大会 | 腾讯AI Lab独家解析ICML 2017五大研究热点
腾讯AI Lab去年四月成立,今年是首次参加ICML,共计四篇文章被录取,位居国内企业前列。此次团队由机器学习和大数据领域的专家、腾讯AI Lab主任张潼博士带领到场交流学习,张潼博士还担任了本届ICML领域主席。在本次130人的主席团队中,华人不超过10位,内地仅有腾讯AI Lab、清华大学和微软研究院三家机构。
以下为腾讯AI Lab机器学习团队在会后对五大研究领域的回顾与独家解析。
所提及论文下载地址:http://t.cn/R9WyXxz
强化学习
Reinforcement Learning
强化学习是机器学习的重要分支,通过试错或模仿专家的方式学习可靠策略,解决序列决策问题。其应用领域包括视频游戏AI、无人驾驶、机器人控制、物流管理和仓储调度等。粗略统计,本届ICML有40余篇强化学习相关论文,涵盖了收敛性分析、连续控制、搜索与探索、多智能体与博弈论、模仿学习与转导、端到端深度强化学习等多个方面。
这次会议的研究中体现出三大特点:一、深度学习范式被广为采用,研究者将对问题的理解和先验知识做成了复杂网络模型的子模块,并采用端到端的方式训练;二、来自机器人领域的学者持续影响连续控制方面的研究;三、团队配合多智能体方面的研究吸引了越来越多的注意力。另外,「视频游戏与机器学习」研讨会(Workshop)环节发布了新的强化学习模拟器平台。我们重点关注了以下文章:
1) FeUdal Networks for Hierarchical Reinforcement Learning
本文由Google DeepMind发表。策略网络被划分为两个模块:管理者和工作者。管理者模块在低时间分辨率工作,产生中长期子目标;工作者模块在高时间分辨率工作,从管理者模块拿到子目标,并上原始的环境观测一起输出当前时刻的决策动作。本文这种精巧设计的网络结构能自动「发现」子目标,并自动学出相应的「子策略」,而之前的工作都采用了手调子目标的方式,在灵活性和通用性不如本文所提出的算法。
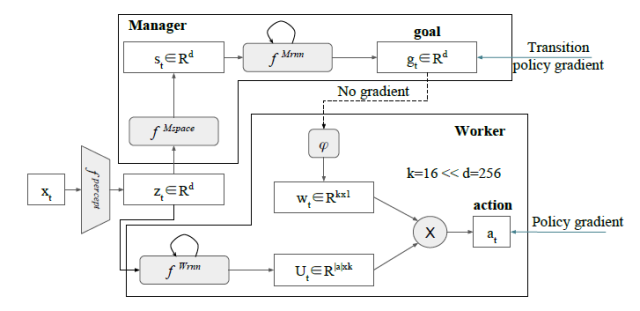
本文的管理者-工作者网络结构
实验表明该方法确实能够成功的自动发现「子目标」并学出「子策略」。下图展示了该方法在「蒙特祖玛的复仇」游戏环境[1]上的结果。
[1]该游戏特点是有多幕切换,奖励信号稀疏且延迟很长,例如在某一幕拿到了剑要再回到前两幕斩杀某个骷髅怪。
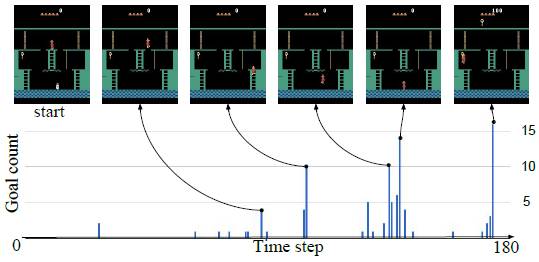
2)Improving Stochastic Policy Gradients in Continuous Control with Deep Reinforcement Learning using the Beta Distribution
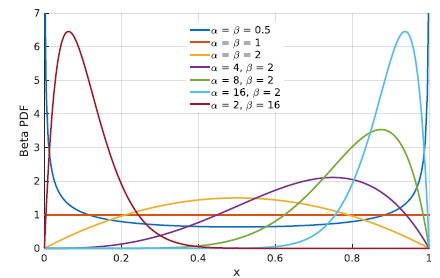
