第四范式与新加坡国立大学及英特尔的最新联合研究成果——基于持久内存优化的 AI 实时决策系统数据库 OpenMLDB(Open Source Machine Learning Database)被国际数据库顶级会议 VLDB 2021 录用。
![]()
VLDB (Very Large Data Base) 是数据库研究人员、厂商、应用开发者,以及用户广泛参与的年度国际会议,它与 SIGMOD、ICDE 被公认为数据管理与数据库领域的三大国际顶尖学术会议。
OpenMLDB(Open Source Machine Learning Database)是第四范式自研的开源机器学习数据库。此次被录用的论文由第四范式 AI 基础技术研发团队和新加坡国立大学及 Intel 合作发表,题为《Optimizing In-memory Database Engine For AI-powered On-line Decision Augmentation Using Persistent Memory》。
论文相关的开源项目:
机器学习数据库 OpenMLDB:https://github.com/4paradigm/openmldb
持久化跳表数据结构 pskiplist:https://github.com/4paradigm/pskiplist
整合了 pskiplist 的持久内存存储引擎:https://github.com/4paradigm/pmemstore
注:论文中的特征工程数据库 FEDB,目前已更名为机器学习数据库 OpenMLDB,并对外开源(https://github.com/4paradigm/OpenMLDB),下文将使用 OpenMLDB 作为描述名称。
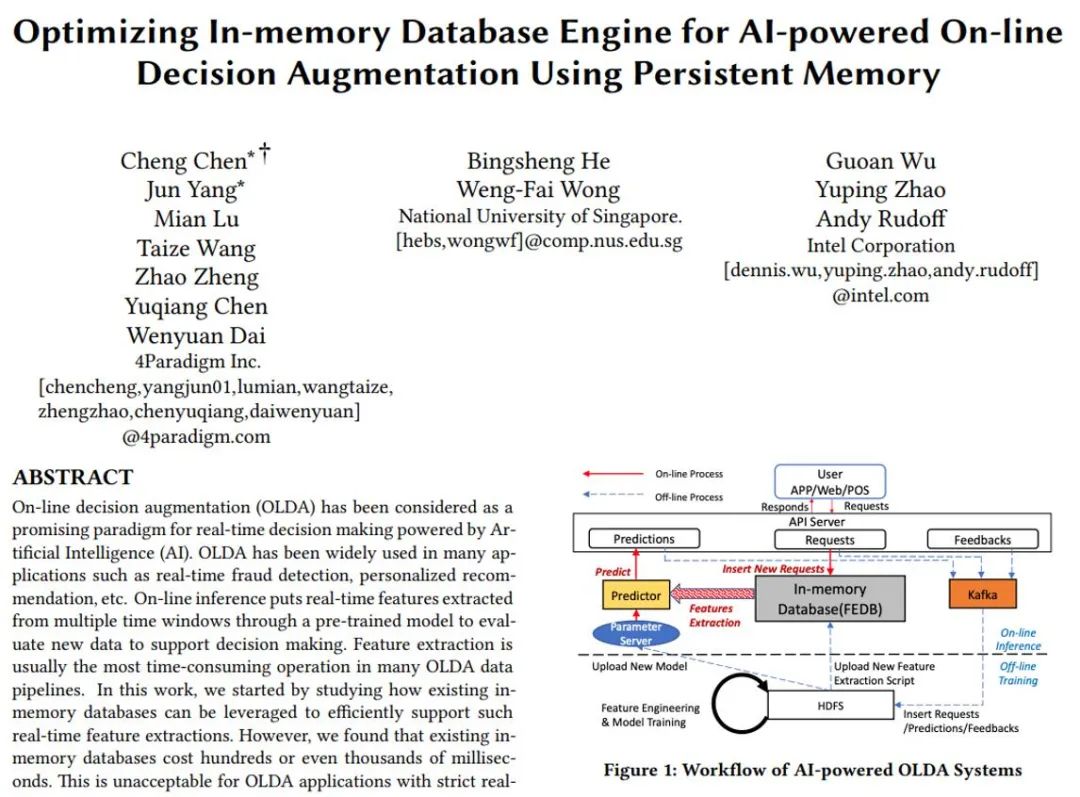
