![]()
来源:嘉数汇
ID:Datahui
![]()
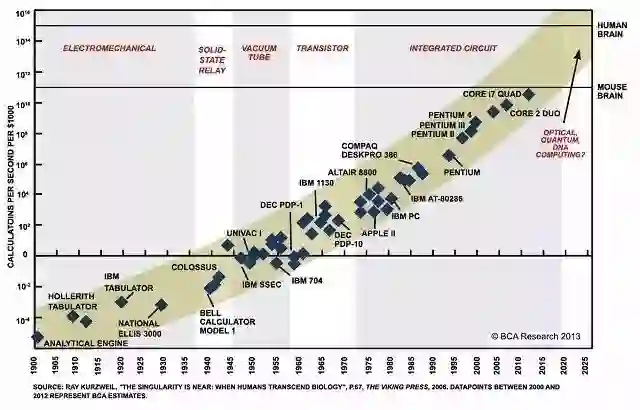
概要:在计算机时代,有个著名的摩尔定律,就是说同样成本每隔18个月晶体管数量会翻倍,反过来同样数量晶体管成本会减半。
作者: 同济大学,电信学院 王伟
在计算机时代,有个著名的摩尔定律,就是说同样成本每隔18个月晶体管数量会翻倍,反过来同样数量晶体管成本会减半,这个规律已经很好地吻合了最近50年的发展,并且可以衍生到很多类似的领域:存储、功耗、带宽、像素。
两年前的这个月是摩尔定律发表50周年,整整半个世纪。当时IEEE Spectrum为了纪念摩尔定律50周年,特地发表了四篇关于摩尔定律的文章。其中一篇的题目叫“Moore’s Law is Dying (and That Could Be Good)”,说的是摩尔定律不可能继续下去了。
1965年微芯片上的元件数增加了1倍,Gordon Moore于是预言这一趋势近期内将继续。1975年他修改为每两年翻一翻,后来又说是18个月,或者说按指数律增长,每年46%。这就是摩尔定律。摩尔定律预言了半导体产业50年的发展。摩尔预言了一个光辉的未来,改变了世界。
![]()
这样高速的增长在其他产业是见不到的。美国的主粮玉米从1950年以后平均产量每年增长2%,蒸汽涡轮式发电机把热能转换为电能,其效率在20世纪年增长率为1.5%,而1881-2014室内灯光有效性(流明每瓦)年平均增长2.6%,而室外为3.1%。1900年洲际旅行用远洋客轮每小时走35公里,而1958年用波音707每小时885公里,平均每年提高5.6%,但这速度基本保持不变,即使是波音787也和707差不多。1973-2014汽车燃油的换能效率年平均提高2.5%。所以,半导体产业这50年的特殊高速增长是特例,以后不可能保持的。这并不奇怪!
