作者:Aravind Srinivas等
机器之心编译
参与:Racoon、Jamin
pixel-based RL 算法逆袭,BAIR 提出将对比学习与 RL 相结合的算法,其 sample-efficiency 匹敌 state-based RL。
此次研究的本质在于回答一个问题—使用图像作为观测值(pixel-based)的 RL 是否能够和以坐标状态作为观测值的 RL 一样有效?传统意义上,大家普遍认为以图像为观测值的 RL 数据效率较低,通常需要一亿个交互的 step 来解决 Atari 游戏那样的基准测试任务。
研究人员介绍了 CURL:一种用于强化学习的无监督对比表征。CURL 使用对比学习的方式从原始像素中提取高阶特征,并在提取的特征之上执行异策略控制。在 DeepMind Control Suite 和 Atari Games 中的复杂任务上,
CURL 优于以前的 pixel-based 的方法(包括 model-based 和 model-free),在 100K 交互步骤基准测试中,其性能分别提高了 2.8 倍以及 1.6 倍
。在 DeepMind Control Suite 上,CURL 是第一个几乎与基于状态特征方法的 sample-efficiency 和性能所匹配的基于图像的算法。
![]()
论文链接:https://arxiv.org/abs/2004.04136
网站:https://mishalaskin.github.io/curl/
GitHub 链接:https://github.com/MishaLaskin/curl
CURL 是将对比学习与 RL 相结合的通用框架。理论上,可以在 CURL pipeline 中使用任一 RL 算法,无论是同策略还是异策略。对于连续控制基准而言(DM Control),研究团队使用了较为熟知的 Soft Actor-Critic(SAC)(Haarnoja et al., 2018) ;而对于离散控制基准(Atari),研究团队使用了 Rainbow DQN(Hessel et al., 2017))。下面,我们简要回顾一下 SAC,Rainbow DQN 以及对比学习。
SAC 是一种异策略 RL 算法,它优化了随机策略,以最大化预期的轨迹回报。像其他 SOTA 端到端的 RL 算法一样,SAC 在从状态观察中解决任务时非常有效,但却无法从像素中学习有效的策略。
最好将 Rainbow DQN(Hessel et al., 2017)总结为在原来应用 Nature DQN 之上的多项改进(Mnih et al., 2015)。具体来说,深度 Q 网络(DQN)(Mnih et al., 2015)将异策略算法 Q-Learning 与卷积神经网络作为函数逼近器相结合,将原始像素映射到动作价值函数里。