随着人工智能的蓬勃发展,越来越多的在线实时决策系统采用 AI 技术帮助决策。典型的应用包括实时信用卡反欺诈、个性化推荐等。一个典型的由 AI 驱动的实时决策系统包含两个子系统:线下训练和在线预估。如图 1 所示,我们把海量的历史数据放入左侧的线下训练系统中,这套系统会帮我们从历史数据中提取特征,并训练出超高维的 AI 模型。然后我们把训练好的模型部署到在线预估系统中。在线预估系统需要根据用户的实时行为(比如刷卡交易)提取出用户历史行为信息,并导入 AI 模型进行实时打分,从而进行预测。整个在线预估系统对实时性有很高的要求,一般延迟要求为毫秒级。本文主要关注在线预估系统的数据库存储引擎部分(图 1 中的 OpenMLDB)的性能优化,也是整个在线预估链路中的性能瓶颈。
![]()
图 1. 典型的由 AI 驱动的在线实时决策系统架构
![]()
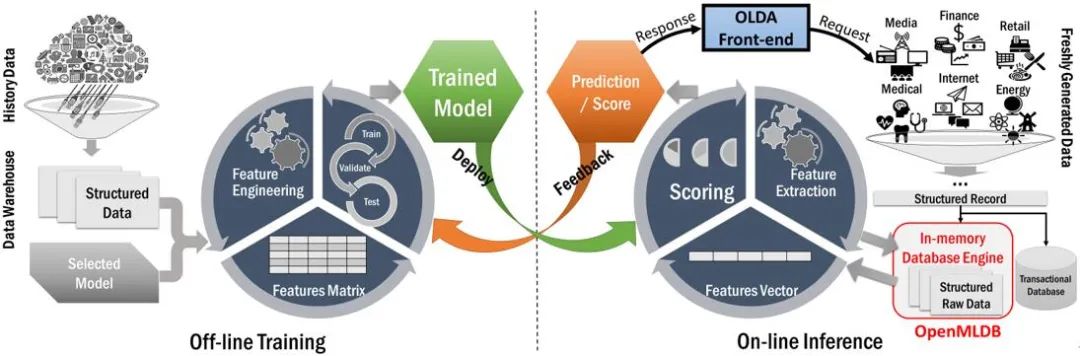
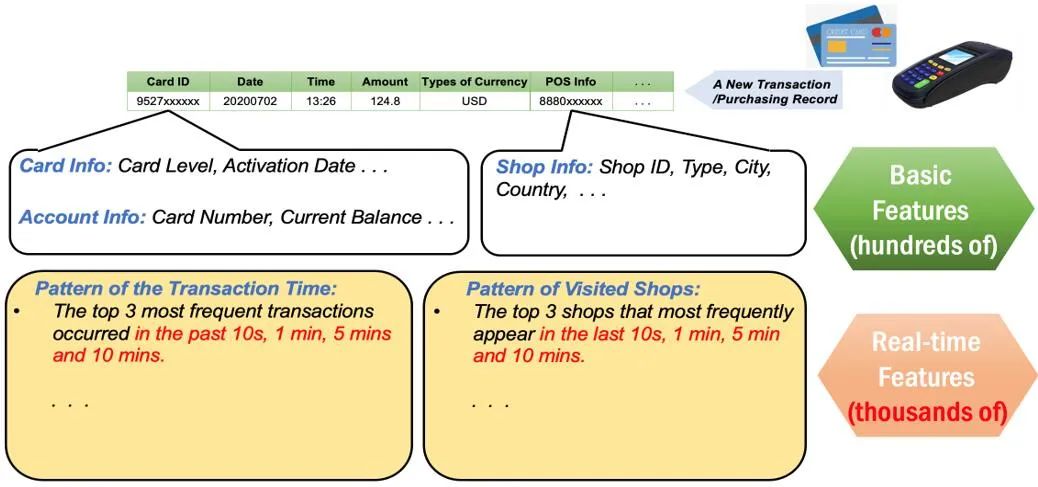
如图 2 所示,我们以信用卡反欺诈应用为例。当刷卡行为产生时,POS 机会产生一条记录。单从这条记录是无法准确判断本次刷卡是一次正常的刷卡还是一次盗刷。在人工智能系统中,除了利用这条新的刷卡记录外,我们还需要根据新记录提取背后隐藏的信息用来做模型训练。所有这些信息一起就是我们的特征,而这个特征抽取的过程就是特征工程。
如图 2 所示,通过 Card ID, 我们可以通过查询特征数据库了解这张卡的信息和与之关联的账户信息。还可以通过基于时间窗口的计算,进一步了解这张卡的最近 10 秒、1 分钟、5 分钟、10 分钟的信用卡消费总额最多的三个店铺等信息。这些特征需要从用户近期的历史数据中实时抽取。一般来说,特征抽取数量越多,模型预测约准确。
特征抽取是一个昂贵的操作。首先特征抽取涉及多个数据库查询操作。以反欺诈为例,一个用户的一次刷卡行为,会触发上千次的数据库查询请求。与此同时,这些特征中很多的实时特征,比如计算最近一条刷卡记录和最新刷卡记录的金额差,必须等新的用户刷卡数据产生并传输到后端系统后才能开始抽取,无法进行数据预计算。与此同时,大部分的实时特征都会涉及在不同维度进行大量的时间窗口查询。这些特征抽取的工作负载特点和传统的 OLTP、OLAP 或 HTAP 负载有很多不同。
