KDD 2020最佳论文揭晓!杜克大学陈怡然组获最佳学生论文奖,清华入选论文实力霸榜

新智元报道
新智元报道
来源:KDD
编辑:雅新、小匀
【新智元导读】KDD 2020最佳论文新鲜出炉!最佳学生论文、最佳论文亚军均被华人学生(一作)摘得,来看看这些论文出自谁之手吧!
KDD Best Paper 终于来了!
受疫情影响,今年第26届国际数据挖掘顶会 ACM SIGKDD 于8月23日-27日以虚拟线上方式召开。

近日,KDD 2020公布了最佳论文奖、最佳学生论文奖等多个奖项。
其中由谷歌研究院的研究者Walid Krichene和Steffen Rendle获得最佳论文奖,杜克大学的 Ang Li、Huanrui Yang、陈怡然和北航段逸骁、杨建磊获得本届会议的最佳学生论文奖。
此外,汤继良、盛胜利、唐杰等华人学者在本届 SIGKDD 大会上也获得了多项大奖。
最佳论文
最佳论文奖由来自谷歌研究院的Walid Krichene和Steffen Rendle获得,获奖题目为「On Sampled Metrics for Item Recommendation」

论文链接:http://walid.krichene.net/papers/KDD-sampled-metrics.pdf
这篇论文主要对抽样指标进行了详细的研究。在该项目中是使用依赖于相关项目位置的排名指标算法来进行评估,在任务中需要在给定的上下文情况下来对大量的项目进行排序。结果发现这些抽样指标与精确的度量值不一致,因为它们没有保留相关的语句。而研究者证明了一种可行的方法就是通过应用一个修正项,即最小化不同的标准,如偏差或均方误差,来提高抽样指标的性能。最后通过对原始抽样指标及其修正变量实证评估,研究者建议在度量计算中应避免抽样,但是如果实验研究需要抽样,那么他们所提出的修正项可以提高估计的质量。
最佳学生论文
杜克大学的 Ang Li、Huanrui Yang、陈怡然和北京航空航天大学的段逸骁、杨建磊摘得最佳学生论文奖,获奖论文为「TIPRDC: Task-Independent Privacy-Respecting Data Crowdsourcing Framework for Deep Learning with Anonymized Intermediate Representations」。

论文链接:https://arxiv.org/pdf/2005.11480.pdf
这篇论文的研究人员提出了一种基于匿名中间表示的任务无关隐私的数据众包框架TIPRDC。该框架的目标是学习一个特征抽取器,它可以隐藏中间表征中的隐私信息,同时最大限度地保留原始数据中嵌入的原始信息,供数据采集器完成未知的学习任务。
研究人员设计了一种混合训练方法来学习匿名中间表示:
1 针对特征隐藏隐私信息的对抗性训练过程
2 使用基于神经网络的互信息估计器最大限度地保留原始信息
通过对TIPRDC进行广泛评估,并将其与使用两个图像数据集和一个文本数据集的现有方法进行了比较。结果表明,TIPRDC大大优于其他现有的方法。
这篇论文第一作者 Ang Li 是杜克大学电子和计算机工程系的一名在读博士,导师为陈怡然和 Hai (Helen) Li 教授。
Ang Li 的主要研究方向是移动和物联网平台上的深度学习系统。他曾在 2018 年获得阿肯色大学计算机科学博士学位,2013 年获得北京大学软件工程硕士学位,2010 年获得河南大学计算机科学本科学位。

Ang Li 目前还是阿里巴巴达摩院的一位实习生。

Ang Li 主页:https://www.linkedin.com/in/ang-li-3658273b/
他的导师陈怡然教授还在微博上表示庆祝团队成员摘得最佳学生论文奖。陈怡然教授现任杜克大学电子与计算机工程系教授、杜克大学计算进化智能中心主任、美国 NSF 新型可持续智能计算中心主任。

最佳论文亚军
来自弗吉尼亚大学的 Mengdi Huai、Jianhui Sun、Renqin Cai、Aidong Zhang 和来自纽约州立大学布法罗分校的 Liuyi Yao 获得了最佳论文的亚军,获奖论文是「Malicious Attacks against Deep Reinforcement Learning Interpretations」。

