。针对新用户的话,我们会使用当前的经纬度推荐一些附近房源或者是热门房源,进行新用户的冷启动。第三个场景是零少结果页,对于零少结果页,我们是可以拿到用户的筛选条件,这时会针对用户的筛选条件做一些相关方面的推荐。第四个场景是房源单页(房源详情页),对于房源单页其实用户已经对这个页面的房产信息感兴趣,这里的“看了又看”主要是推荐当前房源的相似房源。第五个场景是推荐频道,推荐频道主要是用到了Feed流的技术,推拉结合,把用户感兴趣的最新房产信息推荐给用户。
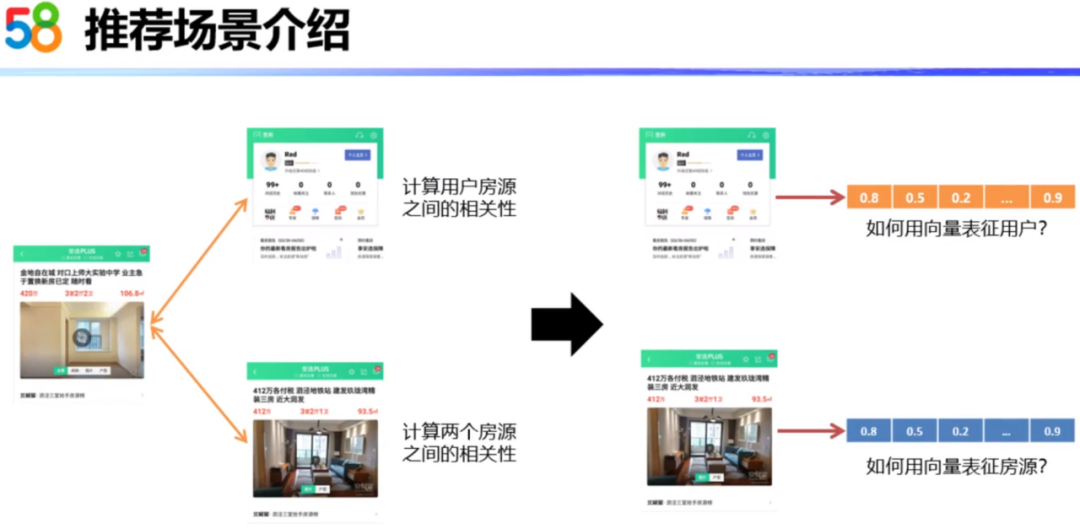
上面介绍了五种不同的推荐位,其实在这些推荐场景中都离不开两类相似性的计算。一类是用户和房源之间的相关性,另一类是两个房源之间的相关性。具体该怎么计算这两类相关性呢?我们首先需要把房源和用户这两个实体用向量表征出来,然后通过计算向量的差异,衡量用户和房源、房源和房源是否相似。
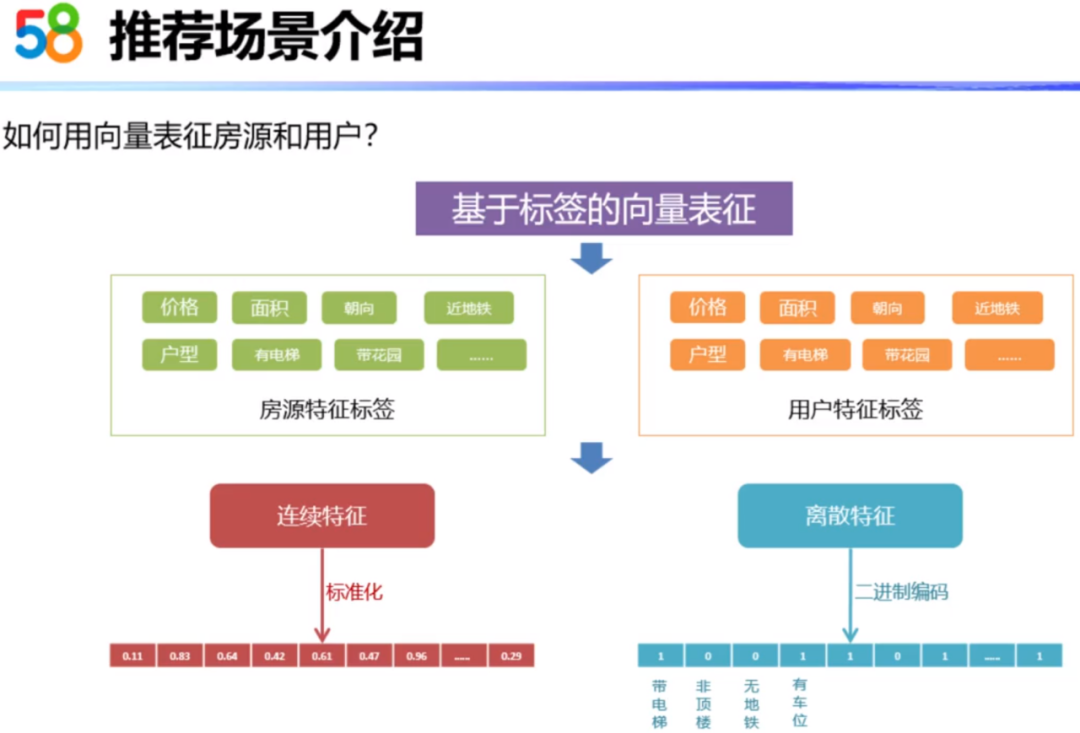
对于房源和用户的向量表征可以分为两类:第一类是基于标签的向量表征,第二类是基于关系的向量表征。
基于标签的向量表征是比较好处理的。比如,对于某个房源有对应的价格、面积、朝向等特征标签;同样的,对于用户也有自己的兴趣偏好,比如价格、面积、近地铁等特征标签。因为用户在选房子的时候,有自己的选择标准,比如价格、户型等,我们可以把房源的标签信息打到用户身上,这样用户也有自己的偏好特性标签。针对这些特征标签的连续型特征,我们可以直接标准化后作为连续型特征标签向量的值。离散型特征可以直接进行二进制编码,加入特征向量里面。
基于标签的向量表征的优点是实时性好。比如来了一个新房源,我们就可以很容易将房源的属性转化为房源的标签向量。基于标签的向量表征的缺点是:计算相关性时是基于现有的标签,没有自适应的能力,或者是学出新标签的能力。
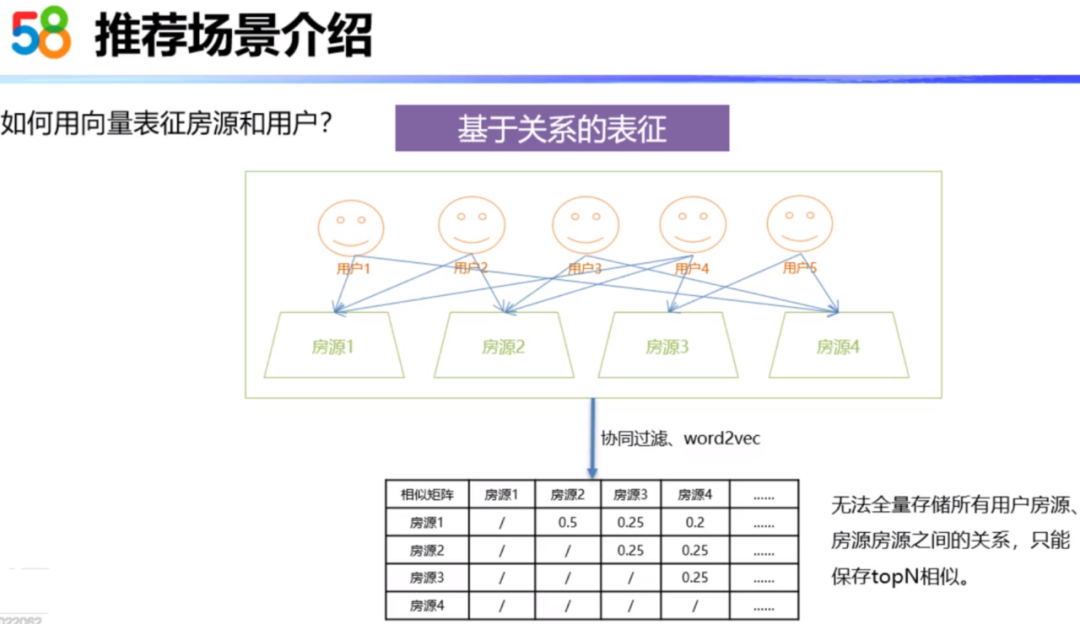
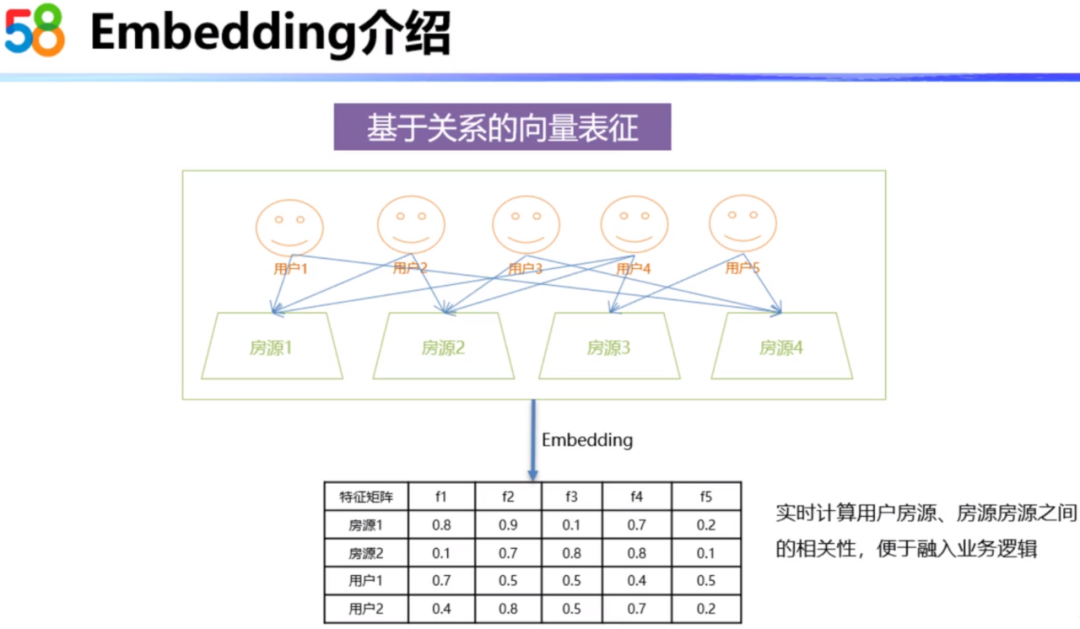