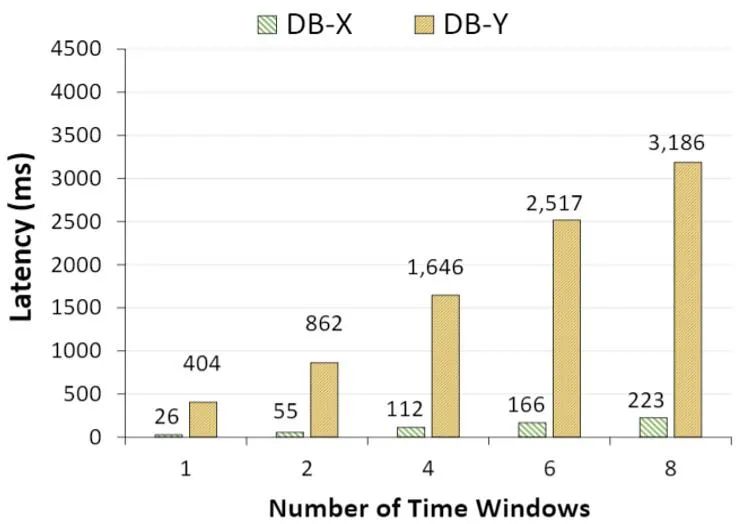
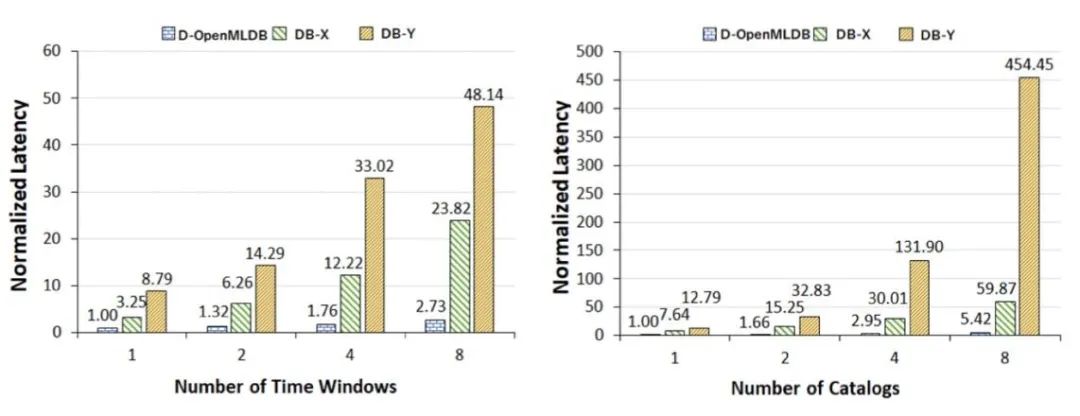
我们选取了两种目前最先进的主流商用内存数据库(DB-X 和 DB-Y),使用典型的实时特征抽取负载进行性能测试。如图 3 所示,随着时间窗口数的增加,DB-X 和 DB-Y 的查询延迟显著上升,且当窗口数大于 4 之后,两种数据库的查询性能均已经超过 100 毫秒,完全无法满足我们的性能需求。而且在真实业务场景下,时间窗口数远远大于 4。基于以上结果,需要我们设计一个新的专门针对人工智能特征抽取的数据库引擎。
![]()
图 3. 主流商用数据库在实时特征提取负载上的性能表现
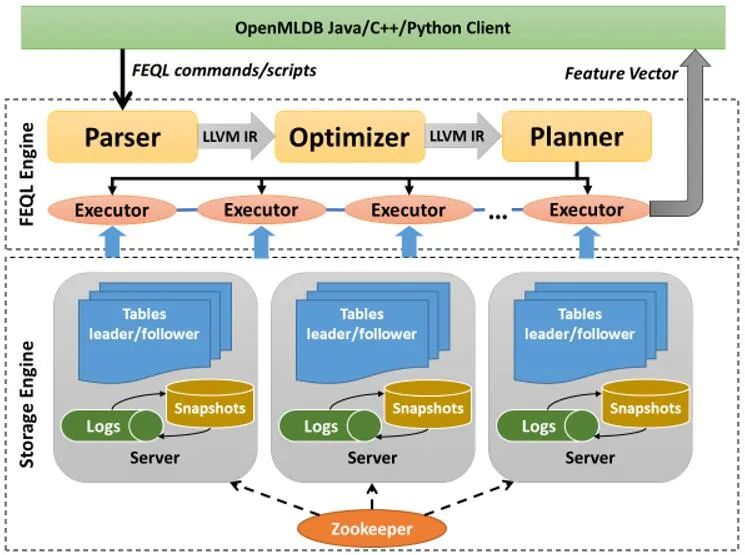
为了能高效的抽取实时特征,我们设计了机器学习数据库。如图 4 所示, OpenMLDB 包括
![]()
图 4. 机器学习数据库 OpenMLDB 架构图
特征抽取执行引擎(FEQL)和存储引擎两部分。FEQL 使用 llvm 对查询语句进行编译优化,并对多窗口类型的查询进行了优化处理,从而使特征抽取的语句解析执行效率大大增加。FEQL 除了支持类似 SQL 的语法,还针对特征抽取操作定义了特别的语法。
如图 5 所示,FEQL 允许在同条 SQL 语句中定义多个时间窗口,在语法解析和优化的过程中,FEQL 可以最大程度的复用不同窗口内提取的结果。比如当我们需要提取 10 秒、1 分钟、5 分钟、30 分钟、1 小时、5 小时内用户在各个时间段消费的总额度,我们可以在一个 FEQL 中定义 6 个时间窗口,执行器在运行 FEQL 的时候,可以只取最大窗口(5 小时)的全部数据再分别处理,而不是重复的提取 5 个窗口的数据,从而大大提升特征提取操作中多窗口 TopN 操作的效率。
