这篇文章是我学习群里一个小兄弟的面试总结,他是专科大三,很早之前找我指导了学习路线,学习很认真努力,目前他已经过了阿里一面。
在征求他同意的之后发我公众号上面,答案经过我重新整理。
https://m.nowcoder.com/discuss/226834
https://my.oschina.net/134596(无精疯)
一、PV和UV是怎么计算的,UV怎么进行去重的?不用ES该如何实现去重?
思路:首先要理解PV、UV的基本概念。去重分两种,一种是基本的数据结构(Hashset等),另外一种是借助框架去实现(bigmap、hyperloglog等)。
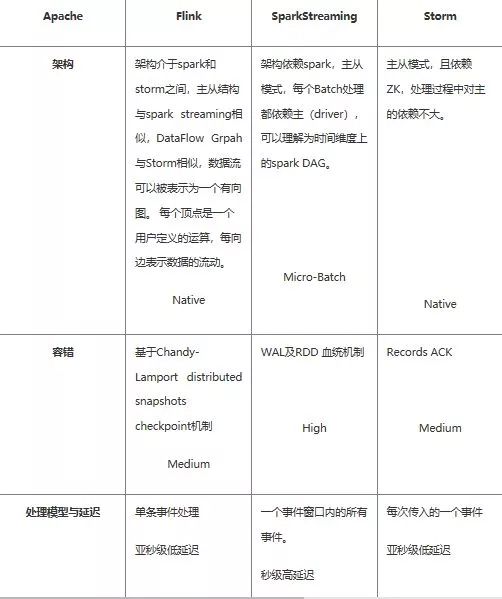
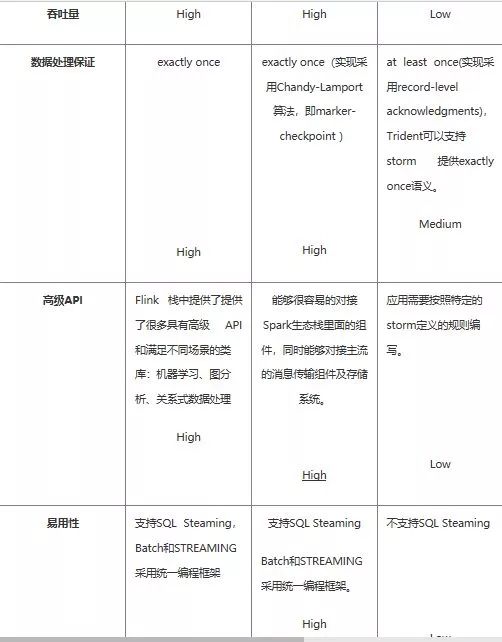
二、说说 flink,spark streaming,storm 的区别?
三、讲一讲spark的调度执行逻辑,stage,宽依赖和窄依赖,容错机制 ?
spark shuffle:因为具有某种共同的特征的一类数据需要最终汇聚 (aggregate)到一个计算节点进行计算 ,这个数据重新打乱然后汇聚到不同节点的过程就是 shuffle。
老版本:Hash Base shuffle 产生的临时文件数 = MapTask * ResultTask 。
新版本:SortBasedShuffle:产生的文件数 = MapTask 数量 。
但如果Shuffle不落地:①可能会造成内存溢出。②当某分区丢失时,会重新计算所有父分区数据
2. Stage:一个DAG会根据RDD之间的依赖关系进行Stage划分,流程是:以Action为基准,向前回溯,遇到宽依赖,就形成一个Stage。遇到窄依赖,则执行流水线优化(将多个连续的窄依赖放到一起执行)
a.窄依赖【Narrow Dependency 】(1:1):如 map ->flatMap等。
b. 宽依赖【Wide Dependency 】(1:多):如groupByKey()等。
窄依赖可以通过血缘关系来恢复故障RDD,而宽依赖则考虑使用检查点的方式恢复。
a.借助这些依赖关系,DAG可以认为这些RDD之间形成了 lineage(血统,血缘关系),借助lineage ,能保证一个RDD在计算前,它的 父RDD已经完成了计算,并实现了RDD的容错。
b.当某个RDD发生故障需要恢复时,从数据源逐步执行对应的 transformation 操作来重新生成当前的RDD,这种容错策略要高于常用的检查点(Check Pointing)策略。
四、HashMap源码,红黑树,阿里的好像都比较爱问HashMap,建议面试前着重准备一下?