基于关系的表征其实是使用了群体智慧,它有很强的自适应能力。比如看下图,用户和房源之间的关系。对于用户2和用户4,他们同时看了房源1和房源2,这就说明房源1和房源2存在某种潜在的关系,这种关系可能是他们的价格相同、在同一个小区或者是有相同的对口学校,也有可能是其它内在的联系。所以,基于关系的推荐可以有效的挖掘出用户和房源、房源和房源之间的潜在联系。
基于关系的表征一般使用的方法是协同过滤、Word2Vec。基于关系的表征一般是使用相似度表进行保存。由于相似度表无法全量保存用户与房源、房源与房源之间的关系,只能保存TopN的相似度。这种存储实际上会存在一些问题,比如在零少结果的场景,根据用户的搜索标签是可以召回一批房源的,但是这个召回房源可能与用户TopN的相似房源交集比较小,所以在召回的大部分房源中很难引入关系特征。因此就需要引入Embedding的思想,来对关系进行量化。
2. Embedding介绍
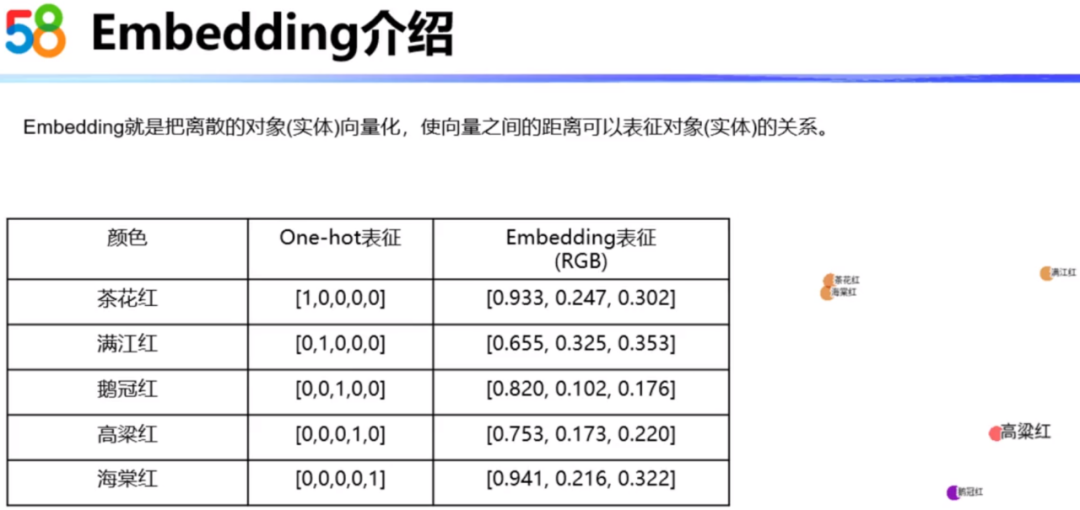
Embedding概念介绍:Embedding就是把离散的对象(实体)向量化,使向量之间的距离可以表征对象(实体)的关系。
比如下图中的例子,有五种颜色,总体来说的话都是红色,但对于我们大多数人来说对这些红色是没有概念的,也不清楚哪些红色是比较相近。如果我们知道这些颜色的RGB值,就可以轻松的了解这些红色之间的关系。我们通过RGB值知道,茶花红和海棠红这两个颜色是比较相近的。其实颜色的RGB值可以简单的理解为对颜色这种实体的Embedding。
那具体有哪些方法可以Embedding呢?我们下面会举三个例子。
2.1 协同过滤矩阵分解-ALS
我们可以使用ALS进行Embedding,ALS是通过矩阵分解实现的协同过滤。使用ALS我们需要构建一个评分矩阵,比如下图所示的例子,User1对汤臣一品的打分是4分,对上海康城的打分是3分,未对耀华路550弄打分。User2对汤臣一品的打分是1分,对上海康城的打分是3分,对耀华路550弄打分是4分。这是一个 的评分矩阵,我们通过ALS算法可以把它分解成一个 的矩阵和一个 的矩阵。 的矩阵就是一个用户矩阵, 的矩阵就是一个物品矩阵。