当元件越来越小、越来越密、越来越快、越来越便宜,增加了功耗,切割了许多产品和服务的成本,特别是计算机和数字相机,也包括发光二极管和光电管,这是电子、光和太阳能时代的革命。
摩尔定律这种指数级增长规律使得大多数的人们理解起来相当困难。人类的感知是线性的,但技术的发展是指数型的。我们的大脑固守着线性的期望,因为这是它过去累积的经验。然而今天的技术进展日新月异,过去与今天不能同日而语,而今天也永远赶不上未来的步伐。于是,我们突然间发现,自己身处一个完全意想不到的世界里。技术将会逼近人类历史上的某种本质的奇点,在那之后全部人类行为都不可能以我们熟悉的面貌继续存在。这就是著名的奇点理论。
由于对技术进步高度预期的非预期效应,人们相信技术进步将很快催生自驾驶电动汽车、特超音速飞机、私人定制的癌症治疗、心脏和肾脏的3D打印,世界将从石化到再生能源。但是,晶体管翻倍的这段时间并没有引领人类文明的技术进步。现代生活依赖于许多过程,有待改进,特别是食物和能量的生产和人货的运输。许多历史数据说明这现实,譬如晶体管的第一个商业应用是1952年的助听器,微处理器占据着整个20世纪,甚至更长。
摩尔定律的奇点效应从CPU、GPU、FPGA,一直到今天Google所提出的TPU,虽然没有完全显现,但都似乎预示着这一天的即将到来。
1、摩尔定律的崛起:CPU
大家最熟悉的就是中央处理器(Central Processing Unit),简称CPU。它是一种超大规模的集成芯片,而且是一种通用芯片,也就是说,它可以用它来做很多种类的事情。我们日常使用的电脑使用的处理器基本上都是CPU,看个电影、听个音乐、跑个代码,都是可以的。
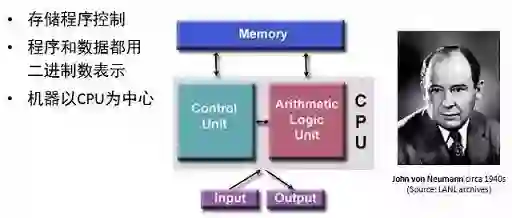
CPU主要包括运算器(ALU)和控制器(CU)两大部件。此外,还包括若干个寄存器和高速缓冲存储器及实现它们之间联系的数据、控制及状态的总线。ALU主要执行算术运算、移位等操作、地址运算和转换;寄存器件主要用于保存运算中产生的数据以及指令等;CU则是负责对指令译码,并且发出为完成每条指令所要执行的各个操作的控制信号。
![]()
CPU的冯•诺依曼结构
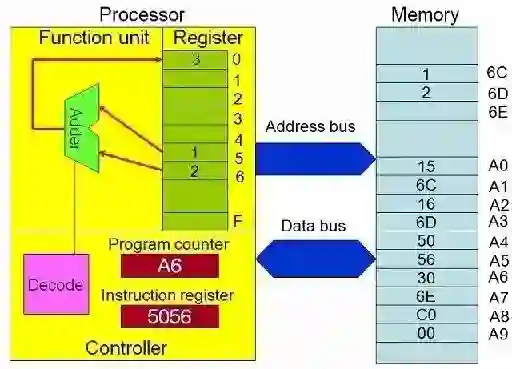
CPU的运行严格遵循着冯•诺依曼结构,其核心原理是:存储程序,顺序执行。整个执行过程大致如下:CPU根据程序计数器(PC)从内存中取到指令,然后通过指令总线将指令送至译码器,将转译后的指令交给时序发生器与操作控制器,再从内存中取到数据并由运算器对数据进行计算,最后通过数据总线将数据存至数据缓存寄存器以及内存。
![]()
CPU就像一个有条不紊的管家,我们吩咐的事情总是一步一步来做。但是随着摩尔定律的失效,以及人们对更大规模与更快处理速度的需求的增加,CPU越来越难以应对现实需要了。
摩尔定律不是一个科学定律,而是产业发展的一个预言,一定有时效性。集成度增加以后,漏电流增加,散热问题大,时钟频率增长减慢,无法提高。线宽到2020-2030约为5纳米,相当于10个硅原子的空间。不管怎么样,总会有物理极限。晶体管数是翻倍了,但应用并没有翻倍。
于是人们就想,我们可不可以把好多个处理器放在同一块芯片上,让他们一起来并行做事,这样效率就会提高很多,于是多核和GPU技术就诞生了。