答:建议面试前多看看hashmap的put函数和一些阈值;
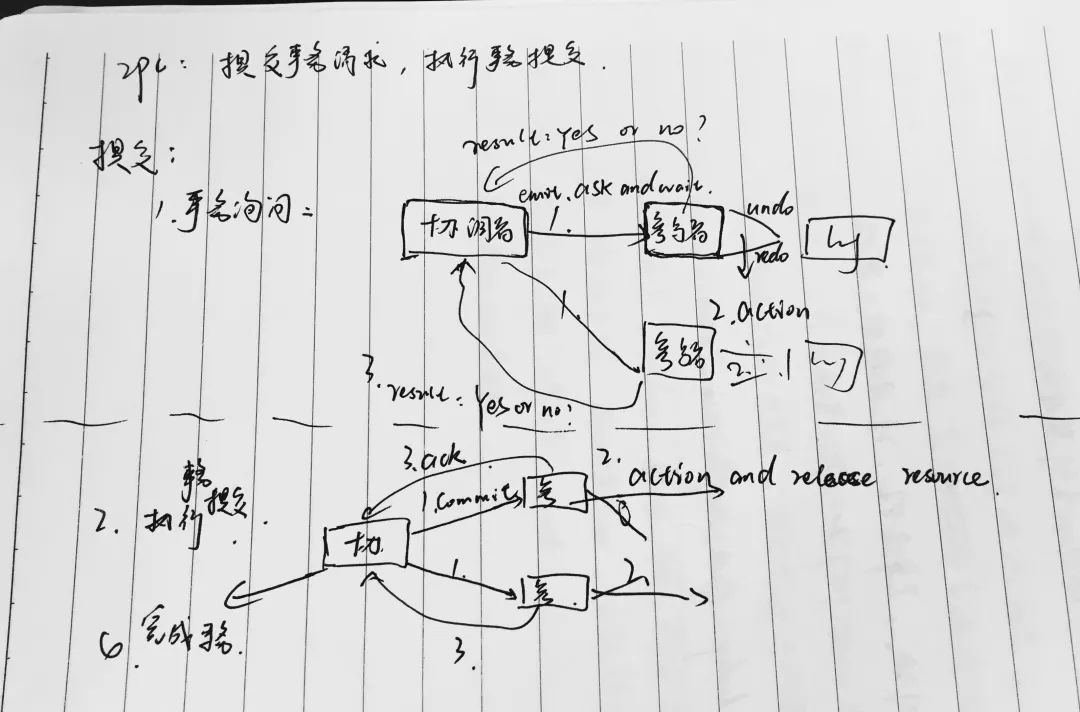
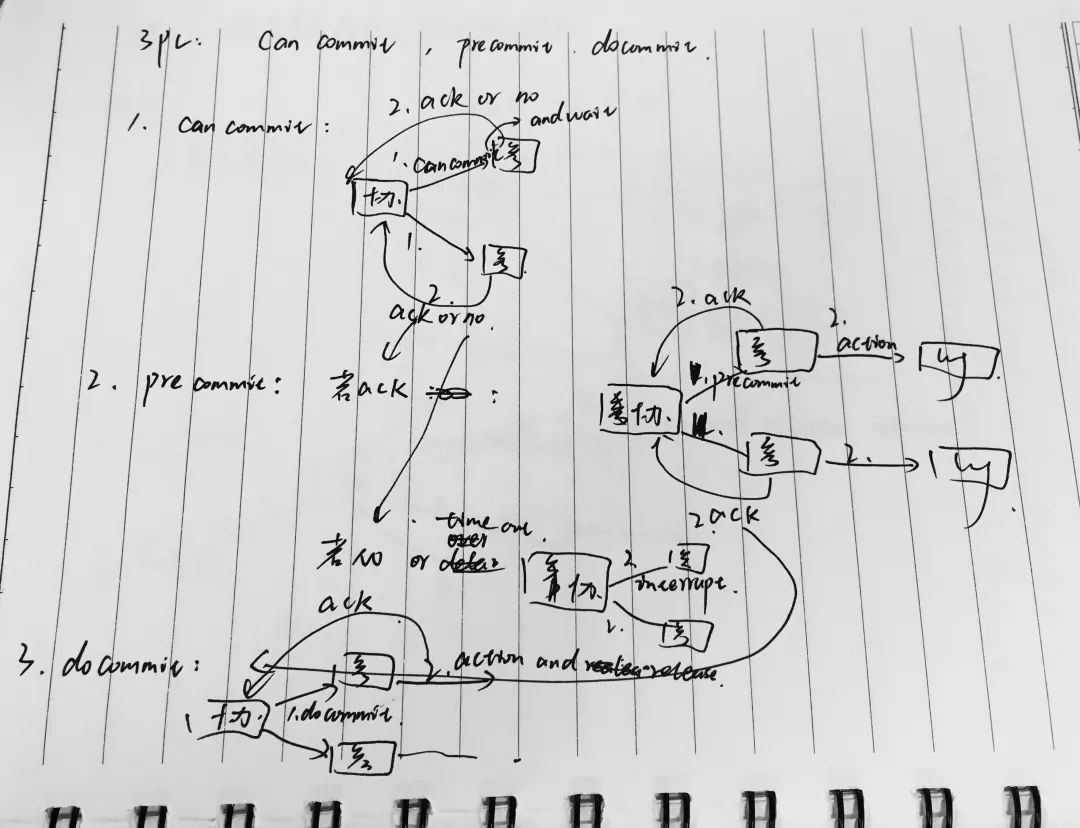
五、分布式一致性协议算法有哪些,说说它们?PC、3PC与Paxos
两阶段提交分为两个阶段,第一阶段是提交事务请求,第二阶段是执行事务提交。首先是提交事务请求,它分为三小步:1.首先就是事务询问,协调者向参与者发送事务内容,询问是否可以执行事务提交操作,并开始等待各参与者响应。2.然后就是执行事务,各参与者节点执行事务操作,并将undo和redo信息计入事务日志中。3.最后就是各参与者向协调者反馈事务询问的响应,如果参与者成功执行了事务操作,那么就反馈反馈给协调者YES响应,表示事务可以执行;如果参与者没有成功执行事务,那么反馈给协调者NO响应,表示事务不可以执行。
如果所有参与者都响应YES,那么就开始第二阶段。1.首先由协调者向所有参与者节点发出commit请求。2.参与者接收到commit请求后,会正式执行事务提交操作,并在完成提交后释放在整个事务执行期间占用的事务资源。3.然后参与者在完成事务提交之后,向协调者发送确认ack消息。4.协调者接收到所有参与者反馈的ack消息后,完成事务。
三阶段提交分为三个阶段,分别是cancommit, precommit, docommit.
1.首先是cancommit阶段,协调者向所有参与者发送事务内容在内的cancommit请求。并等待参与者的反馈。2.参与者收到cancommit请求后,若判断自己可以顺利执行事务,则向协调者发送ack响应,否则反馈NO相应。
3.然后就是precommit阶段,若协调者收到了所有参与者的ACK响应,则向所有的参与者发送precommit请求。4.参与者收到后执行事务,并将操作写入本地事务日志中,成功后向协调者发送ACK响应。若协调者在第一阶段的反馈中有NO,或者协调者等待超时,则向所有的参与者发送中断请求。
5最后是docommit,如果协调者收到第二阶段的所有参与者的ack请求,则向参与者发送docommit请求,执行事务的提交。参与者收到docommit请求后执行事务的提交,成功后释放事务资源,并向协调者发送ACK反馈。协调者收到所有的参与者反馈后,完成事务的提交。