除此之外,价值分布强化学习(Bellemare et al., 2017)提出了一种通过 C51 算法预测可能值函数 bin 上的分布技术。Rainbow DQN 将上述所有技术组合在单一的异策略算法中,用以实现 Atari 基准的最新 sample efficiency。此外,Rainbow 还使用了多步回报(Sutton et al.,1998)。
CURL 的关键部分是使用对比无监督学习来学习高维数据的丰富表示的能力。对比学习可以理解为可区分的字典查找任务。给定一个查询 q、键 K= {k_0, k_1, . . . } 以及一个明确的 K(关于 q)P(K) = ({k+}, K \ {k+}) 分区,对比学习的目标是确保 q 与 k +的匹配程度比 K \ {k +} 中的任何的键都更大。在对比学习中,q,K,k +和 K \ {k +} 也分别称为锚点(anchor),目标(targets),正样本(positive), 负样本(negatives)。
CURL 通过将训练对比目标作为批更新时的辅助损失函数,在最小程度上改变基础 RL 算法。在实验中,研究者将 CURL 与两个无模型 RL 算法一同训练——SAC 用于 DMControl 实验,Rainbow DQN 用于 Atari 实验。
CURL 使用的实例判别方法(instance discrimination)类似于 SimCLR、MoC 和 CPC。大多数深度强化学习框架采用一系列堆叠在一起的图像作为输入。因此,算法在多个堆叠的帧中进行实例判别,而不是单一的图像实例。
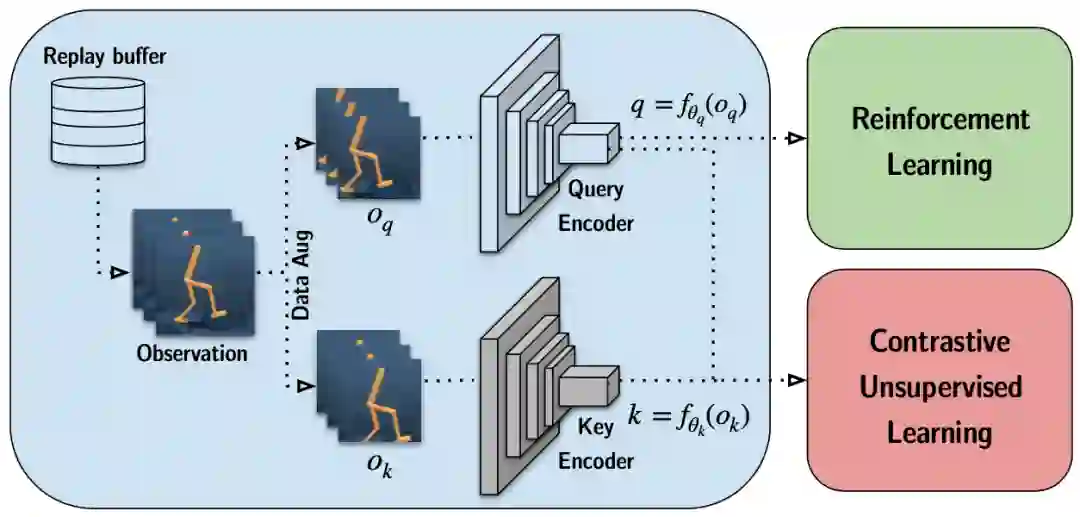
研究者发现,使用类似于 MoCo 的动量编码流程(momentum encoding)来处理目标,在 RL 中性能较好。最后,研究者使用一个类似于 CPC 中的双线性内积来处理 InfoNCE score 方程,研究者发现效果比 MoCo 和 SimCLR 中的单位范数向量积(unit norm vector products)要好。对比表征和 RL 算法一同进行训练,同时从对比目标和 Q 函数中获得梯度。总体框架如下图所示。
![]()
选择关于一个锚点的正、负样本是对比表征学习的其中一个关键组成部分。
不同于在同一张图像上的 image-patches,判别变换后的图像实例优化带有 InfoNCE 损失项的简化实例判别目标函数,并需要最小化对结构的调整。在 RL 设定下,选择更简化判别目标的理由主要有如下两点:
因此,CURL 使用实例判别而不是 patch 判别。我们可将类似于 SimCLR 和 MoCo 这样的对比实例判别设置,看做最大化一张图像与其对应增广版本之间的共同信息。
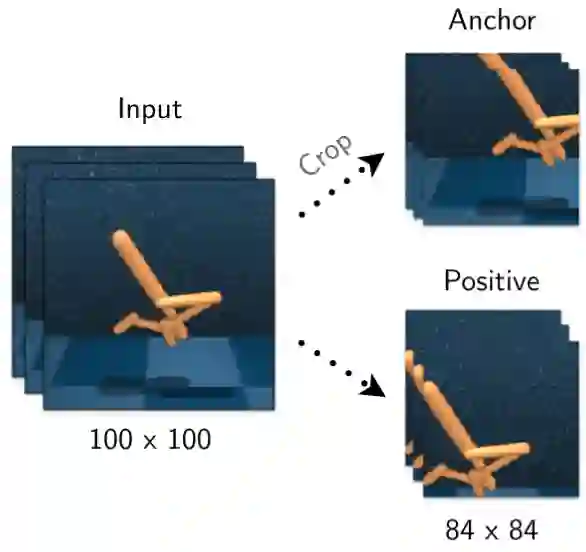
类似于在图像设定下的实例判别,锚点和正观测值是来自同一幅图像的两个不同增广值,而负观测值则来源于其他图像。CURL 主要依靠随机裁切数据增广方法,从原始渲染图像中随机裁切一个正方形的 patch。
研究者在批数据上使用随机数据增广,但在同一堆帧之间保持一致,以保留观测值时间结构的信息。数据增广流程如图 3 所示。
![]()