![]()
图 5. OpenMLDB 进行多窗口特征抽取的例子
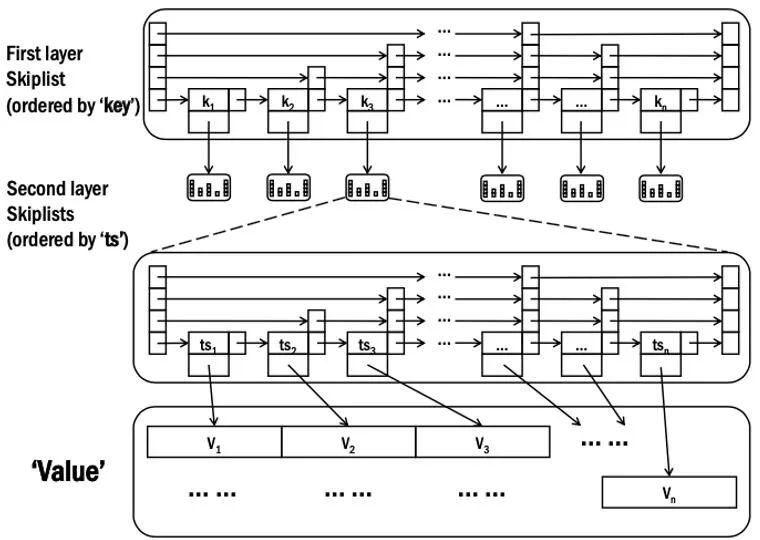
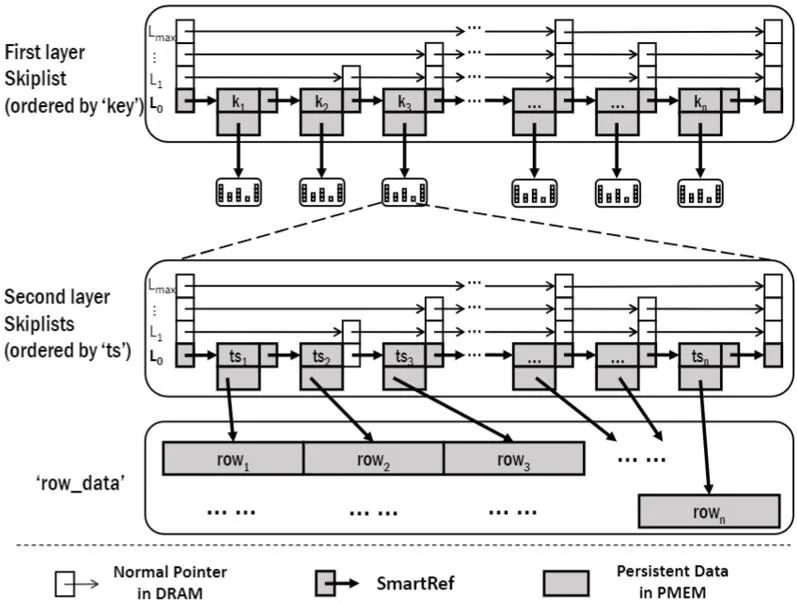
在存储引擎部分,如图 6 所示,OpenMLDB 采用了两层的内存跳表数据结构。在第一层跳表中存储了特征的主键,而在第二层中存储了主键对应的各个时间窗口。当我们在查询某个主键下多个时间窗口范围内的数据,只需要先在第一层跳表中定位到对应的主键,再继续在第二层中查询时间窗口即可。
![]()
图 6. OpenMLDB 存储引擎的两层跳表结构
![]()
图 7. DRAM 版本 OpenMLDB 和主流数据库的性能对比
如图 7 所示,图中 D-FEDB(即 D-OpenMLDB)表示 DRAM 版本的 OpenMLDB。我们在 DRAM 版本 OpenMLDB、商用内存数据库 DB-X 和 DB-Y 上变换时间窗口个数和特征主键数目,并运行典型的特征抽取查询对比性能。如图所示,DRAM 版本的 OpenMLDB 的性能远远高于传统商业数据库,最高可达 84x 的性能提升。
DRAM 内存版本 OpenMLDB 可以很好的满足特征抽取实时性的要求,但在实际的部署过程中,我们仍然发现以下痛点。
为了保证线上服务性能,OpenMLDB 的索引和数据均存放在内存中。以信用卡反欺诈场景为例,我们的测试数据存储了最近 3 个月的 10 亿条刷卡记录信息用来做特征抽取。这部分数据已经占用了超过 3 TB 的内存空间。当我们考虑多副本的情况,数据规模超过 10 TB 。而当我们需要更多的历史数据做特征抽取(比如一年甚至三年),其需要的硬件成本是十分高昂的。
OpenMLDB 作为实时在线决策系统数据库,当节点离线时(比如系统故障或者例行维护),OpenMLDB 需要把海量数据从磁盘读入内存,再重构内存数据结构。整个过程需要耗费若干个小时,会严重影响线上服务质量。
