又出现异常数据?架构师深度剖析分布式系统「事务」
关于作者:张帆(Zachary)。坚持用心打磨每一篇高质量原创。
本文首发于公众号:「跨界架构师」(ID:Zachary_ZF)。
一、为什么需要事务
如果说「共识」解决的是「水平」问题,那么「事务」解决的是「垂直」问题。是如何让一条绳上的蚂蚱共同起舞?
事务只是一个计算机术语,而事务的体现形式其实在我们生活中也无处不在。任何我们认为应该是这样的事情,去确保它达到预期的过程就是「事务」。 往小了说,我们平时在走路的时候,向前摆动左手的同时抬右腿,如果不是这样的话就是不一致,别人会说你走路不协调。所以我们小时候父母会通过各种方式教会我们这个,这些各式各样的方式就好比我们在软件开发中去实施「事务」一样,一题是多解的。
二、事务的来源
提到事务不得不提到「XA规范」[1],这是分布式还没大行其道的时期,被大多数的数据库作为其内部分布式事务实现的接口标准。
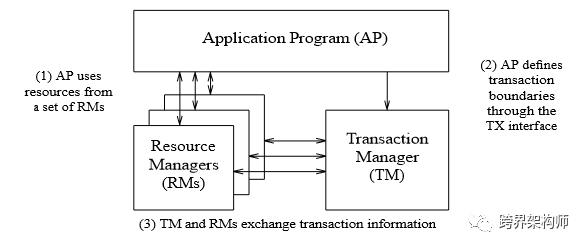
▲图片来源于论文中,版权归原作者所有
「XA规范」就是上图中「RM」和「TM」的交互规范和接口定义。仅仅是定义了xa_和ax_系列的函数原型以及功能描述、约束和实施规范等,并不包括建议的实现方式。后面会提到的两阶段提交(2PC)是「TM」协调「RM」们完成事务的方法。
所以其实可以说,事务起源于数据库,辉煌于分布式系统。在摩尔定律还适用的时候,软件系统为了承载更大的流量或者说用户数,开始运用「分治」的思想来设计。然后随着互联网的蓬勃发展,B/S应用大行其道的背景下,分布式系统越来越常见。并且随着一个个巨无霸互联网公司的出现,越来越被鼓吹和传颂。
一轮明月的背后是一个阴暗面,从来不让人看见。
能被吹捧的永远是有益的一面,再加上耀眼的数据:多少TPS、多少QPS,更抓人眼球。但是这背后为了让「分治」后的系统能够尽可能的像单个个体一样运作,各类专家学者们通过多年研究,才有了如今的各种著名理论和解决方案。
三、分布式系统中的事务问题
正如前面所说,事务问题其实一直存在,只是在分布式系统中被放大了。并且随着系统拆分的粒度越细,问题的复杂度成指数上升。
分布式系统的事务,不得不提到被广为流传的两个理论:「CAP」、「BASE」。
「CAP」理论由Eric Brewer在2000年PODC会议上提出[2],所以还被称为Brewer定理。是Eric Brewer在Inktomi期间研发搜索引擎、分布式web缓存时得出的一个猜想:
It is impossible for a web service to provide the three following guarantees : Consistency, Availability and Partition-tolerance.