本文由卡内基梅隆大学发表。假设输出的连续控制信号从Beta分布中采样,本文通过一个深度神经网络直接学习、预测Beta分布的两个参数。在连续控制的文献中,以往工作多采用高斯分布假设并直接学习和预测高斯分布的均值和方差。但高斯分布在数值上是无界的,对一些需要安全策略的场合这种性质极不合理。例如,自动驾驶中,左右打盘的角度无论如何不能太大。而Beta分布刚好满足左右有界这一性质(如下图)。
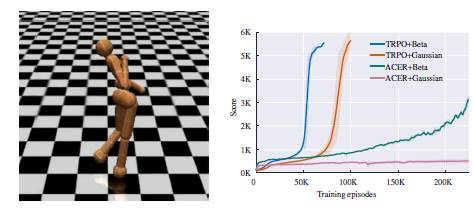
本文方法的实现非常简单但又十分有效,在机器人控制模拟环境mujoco的多个任务中取得的结果超过了基于高斯分布的连续控制方法(如下图)。
3) Coordinated Multi-Agent Imitation Learning
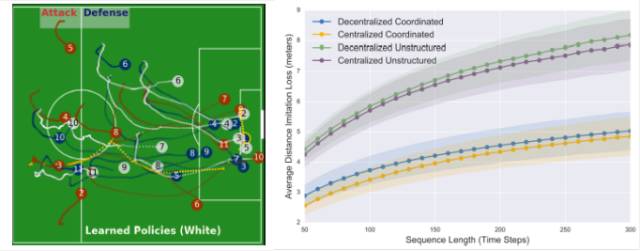
本文由加州理工大学、迪斯尼研究院和STATS公司(该公司有大量体育比赛的各类实际数据)联合发表,通过模仿学习方式学出多智能体控制模型。本文收集了大量英超足球比赛数据,使用结构学习方式自动学出智能体和实际数据的合理对应关系。这里的对应关系是指,比如当前智能体在某个具体位置到底是更适合学习前锋、前卫还是中场的行为。
通过动态构造对应关系,本文算法绕开了多智能体模仿学习中对应关系可能存在模糊或不确定性这一难题,例如边后卫助攻到前场后,到底该表现得更像后卫还是更像前锋。实验表明该方法学出的控制策略与专家数据(来自实际的英超比赛)更为接近,见下左图中的白圈,而定量结果可见下图右。
4)其他话题
在「视频游戏与机器学习」研讨会环节,暴雪公司宣布开源并发布《星际争霸2》的C++编程接口,开发者通过其可获得游戏内部状态、操纵游戏单位执行指定动作等。其还公布了几十万一对一比赛回放文件,记录了匿名玩家的操作序列。暴雪还与Google DeepMind合作,推出了相应的Python版本接口。
C++ APIs效果现场演示

Python接口,访问特征图层
另外,Facebook AI Research发布了新的强化学习框架ELF,其特点为支持多种环境-执行器的并发模型(一对一,多对一、一对多,多对多),这会为现代强化学习算法的实现,如模特卡罗树搜索(MCTS)和自我对战(Self Play),带来极大便利。
随机优化
Stochastic Optimization
随机优化算法是指每次只随机采样一个或少量几个(Mini-batch)训练样本对模型更新的优化方法。因其有低内存消耗、低单次迭代计算复杂度等特点,被广泛应用于大规模机器学习模型训练中,包括绝大多数深度学习模型的训练。粗略统计,本届ICML有20余篇随机优化相关论文,大致可分为一阶随机优化、二阶随机优化和非凸随机优化三个大方向。
本次会议的相关论文中体现出两大特点:二阶随机优化算法被更多研究者所关注;非凸随机优化,特别是针对深度学习的非凸随机优化算法成为一个新的研究热点。我们重点关注了以下几篇论文:
1)Follow the Moving Leader in Deep Learning