传统的内存数据库为了保证数据的一致性,都会周期性的通过日志或者快照把数据从易失性的 DRAM 内存写到低速的磁盘或闪存中。当系统负载高时,这种同步操作很容易造成一部分上层查询产生超长的延时,我们称之为长尾延时。
我们引入持久内存为解决以上痛点提供新思路。持久内存具有低成本、大容量、数据持久化的特性。低成本大容量的内存特性有助于解决 OpenMLDB 高硬件成本的问题。数据持久化则带来了两个好处:1) 大幅缩短节点离线以后的恢复时间,保障线上服务质量;2) 由于内存数据持久化特性,因此数据库不再需要通过低速磁盘设备做日志和快照的持久化工作,因此可以有效解决长尾延迟的问题。
持久内存有两种工作模式:Memory Mode 和 App Direct Mode。在 Memory Mode 下,持久内存会被当做内存的一部分对用户透明。该模式的好处是用户程序无需修改即可使用大内存容量,但是无法使用持久化特性以及做精细化的优化。在 App Direct Mode 下,持久内存会以独立块设备的形式被系统感知。程序员通过英特尔提供的 PMDK 库来编程使用。此种模式下,应用可以享受大容量特性的同时,还可以利用内存数据持久化的特性。
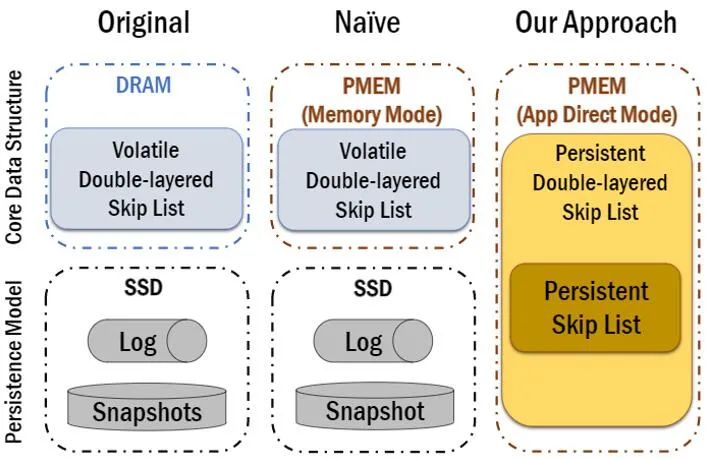
![]()
如图 8 所示,最左边的版本是原始的基于 DRAM 内存的 OpenMLDB,其查询数据的过程都在 DRAM 内存中完成,但是会通过写入外存(SSD/HDD)上的日志和快照进行持久化。如果使用 Memory Mode(图 8 中间图),则使用大容量的持久内存直接替换 DRAM 内存,但是无法受益于数据持久化特性。因此,如图 8 右图,我们用 App Direct Mode 重构了 OpenMLDB 下层的存储引擎,用 PMDK 实现了基于持久内存的双层链表结构,移除了传统的日志和快照机制。
