矩阵相乘在GPU上的终极优化:深度解析Maxas汇编器工作原理
机器之心发布
作者:XiaoyuWang
九大章节,一万余字,这篇文章可能是目前为止Maxas汇编器工作原理最全面、最细致的解析。

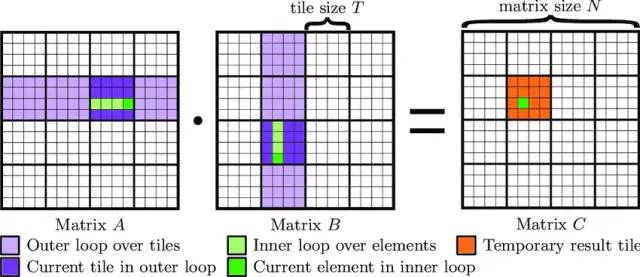
 )的每一个元素开一个线程,该线程载入 A 的一行和 B 的一列,然后对其做一次向量的内积。但问题是在 GPU 上访问显存的延时相当的大(~100 时钟周期),如果 A 的一行因为在内存中是连续的还能够利用 GPU 的超大显存带宽一次载入多个元素平摊其载入时间以及缓存来降低延时,对于 N 上千的大矩阵来说 B 的一个列中的元素的内存地址也要相隔上千,意味着载入一次中除了需要的那个列元素外大部分数据都是无用的,同时这种访问模式几乎不可能有缓存线命中,总而言之这个并行方法的内存访问效率低到令人发指。
)的每一个元素开一个线程,该线程载入 A 的一行和 B 的一列,然后对其做一次向量的内积。但问题是在 GPU 上访问显存的延时相当的大(~100 时钟周期),如果 A 的一行因为在内存中是连续的还能够利用 GPU 的超大显存带宽一次载入多个元素平摊其载入时间以及缓存来降低延时,对于 N 上千的大矩阵来说 B 的一个列中的元素的内存地址也要相隔上千,意味着载入一次中除了需要的那个列元素外大部分数据都是无用的,同时这种访问模式几乎不可能有缓存线命中,总而言之这个并行方法的内存访问效率低到令人发指。
 个小片,输出矩阵 C 可以写为:
个小片,输出矩阵 C 可以写为:

 不是元素而是小片矩阵,当然小片大小为 1 时小片矩阵就退化为单个元素。显然矩阵乘法的定义依然在此适用:
不是元素而是小片矩阵,当然小片大小为 1 时小片矩阵就退化为单个元素。显然矩阵乘法的定义依然在此适用: 。
。
 倍。对于每个小片的结果可以由一组线程负责,其中每个线程对应小片中的一个元素。这个线程组将 A 的行小片和 B 的列小片一一载入共享内存,在共享内存上对其做矩阵相乘,然后叠加在原有结果上。这样对小片中的元素每载入一次可以被在高速的共享内存中被访问 K 次,由此得到远高于原始方法的内存存取效率。
倍。对于每个小片的结果可以由一组线程负责,其中每个线程对应小片中的一个元素。这个线程组将 A 的行小片和 B 的列小片一一载入共享内存,在共享内存上对其做矩阵相乘,然后叠加在原有结果上。这样对小片中的元素每载入一次可以被在高速的共享内存中被访问 K 次,由此得到远高于原始方法的内存存取效率。