图 3: 使用随机裁剪产生锚点与其正样本过程的直观展示。
区分目标中的另一个决定因素是用于测量查询键对之间的内部乘积。CURL 采用双线性内积 sim(q,k)= q^TW_k,其中 W 是学习的参数矩阵。研究团队发现这种相似性度量的性能优于最近在计算机视觉(如 MoCo 和 SimCLR)中最新的对比学习方法中使用的标准化点积。
在 CURL 中使用对比学习的目标是训练从高维像素中能映射到更多语义隐状态的编码器。InfoNCE 是一种无监督的损失,它通过学习编码器 f_q 和 f_k 将原始锚点(查询)x_q 和目标(关键字)x_k 映射到潜在值 q = f_q(x_q) 和 k = f_k(x_k) 上,在此团队应用相似点积。通常在锚点和目标映射之间共享相同的编码器,即 f_q = f_k。
CURL 将帧-堆栈实例的识别与目标的动量编码结合在一起,同时 RL 是在编码器特征之上执行的。
![]()
研究者评估(i)sample-efficiency,方法具体为测量表现最佳的基线需要多少个交互步骤才能与 100k 交互步骤的 CURL 性能相匹配,以及(ii)通过测量 CURL 取得的周期回报值与最佳表现基线的比例来对性能层面的 100k 步骤进行衡量。换句话说,当谈到数据或 sample-efficiency 时,其实指的是(i),而当谈起性能时则指的是(ii)。
CURL 是我们在每个 DMControl 环境上进行基准测试的 SOTA ImageBased RL 算法,用于根据现有的 Image-based 的基准进行采样效率测试。在 DMControl100k 上,CURL 的性能比 Dreamer(Hafner 等人,2019)高 2.8 倍,这是一种领先的 model-based 的方法,并且数据效率高 9.9 倍。
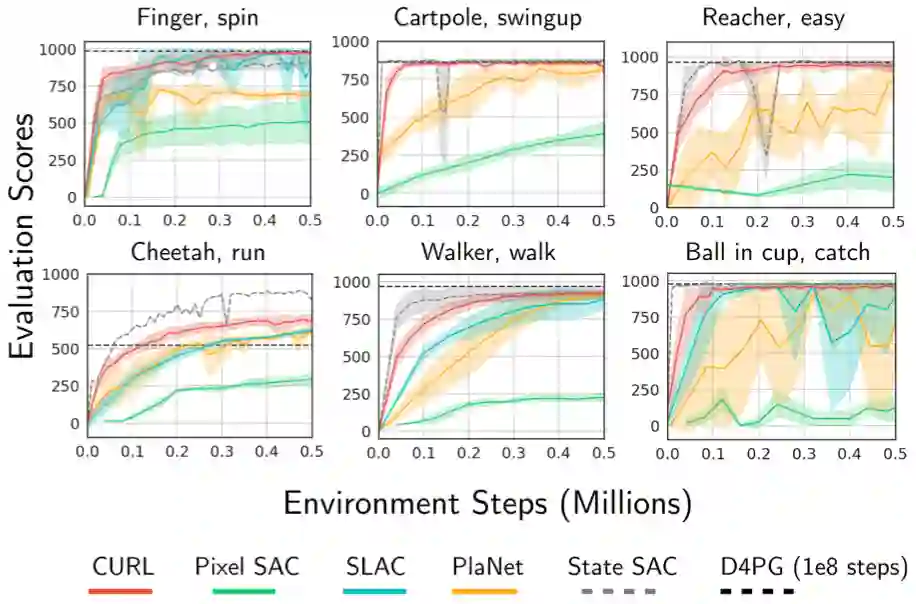
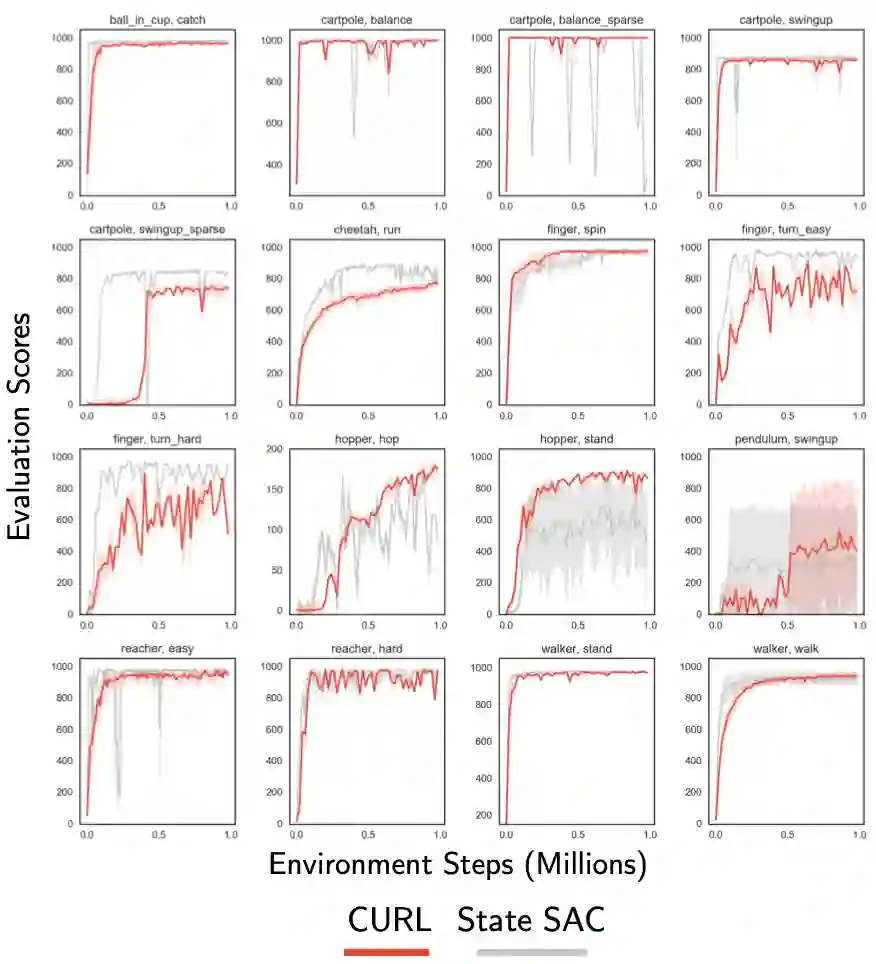
从图 7 所示的大多数 16 种 DMControl 环境中的状态开始,仅靠像素操作的 CURL 几乎可以进行匹配(有时甚至超过)SAC 的采样效率。它是基于 model-based,model-free,有辅助任务或者是没有辅助任务。
在 50 万步之内,CURL 解决了 16 个 DMControl 实验中的大多数(收敛到接近 1000 的最佳分数)。它在短短 10 万步的时间内就具有与 SOTA 相似性能的竞争力,并且大大优于该方案中的其他方法。
![]()
表 1. 在 500k(DMControl500k)和 100k(DMControl100k)环境步长基准下,CURL 和 DMControl 基准上获得的基线得分。
![]()
图 4. 相对于 SLAC、PlaNet、Pixel SAC 和 State SAC 基线,平均 10 个 seeds 的 CURL 耦合 SAC 性能。
![]()
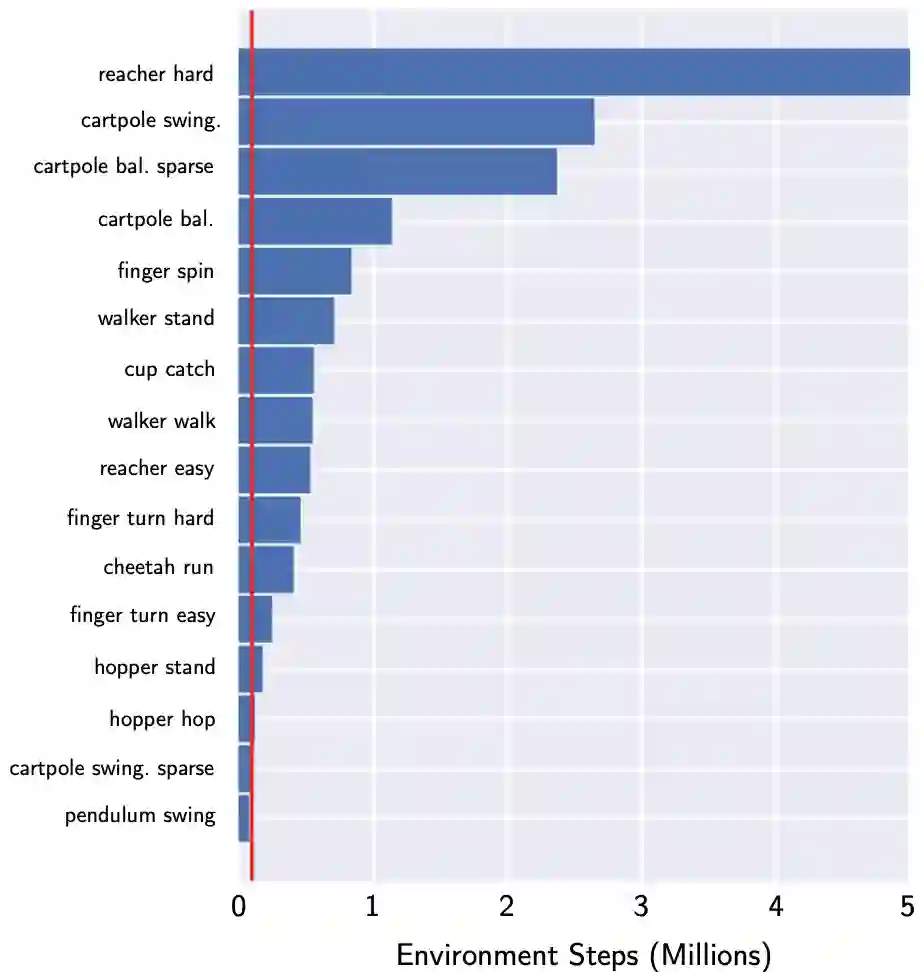