开发基于持久内存的存储引擎的主要挑战是保证数据持久化的正确性和高效性。OpenMLDB 的底层数据结构双层链表运行在多线程环境中,存在大量的多线程并发读写操作,为了更高效率的并发读写,在 DRAM 环境下通常会使用 Compare-and-swap(CAS)技术。CAS 是一种通过硬件实现并发安全的常用技术,底层通过利用 CPU 的 CAS 指令对缓存或总线加锁来实现多处理器之间的原子操作。但是当我们应用 CAS 到持久内存上时,会带来数据一致性的问题。
![]()
图 9. Compare-and-swap (CAS) 操作在持久内存上的一致性问题
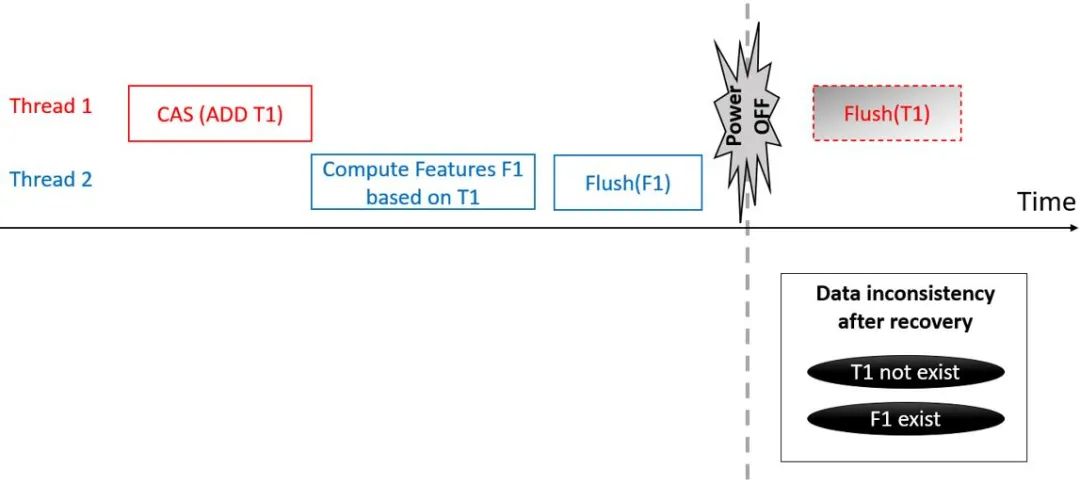
如图 9 所示,一个典型的场景是当一条新的信用卡刷卡记录 T1 在 Thread 1 上通过 CAS 插入 OpenMLDB,紧接着另外一个线程 Thread 2 基于新的记录 T1 抽取特征 F1。由于 CAS 和 CPU 的 flush 指令相互独立,传统的基于 DRAM 的 CAS 并没有持久化语义,如果系统按照图 9 的顺序持久化 F1 和 T1(即图 9 中的 flush 指令),而在两个 flush 命令中间掉电,重启之后在系统上新的信用卡记录 T1 会丢失,但基于 T1 计算出的特征 F1 却存在,这在一致性上显然是不正确的。
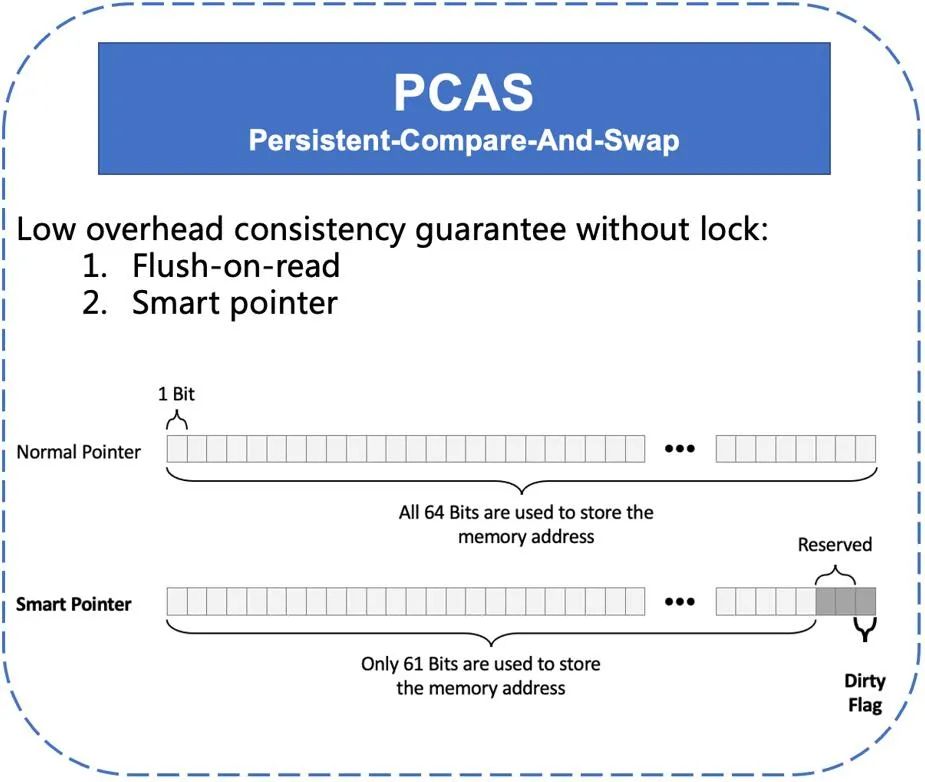
为了解决持久内存上数据一致性的问题,我们提出了 Persistent-Compare-And-Swap(PCAS)技术。首先我们使用 flush-on-read 的规则解决正确性问题。当每次读取一个内存数据时,我们先进行 flush 以保证读取的数据是持久化过的。但是过多的持久化 flush 操作会带来额外的性能损耗,特别是无必要的持续的 flush 那些本来没有修改过的 「干净」数据。为了高效的判断数据是否「干净」,我们使用了一种特殊的指针,称为智能指针。