图灵奖获得者Yann LeCun :学习“世界模型”的能力是构建人类级AI的关键所在

本文最初发布于 Meta AI 博客,由 InfoQ 中文站翻译并分享。
尽管人工智能研究最近取得了显著进展,但我们离创造出像人一样善于思考和学习的机器还很远。正如 Meta AI 首席人工智能科学家 Yann LeCun 所指出的那样,一个从未摸过方向盘的青少年可以在大约 20 个小时内学会开车,而当今最好的自动驾驶系统也需要数百万甚至数十亿带标签的训练数据和数百万次虚拟环境中的强化学习试验。即便如此,它们驾驶汽车也还是不如人类可靠。
构建接近人类水平的人工智能需要什么?仅仅是更多的数据和更大的人工智能模型吗?
作为 2022 年 2 月 23 日 Meta AI 实验室内部活动的一部分,LeCun 勾勒了一个构建人类级 AI 的愿景。LeCun 提出,学习“世界模型”的能力——关于世界如何运作的内部模型——可能是关键所在。
Meta AI 在此简要分享下 LeCun 的一些想法,包括他对模块化、可配置的自主智能架构的建议,以及人工智能研究界为构建这样一个系统必须解决的关键挑战。我们通常在研究完成后,通过发表论文、代码和数据集以及博客文章来分享我们的研究成果。但为了与 Meta AI 开放科学方法保持一致,我们借此机会介绍下我们的研究愿景和思路,希望激发人工智能研究人员之间的讨论与合作。一个简单的事实是,我们需要共同合作来解决这些极具挑战性的、令人兴奋的问题。
我们计划在即将发布的建议书中分享有关 LeCun 愿景的更多细节。
“人类和非人类动物似乎能够通过观察和少量难以理解的互动,以一种与任务无关的、无监督的方式学习关于世界如何运作的大量背景知识,“LeCun 说。”根据推测,这样积累的知识可能就构成了我们通常所说的常识的基础。”
而常识可以看作是世界模型的集合,可以解释什么可能,什么合理,什么不可能。
这使得人类能够在不熟悉的情况下有效地进行计划。例如,那个青少年司机可能以前没有在雪地上开过车,但他(很可能)知道雪地会很滑,如果开得太猛,车就会打滑。
常识性知识使动物不仅能够预测未来的结果,而且能够填补缺失的信息,无论是时间上的还是空间上的。当司机听到附近有金属撞击的声音时,马上就知道发生了事故——即使没有看到相关的车辆。
人类、动物和智能系统使用世界模型的想法可以追溯到几十年前的心理学和工程领域,如控制与机器人学。LeCun 提出,当今人工智能最重要的挑战之一是设计学习范式和架构,使机器能够以自监督的方式学习世界模型,然后使用这些模型进行预测、推理和规划。 他在纲要中重新组合了不同学科提出的观点,如认知科学、系统神经科学、最优控制、强化学习和“传统”人工智能,并将它们与机器学习的新概念相结合,如自监督学习和联合嵌入架构。