本文由香港科技大学发表。在深度学习中,参数以及数据分布都会随着迭代进行不断变化,这使得深度学习模型的训练一直是一个具有挑战性的问题。针对这一问题,本文提出了全新的FTML算法,具有更快收敛速度。与已有优化算法(如FTRL)不同的是,本文的FTML算法迭代中,越新样本具有越大权重,这使算法更能适应数据分布变化,有更快收敛速度。多个数据集上深度学习模型训练实验结果显示,FTML比其他已有算法收敛更快。
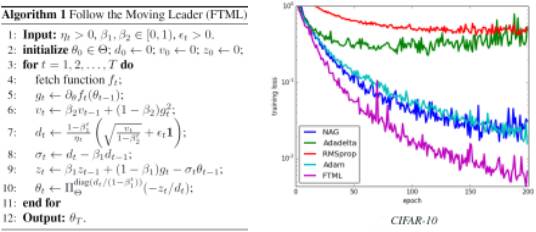
模型训练实验结果
2)Natasha: Faster Non-Convex Stochastic Optimization Via Strongly Non-Convex Parameter
本文由微软研究院发表。随机梯度下降和梯度下降是当前求解非凸机器学习模型的常用方法,本文借用方差下降随机优化算法SVRG的关键思路,并对目标函数的强非凸性做更细致的分析,提出了针对于非凸随机优化问题的新算法Natasha,比目前标准算法更高效。作者的创新之处,是提出了一套针对强非凸函数更细致的分析方法,并在此基础上设计了针对非凸优化问题更精细的随机算法,能有效利用强非凸函数的结构信息。理论分析结果显示,在强非凸参数大于某个常数时,本文所提出的算法具有更低的计算复杂度。
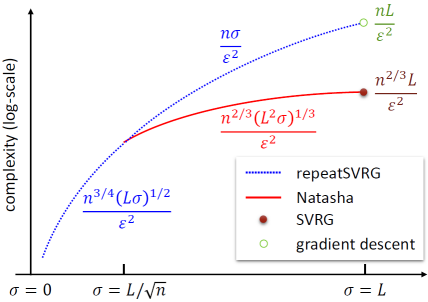
计算复杂度对比结果
3)A Unifying Framework for Convergence Analysis of Approximate Newton Methods
本文由上海交通大学和北京大学联合发表。近似牛顿算法,如Sketched-Newton和Subsampled-Newton,是一类高效的二阶随机优化算法,因其单次迭代计算复杂度较低、收敛速度快等特点受到广泛关注。但已有理论的分析结果和其在实际应用中的性能表现在很多方面并不一致。本文为二阶随机优化算法提出了一套新的分析工具,解决了多个理论及应用中表现不一致的问题。
在创新点上,作者将多种近似牛顿算法统一到同一个算法框架中,对其局部收敛性质做统一分析,解决了多个理论分析结果和实际应用性能不一致的问题,并为新算法设计提供了新的思路。本文从理论上证明了:一、近似牛顿算法的线性收敛速度不需要Hessian矩阵满足Lipschitz连续,但是算法平方收敛速度需要此连续。二、Hessian矩阵的条件数和Sketched-Newton的性能不相关。
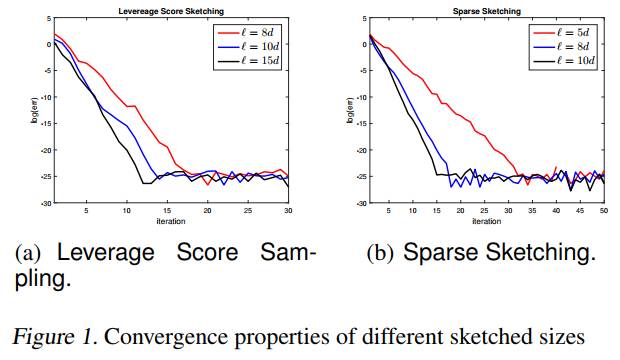
连续(非)凸优化
Continuous Optimization
连续(非)凸优化在机器学习中起着举足轻重的作用,大部分机器学习问题均可建模成某一类连续(非)凸优化问题。粗略统计,本届ICML大概有40篇连续优化的论文,其中半数以上为非凸连续优化内容。另外,由于深度学习的流行,一阶优化算法相关论文也占有相当大的比重。我们将重点介绍以下三个研究:
1)GSOS: Gauss-Seidel Operator Splitting Algorithm for Multi-Term Nonsmooth Convex Composite Optimization