我们怎么来求解这两个矩阵呢?首先,我们可以对用户矩阵随机的赋值,其次使用最小二乘法得到物品矩阵的值,然后固定物品矩阵的值通过最小二乘法再求解用户矩阵。通过这种交替使用最小二乘法的方法可以使这两个矩阵数值逐渐趋于平稳,这个时候我们可以认为评分矩阵就是用户矩阵和物品矩阵的乘积。
通过下图我们可以看到,用户矩阵和评分矩阵都有“豪华指数”和“刚需指数”这两个维度。当然这两个维度的表述是我们在矩阵分解完成之后,人为总结的。其实,用户矩阵和物品矩阵可以理解为针对用户和房源的Embedding。从用户矩阵中可以看出,User1对豪宅的偏好度比较高,所以他对耀华路550弄不太感兴趣。同时,从物品矩阵中可以看出,汤臣一品和上海康城的相似度应该是大于汤臣一品和耀华路550弄的相似度。

2.2 Skip-gram
Embedding的第二种方法就是使用自然语言处理中的Skip-gram算法进行向量表征。首先,我们将用户浏览、关注、微聊、电话等行为对应的房源汇总成一个房源序列,这样一个用户的行为序列就相当于一个句子,序列中的房源就相当于词。Skip-gram算法认为相邻的房源是有相关性的房源。这些房源的相互关系可以作为正样本。比如下图中的7、6、8、3、5序列,8和7、6、3、5都可以认为是有正相关性的。然后,我们现在有了一些正样本,可以随机抽取一些出现频率比较高、但是不相邻的房源作为负样本。
这里的模型结构主要有三层。输入层的输入就是房源的One-Hot表示。其次通过输入层的参数矩阵W转化为隐层固定维度的向量。然后隐层固定维度的向量乘以输出矩阵参数 ,就可以转化为输出值。在输出层这里,我们没有使用Softmax函数,因为这里加入了负采样,不需要计算目标词和所有词之间的相似度,所以这里就使用Sigmoid函数,计算目标词和正负样本之间的相似度,然后对比真实的标签构造损失函数。
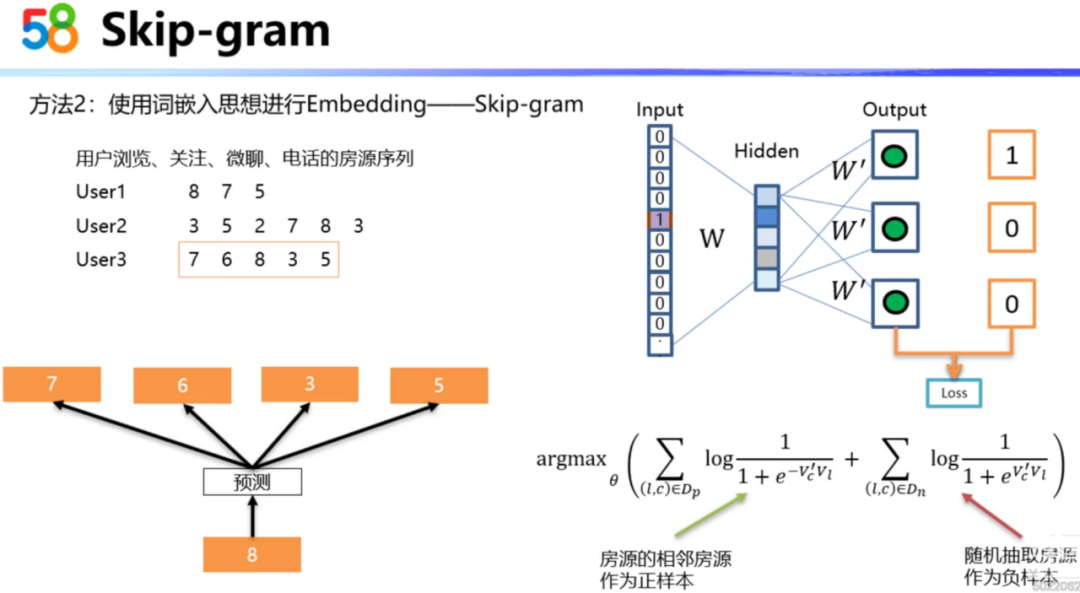
上图中的公式即为转化后的目标函数。我们需要通过参数优化来极大化这个目标函数,当c为 的正样本时, 的输入向量和c的输出向量的内积要尽量的大;当c为 的负样本时, 的输入向量和c的输出向量的内积要尽量的小。我们可以通过随机梯度上升来求解模型的参数。