在 x86 下 64 位 CPU 中支持 8 字节 CAS 原子操作的内存地址是必须保证 8 字节对齐的,由于内存访问的基本单元是一个字节,8 字节对齐意味着 CAS 地址的低 3 位始终为 0。如图 10 所示,智能指针巧妙的利用了使用 CAS 时内存地址始终为 0 的低 3 位来标记数据是否为 dirty。有了智能指针,我们只需要在每次修改数据后,对未 flush 的数据的指针标记 dirty 位。然后在后续的读取时,只有当 dirty 位被标记,则执行 flush 指令进行持久化,从而避免了不必要的持久化开销。
![]()
如图 11 所示,我们利用 PCAS 技术对持久内存跳表的指针做了优化。为了进一步减少在持久内存上写的量,我们只把跳表最后一层和数据放在持久内存上。为此,我们也设计了一套新的重构流程,以保证在掉电后系统可以根据最后一层跳表信息重构出整个跳表。我们也在实验中会考察不同层级的持久化策略带来的性能影响。
![]()
![]()
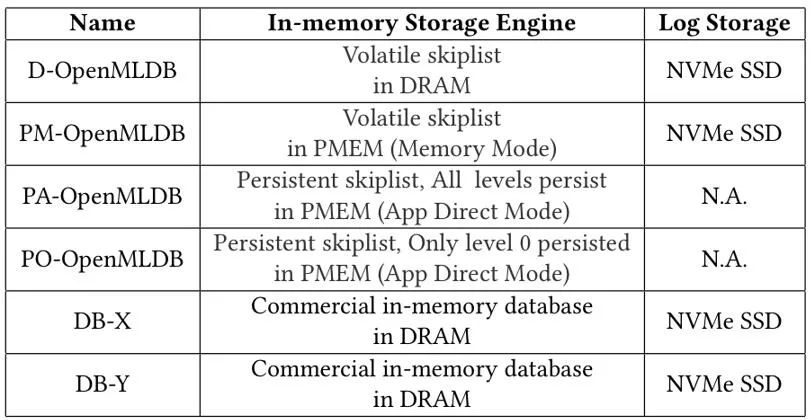
我们使用一个真实的反欺诈应用数据进行测试,该数据包含了 3 个月的 10 亿条刷卡记录信息,实际部署中大概需要 10 TB 的内存空间。我们对比了 DRAM 版本的 OpenMLDB 以及各种持久内存版本的 OpenMLDB 变种,图 12 给出了测试中各种数据库系统的配置。该实验得出以下结论。
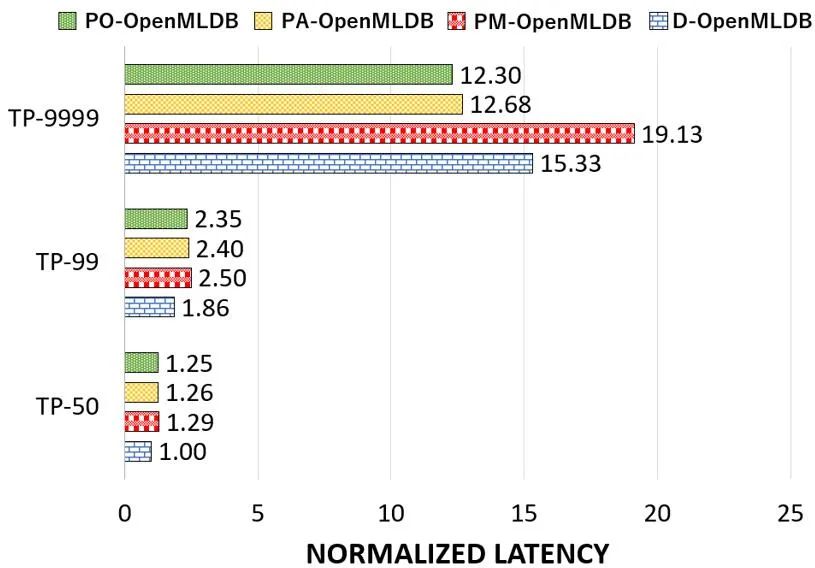
1.长尾延迟 TP-9999 比较(图 13):基于持久内存进行持久化数据结构设计的 OpenMLDB 舍弃了原有纯内存方案的基于外存储设备的持久化机制,实现了长尾延迟(TP-9999)接近 20% 的改善。
![]()
图 13. OpenMLDB 基于 DRAM 和持久内存的性能比较
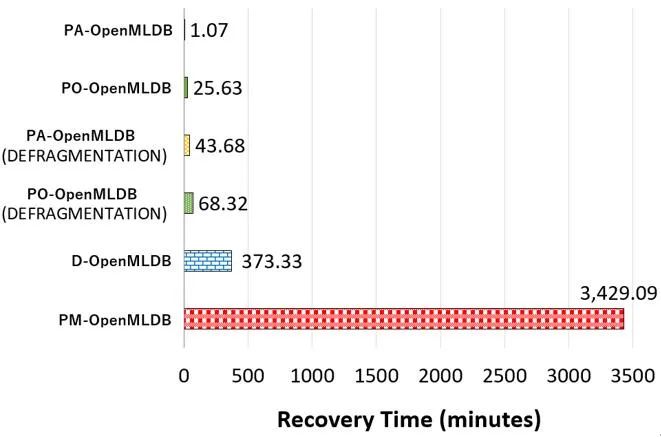