若协调者等待超时,或者第二阶段中有参与者发送NO反馈,则向所有参与者发送中断请求。参与者收到后执行事务回滚,回滚结束后释放事务资源。参与者向协调发送ACK响应,协调者收到所有的ACK响应后中断事务。
优点:解决了同步阻塞问题(超时提交策略,第三阶段参与者等待超时后会提交事务)。由于precommit解决同步阻塞的问题。
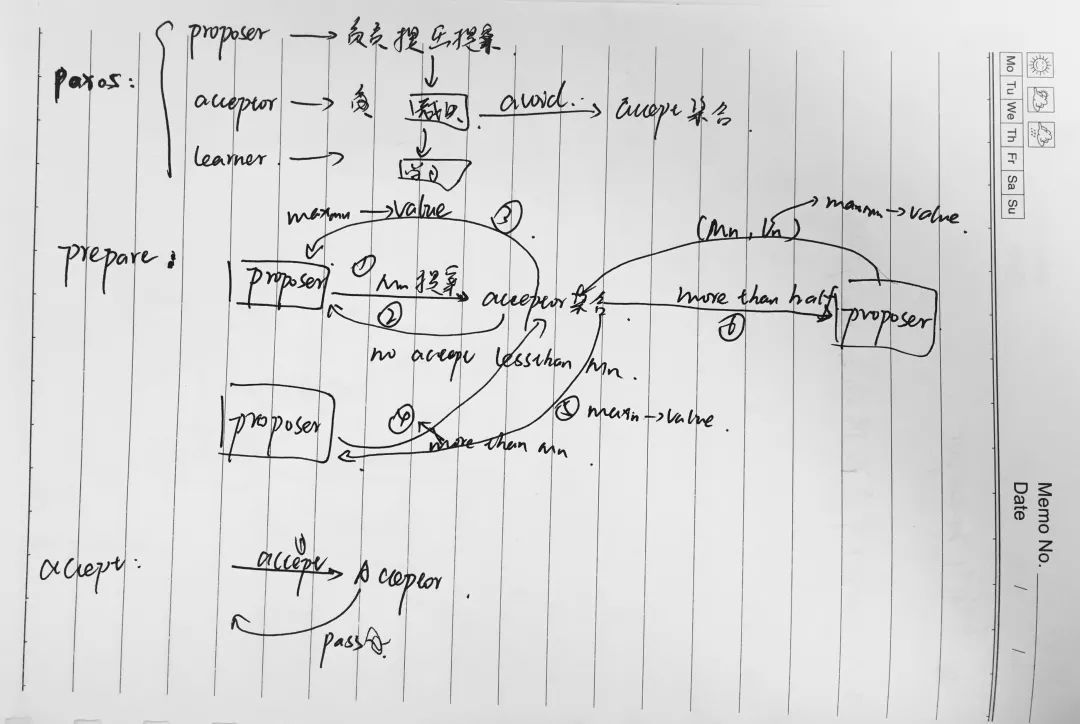
paxos算法是一种基于消息传递的且具有高度容错性的一种算法,解决的问题是一个分布式系统如何就某个值或者某个协议达成一致,该算法的前提是假设不存在拜占庭将军问题。
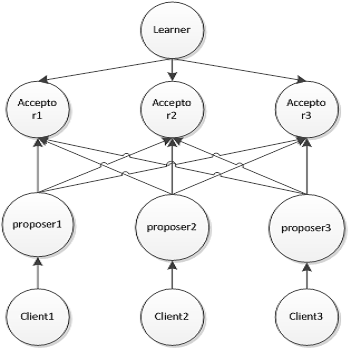
在该算法中一共有三种角色:proposer, accpetor和learner。proposer负责提出提案,acceptor负责对该提案做出裁决,learner负责学习得到的提案。为了避免单点故障,会有一个acceptor集合,proposer向该集合发送提案,acceptor集合中的每个成员都有可能同意该提案且每个acceptor只能批准一个提案,当有一半以上的成员同意,则同意该提案。
它主要分为两个阶段:分别是prepare阶段和accept阶段。首先是prepare阶段,先由proposer提出编号为Mn的提案,向accpetor集合发送prepare请求。Accept做出反馈:保证不会再接受编号比Mn小的提案;如果acceptor已经批准过某提案,会向proposer返回已经批准的编号最大的提案的value值。
如果acceptor收到一个编号为Mn的请求且编号大于accpetor已经响应的所有prepare请求的编号,则它会将自己已经批准过的编号最大的提案值反馈给proposer,同时acceptor承诺不会再接受编号比Mn小的提案。(优化:忽略编号小于已批准的提案的请求)。
如果proposer收到了集合至少一半的响应,则会发送一个针对Mn Vn的accept请求给Accpetor。Vn为收到的所有响应中编号最大的提案的值。如果响应不包括值,则可以由proposer选择任意值。