图 6. 要获得与 CURL 在 100k 训练步骤中所得分相同的分数,需要先行采用领先的 pixel-based 方法 Dreamer 的步骤数。
![]()
图 7. 将 CURL 与 state-based 的 SAC 进行比较,在 16 个所选 DMControl 环境中的每个环境上运行 2 个 seeds。
就大多数 26 项 Atari100k 实验的数据效率而言,CURL 是 SOTA PixelBased RL 算法。平均而言,在 Atari100k 上,CURL 的性能比 SimPLe 高 1.6 倍,而 Efficient Rainbow DQN 则高 2.5 倍。
CURL 达到 24%的人类标准化分数(HNS),而 SimPLe 和 Efficient Rainbow DQN 分别达到 13.5%和 14.7%。CURL,SimPLe 和 Efficient Rainbow DQN 的平均 HNS 分别为 37.3%,39%和 23.8%。
CURL 在三款游戏 JamesBond(98.4%HNS),Freeway(94.2%HNS)和 Road Runner(86.5%HNS)上几乎可以与人类的效率相提并论,这在所有 pixel-based 的 RL 算法中均属首例。
表 2. 通过 CURL 和以 10 万个时间步长(Atari100k)为标准所获得的分数。CURL 在 26 个环境中的 14 个环境中实现了 SOTA。
![]()
所有相关项都在 conda_env.yml 文件中。它们可以手动安装,也可以使用以下命令安装:
conda env create -f conda_env.yml
要从基于图像的观察中训练 CURL agent 完成 cartpole swingup 任务,请从该目录的根目录运行 bash script/run.sh。run.sh 文件包含以下命令,也可以对其进行修改以尝试不同的环境/超参数。
CUDA_VISIBLE_DEVICES=0 python train.py \
--domain_name cartpole \
--task_name swingup \
--encoder_type pixel \
--action_repeat 8 \
--save_tb --pre_transform_image_size 100 --image_size 84 \
--work_dir ./tmp \
--agent curl_sac --frame_stack 3 \
--seed -1 --critic_lr 1e-3 --actor_lr 1e-3 --eval_freq 10000 --batch_size 128 --num_train_steps 1000000
| train | E: 221 | S: 28000 | D: 18.1 s | R: 785.2634 | BR: 3.8815 | A_LOSS: -305.7328 | CR_LOSS: 190.9854 | CU_LOSS: 0.0000