这篇论文由腾讯AI Lab、中山大学和香港中文大学合作完成,提出了新的求解多块非光滑复合凸优化问题的算子分裂算法。该算法采用Gauss-Seidel迭代及算子分裂的技巧处理不可分的非光滑正则项。通过用单调算子理论,文中给出多块非光滑复合凸优化问题最优解集以及算法的等价刻画,并利用该等价刻画来巧妙的建立了所提算法的全局收敛性。最后本文以实验证实了该算法的有效性。
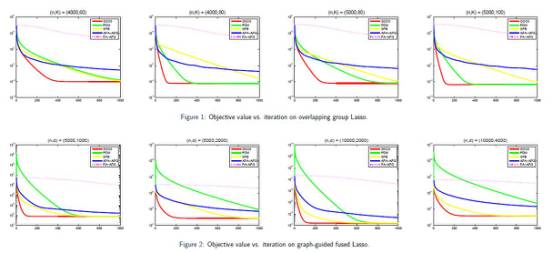
2)Exploiting Strong Convexity from Data with Primal-Dual First-Order Algorithms
这篇论文由芝加哥大学和微软研究院共同完成,提出两类新的原对偶一阶算法来求解经验风险最小化的凸优化问题。通过自适应地利用样本数据中暗含的强凸性质,文中证明了这两类新算法的线性收敛速率。另外,通过利用Dual-free的技巧,文中将算法中Euclidean距离下的邻近算子替换为Bregman距离下的邻近算子,从而得到两类Dual-free原对偶算法变体。最后实验证明该算法的有效性。
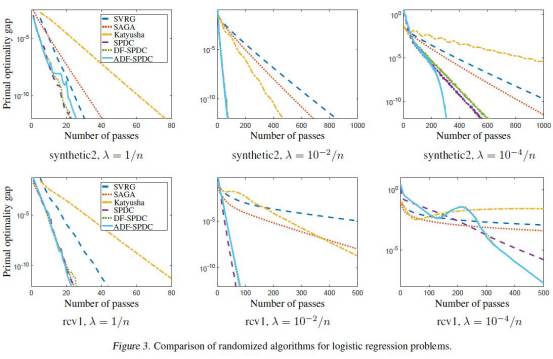
3)Dual Iterative Hard Thresholding: From Non-convex Sparse Minimization to Non-smooth Concave Maximization
这篇论文由罗格斯大学和南京信息工程大学共同完成,作者首次建立了有稀疏约束的极小化问题Lagrange对偶理论。基于此,本文提出了求解具有稀疏约束的极小化问题的对偶硬阈值(Dual ITH)算法及其随机版本的变体,并在无需采样算子满足限制同构性质(RIP)的条件下建立了算法收敛性。这篇论文从实验上说明了该算法在具有稀疏约束的极小化问题上效果为目前最佳。
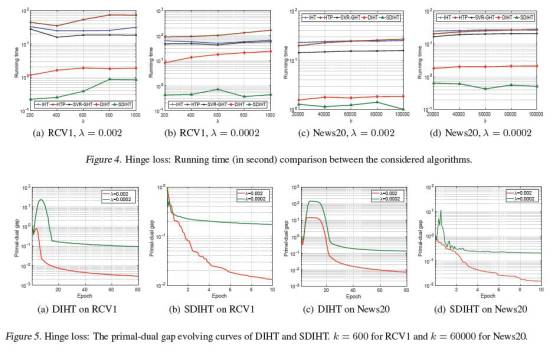
分布式机器学习
Distributed Machine Learning
分布式机器学习旨在研究如何以平行、分布式方式来设计算法和系统,实现对大规模海量数据的高效处理。其研究涉及算法和系统两个方面,本届ICML的相关研究主要以算法设计为主。依照分布式类型,主要有中心化分布式和去中心化分布式两种。
粗略统计,本届ICML有13篇分布式机器学习相关论文。其中6篇为传统分布式机器学习算法(优化算法)设计,中心化分布式和去中心化分布式各占3篇;此外,1篇论文讨论了中心化分布式场景下,如何利用数据稀疏性降低通信消耗;1篇讨论了通信限制条件下的中心化分布式算法设计;另外几篇则涉及高斯过程、汤普森采样和聚类算法等的中心化分布式算法设计。
从研究上本届ICML有三大研究趋势:一、去中心化的分布式机器学习得到了越来越多关注;二、异步通信仍是分布式机器学习关注的重要方向;三、在贝叶斯优化、高斯过程、聚类算法等具体领域,开始有更多分布式研究。我们重点关注了以下几篇文章:
1) Projection-free Distributed Online Learning in Networks