2.3 DeepWalk
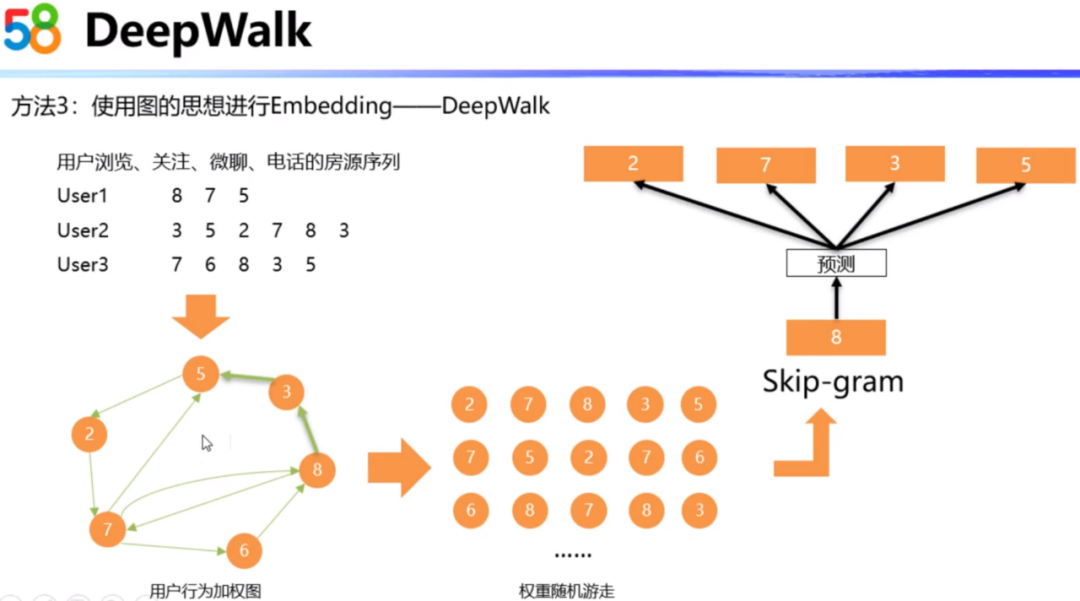
第三种方法是通过使用图的思想进行Embedding。我们针对Skip-gram方法中的用户行为,可以将用户的房源序列抽象为有向带权图,然后轮流以每个结点为出发点,根据权重做随机游走,这样就可以形成新的房源序列,最后对这些不同的房源序列继续使用Skip-gram模型,得到不同的房源的Embedding向量。
2.4 三种Embedding效果展示
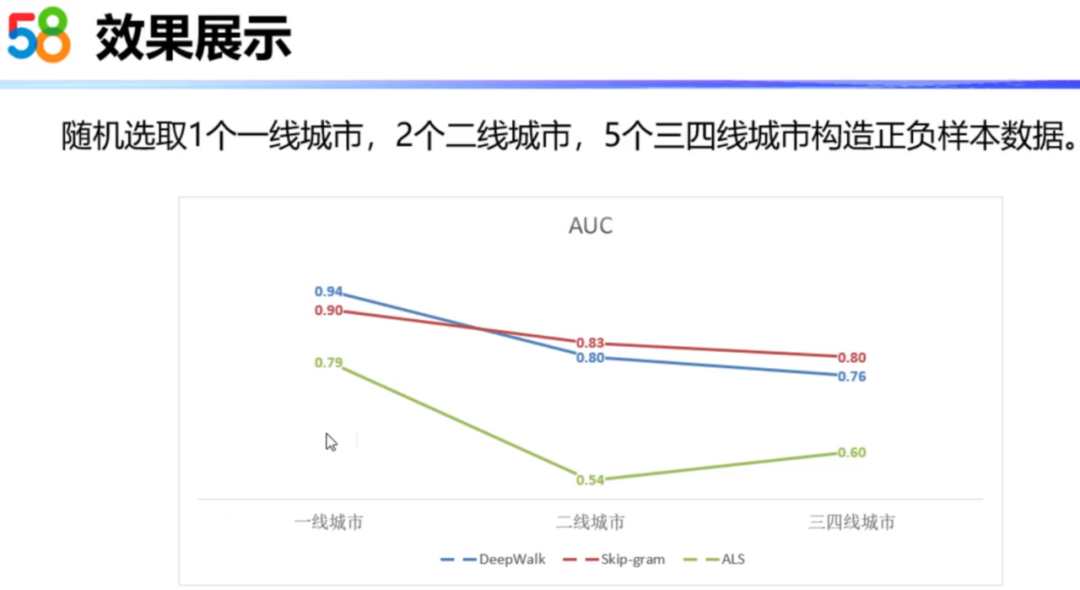
下图是三种Embedding的效果展示,使用了T-SNE进行了降维,不同的颜色代表不同的区域。分的比较清楚的区域,是当前城市比较偏远的区域,这些区域跟其他区域重叠的可能性比较少,所以他们可以分的比较清晰。对于这些重叠的区域,是当前城市的中心区域或者是相邻的区域,由于交通比较便利,用户在找房的时候,这几个区域都在看,所以在颜色上有比较大的交叉。

上图不太能直观的展示出哪种Embedding效果好,这里我们构造出了一批正负样本,通过样本数据的AUC值,来评测样本Embedding的效果。这里的正样本取的是共现次数比较多的房源对,取了没有共现的高频房源作为负样本。从下图结果可知,DeepWalk在一线城市效果还是比较好的,可能因为这一块用户量比较大,对于DeepWalk模型可以得到充分的训练,可以随机游走出一些比较好的房源序列。在二线城市和三、四线城市的话,Skip-gram算法要优于DeepWalk算法,可能是因为小城市数据量比较少,所以DeepWalk差一些。对于ALS,它在一线城市的效果还不错,但是到了二线城市和三、四线城市降低了很多,应该还是由于打分矩阵过于稀疏,无法做一个很好的训练。
通过以上列举的三种方式,我们可以将用户和房源之间的关系进行向量化。通过计算向量的余弦相似度,就可以实时计算出用户和房源之间的相似度了。这样我们可以将基于关系的推荐不仅用在房源的召回阶段,也可以用在精排阶段作为一部分输入数据。
3. Embedding应用
3.1 Skip-gram模型应用