| train | E: 225 | S: 28500 | D: 18.6 s | R: 832.4937 | BR: 3.9644 | A_LOSS: -308.7789 | CR_LOSS: 126.0638 | CU_LOSS: 0.0000
| train | E: 229 | S: 29000 | D: 18.8 s | R: 683.6702 | BR: 3.7384 | A_LOSS: -311.3941 | CR_LOSS: 140.2573 | CU_LOSS: 0.0000
| train | E: 233 | S: 29500 | D: 19.6 s | R: 838.0947 | BR: 3.7254 | A_LOSS: -316.9415 | CR_LOSS: 136.5304 | CU_LOSS: 0.0000
cartpole swing up 的最高分数约为 845 分。而且,CURL 如何以小于 50k 的步长解决 visual cartpole。根据使用者的 GPU 不同而定,大约需要一个小时的训练。同时作为参考,最新的端到端方法 D4PG 需要 50M 的 timesteps 来解决相同的问题。
Log abbreviation mapping:
train - training episode
E - total number of episodes
S - total number of environment steps
D - duration in seconds to train 1 episode
R - mean episode reward
BR - average reward of sampled batch
A_LOSS - average loss of actor
CR_LOSS - average loss of critic
CU_LOSS - average loss of the CURL encoder
与运行相关的所有数据都存储在指定的 working_dir 中。若要启用模型或视频保存,请使用--save_model 或--save_video。而对于所有可用的标志,需要检查 train.py。使用 tensorboard 运行来进行可视化:
tensorboard --logdir log --port 6006
同时在浏览器中转到 localhost:6006。如果运行异常,可以尝试使用 ssh 进行端口转发。
对于使用 GPU 加速渲染,确保在计算机上安装了 EGL 并设置了 export MUJOCO_GL = egl。
机器之心联合 AWS 开设线上公开课,通过 6 次直播课程帮助大家熟悉 Amazon SageMaker 各项组件的使用方法,轻松玩转机器学习。
5 月 28 日 20:00,AWS 应用科学家王鹤男带来第 2 课,详解如何使用 SageMaker 运行基于 TensorFlow 的中文命名实体识别。识别二维码,立即预约直播。
![]()