本文由清华大学计算机系与腾讯AI Lab联合发表,首次提出了免投影的分布式在线学习算法,并给出了它的悔界上界(Regret Bound)。后者依赖于网络大小和拓扑结构,随网络增大而增大,随网络拓扑连接性能提升而减小。相较于传统的有投影分布式在线算法,本文的算法计算复杂度明显降低,能高效处理分布式在线数据流,克服了传统有投影算法需复杂投影计算的问题。
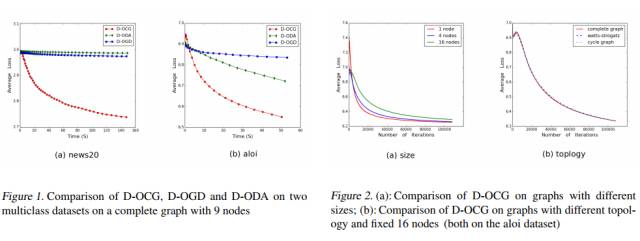
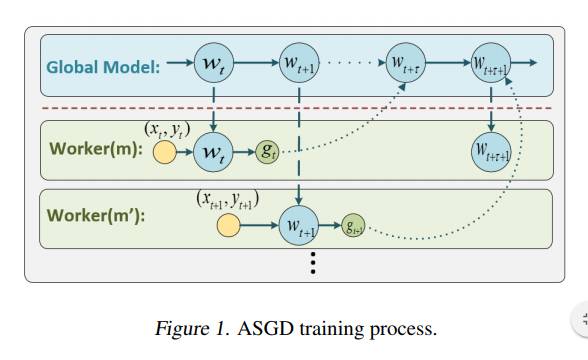
2) Asynchronous Stochastic Gradient Descent with Delay Compensation
本文由中国科技大学与微软亚洲研究院(MSRA)联合发表,提出了延迟补偿的异步随机梯度下降算法。传统异步随机梯度下降算法直接使用延迟的梯度,而该文则给出了一种补偿延迟梯度的算法。补偿方法利用梯度函数的一阶近似,即损失函数的二阶近似来估计延迟的梯度,使算法能取得优于异步随机梯度算法的效果。从创新点上,该文首次提出了对延迟梯度的估计思路,并应用在实际的深度学习训练当中。
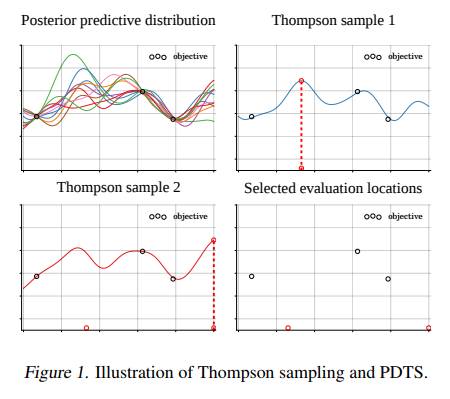
3) A Parallel and Distributed Thompson Sampling for Large-scale Accelerated Exploration of Chemical Space
本文由剑桥大学和IBM联合发表。汤普森采样算法是贝叶斯优化领域的经典算法,可对搜索空间做高效探索,但当前算法无法实现大规模并行化。本文提出了分布式的汤普森采样算法,并在具有大规模搜索空间的化学实验中验证了该算法的有效性。
递归神经网络
Recurrent Neural Networks
递归神经网络(RNN),尤其是LSTM和GRU,已经在时序性数据(Sequential Data)建模与生成都取得了显著的效果。RNN研究已是深度学习一个重要研究方向。去年的ICML,所有深度学习相关论文、至少三个Session都提及了神经网络与深度学习。而今年的ICML中,有4个session专门介绍最近RNN的进展,包括一些新的RNN模型,如Recurrent Highway Networks,和一些RNN在音乐、音频和视频数据上的应用。这说明主流学术界与工业界近期对RNN有很大关注度。我们也重点关注了以下几篇研究:
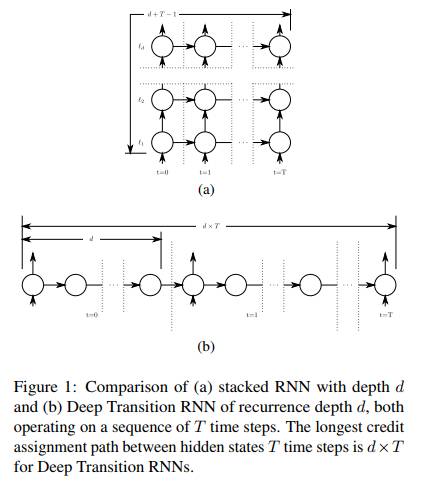
1) Recurrent Highway Networks
本文由苏黎世联邦理工学院及卢加诺大学的IDSIA实验室联合完成。Recurrent Highway Network (RHN) 是对LSTM框架的一种扩展。LSTM Step之间的变换深度(Transition Depth)为1,而RHN允许该深度高于1,因而进一步学习信号间的复杂关系。在一些语言建模任务上,RHN显示了更强大的能力,如在Penn Treenbank数据集上Word Level的perplexity从90.4降到了65.4。