后来Seth Gilbert和Nancy Lynch对其进行了证明[3],成为我们熟知的「CAP」定理(感谢园友@bangerlee的信息收集)。
对,就是下面这张经典的图。

▲图片来源于网络,版权归原作者所有
一致性(consistency):这里的一致性指是「线性一致性」。(关于线性一致性的解释,点我可阅读)
可用性(availability):每个请求都在一定时限内得到响应。
分区容忍性(partition-tolerance):这应该是这三点中最晦涩的。允许丢失以一个节点发给另一个节点的任意多的消息。只要是分布式系统,这项是无法逃避的,因为网络、硬件说不准啥时候就出问题了。
举个不是特别严谨的例子,这就好比要实现一个系统不能产生BUG(C),并且10天内完成上线(A),以及需要多人团队一起协作进行(P)。我们做开发的也很清楚这三者是无法兼得的。况且只要是一个组织,团队协作是无法避免的,正如这里的分区容忍性一样,比如得考虑人员请假的问题。剩下的2项,如果说可以达到没有BUG的话,那就是时间无限延长,但也只是无限趋近于0,并不能达到真正的0,因为没有人可以保证发现了所有的BUG。
「BASE」理论是由时任ebay架构师的Dan Pritchett提出的[4],本质上就是对「线性一致性」的弱化。
「BASE」理论解释如下:
基本可用(Basically Available)。分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用。
软状态(Soft State)。状态可以有一段时间不同步,且这个状态不影响系统可用性。
最终一致(Eventually Consistent)。确保最终数据能够一致,而不是时时保持强一致。