2.数据恢复时间比较(图 14):在服务中断情况下实现数据快速恢复,服务恢复时间减少 99.7%,全面降低对线上服务质量的影响,在测试场景中,其数据恢复时间从原来的六个小时缩短至一分钟左右。
![]()
图 14. OpenMLDB 基于 DRAM 和持久内存的恢复时间比较
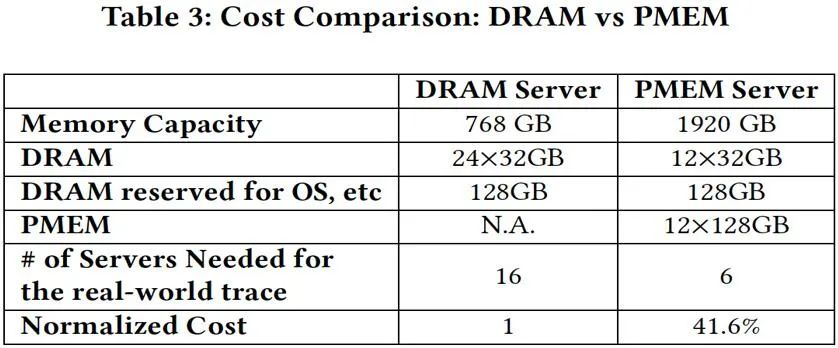
3.硬件成本比较(图 15):我们对比了 10 TB 信用卡反欺诈业务部署在不同集群上的对比,显示了在论文实验中使用的机器配置,在 10 TB 数据的业务场景中,基于持久内存的 OpenMLDB 的硬件成本仅为基于纯内存版本的 41.6%。
![]()
图 15. OpenMLDB 基于 DRAM 和持久内存的硬件成本比较
本文分析了目前人工智能驱动的实时决策系统面临的挑战以及解决方案,着重描述了:
总结了 AI 驱动的实时决策系统的架构和负载,我们发现现有的商用内存数据库并不能满足这类应用高实时性的要求。
设计了针对人工智能在线实时决策系统的机器学习数据库 OpenMLDB,在执行引擎和存储引擎上进行了针对性的优化以满足实时决策的性能需求。
为了解决在线预估系统内存消耗大、离线后恢复慢、长尾延迟的痛点,我们基于持久内存重新设计了 OpenMLDB 的存储引擎,并且提出了持久化 CAS (PCAS) 和智能指针的技术。
实验显示,相比较于基于 DRAM 的 OpenMLDB,基于持久内存的 OpenMLDB 可以减少 19.7% 的长尾时延,缩短 99.7% 的恢复时间,与此同时,降低 58.4% 的成本。
数据智能技术实践论坛——从数据到知识的「智变」
8月27日15:00-17:00,百分点科技与机器之心联合举办
「数据智能技术实践论坛」全程线上直播,四位业界专家与学者详细解读多模态数据融合治理、计算机视觉、基于知识图谱的认知智能、知识图谱构建等领域的技术进展和实践心得。
直播设有QA环节,欢迎加群交流答疑。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com