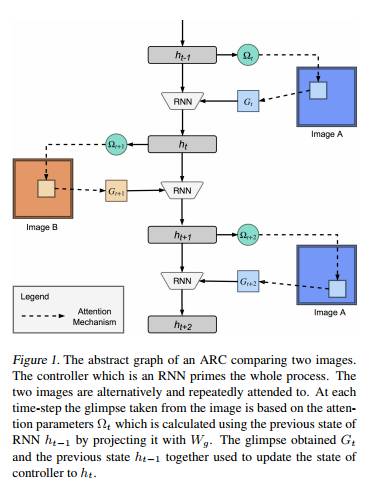
2) Attentive Recurrent Comparators
本文由北卡罗来纳大学和印度科学研究院共同完成。Attentive Recurrent Comparator (ARC) 可学习一个近似的动态表示空间用于极小样本学习。在极小样本学习公开数据集合Omniglot上,错误率降低为1.5%,可以说是在这个人物的公开测评库上,AI超过了人类的识别水平。这个工作主要模拟人类比较两个图像相似度的行为,用一个RNN网络协调整个过程,采用相应注意力模型让两幅图像交替比对。在每一个Time Step,结合图像局部区域信息和RNN的前一个时刻状态,产生当前时刻状态。RNN的最终状态可推导出两副图像的相关性表示(Relative Representation)。
ARC在极小样本应用上有两种处理方式:一是采用朴素的ARC模型,将给定测试图像与数据集合的所有图像比对,返回最相似的图像对应的所属类别;第二种方式成为Full Context ARC,在采用朴素的ARC将测试图像与数据集合的图像比对后,得到相应的相关性表示。这一步学习了局部的两两之间比对关系,基于相关性表示,进而使用双向LSTM学习全局的比对信息。朴素ARC模型和Full Context ARC模型在Omniglot数据集上都取得了超过人类的识别能力;另外,前者在MiniImageNet数据集上的测试结果也超越了Matching Networks等模型。
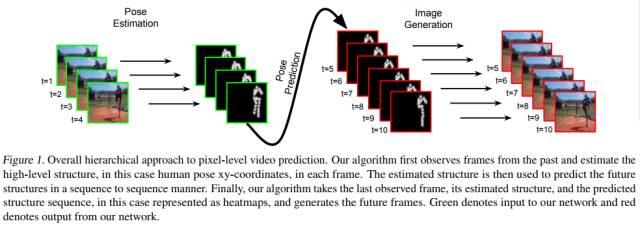
3)Learning to Generate Long-term Future via Hierarchical Prediction
本文由谷歌大脑、Adobe和密歇根大学联合发表,文中介绍了一个层次(Hierarchical)方法预测长时(long-term)视频未来帧。模型先估计输入视频帧的高阶结构信息,再预测此信息如何在未来视频帧进化,最终给定一个单帧图像和预测得到的高阶结构信息,来重构未来视频帧像素级别的信息。文中提出的模型使用LSTM预测视频结构信息,和一个Analogy-based encoder-decoder CNN产生未来视频帧。其预测性能在Human3.6M和Peen Action datasets数据集上均取得了很好结果。
4) Delta Networks for Optimized Recurrent Network Computation
本文由苏黎世联邦理工学院、苏黎世大学和三星综合技术院等机构共同发布。神经网络的激活模式(Activation Pattern)一般呈现出稳定输出,为进一步处理这样的自然信号,该论文提出了一个Delta Network,其中每个神经元只在其激活值超越一个阈值时传输相应的信号。虽然一个朴素的Delta Network在内存使用和计算量上有一定程度提升,但是其能在训练阶段以较快时间得到较高准确度。在TIDIGITS Audio Digit Recognition Benchmark数据集上提高了9倍训练效率,而准确度基本无损失。在另一个自动驾驶数据集上,使用一个端到端的CNN-RNN网络来完成Steering Angle Prediction,RNN训练效率显著提高了100倍。在WSJ的语音识别数据集上,Delta Networks可在不损失精度的情况下,提高5.7倍训练效率。