「BASE」理论的提出并不是取代「CAP」理论,让我们在实际的工作中就可以完全的撇开「线性一致性」。并不是这样,而是引导我们可以区分核心和非核心,然后分别对待,核心部分还是需要用CAP理论来保证「线性一致性」。为什么要区别对待?根本上还是无法容忍「线性一致性」带来的巨大的性能损耗,因为它是反可伸缩性的。但是只要涉及到Money之类的高敏感数据的操作部分,还是必须保证「线性一致性」。
还是上面的例子,我们侧重于降低核心功能的BUG,不花过多精力在非核心功能上(BA)。我们允许产生不影响核心功能的BUG(S),但是必须最终要修复(E)。
四、分布式事务的解决方案
如果说「CAP」理论和「BASE」理论是「道」,那么围绕这两个理论演化的解决方案就是「术」。对我们来说,在实际的运用中根据所处的场景找到最合适的,是我们最重要的事。
以「CAP」为基础的强一致性解决方案都会引入一个类似“协调器”的东西来作为全局事务的掌控者,可以来看一下。
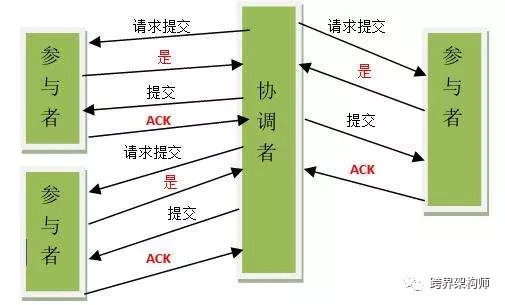
另外值得注意的是,参与者在答复「是」之前会将自己的内部资源变为阻塞状态。因此如果在产生阻塞后协调者出问题,那么这些被阻塞的资源有可能就一直不被释放了,需要额外的介入。
2PC相对来说是最简单的事务模型,但缺点也更多。其它缺点诸如:在某些场景下的数据不一致(参与者与协调者共同与「提交」环节挂了)、阻塞范围过大等问题。
02 三阶段提交(3PC)[6]
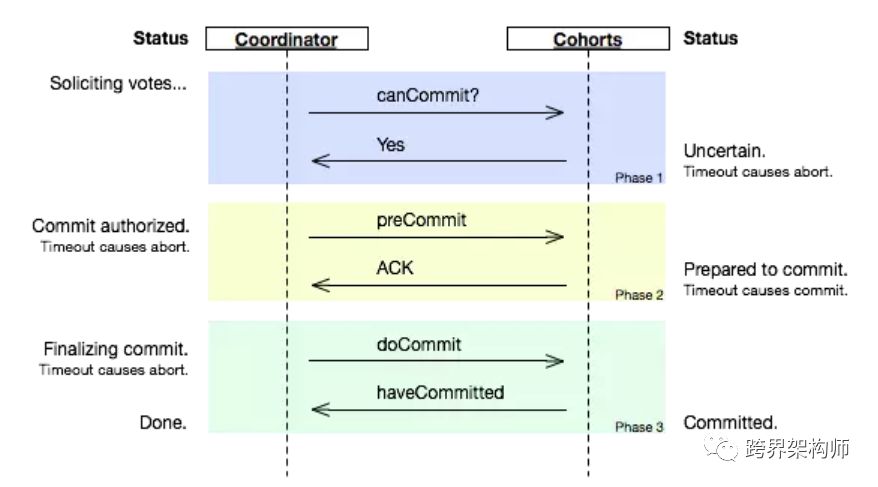
▲图片来源于网络,版权归原作者所有
3PC的出现就是通过增加复杂度(性能也因此降低)来解决或优化2PC中的一部分问题。本质的变化就是在2PC的「请求提交」之后增加了一个「准备提交」环节,以增加每个参与者需要等待其它的参与者确认后方可进行具体的操作。
「阻塞」这个动作延后到这个「准备提交」环节再做,使得阻塞范围缩小为2PC的2/3(图中背景黄色和绿色部分)。正如上面的例子,在交换戒指之前增加了把戒指交给牧师的动作。