然后就是accpet阶段,accpet阶段是接受提案的要求。当Acceptor收到accpet请求后,只要未收到任何编号大于Mn的prepare请求,则通过该提案。
优化:为了避免死循环,比如两个proposer一次提出一系列编号递增的提案,可以产生一个主proposer,提案只能由主proposer负责提出。
paxos算法的应用:chubby(分布式锁服务、GFS中master选举)。
https://juejin.im/post/5ae1476ef265da0b8d419ef2
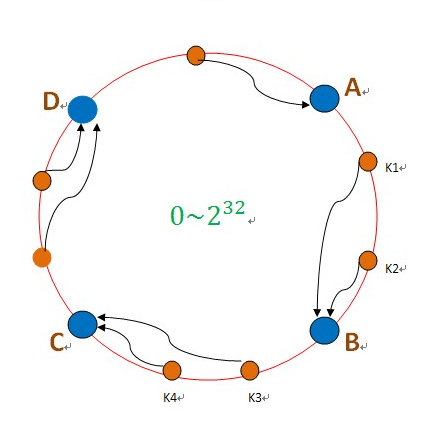
分布式哈希表(DHT) 是 P2P网络 和 分布式存储中常见的一种技术 ,是哈希表的分布式扩展,每台机器只负责承载部分数据,如何通过哈希方式对数据进行 增删改查等数据操作的技术。而"一致性哈希" 就是DHT其中的一种实现方式。
“一致性哈希”算法 将 (哈希数值空间) 按照(大小)组成一个首尾相接的环状序列。对于每台机器,可以根据其 (IP) 和 (端口号)经过 (哈希函数 )映射到 哈希数值空间内。每台机器就是环状序列的不同节点。
(注:假设 N 代表机器,i代表哈希空间对应的数值)
而每台机器负责存储落在一段有序哈希空间内的数据,比如N 14存储 经过哈希后落在6~14范围内的数据。同时每个机器节点 记录环中的前趋节点和后继节点的位置,使之成为一个真正的有向环。
a.低效率解决办法:沿着有向环顺序查找,接收到查询请求的节点,获得查询的主键的哈希值 ( j) 之后,判断是否在自身管理范围内,否的话就交给后继节点进行处理。直到 某个节点 Nx, x是>=j的最小编号节点。这样,最多遍历所有的节点也能找到 对应的结果。
b.高效率解决办法:为了加快查找速度,在每个节点配置路由表,路由表存储 m 条路由信息(m 为哈希空间的二进制数值比特位长度)。其中i 项 (0<=i<=m-1)路由信息表示距离上一个节点的2**i的距离的哈希空间内的节点。
七、说一下布隆过滤器(Bloom Filter)?
(自问知道的比较清楚,说了一点,我等他往更深层问呢,结果他直接就下一个问题了,早知道我就自己说完了。[是谁说阿里考官问知识点直到不会为止的,出来我要跟你理论理论])
场景:快速 从海量数据中找出某个成员是否属于这个集合。