而第二条路就是保持芯片不变,而在智能上创新,要在应用系统里面加智能,取得计算上的收益。这就给创新提供了足够的空间,并且延缓了摩尔定律的矛盾。随着大数据时代的崛起,以人工智能为导向的各种各样的智能应用系统越来越多。并且很多软件提供商和互联网公司都开始自己做适合本公司业务的全套硬件,例如微软利用FPGA开展其业务,以及Google新近推出的TPU。
2、摩尔定律的延续:GPU
GPU英文全称Graphic Processing Unit,中文翻译为“图形处理器”。GPU是相对于CPU的一个概念,由于在现代的计算机中(特别是家用系统,游戏的发烧友)图形的处理变得越来越重要,需要一个专门的图形的核心处理器。因为对于处理图像数据来说,图像上的每一个像素点都有被处理的需要,这是一个相当大的数据,所以对于运算加速的需求图像处理领域最为强烈,GPU也就应运而生。
![]()
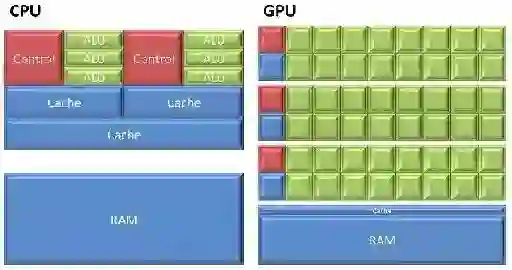
CPU与GPU结构对比示意图
CPU功能模块很多,能适应复杂运算环境;而GPU构成则相对简单,大部分晶体管主要用于构建控制电路(比如分支预测等)和Cache,只有少部分的晶体管来完成实际的运算工作。因此,GPU的控制相对简单,且对Cache的需求小,所以大部分晶体管可以组成各类专用电路、多条流水线,使得GPU的计算速度有了突破性的飞跃,拥有了更强大的处理浮点运算的能力。
当前的主流CPU一般只有4核或者6核,模拟出8个或者12个处理线程来进行运算;但普通级别的GPU就包含了成百上千个处理单元,高端的甚至更多,这对于多媒体计算中大量的重复处理过程有着天生的优势,同时更重要的是,它可以用来做大规模并行数据处理。
因此,虽然GPU是为了图像处理而生的,但它在结构上并没有专门为图像服务的部件,只是对CPU的结构进行了优化与调整,所以现在GPU不仅可以在图像处理领域大显身手,它还被用来科学计算、密码破解、数值分析,海量数据处理,金融分析等需要大规模并行计算的领域。所以GPU也可以认为是一种较通用的芯片,又叫做GPGPU,这里GP就是通用(General purpose)的意思。
普通人知道GPU的概念往往通过三个渠道:游戏、比特币和深度学习。
特别是近几年大热的深度学习,让包括NVIDIA在内的硬件提供商股价飞涨。虽然深度学习背后的理论早已有之,但它的崛起跟现代GPU的问世密切相关。NVIDIA的联合创始人兼首席执行官黄仁勋(Jen-Hsun Huang)一直反复强调了这一事实:“五年前,人工智能世界的大爆炸发生了,神奇的人工智能计算机科学家们找到了新的算法,让我们有可能利用这种名为深度学习的技术,取得无人敢想的成果和认知。”
到目前为止,深度学习一直是个由大型科技公司占据主导地位的领域,比如谷歌、百度、微软等。他们在大规模的GPU集群上部署算法,为自己的多种网络服务提供支持。
人们开始意识到,机器并不是比人更聪明,它只是能够比人看到更多的东西,它的关注范围远超人类。正式由于这些大的数据,结合GPU这样的技术,我们可以利用它们来训练新的算法,成效则超越人类。
随着大数据与人工智能时代的到来,GPU的一个竞争对手也开始觉醒,它就是FPGA。
3、摩尔定律的专业化:FPGA
2015年6月1日,Intel宣布斥资167亿美元,以每股约54美元的价格收购全球第二大FPGA厂商Altera(阿尔特拉),这是Intel成立47年以来历史上规模最大的收购。本次Intel的收购对应的估值高达35倍,这在半导体领域已经非常罕见。
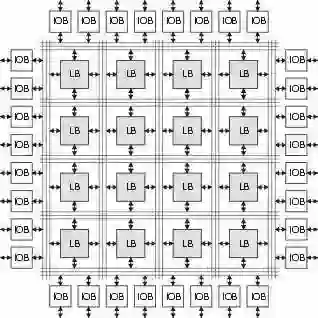