同时还解决了协调者的单点问题。故障恢复或者新接替的协调者,可以利用「准备提交」产生的状态结果,来作为参与者和协调者在「提交」出现故障恢复后的界定依据。还是前面的例子,夸张点,交换戒指的时候我失忆了,意识恢复后我只要看到牧师手掌上托着戒指或者我的手上已经被戴好了戒指,就知道我的妻子已经答应了,我只要继续给她做带戒指这个事就好了。
新引入了timeout机制,在发生超时执行默认约定,避免了永久阻塞,也因此对多个参与者下的100%数据一致性作出了妥协。比如,协调者在向参与者A发送「doCommit」时timeout了,会引发广播「abort」,但是这个「abort」又未能投递到参与者B,导致参与者B执行了「ACK」后的timeout默认约定「commit」。
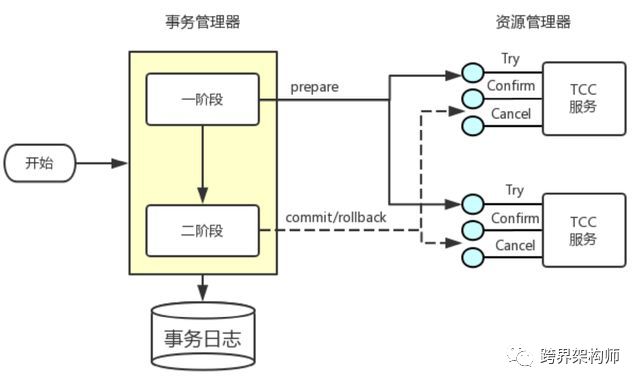
通过运用本地事务代替了全局事务,使得可以不需要协调者的存在,避免了协调者的单点问题。
3PC中协调者的另一个作用:故障恢复后的数据一致性。在TTC里通过事务日志来确保。
以上这三种就是主流的DTS(Distributed Transaction Service)框架。值得一提的是,不管是3PC还是TCC,只要涉及到故障恢复或者重试机制,那么「幂等性」问题必须要提上来了。比如3PC中「提交」阶段某个参与者和协调者同时挂了,但是这个参与者在挂之前已经做了commit操作。那么故障恢复后其实没人知道它是否执行过了commit,协调者只会为了能100%确保commit指令被送达,又会发起一次commit通知,这时候如果没有做好「幂等性」就会发生重复commit的问题。
下面聊聊以「BASE」理论为基础的解决方案。
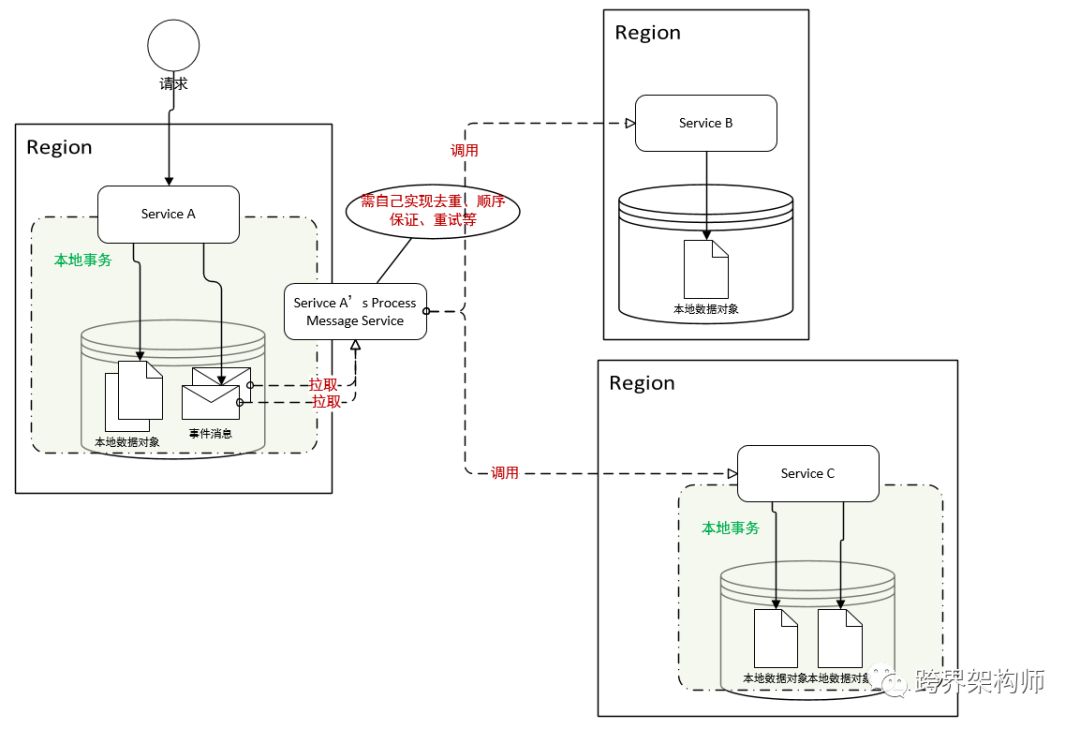
02 异步消息——不支持事务的MQ
try{ beginTrans(); modifyLocalData1();