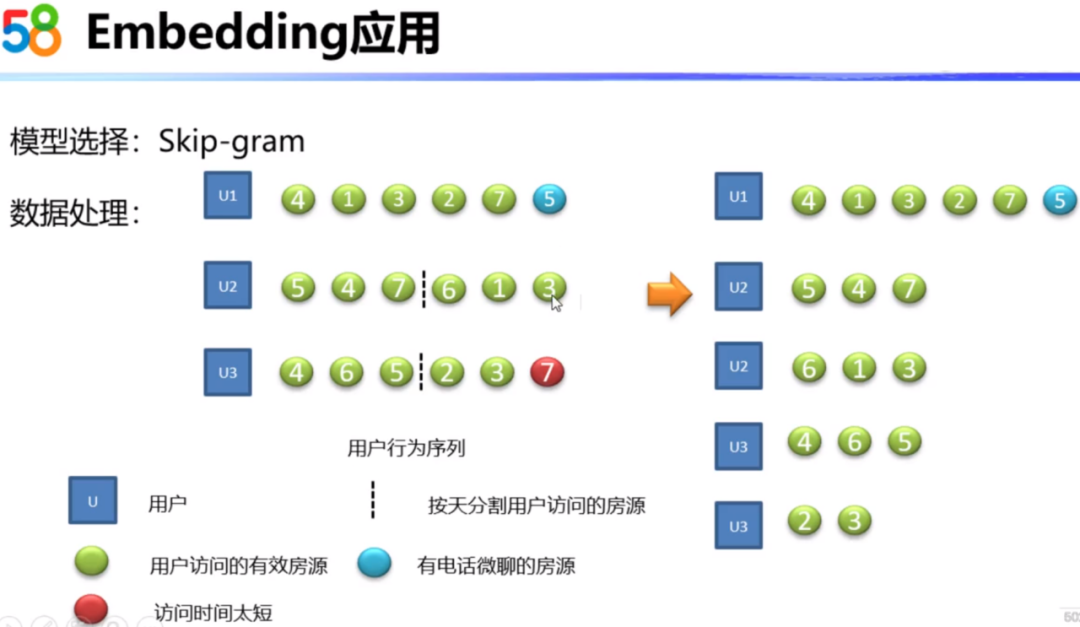
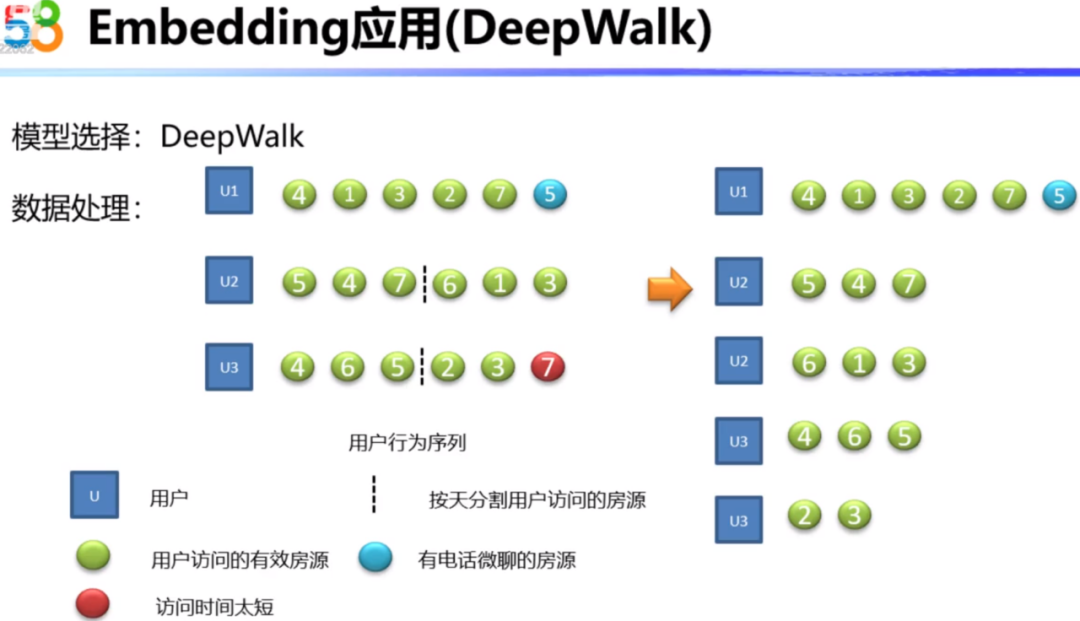
下面就详细介绍Embedding技术在线上的具体应用。首先我们需要对数据进行预处理。这里我们区分了一下房源和用户之间的关系,对于这种只有访问的房源,点击关系是一种弱关系,下图中用绿色表示。电话和微聊是一种强关系,下图用蓝色表示。同时会去掉一些用户停留时间比较短的房源,这些可能是用户的误触。对于一个用户多天的行为序列,会进行按天的分割,因为隔两天的用户浏览房源数据差异就比较大了,会影响模型的计算。经过处理可以得到下图右边的房源序列。
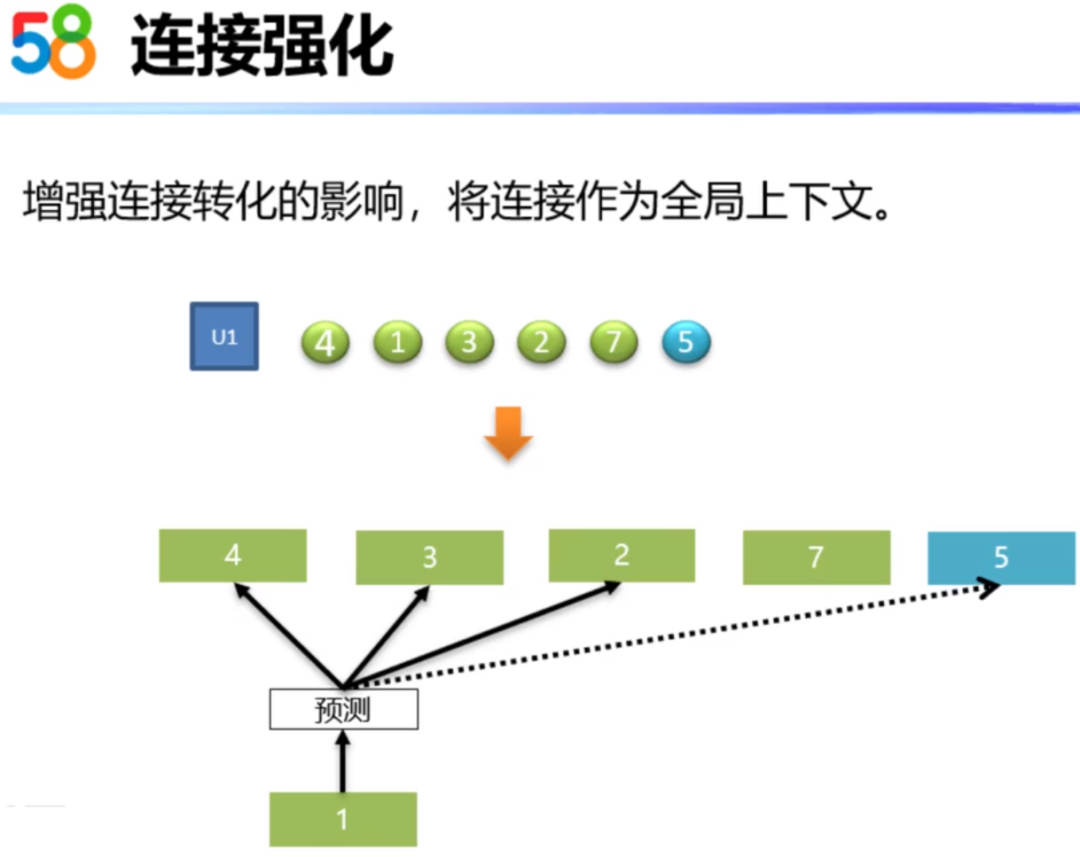
我们参考了Airbnb在2018年发表的Embedding在实时搜素排序中的论文《Real-time Personalization using Embeddings for Search Ranking at Airbnb》。我们这里为了增强连接转化的影响,也把用户有电话微聊等连接行为的房源,作为一个房源序列的全局上下文进行训练。
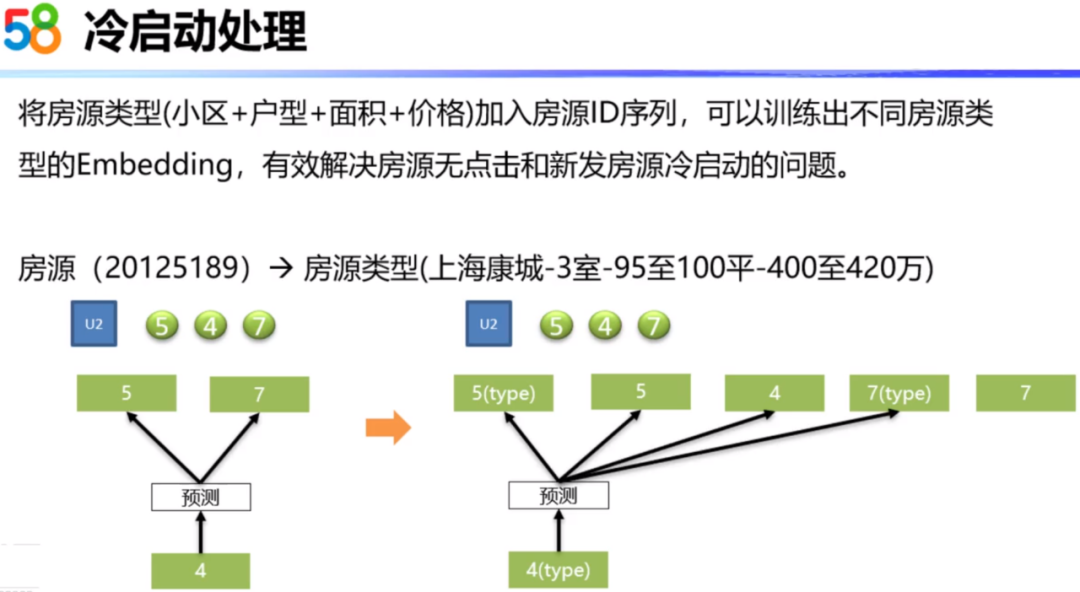
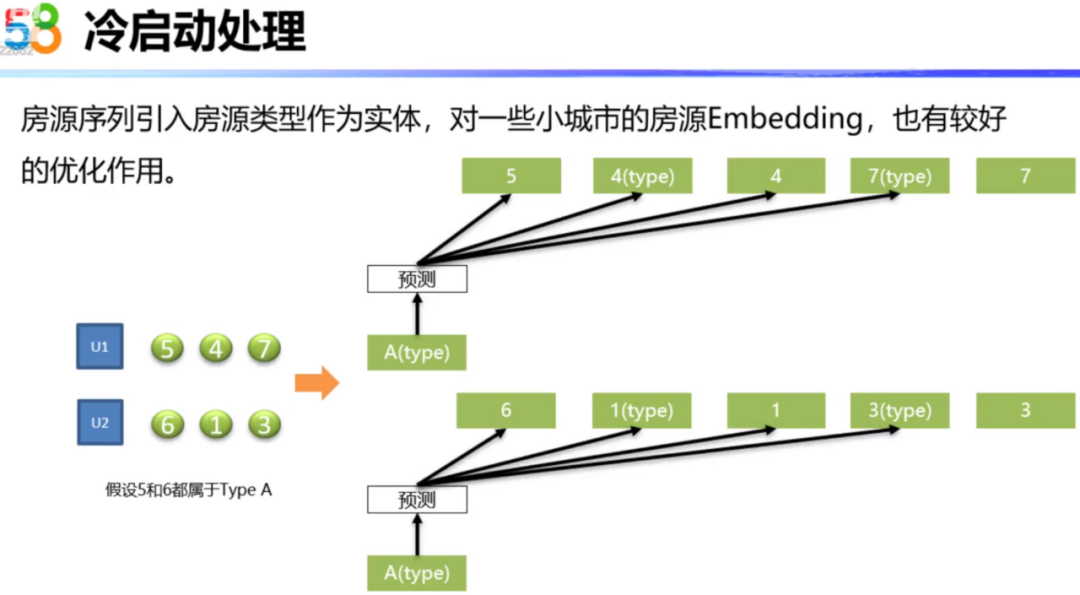
为了解决冷启动的问题,在房源序列中加入了房源的Type类型。比如下图所示的房源,它对应的Type类型为:上海康城小区、户型为3室、面积为95至100平、价格为400万至420万。在训练时通过加入这种Type类型我们得到房源Embedding的同时,也可以得到类型房源的Embedding。当一个房源没有算出具体的Embedding向量时,我们就可以利用这个房源对应的类型向量进行补充。这里把房源对应的类型放在了房源前面,其实也是有一种思想在里面,我们可以认为在用户的看房行为中,用户首先看到了房源列表页的房源信息描述,表示用户对这种小区、户型、面积和价格的组合特征感兴趣了,才点击进入房源的详情页面。所以,用户先有了对房源类型感兴趣,才点击到房源详情页,这是有先后关系的。