LeCun 提出了一个自主智能的架构,它由六个独立的模块组成。每个模块都是可微分的,因为它可以很容易地计算出一些目标函数相对于其自身输入的梯度估计,并将梯度信息传播给上游模块。
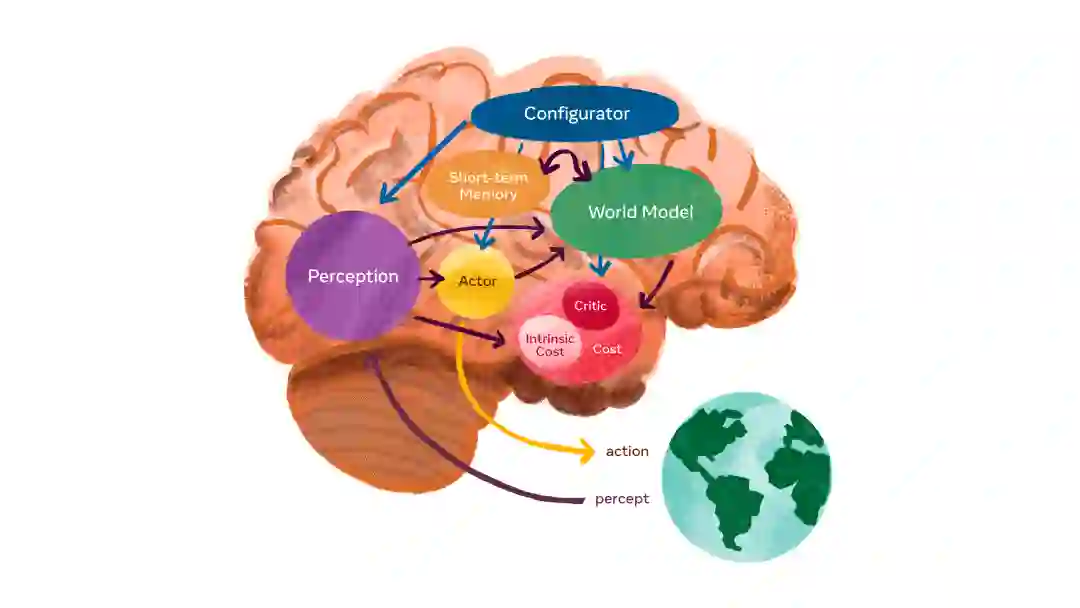
自主智能的系统架构。配置器从其他模块获得输入,但为了简化图表,我们省略了这些箭头。
配置器模块负责执行控制。给定一个要执行的任务,它会针对这项任务预先配置感知模块、世界模型、成本和行为者,可能是通过调整这些模块的参数。
感知模块接收来自传感器的信号并估计世界当前的状态。对于一个特定的任务,感知到的世界状态只有一小部分是相关和有用的。配置器模块预先通知感知系统,从感知到的状态中提取与当前任务相关的信息。
世界模型模块是这个架构中最复杂的部分。它有两个作用:(1)评估感知未能提供的关于世界状态的缺失信息;(2)合理预测世界的未来状态。世界模型可以预测世界的自然演变,也可以预测由行为者模块采取的一系列行动所产生的未来世界状态。世界模型就像是一个与当前任务相关的这部分世界的模拟器。由于世界充满了不确定性,该模型必须能够代表多种可能的预测。司机可能会在靠近十字路口时放慢速度,以防另一辆靠近十字路口的车没有停在停车标志前。
成本模块会计算输出一个标量,预测代理的不适程度。它由两个子模块组成:内在成本模块,这是固有的,不可改变(不可训练),它负责计算即时不适(如对代理的损害,违反硬编码的行为约束等);批评者模块是一个可训练的模块,负责预测内在成本的未来值。代理的最终目标是长期保持内在成本最小化。LeCun 说:“这是基本的行为驱动和内在动机。“因此,它将考虑到内在成本,如不浪费能量以及特定于当前任务的成本。"因为成本模块是可微分的,所以成本的梯度可以通过其他模块反向传播,用于规划、推理或学习。”
行为者模块计算行动序列的建议。”行为者可以找到一个最佳行动序列,使预估的未来成本最小,并输出最佳序列中的第一个行动,其方式类似于经典的最优控制,“LeCun 说。
短期记忆模块记录了当前和预测的世界状态,以及相关成本。
世界模型架构和自监督训练
该架构的核心是预测性世界模型。构建这样一个模型的关键挑战是如何使它能够代表多种多样的合理预测。现实世界并不是完全可预测的:一个特定的情况可能有许多演变方式,而且,一个情况有许多细节与当前任务无关。当我开车时,我可能需要预测周围的汽车会做什么,但我不需要预测道旁树上个别树叶的准确位置。世界模型怎么样才能习得世界的抽象表示,保留重要的细节信息而忽略不相关的,并在抽象表示的空间里进行预测?