FPGA是Field Programmable Gate Array的简称,中文全称为现场可编程门阵列,它是作为专用集成电路领域中的一种半定制电路而出现的,既解决了全定制电路的不足,又克服了原有可编程逻辑器件门电路数有限的缺点。
随着人们的计算需求越来越专业化,人们希望有芯片可以更加符合我们的专业需求,但是考虑到硬件产品一旦成型便不可再更改这个特点,人们便开始想,我们可不可以生产一种芯片,让它硬件可编程。也就是说:这一刻我们需要一个比较适合对图像进行处理的硬件系统,下一刻我们需要一个对科学计算比较适合的硬件系统,但是我们又不希望焊两块板子,这个时候FPGA便应运而生。
FPGA运用硬件描述语言(Verilog或VHDL)描述逻辑电路,可以利用逻辑综合和布局、布线工具软件,快速地烧录至FPGA上进行测试。人们可以根据需要,通过可编辑的连接,把FPGA内部的逻辑块连接起来。这就好像一个电路试验板被放在了一个芯片里。一个出厂后的成品FPGA的逻辑块和连接可以按照设计者的需要而改变,所以FPGA可以完成所需要的逻辑功能。
![]()
FPGA结构简图
FPGA这种硬件可编程的特点使得其一经推出就受到了很大的欢迎,许多ASIC(专用集成电路)就被FPGA所取代。ASIC是指依产品需求不同而定制化的特殊规格集成电路,由特定使用者要求和特定电子系统的需要而设计、制造。包括最近Google隆重推出的TPU也算是一种ASIC。
Intel通过收购已经展示了其Xeon + FPGA的创新模式,并计划今年投放市场。Altera的FPGA产品可以让英特尔Xeon至强处理器技术形成高度定制化、整合产品,单位功耗性能比CPU+GPU模式更高。CPU + FPGA用于数据中心,对于Intel来说,这将是未来数据中心的标配。
目前在海量数据处理,主流方法是通过易编程多核CPU+GPU来实现,而从事海量数据处理应用开发(如密钥加速、图像识别、语音转录、加密和文本搜索等)。设计开发人员既希望GPU易于编程,同时也希望硬件具有低功耗、高吞吐量和最低时延功能。但是依靠半导体制程升级带来的单位功耗性能在边际递减,CPU + GPU架构设计遇到了瓶颈而,而CPU + FPGA可以提供更好的单位功耗性能,同时易于修改和编程。
瑞士苏黎世联邦理工学院(ET Zurich)研究发现,基于FPGA的应用加速比CPU/GPU方案,单位功耗性能可提升25倍,而时延则缩短了50到75倍,与此同时还能实现出色的I/O集成。换言之,FPGA能在单芯片上提供高能效硬件应用加速所需的核心功能,并同时提供每个开发板低功耗的解决方案。
随着人工智能的持续火爆,Intel的首席FPGA架构师兰迪·黄(Randy Huang)博士也认为:“深度学习是人工智能方面最激动人心的领域,因为我们已经看到深度学习带来了最大的进步和最广泛的应用。虽然人工智能和DNN研究倾向于使用 GPU,但我们发现应用领域与英特尔的下一代FPGA 架构之间是完美契合的。”
但FPGA也不是没有缺点。FPGA相对于它的先辈ASIC芯片来说速度要慢,而且无法完成更复杂的设计,并且会消耗更多的电能;而ASIC的生产成本很高,如果出货量较小,则采用ASIC在经济上不太实惠。但是如果某一种需求开始增大之后,ASIC的出货量开始增加,那么某一种专用集成电路的诞生也就是一种历史趋势了。例如,Google的Tensor Processing Unit就是当下大数据和人工智能的产物。至此,TPU便登上了舞台。
4、摩尔定律的超越:TPU