a.特长:二进制向量数据结构,空间效率极高。因为 BF 使用位数组和哈希函数来表征集合,并不需要存储集合数据本身内容,所以其空间利用率非常高。
b.基本思想:长度为 m 的位数组来存储集合信息;k 个相互独立的哈希函数将数据映射到数组空间;对于集合S中的某个成员a,分别使用k个哈希函数对其进行计算,如果 H i(a)=x(1<=i<=k,1<=x<=m),则将位数组的第 x 位置为1,
c.查询:当查询某个成员a是否在集合S中出现时,使用相同的k个哈希函数计算,如果其对应位置全部为1,则a属于集合S,只要有一个位置为0,则a 不属于集合S。
使用场景:运行发生一定误判的场景,而在要求 100%精确判断的场景下不适合使用。
为什么会发生误判:假如此时再查询X3这个元素是否属于集合,通过3个哈希函数计算后的位置数为 2,7,11 ,而这时这3个位置都为1,BF会认为X3属于集合,这样岂不是误判了。
漏判:会发生误判但一定不会发生漏判,因为整个过程不存在将 1 改为 0的情况。
影响误判率的因素:1.集合大小 n。因为集合n越大,其它条件固定的情况下,位数组中就会有更多比例的位置被设成1,误判率就会增大。2. 哈希函数的个数k。个数越多,位数组中更多比例的位置被设置为1,即增大了 误判率。但在查询时,显然个数越多的时候误判率会越低。3. 位数组的大小 m。位数组大小 m越大,那么在 n和k固定的情况下,位数组中剩余0的比特位就越高,误判率就会减小。
已知 n,m 最优的哈希函数个数为:k = n/m * ln2
已知集合大小n,并设定好误判率 p, 问:m的大小如何确定?
改进:计数 BF (Counting Bloom Filter)
答:其基本信息单位是 1 个比特位。所以只能表达两种状态。计数BF 的 基本信息单元 由多个比特位组成,一般为3到4个。
使用过程:将集合成员加入 位数组时,根据k个哈希 函数进行计算,只需要将原先的数值 +1 即可。查询集合成员时,只要对应位置的信息单元都不为 0 ,即判定该成员属于集合。
改进的代价:位数组大小倍数增加。另外存在计数溢出的可能,因为比特位表达能力仍然有限,计数很大的时候存在计数溢出的问题。
八、public,private,default,protected 中default(包内)和protected谁的范围更大?