modifyLocalData2(); deliverMessageToMQ(); commitTrans();
}catch(Exception ex){ rollbackTrans();
}
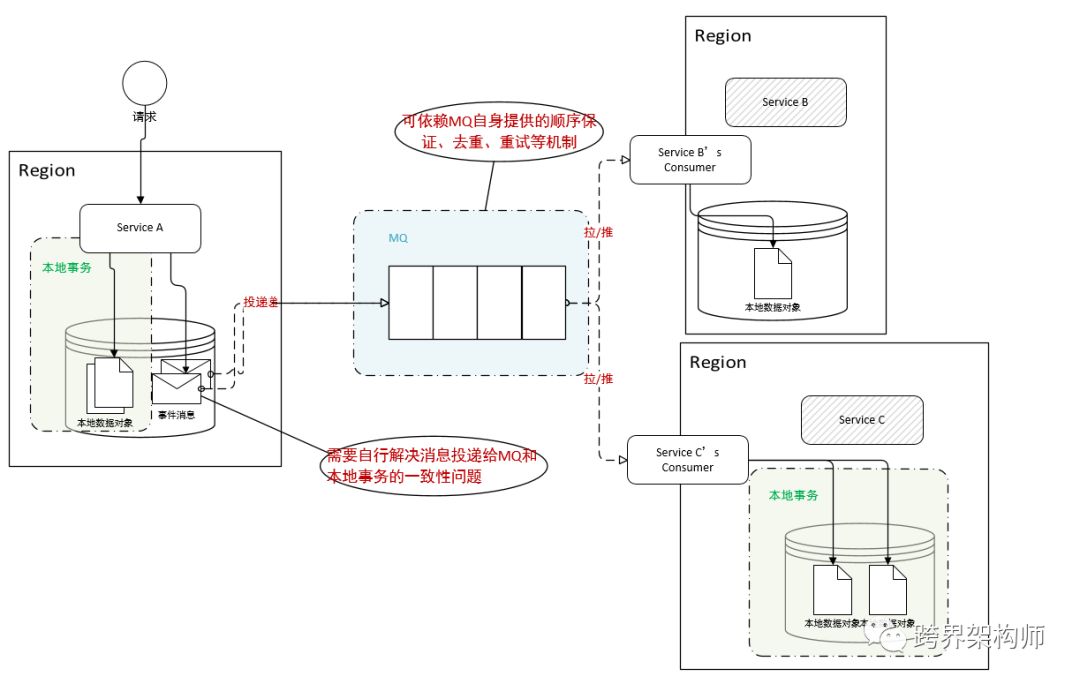
03 异步消息——支持事务的MQ

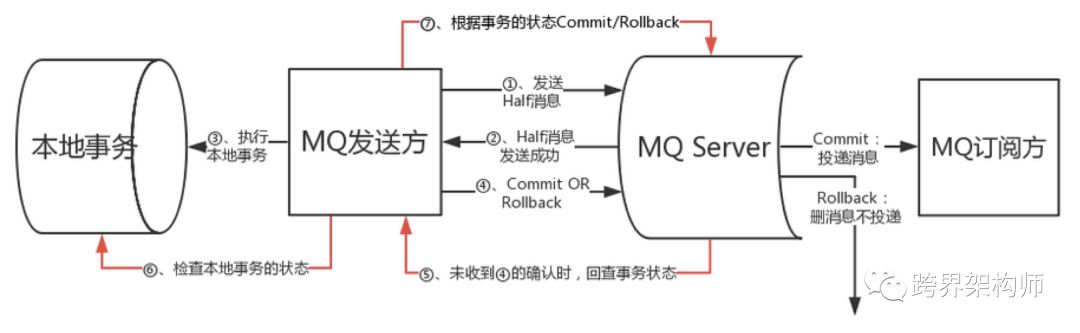
▲图片来源于网络,版权归原作者所有(点击图片可查看大图)
不过其实有一个疑点我没有去验证,有知道的小伙伴们可以留言下,就是RocketMQ是否有防止consumer(上图中的订阅方)在消费完成后发送的ACK丢失的机制。如果能达到这点,对于consumer内部的方法幂等性需求就低了很多。
04 Saga
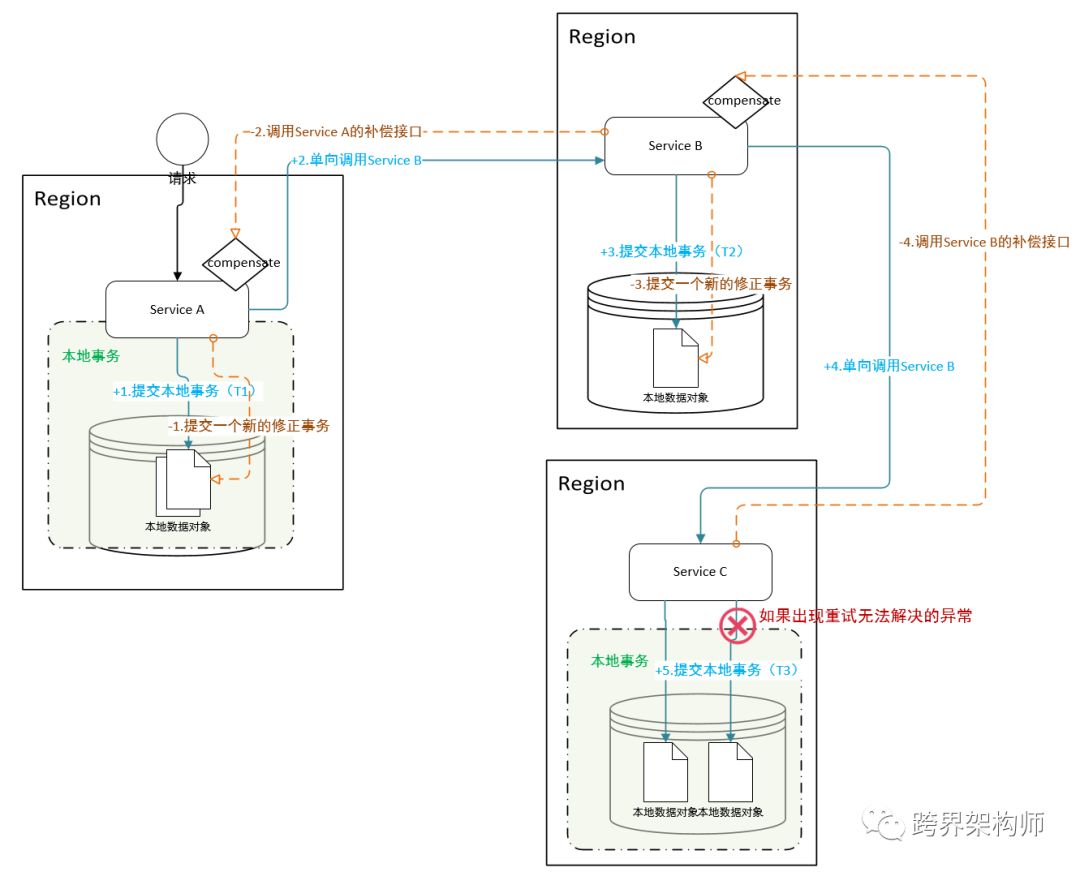
▲点击图片可查看大图
将一个分布式事务拆分为多个本地事务,并且击鼓传花给下一个,不用阻塞本地事务等待响应。且允许嵌套至多一层子事务。
除了最后一个参与者之外,都需要定义一个「回滚」接口,便于在遇到无法进行下去的情况下撤销之前上游系统的修改。当然这里的撤销除了Update还可以是冲抵类的操作。
Saga原则上是个链式的「长活事务」,整个处理耗时可能会很长。所以可以通过增加save point(保存点,类似于游戏里的存档),便于故障恢复和提速,如向前恢复(重试)和向后恢复(回滚)。不过,也可以并行多个子事务,但一般在运用中心节点的Saga模式中,如图。
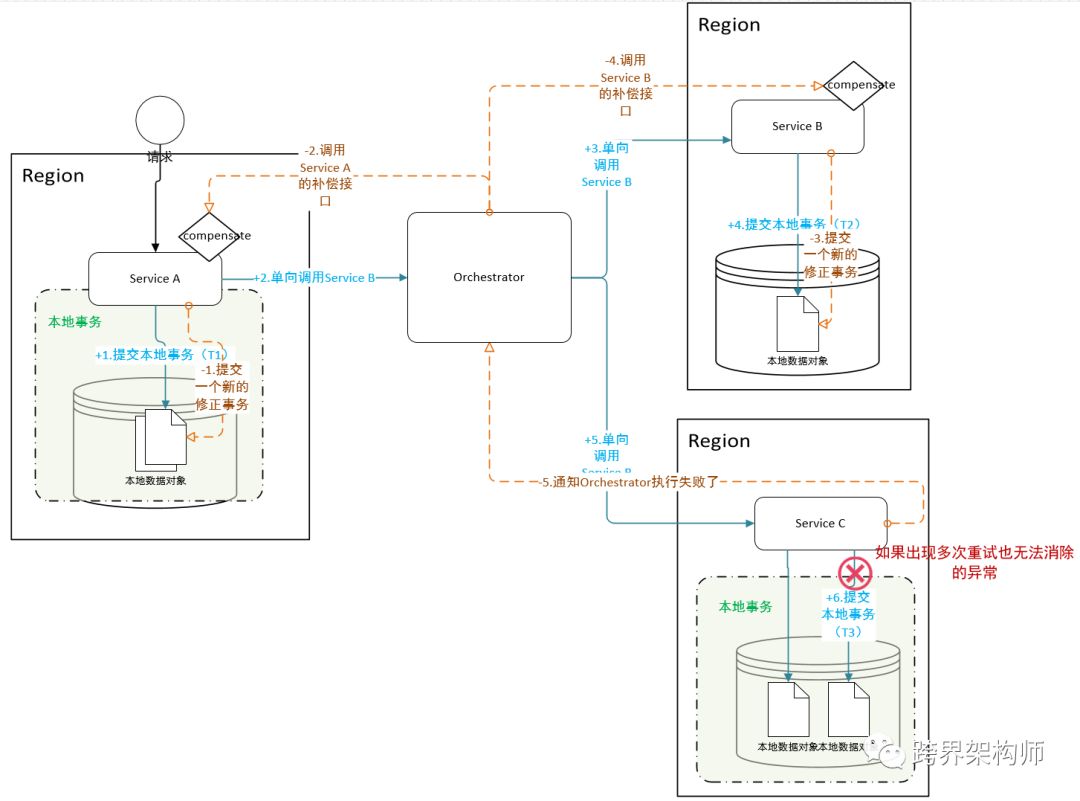
▲点击图片可查看大图
只是在我们打破了链式规则后必须要额外确保执行了「回滚」之后再接收到「正向请求」,等于“请求无效”的效果。中心节点模式还有一个比较大的好处是能够更好的避免事务之间的循环依赖关系。