历史就是这么的有趣,对计算通用性的追求造就了硬件从ASIC到FPGA到GPU到CPU的演变路线,而对领域性能的追求使得这一路线彻底掉了个头,只不过这一次,似乎所有的方案都在变成通用化。
随着机器学习算法越来越多的应用在各个领域并表现出优越的性能,例如街景、邮件智能回复、声音搜索等,对于机器学习算法硬件上的支持也越来越成为一种需要。目前很多的机器学习以及图像处理算法大部分都跑在GPU与FPGA上面,但是这两种芯片都还是一种通用性芯片,所以在效能与功耗上还是不能更紧密的适配机器学习算法,而且Google一直坚信伟大的软件将在伟大的硬件的帮助下更加大放异彩,所以Google便在想,我们可不可以做出一款专用机机器学习算法的专用芯片,TPU便诞生了。
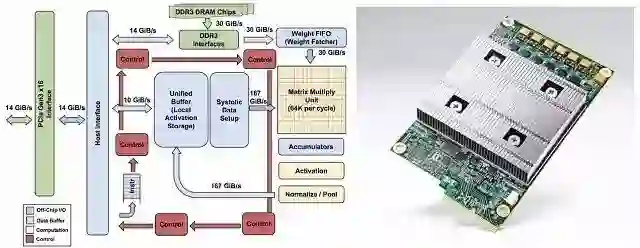
![]()
Google想做一款专用机机器学习算法的专用芯片:TPU(Tensor Processing Unit)。
从名字上我们可以看出,TPU的灵感来源于Google开源深度学习框架TensorFlow,并且开始从Google内部走向全世界。
简单来说,CPU是基于完全通用的诉求,实现的通用处理架构,GPU则主要基于图像处理的诉求,降低了一部分通用性,并针对核心逻辑做了一定的优化,是一款准通用的处理架构,以牺牲通用性为代价,在特定场合拥有比CPU快得多的处理效率。而TPU,则针对更明确的目标和处理逻辑,进行更直接的硬件优化,以彻底牺牲通用性为代价,获得在特定场合的极端效率。
Google已经在它内部的数据中心跑TPU两年多了,性能指标非常出众,大概将硬件性能提升了7年的发展时间,约为摩尔定律的3倍。不仅延续了摩尔定律,甚至还跨越了摩尔定律的发展规律。据称,Google开始测试和线上运营环境完成更新迭代一款TPU,只需要惊人的短短22天!
TPU的高性能来源于三个方面:对发热量的控制、对于低运算精度的容忍、以及数据的本地化。
特别是针对大数的处理,相对与GPU,从存储器中取指令与数据将耗费大量的时间,但是机器学习大部分时间并不需要从全局缓存中取数据,所以在结构上设计的更加本地化也加速了TPU的运行速度。
在Google数据中心的TPU其实已经干了很多事情了,例如机器学习人工智能系统RankBrain,它是用来帮助Google处理搜索结果并为用户提供更加相关搜索结果的;还有街景Street View,用来提高地图与导航的准确性的;当然还有下围棋的计算机程序AlphaGo。
在描述AlphaGo的那篇Nature文章中看到,AlphaGo只是跑在CPU + GPUs上,文章中说AlphaGo的完整版本使用了40个搜索线程,跑在48块CPU和8块GPU上,AlphaGo的分布式版本则利用了更多的机器,40个搜索线程跑在1202个CPU和176块GPU上。这个配置是和樊麾比赛时使用的,所以当时李世乭看到AlphaGo与樊麾的对弈过程后对人机大战很有信心。但是就在短短的几个月时间,Google就把运行AlphaGo的硬件平台换成了TPU,然后对战的局势立即变得一边倒。
![]()
装有TPUs的Google服务器机架
在今年召开的ISCA 2017(计算机体系结构顶级会议)上面,Google终于揭示了TPU的细节。在论文中,谷歌将 TPU 的性能和效率与 Haswell CPU 和英伟达 Tesla K80 GPU 做了详尽的比较,从中可以了解 TPU 在性能卓越的原因。对的,你没有看错,75位联合作者!包括系统结构领域的大牛David Patterson!