1.private 访问权限 限于当前类的内部 不能被外部类访问。
2.default 针对当前包的。当前本报下的类 接口 等均可访问。
3.protected 当前类的子类中可以使用的当前类protected修饰的成员
1.父类静态变量初始化。2.父类静态代码块。3.子类静态变量初始化。4.子类静态语句块。5.父类变量初始化。6.父类代码块。7.父类构造函数。8.子类变量初始化。9.子类语句块。10.子类构造函数。
static
private static String name=null;
上面这段代码,把name打印出来是null
-------
private static String name=null;
static
上面这段代码,把name打印出来是 大数据肌肉猿
--------
static
private static String name;
上面这段代码,把name打印出来是大数据肌肉猿
由此可见,变量名首先被加载,而赋值的时候,无论是直接在变量上赋值还是在静态代码块中赋值,都是按照代码的顺序赋值的。
4.生成索引,建立Hash,基于InnoDB和MyISAM的Mysql不显示支持哈希
5. 位图数据结构,BitMap,少量主流数据库使用,如Oracle,mysql不支持,
十一、Synchronized 与volatile 关键字的区别?
Synchronized 解决执行控制问题,它会其它线程获取当前对象的监控锁,使得当前对象中被Synchronized关键字保护的代码块无法被并发执行,并且Synchronized 还会创建一个 内存屏障,保证了所有CPU操作结果都会直接刷到主存中去,从而保证了可见性。
内存可见:控制的是线程执行结果在内存中对其它线程的可见性,根据Java内存模型的实现,Java线程在具体执行时,会先拷贝主存中的数据 到线程本地(CPU缓存),操作完成后再把结果从线程刷到主存中;
volatile 解决了内存可见,所有对volatile关键字的读写都会直接刷到主存中去,保证了变量的可见性,适用于对变量可见性有要求而对读取顺序没有要求的场景。
1. volatile 不会造成线程的阻塞,Synchronized 会造成线程的阻塞。
2. volatile仅能使用在变量级别,Synchronized 可以使用在变量,方法,类级别上。
3. volatile 标记的变量不会被编译器优化,Synchronized标记的变量会被编译器优化。
4. Volatile 仅能保证变量的修改可见性,不能保证原子性,而Synchronized 可以保证变量修改的可见性和原子性。
5. Volatile本质告诉JVM 当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中去读取 ,Synchronized则是锁定当前变量,只有当前线程可以访问该变量,其它线程不可以。
十二、ArrayBlockingQueue和LinkedBlockingQueue?
BlockingQueue接口定义了一种阻塞的FIFO queue,每一个BlockingQueue都有一个容量,让容量满时往BlockingQueue中添加数据时会造成阻塞,当容量为空时取元素操作会阻塞。
ArrayBlockingQueue是一个由数组支持的有界阻塞队列。在读写操作上都需要锁住整个容器,因此吞吐量与一般的实现是相似的,适合于实现“生产者消费者”模式。
LinkedBlockingQueue是基于链表的阻塞队列,同ArrayListBlockingQueue类似,其内部也维持着一个数据缓冲队列(该队列由一个链表构成),当生产者往队列中放入一个数据时,队列会
从生产者手中获取数据,并缓存在队列内部,而生产者立即返回;只有当队列缓冲区达到最大值缓存容量时(LinkedBlockingQueue可以通过构造函数指定该值),才会
阻塞生产者队列,直到消费者从队列中消费掉一份数据,生产者线程会被唤醒,反之对于消费者这端的处理也基于同样的原理。而LinkedBlockingQueue之所以能够高效
的处理并发数据,还因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,
ArrayBlockingQueue实现的队列中的锁是没有分离的,即生产和消费用的是同一个锁;
LinkedBlockingQueue实现的队列中的锁是分离的,即生产用的是putLock,消费是takeLock
ArrayBlockingQueue实现的队列中在生产和消费的时候,是直接将枚举对象插入或移除的;
LinkedBlockingQueue实现的队列中在生产和消费的时候,需要把枚举对象转换为Node<E>进行插入或移除,会影响性能
ArrayBlockingQueue实现的队列中必须指定队列的大小;
LinkedBlockingQueue实现的队列中可以不指定队列的大小,但是默认是Integer.MAX_VALUE
十三、最后还问了一个IPV4相关的场景,设计算法和数据结构,晚上面的,脑子有点闷,没想明白?
●编号891,输入编号直达本文
●输入m获取到文章目录
![]()
程序员求职面试