5)The Statistical Recurrent Unit
本文由卡内基梅隆大学发表,文中提出了一个没有门操作的RNN单元,即Statistical Recurrent Unit (SRU),可保证Moving Average of Statistics来学习序列信号的长时(long-term)依存特性。SRU结构简单,没有相应门操作,跟LSTM的参数量比较一致。在合成数据上,相较于LSTM/GPU,SRU可学习多尺度循环统计特性(Multi-scale Recurrent Statistic)。而且SRU在学习一维信号的长时依赖,其性能也优于LSTM/GRU。具体说来,SRU在MNIST数据集分类、多声部音乐(polyphonic music)建模、一维天气数据建模等任务上性能优于LSTM或GRU。
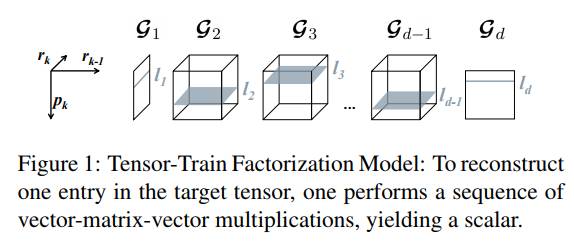
6)Tensor-Train Recurrent Neural Networks for Video Classification
该论文由西门子公司与德国慕尼黑大学联合发表,通过Tensor-train Decomposition的方式分解Input-to-hidden矩阵,以处理RNN中高维度的输入信号,如视频建模(video modeling)任务。现阶段对视频类高维度的输入信号,都通过CNN操作将视频每一帧表示为一个特征向量,降低相应维度,后使用RNN建模时序信息。在UCF101等现有视频数据集上,该方法取得了与当前最优方法匹敌的结果,但是其计算复杂度远低于朴素的RNN。本文提出的Tensor-train Factorization可构建一个Tensor-train Layer替换Input-to-hidden的大矩阵,还可与RNN共同用端对端训练方式完成训练。
除了上述的RNN模型创新外,RNN应用于时序数据,尤其是音频、音乐、语音等数据,也取得了显著的进展。比如研究Text-to-speech的进展[1]、音频合成工作[2]和巴赫音乐的产生[3]等。
相关论文为:[1] Deep voice: Real-time neural Text-to-speech;[2] Neural Audio Synthesis of Musical Notes with WaveNet Autoencoders;[3] DeepBach: A Steerable Model for Bach Chorales Generation
腾讯AI Lab四篇论文被ICML接收
论文一:Scaling Up Sparse Support Vector Machines by Simultaneous Feature and Sample Reduction