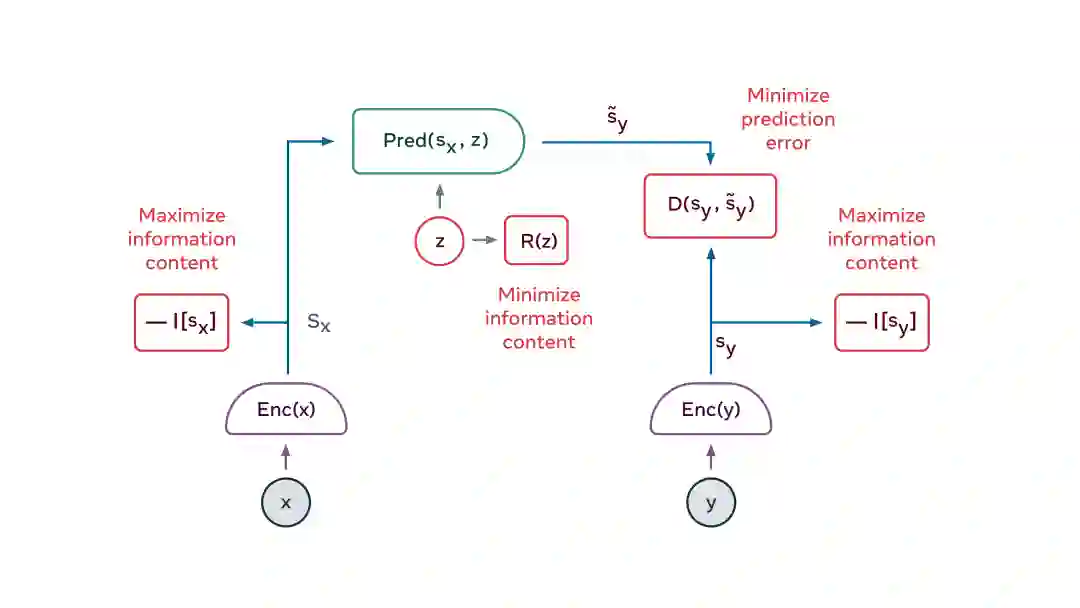
联合嵌入预测架构(JEPA)是解决方案的一个关键因素。JEPA 可以捕获两个输入 x 和 y 之间的依赖关系。例如,x 可能是一个视频片段,而 y 是该视频的下一个片段。将 x 和 y 输入可训练的编码器,提取出它们的抽象表示 sx 和 sy。训练一个预测器模块,它可以从 sx 预测 sy。预测器可以使用一个潜在变量 z 来表示 sy 中存在而 sx 中不存在的信息。JEPA 用两种方式处理预测的不确定性:(1) 编码器可以选择放弃 y 中难以预测的信息;(2)潜变量 z 在一个集合中取值时,预测也会在一组可信的预测中变化。
我们如何训练 JEPA?直到最近,还只有对比法一种方法,包括显示 x 和 y 兼容的例子,以及许多 x 和 y 不兼容的例子。但当向量表示维数很高时,就很不可行了。过去两年里出现了另一种训练策略:正则化方法。当应用于 JEPA 时,该方法使用四个标准:
使 x 的表示包含 x 的最大信息量;
使 y 的表示包含 y 的最大信息量;
能从 x 的表示最大限度地预测 y 的表示;
使预测器尽可能少地使用潜在变量来表示预测的不确定性。这些标准可以通过各种方式转化为可微分的成本函数。一种方法是 VICReg 方法,其中
VICReg 是变量(Variance)、不变性(Invariance)、协方差正则化(Covariance Regularization)的缩写。VICReg 是通过保持 x 和 y 的分量的方差在某个阈值之上,并使这些分量尽可能地相互独立,来最大化 x 和 y 的表示包含的信息量。同时,该模型试图使 y 的表示可以从 x 的表示预测出来。此外,通过离散化、低维化、稀疏化或噪声化,使潜变量的信息量最小化。