![]()
5、大数据的后摩尔时代
随着大数据时代的到来,深度学习应用的大量涌现,使得超级计算机的架构逐渐向深度学习应用优化,从传统CPU为主GPU为辅的英特尔处理器变为GPU为主CPU为辅的结构。虽然当前计算系统仍将保持着“CPU + 协处理器”的混合架构。但是,在协处理市场,随着人工智能尤其是机器学习应用大量涌现,各大巨头纷纷完善产品、推出新品。
如果非要牵强附会一下,那么CPU是面向计算的,GPU是面向数据的,FPGA是面向领域的,而TPU则是面向智能的。
大约在四年前,谷歌开始注意到深度神经网络在各种服务中的真正潜力,由此产生的计算力需求——硬件需求,也就十分清晰。具体说,CPU和GPU把模型训练好,谷歌需要另外的芯片加速计算,经过这一步,神经网络就可以用于产品和服务了。
TPU的总设计师就是著名的硬件大牛Norman Jouppi,加入Google前是MIPS处理器的首席架构师之一,开创了很多内存系统中的新技术。Jouppi表示:TPU 跟CPU或GPU一样是可编程的。TPU不是专为某一个神经网络模型设计的,TPU能在多种网络(卷积网络、LSTM模型和大规模全连接的神经网络模型)上执行CISC指令。所以,TPU 是可编程的,但 TPU 使用矩阵作原语(primitive)而不是向量或标量。
因此,可以看到,除了TPU可以更好更快地运行机器学习算法,Google发布它应该还在下一盘大棋。
Google说他们的目标是在工业界的机器学习方面起到先锋带头作用,并使得这种创新的力量惠及每一位用户,并且让用户更好地使用TensorFlow 和 Cloud Machine Learning。其实就像微软为它的HoloLens增强现实头显配备了全息处理单元(Holographic processing unit,HPU),像TPU这样的专业硬件只是它远大征程的一小步,不仅仅是想让自己在公共云领域超过市场老大Amazon Web Services (AWS)。随着时间的推移,Google会放出更多的机器学习API,现在Google已经推出了云机器学习平台服务和视觉API,我们可以相信,做大数据和机器学习技术与市场的领头羊才是Google更大的目标。
就这样,Google从摩尔定律的一个独特视角,开始用TPU、TensorFlow、Kaggle等重新定义了自己。
TPU的硬件基础设施、TensorFlow和Cloud ML的机器学习平台、加上Kaggle的竞技场,这些冰山上的一角视乎预示着未来将会有无数个黄士杰(AlphaGo大脑的核心缔造者之一)开始接受各种苛刻的挑战,进而创造出属于人类的荣誉。
2017未来科技论坛暨”未来科技资助计划”发布
人工智能学家/未来科技学院与中科创星,中国科学院虚拟经济与数据科学研究中心,金融发展局等机构联合举办未来科技论坛和发起“未来科技资助计划”,联合科技企业家、风险投资家,讲解当前人工智能,互联网,脑科学,机器人最新进展,对科学家的前沿科学研究和科技创业进行支持。为诞生中国的重大原始科学创新和科技独角兽提供燃料和催化剂。
主办单位:中国科学院虚拟经济与数据科学研究中心
承办单位:人工智能学家/未来科技学院
支持单位:中科创星,泰智会,常州经开区金融发展局
会议时间:2017年4月26日
会议地点:北京市海淀区中关村丹棱街1号互联网金融中心1楼泰智会大厅
参会嘉宾:青年科学家代表,科技企业家代表,投资界代表、政府代表
未来科技论坛议题:
1.邀请人工智能,互联网,脑科学,机器人等方面的著名科学家进行最新科技前沿进展的报告
2.邀请著名投资人,科学家,科技企业家从不同角度阐述如何支持科学家的前沿科学研究和科技创业。
3.人工智能学家/未来科技学院发布科学资助平台“Funding Future”,并与合作伙伴联合启动“未来科技资助计划”
![]()
![]()
![]()