05 Gossip协议
看这些案例我们可以发现,基于「CAP」的解决方案都是在线的,而「Base」是允许离线的。好比前者是,累倒了必须得马上爬起来继续干货,要不然就是失败。而后者是,慢慢来,只要最终能干完。
不管怎样,如果每个解决方案中增加「重试」和「回滚」会大大提升程序的自我修正能力,以降低需要人为介入的比例。识别是否需要人为介入的方式就是类似于「对账」的机制,这个机制就是兜底的。最后还需要做一道选择题来防止混乱:确保参与者的接口符合「幂等性」,或者在中间件里做到「正好一次(Exactly-once)」。
这些基于「BASE」的解决方案都是可以作为「CAP」解决方案出现问题时的PlanB来用的,起到补充作用。当然,如非必要,可以优先考虑基于「BASE」的方案,毕竟这才是天然易伸缩的,自然也能带来更好的性能。
五、结语
解决方案如此多,所以不管我们是架构师、还是在成为架构师的路上,甚至在日常生活中,都需要养成Balance的习惯,找到那个最适合的方案。
最后还有一招终极大法 —— 减少冗余。
是亦彼也,彼亦是也,彼亦一是非,此亦一是非。
——庄子
「事物都具有两面性」,所以,在选择走向分布式之前,慎重考虑下是否有必要,以免给自己徒增麻烦。
[1] Distributed TP: The XA Specification , X/Open Company Ltd. , 1991
链接:https://publications.opengroup.org/c193
[2] Harvest, Yield, and Scalable Tolerant Systems, Armando Fox , Eric Brewer, 1999
链接:https://cs.uwaterloo.ca/~brecht/servers/readings-new2/harvest-yield.pdf
[3] Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web, Seth Gilbert, Nancy Lynch, 2002
链接:https://pdfs.semanticscholar.org/24ce/ce61e2128780072bc58f90b8ba47f624bc27.pdf
[4] Base: An Acid Alternative, Dan Pritchett, 2008
链接:http://delivery.acm.org/10.1145/1400000/1394128/p48-pritchett.pdf
[5] Consensus Protocols: Two-Phase Commit, Henry Robinson, 2008
链接:http://the-paper-trail.org/blog/consensus-protocols-two-phase-commit/
[6] Consensus Protocols: Three-phase Commit, Henry Robinson, 2008
链接:http://the-paper-trail.org/blog/consensus-protocols-three-phase-commit/
[7] Life beyond Distributed Transactions:an Apostate’s Opinion, 2007
链接:https://cs.brown.edu/courses/cs227/archives/2012/papers/weaker/cidr07p15.pdf
[8] Sagas, Hector Garcaa-Molrna & Kenneth Salem, 1987
链接:https://www.cs.cornell.edu/andru/cs711/2002fa/reading/sagas.pdf