JEPA 之美在于它自然生成了输入的信息性抽象表示,去掉了不相关的细节,并且可以用它来进行预测。这使得 JEPA 可以一层层叠加,习得更高层次的抽象表示,用于进行更长期的预测。例如有一个场景,在比较高的层次上可以描述为“一个厨师正在做法式薄饼”。我们可以预测,厨师会去拿面粉、牛奶和鸡蛋;混合原材料;把面糊舀到锅里;让面糊炸开;翻转可丽饼;然后重复上述过程。在较低的层次上,倒勺子包括舀一些面糊并在锅里摊开。再往下,可以精确到厨师的手每一毫秒的准确轨迹。在手的轨迹这么低的层次上,我们的世界模型只能做出短期的准确预测。但在更高的抽象层次上,它可以进行长期预测。
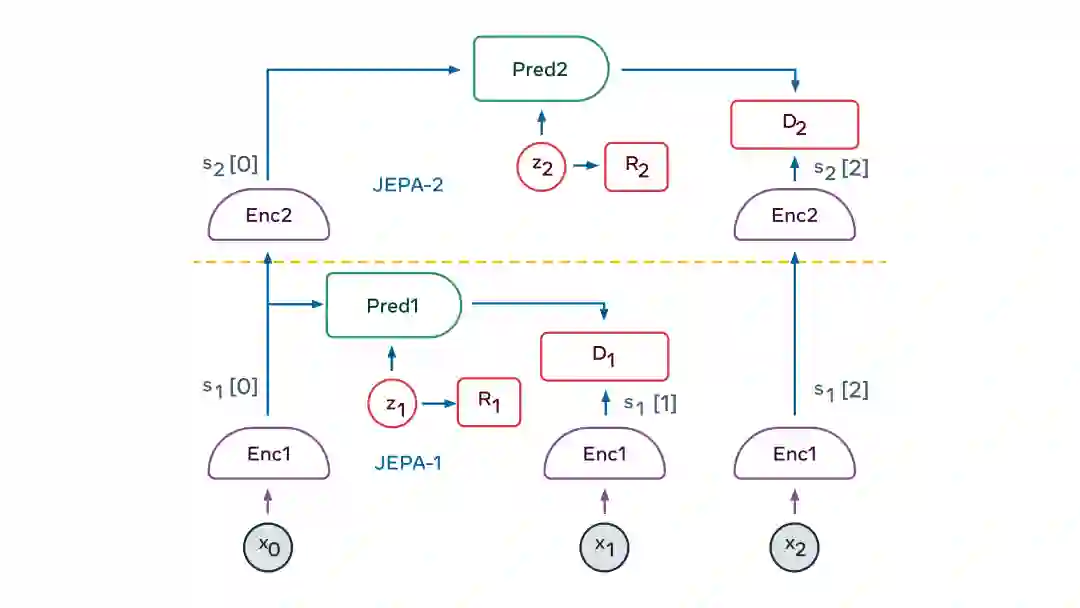
分层 JEPA 可用于在多个抽象层次和多个时间尺度上进行预测。它如何训练呢?主要是通过被动观察,少数时候通过互动。
婴儿在出生后的头几个月里主要是通过观察来了解世界的运作。她知道世界是三维的,一些物体在另一些物体的前面,当一个物体被遮挡时,它仍然存在。最终,在 9 个月大的时候,婴儿学会了直观的物理学知识,例如,没有支撑的物体在重力作用下坠落。
希望分层 JEPA 可以通过观看视频和与环境互动来学习世界的运作方式。通过训练自己预测视频中会发生什么,来生成世界的分层表示。通过在世界中采取行动并观察结果,世界模型将学会预测行动后果,使它能够进行推理和计划。
通过适当的训练将分层 JEPA 变成世界模型,代理可以对复杂的行动进行分层规划,将复杂的任务分解成一系列不太复杂、不太抽象的子任务,一直到效应器上的底层行动为止。
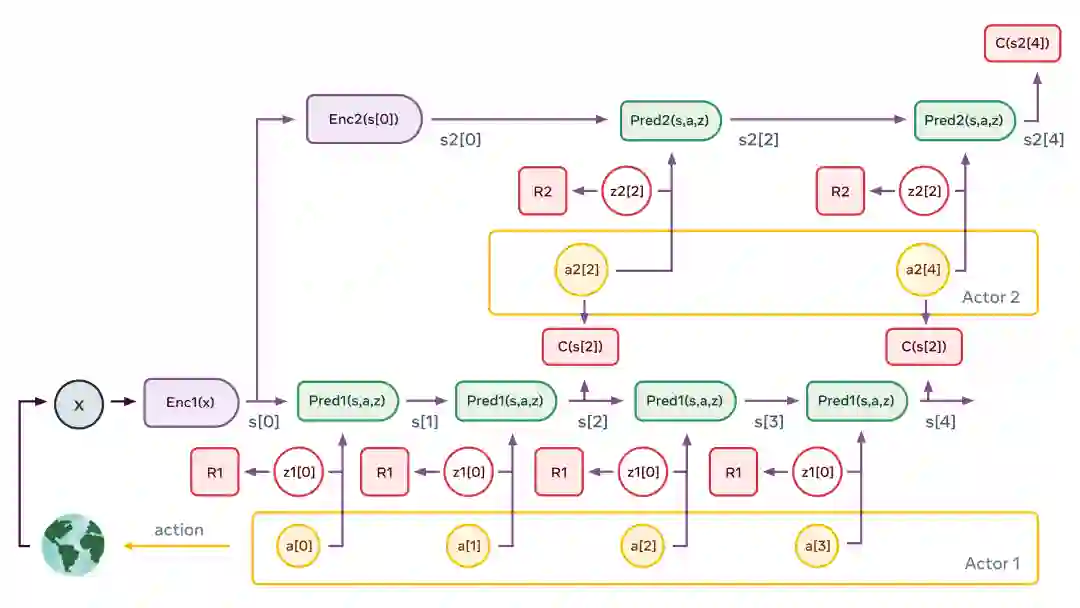
典型的感知 - 行动过程是这样的。该图说明了两层结构的情况。感知模块提取世界状态的层次表示(图中 s1[0]=Enc1(x),s2[0]=Enc2(s[0]))。然后,根据第二层行为者提出的抽象行动序列,多次应用第二层预测器预测未来状态。行动者会优化第二层行动序列,使总成本最小化(图中的 C(s2[4]))。这个过程类似于最优控制中的模型预测控制。这个过程会多次对二级潜变量进行重复绘制,可能产生不同的高层场景。由此产生的高层行动并不构成真正的行动,而只是定义了低层状态序列必须满足的约束条件(例如,各要素是否正确混合?) 