同时引入房源类型作为实体之后,对于一些用户比较少、房源序列比较少的小城市的房源Embedding有比较好的优化作用。比如,下图中用户U1看了5、4、7,用户2看了6、1、3,如果在其它的房源序列中没有出现5和6共现的情况,这个时候Embedding就无法学到房源5和房源6之间的关系,但是我们引入了房源Type类型,通过引入5和6的Type类型都是A,这样可以有效的知道房源5和房源6是有一定相似性的。
这里可以思考一个问题:类型标签的引入是否会有标签泄露的问题,我个人觉得,相同的小区、户型、面积和价格的特征组合下的房源相似度很高,这其实是房产业务中的专家逻辑,在这里加入这种专家逻辑,可以更好的帮助Skip-gram进行Embedding的训练。
3.2 DeepWalk模型应用
通过之前的实验,我们知道DeepWalk在数据充足的情况下Embedding的效果要好于单纯使用Skip-gram,所以在大城市我们会用DeepWalk进行Embedding。这里我们还使用前面提到的数据清洗和预处理方法。
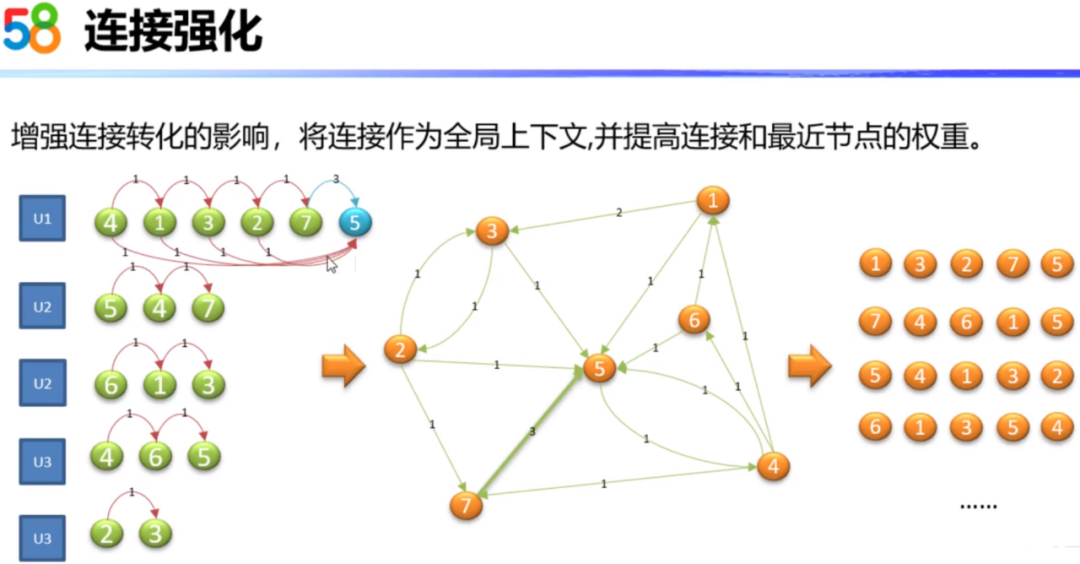
同样地,为了增加连接转化的影响,我们将连接作为全局的上下文,并且提高最近结点的权重。从下图中可以看出,U1用户的房源序列中房源5是连接结点,这样就把4到5、1到5、3到5、2到5都加了转化权重1。7到5由于它们最近,所以转化权重设置为3。通过这样的转化,我们可以得到图中的有向带权图,然后通过随机游走构造出新的房源序列。
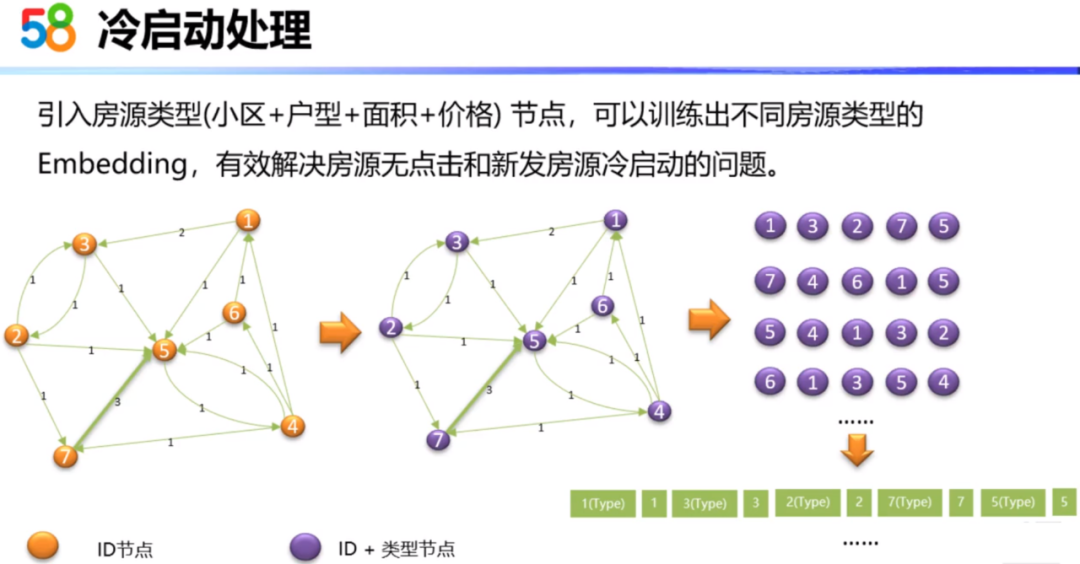
同样地,这里引入Type类型,我们将ID结点的图转化为ID加类型的图。然后通过随机游走,得到ID加类型的序列。图中绿色序列就是房源1类型、房源1ID、房源3类型、房源3ID...。
3.3 EGES应用
上面提到的在房源序列中引入房源类型的做法,是需要先指定好房源的特征组合,这样会造成可扩展性不强。目前,我们也在尝试使用阿里的EGES进行Embedding。这里的SI0(Side Information 0)代表房源本身的ID,后边的SI1,...,SIn代表不同类型的属性。不同的房源属性都有不同的输入矩阵,便于计算出不同属性的权重进行组合,这样每个属性都有自己的向量,也可以解决新房源冷启动的问题。