本文提出了第一个能在模型训练开始前,同时检测和去除稀疏支持向量机中不活跃样本和特征的筛选算法,并从理论和实验中证明其能不损失任何精度地把模型训练效率提升数个量级。
论文二:GSOS: Gauss-Seidel Operator Splitting Algorithm for Multi-Term Nonsmooth Convex Composite Optimization
本文提出了求解多块非光滑复合凸优化问题的算子分裂新算法,该算法采用Gauss-Seidel迭代以及算子分裂的技巧处理不可分的非光滑正则项,并以实验证实了该算法的有效性。
论文三:Efficient Distributed Learning with Sparsity
本文提出了一个高维大数据中能更有效学习稀疏线性模型的分布式算法。在单个机器训练样本足够多时,该算法只需一轮通信就能学习出统计最优误差模型;即使单个机器样本不足,学习统计最优误差模型的通信代价只随机器数量对数曲线上升,而不依赖于其他条件数。
论文四:Projection-free Distributed Online Learning in Networks
本文提出了去中心化的分布式在线条件梯度算法。该算法将条件梯度的免投影特性推广到分布式在线场景,解决了传统算法需要复杂的投影操作问题,能高效处理去中心化的流式数据。
一分钟了解ICML 2017
ICML由国际机器学习协会IMLS(International Machine Learning Society)主办,与NIPS并列为机器学习和人工智能研究领域最具影响力的学术会议。在新发布的2017谷歌学术指标中,以「机器学习」关键词排名,ICML位列第一。
ICML源于1980年在卡内基梅隆大学举办的机器学习研讨会。1980 年第一届会议在匹兹堡举行,迄今已举办了34 届。每年会议地点均不同,去年是纽约,今年为悉尼,明年是斯德哥尔摩。
本届ICML共收到1676篇论文,接收434篇(比率为25.9%),均创历史新高。据粗略统计,25%的被接收论文第一作者为华裔。据OpenAI研究员Andrej Karpathy统计,会议论文大部分由学界完成,工业界参与了其中20-25%的文章撰写。
大会共设22个研讨会(Workshop)、9个教程辅导(Tutorial),覆盖深度学习、强化学习、分布式计算和优化等诸多机器学习领域热门方向。在10 个Session中,若从研讨主题判断领域热度,提及度依次排列为深度学习、连续优化、强化学习、RNN和在线学习。
与去年情况相同,今年所有被接收论文都有一次口头报告和一次海报展示(Poster)的机会。口头报告对论文介绍会更加系统和正式,适合对该领域有深入研究的参会者认真听取和学习;海报展示可参会者在短时间内了解更多人的工作,效率较高。
————— 给爱学习的你的福利 —————
CCF-ADL81:从脑机接口到脑机融合
顶级学术阵容,50+学术大牛
入门类脑计算知识,了解类脑智能前沿资讯
课程链接:http://www.mooc.ai/course/114
或点击文末阅读原文

————————————————————