。它们构成了真正的子目标。整个过程在较低的层次上重复:运行低层预测器,优化低层行动序列以最小化来自上层的中间成本,并重复这一过程对低层潜变量进行多次绘制。一旦这个过程完成,代理就将第一个低层行动输出给效应器,整个过程可以重复进行。
如果我们成功构建了这样一个模型,所有模块都是可微分的,那么整个行动优化过程就可以用基于梯度的方法进行。
这样一篇简短的博文无法聊透 LeCun 的愿景,前方还有许多困难的挑战。其中最有趣也最困难的是将世界模型的架构和训练过程实例化。事实上,可以说,训练世界模型是未来几十年人工智能真正有所进展需要克服的主要挑战。
但架构的许多其他方面仍有待定义,包括如何精确地训练批评者,如何构建和训练配置器,以及如何使用短期记忆来跟踪世界状态并存储世界状态的历史、行动和相关的内在成本来优化批评者。
LeCun 和 Meta AI 的其他研究人员期待在未来几个月甚至几年内探索这些问题,并与该领域的其他人交流想法及相互学习。创造能够像人类一样有效学习和理解的机器需要长期的科学努力——而且不能保证成功。但我们相信,基础研究将继续加深我们对思维和机器的理解,并将使每个人工智能用户从中受益。
查看英文原文:
https://ai.facebook.com/blog/yann-lecun-advances-in-ai-research?accessToken=eyJhbGciOiJIUzI1NiIsImtpZCI6ImRlZmF1bHQiLCJ0eXAiOiJKV1QifQ.eyJhdWQiOiJhY2Nlc3NfcmVzb3VyY2UiLCJleHAiOjE2NTE4Mjg0NTEsImZpbGVHVUlEIjoiZTFBejRPTzlnOFVkUlZxVyIsImlhdCI6MTY1MTgyODE1MSwidXNlcklkIjoyMDQxOTA5MH0.CjoZETnyH4qKFZfOXMw9oBEBklUtHQEqGky9ZVtVJQ4

你也「在看」吗?👇