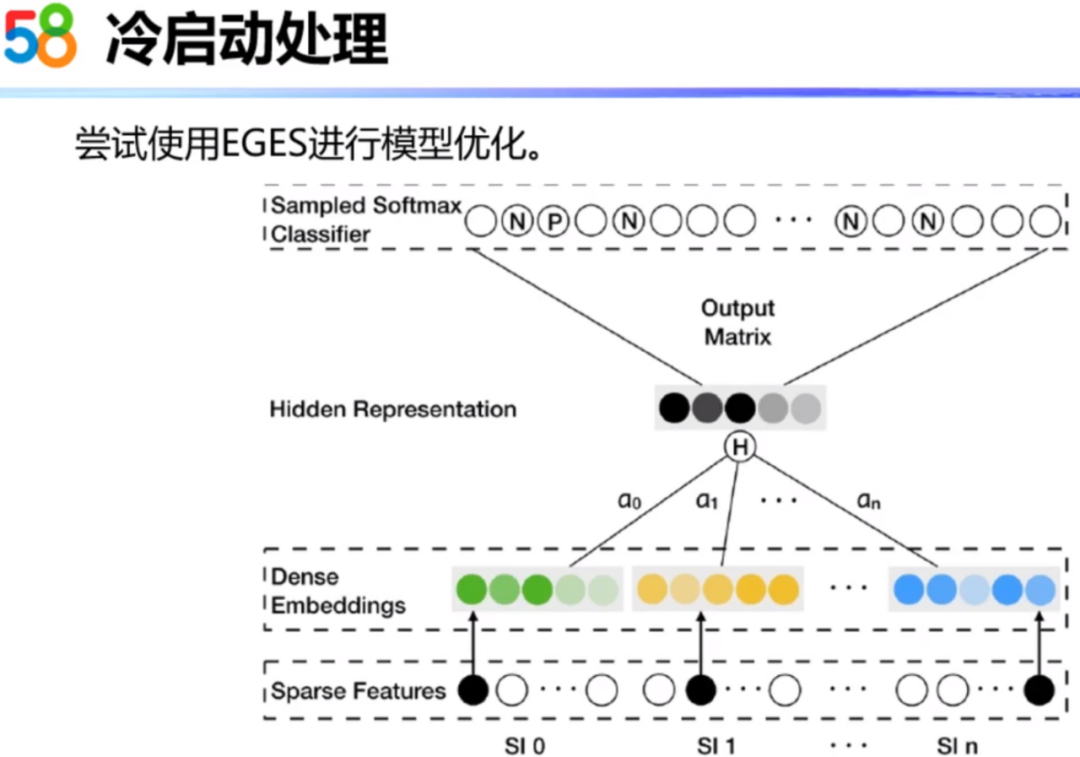
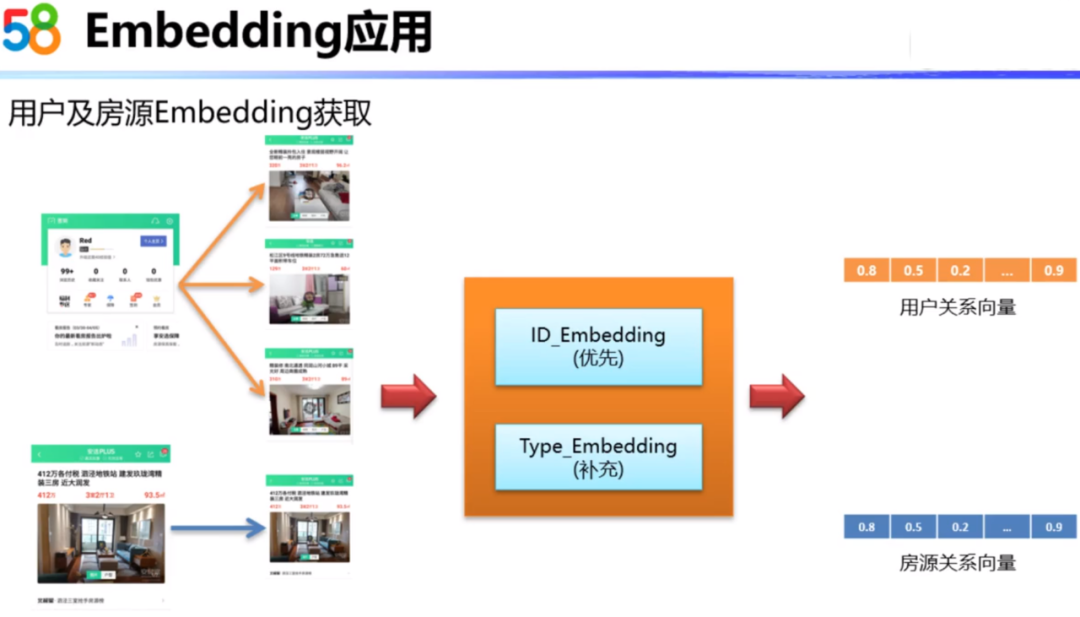
3.4 获取用户及房源的Embedding
我们计算好房源的Embedding之后,对于用户可以汇总用户看过的房源向量,计算出用户的Embedding向量。针对房源的Embedding,我们可以优先拿对应ID的Embedding向量,当ID的值没有取到时,可以使用Type_Embedding向量。这样我们就可以得到用户关系向量和房源关系向量。
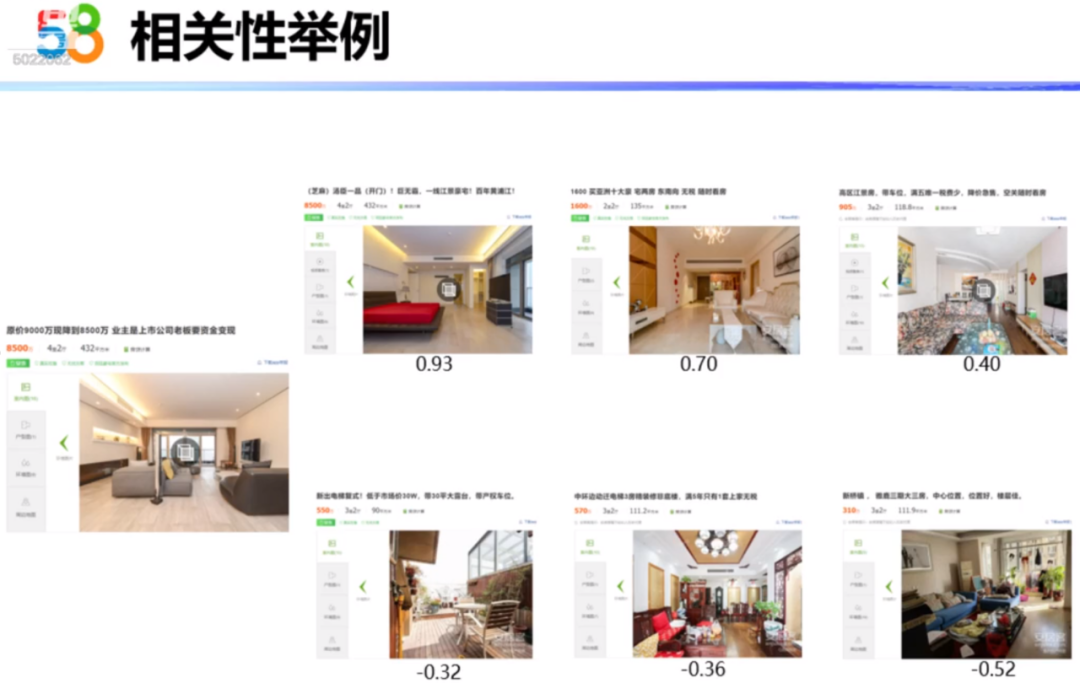
下图展示了相关性的举例。随着相似度的减小,房源的价格、面积和位置差异会越来越大。所以,我们得出的Embedding还是有一定的效果。
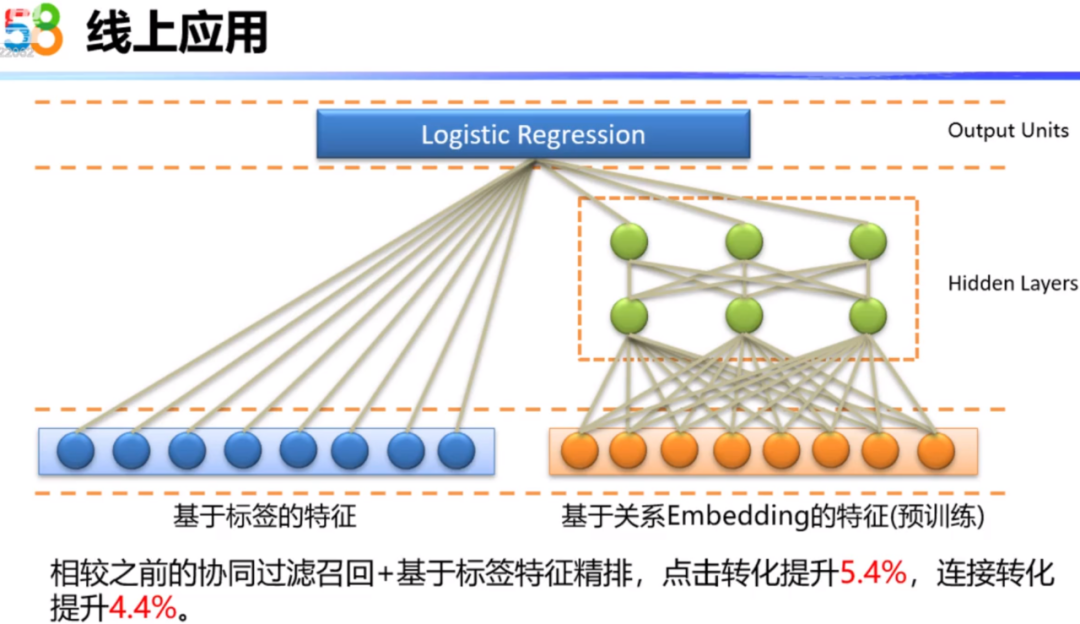
3.5 Embedding线上应用
下图展示了线上应用的效果。我们通过标签特征的处理和关系特征的Embedding,可以得到一个综合的输入向量来表征用户和房源之间的关系,最后构建一个综合的监督模型来训练这种关系之间的相似度。为了提高连接率,我们把有连接行为的用户房源对作为正样本,对于只浏览不连接的用户房源对作为负样本。我们就使用了Wide&Deep模型进行了训练,在Wide部分使用了基于内容的标签特征,Wide部分主要负责模型的记忆能力;Deep部分主要负责模型的泛化,使用基于关系的Embedding进行深度学习,通过深度模型的计算可以学习出隐含的特征组合,提高模型的泛化能力。这个模型相较于之前的协同过滤召回+基于标签特征精排,点击转化提升5.4%,连接转化提升4.4%。它对于业务的兼容性也大大提高,在零少结果场景的推荐,在精排阶段可以使用这种关系的相似度。
3.6 Embedding应用总结
我们来对Embedding应用进行总结。