论文链接:https://dl.acm.org/doi/pdf/10.1145/3394486.3403089
这篇论文将深度学习和强化学习结合(DRL),并证明了其在众多序列决策问题中动态建模的能力。为了提高模型的透明度,已经有研究提出了针对 DRL 的各种解释方法。但是,这些 DRL 解释方法隐式地假定它们是在可靠和安全的环境中执行的,但在实际应用中并非如此。弗吉尼亚大学的研究团队调查了一些 DRL 解释方法在恶意环境中的漏洞,他们提出了第一个针对 DRL 解释的对抗性攻击的研究,提出了一个优化框架来解决所研究的对抗性攻击问题。
论文第一作者Mengdi Huai 是弗吉尼亚大学计算机系在读博士生,导师为Aidong Zhang。她的研究兴趣是数据挖掘和ML,尤其是对可解释机器学习,对抗性机器学习,隐私保护数据挖掘,深度强化学习,元学习,成对学习和医疗保健数据挖掘感兴趣。

个人主页:http://www.cs.virginia.edu/~mh6ck/
KDD 2020 全部论文摘要传送门:
https://www.paperdigest.org/wp-content/uploads/2020/08/KDD-2020-Paper-Digests.pdf
KDD 2020 华人学者入选情况
据Aminer统计,来自美国伊利诺伊大学香槟分校计算机系教授韩家炜共入选7篇,位列华人榜首。曾发表过1244篇论文的他,如今论文引用数已达到了183044。

第二名是来自阿里集团的杨红霞,现任阿里巴巴资深算法专家。共入选6篇,相较于去年增加了2篇。

与第二名并列的两位学者,一位来自清华大学计算机科学与技术系的崔鹏教授,另一位是美国罗格斯-新泽西州立大学罗格斯商学院管理科学与信息系统系终身教授熊辉,现任百度研究院副院长。


共入选5篇论文的是美国密歇根大学终身教授叶杰平。

来自百度研究院的周景博共有4篇论文入选。

在一作华人学生榜单中,来自康奈尔大学威尔康奈尔医学院 Chengxi Zang 入选4篇论文位列第一。

在Research track中,个人以及机构论文数量如下表:
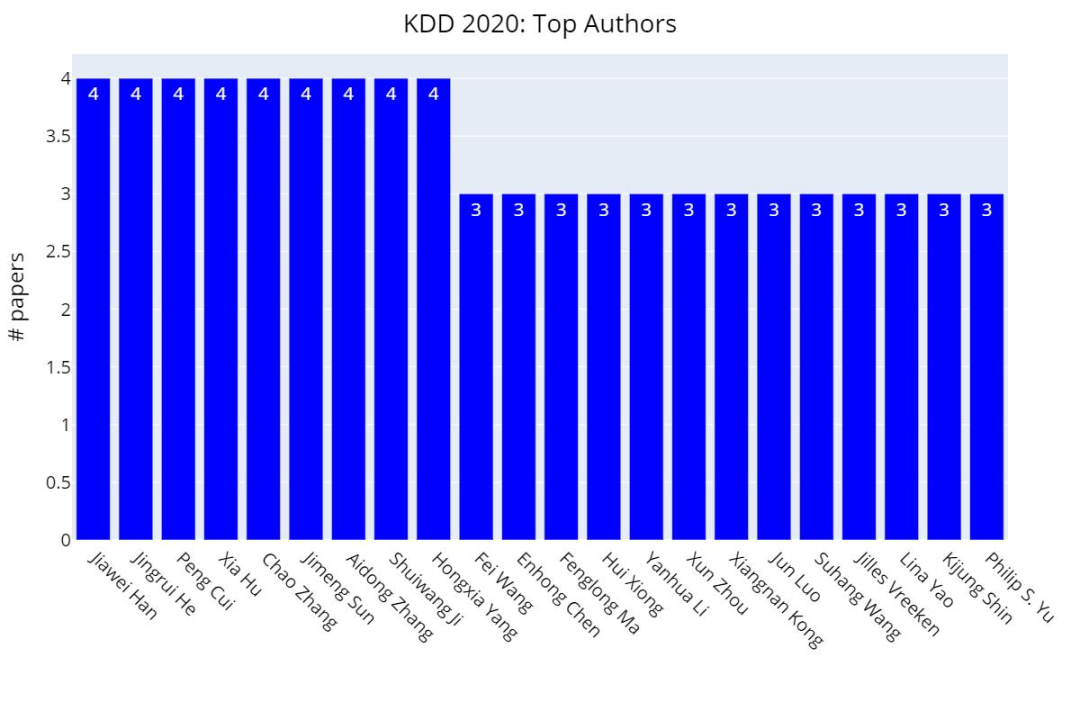
KDD 2020:作者论文数量排行
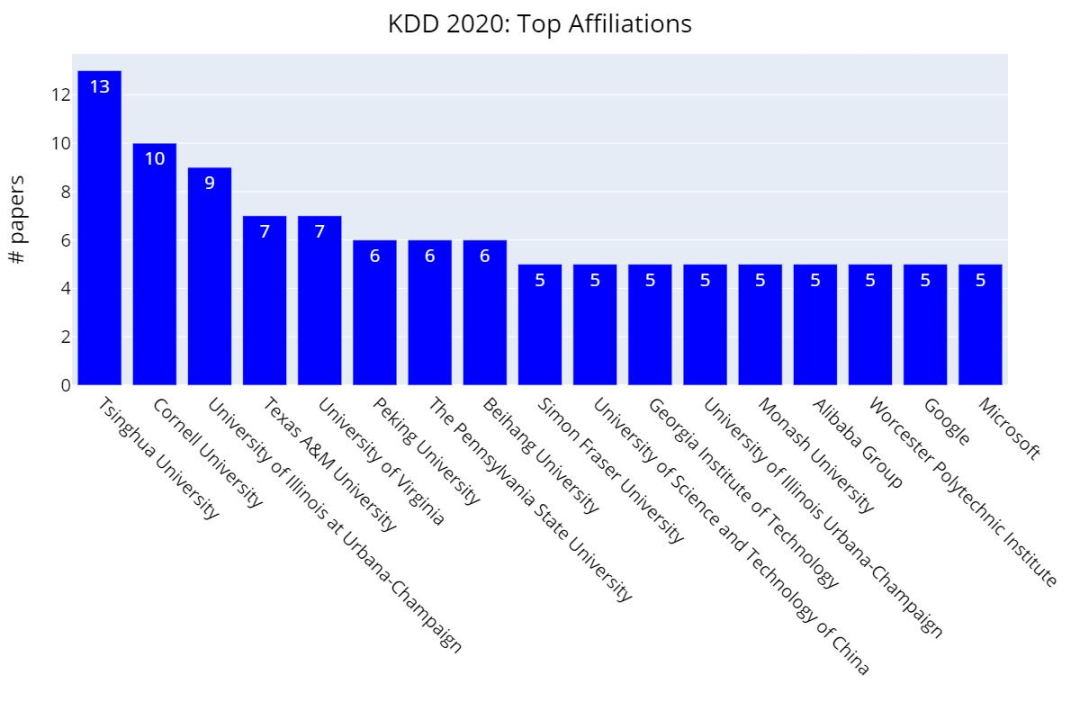
KDD 2020:机构论文数量排行
值得一提的是,无论是从高校还是个人上来说,中国都远远领先其他国家。与ICML2020相比,MIT、斯坦福、Facebook等高校或大型科技公司明显较少。
今年的KDD依然保持着申请量创历史新高的趋势,并刷新了最高纪录。
总共进行了2035次有效提交,这是KDD历史上的最高提交数量(比第二高的提交数量高出13%):Research track为1279,Applied Data Science track为756。经过审查,最终接收了338篇论文(Research track为217篇,Applied Data Science track为121篇)。
让我们来看一下今年的流行趋势词:

包括图表、推荐、对抗攻击、生成模型等。图形与推荐系统一直是KDD的「宠儿」,其他热门话题还包括聚类(Clustering)、算法的公平性(Fairness)和数据挖掘算法( Data Mining Algorithm)。
图机器学习(Graph machine Learning)
与图表相关的论文占接收总数的约30%。其中以用于实际应用为主题的新图形神经网络模型居多,例如分子预测与推荐系统。
还有通过PageRank、最小方差抽样、大、小、无冗余模型解决GNN模型计算的复杂性。
其他也包括网络挖掘(Graph Mining)中的各种主题,包括聚类、绘图、摘要
推荐系统(Recommender System)
旨在解决现代推荐系统问题约占15%。包括反事实学习,推荐解决Google云端硬盘位置偏见、优化广告和推荐策略的RL框架等。
四大主题演讲
一年一度的SIGKDD会议是数据的「盛宴」。在数据科学、数据挖掘、知识发现、大规模数据分析和大数据领域等领域,SIGKDD会议会带来最前沿的同行分享机会。四场主题演讲如下:
用于智能金融服务的AI:示例和讨论(AI for Intelligent Financial Services: Examples and Discussion)
状态空间多锥度时频分析(A Look at State-Space Multi-Taper Time-Frequency Analysis)
通过元起源产生重要的解释(Generating Explanations that Matter through Meta-Provenance)
基于COVID-19下的计算流行病学(Computational Epidemiology at the Time of COVID-19)
参考链接:
https://medium.com/criteo-labs/kdd-2020-highlights-f4de20af5d4
https://medium.com/criteo-labs/kdd-2020-highlights-f4de20af5d4
https://www.aminer.cn/conf/kdd2020