4. Embedding相关问题解答
(1)Embedding在推荐中的应用,对连续特征要不要和离散特征一样进行Embedding处理呢?
连续特征已经可以从本身的数值评估不同实体之间的相关性了。一般情况下,不需要进行Embedding处理。但是也有一些特殊的场景是需要的,比如,在某种场景下,可能20岁的用户和40岁的用户的相关性大于20岁和30岁的相关性,这个时候就需要Embedding的处理。
(2)连续数据Embedding的方法?
对于连续变量的Embedding,需要对特征进行分桶或分箱。
(3)跨业务Embedding应用?
根据点击构造序列。因为基于关系的相似性计算,不需要考虑业务类型的标签差异。如果要使用DeepWalk的话,可以在结点跳转的时候,对业务进行一些加权。
5. Reference
本文是Microstrong在观看58同城资深算法工程师周彤在DataFunTalk公众号分享的《Embedding 技术在房产推荐中的应用》视频的笔记。
【1】Embedding 技术在房产推荐中的应用,地址:https://mp.weixin.qq.com/s/m6ZRfxzJIVXoQEWUK9O5Jg
【2】 Embedding技术在58商业的探索与实践,地址:https://mp.weixin.qq.com/s/XanNsacqzkywtKYlVUexSg
【2】浅谈Embedding技术在推荐系统中的应用(1),地址:https://mp.weixin.qq.com/s/07I6vQ-6z1_-useYYBVwyg
【3】Embedding 模型在推荐系统的应用,地址:https://mp.weixin.qq.com/s/sKHFD3XZ4HZOeZ4wqc-rMA
【1】Embedding向量召回在vivo个性化推荐中的实践,地址:https://mp.weixin.qq.com/s/-QqvrNwEUk4haX8xfbd06g
推荐阅读
百度PaddleHub NLP模型全面升级,推理性能提升50%以上
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。