 矩阵相乘,在之前的直观算法中,计算一个 C 矩阵的元素是按照矩阵乘法的定义,取 A 中的一行和 B 中的一列做内积。A 中的一行和 B 中的一列都要被用到 64 次。如果要充分利用寄存器的优势三个的矩阵(每个矩阵占 16KB)都要放在寄存器中对寄存器文件(每个 SM 64K)是巨大的压力,更严重的问题是和共享内存不同,寄存器在线程间是不能共享的,如果每个线程要在自己的寄存器中保存所负责的 C 矩阵的那部分,它也必须在寄存器中保存所用到的 A 的行和 B 的列。结果是大量寄存器用于保存重复的数据,而且对共享内存的访问很可能造成 bank 冲突,进一步恶化延时。
矩阵相乘,在之前的直观算法中,计算一个 C 矩阵的元素是按照矩阵乘法的定义,取 A 中的一行和 B 中的一列做内积。A 中的一行和 B 中的一列都要被用到 64 次。如果要充分利用寄存器的优势三个的矩阵(每个矩阵占 16KB)都要放在寄存器中对寄存器文件(每个 SM 64K)是巨大的压力,更严重的问题是和共享内存不同,寄存器在线程间是不能共享的,如果每个线程要在自己的寄存器中保存所负责的 C 矩阵的那部分,它也必须在寄存器中保存所用到的 A 的行和 B 的列。结果是大量寄存器用于保存重复的数据,而且对共享内存的访问很可能造成 bank 冲突,进一步恶化延时。

 个数据就可以进
个数据就可以进 次加乘运算,完全符合利用寄存器进一步缓存共享内存数据的要求。不难看出该方法在 A 的列和 B 的行大小不一样时依然可以适用,只要它们的列指标和行指标相同。
次加乘运算,完全符合利用寄存器进一步缓存共享内存数据的要求。不难看出该方法在 A 的列和 B 的行大小不一样时依然可以适用,只要它们的列指标和行指标相同。
 个
个 矩阵的乘积,64 个线程按照
矩阵的乘积,64 个线程按照 布局,这样就确定了小片的大小为一个边长
布局,这样就确定了小片的大小为一个边长 个元素的矩阵(每线程 8 元素 x8 线程)。这一点区别于原始分片算法中每个线程计算矩阵中的一个元素,也是充分利用寄存器的超低延迟的关键。
个元素的矩阵(每线程 8 元素 x8 线程)。这一点区别于原始分片算法中每个线程计算矩阵中的一个元素,也是充分利用寄存器的超低延迟的关键。
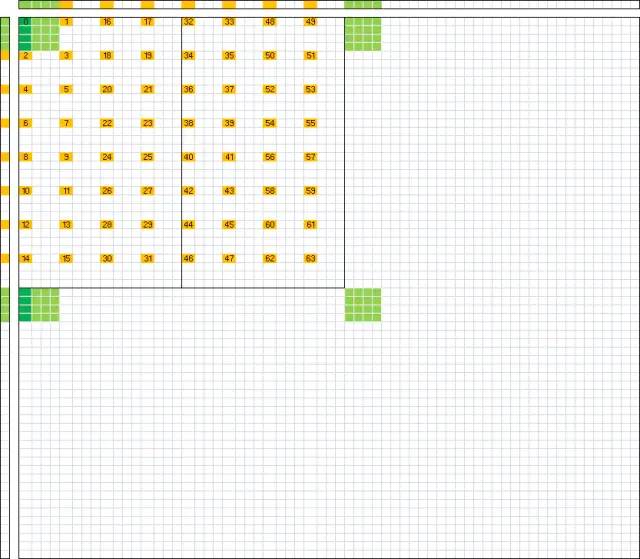 的小片,但为了充分利用寄存器资源,maxas 采用了完全不同的计算方法。如果线程块计算的是
的小片,但为了充分利用寄存器资源,maxas 采用了完全不同的计算方法。如果线程块计算的是 ,首先将矩阵 A 按每 64 行一条划分为
,首先将矩阵 A 按每 64 行一条划分为 的条,所需的输入数据全部在第条上,当然这一条数据还还是很大,需要进一步分次载入,maxas 中每次载入并消耗
的条,所需的输入数据全部在第条上,当然这一条数据还还是很大,需要进一步分次载入,maxas 中每次载入并消耗 ,分
,分 次完成。对于矩阵 B 方法类似,只不过是按列划分为
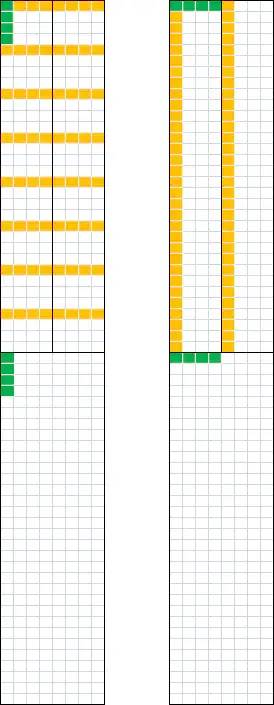
次完成。对于矩阵 B 方法类似,只不过是按列划分为 的条,转置后载入方法和 A 完全相同。其内存布局如下图所示:
的条,转置后载入方法和 A 完全相同。其内存布局如下图所示:


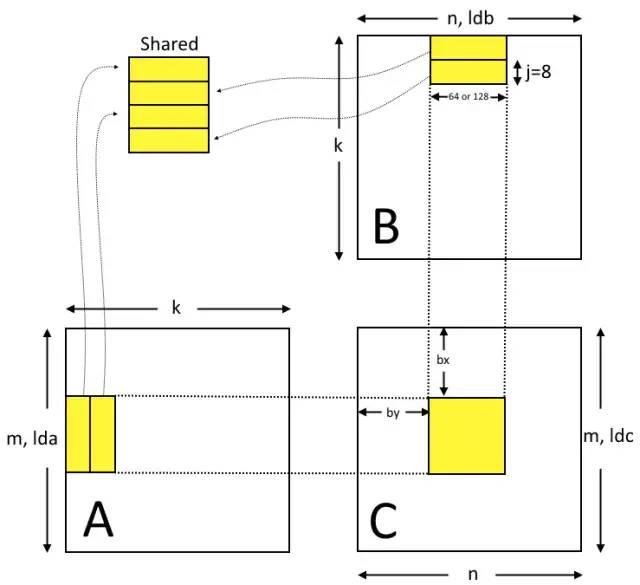
tid = threadId.x;bx = blockId.x; // 可以看作C_ij的iby = blockId.y; // 可以看作C_ij的jblk = tid >= 32 ? by : bx;ldx = tid >= 32 ? ldb/4 : lda/4; // lda和ldb为A的行数或B的列数,ldx为其在向量载入中的表示(每次4个浮点数故除以4),可以看成每一行的跨度tex = tid >= 32 ? texB : texA; // 64个线程分为2个warp,第一个载入纹理A,第二个载入纹理Btid2 = (tid >> 4) & 1; // 此处将32个线程分为两组,tid2=0为第一组载入图三中的第一行,tid2=1载入第二行tid15 = tid & 15; // 本线程在每一行中列的位置// 这些track变量表示本线程需要载入的数据在tex中的偏移,乘以4即在$A_i$或$B_j_T$中的偏移track0 = blk*64/4 + tid15 + (ldx * tid2); // 本线程载入数据的起始位置,解释见后文track2 = track0 + ldx*2; // 本线程载入的第二部分数据,在第一部分两行后,以此类推track4 = track0 + ldx*4;track6 = track0 + ldx*6;end = track0 + (k-8)*ldx; // 载入结束的标志,其中k为A的列数和B的行数,即两个相乘矩阵的公共维度,对于NxN的矩阵, k=N。因为每次载入8行所以减去8作为最后一次的载入的标记writeS = tid15*4*4 + tid2*64*4; // 本线程载入数据在共享内存中的偏移,注意其相当于track0的第二项的16倍,因为向量载入的偏移1代表(4个数x每个浮点数4字节)writeS += tid >= 32 ? 2048 : 0; // 如果载入的是矩阵B的数据,放在矩阵A的数据之后,而矩阵A占用(64列x8行x每元素4字节)=2048字节while (track0 < end){tex.1d.v4.f32.s32 loadX0, [tex, track0];tex.1d.v4.f32.s32 loadX2, [tex, track2];tex.1d.v4.f32.s32 loadX4, [tex, track4];tex.1d.v4.f32.s32 loadX6, [tex, track6];st.shared.v4.f32 [writeS + 4*0*64], loadX0;st.shared.v4.f32 [writeS + 4*2*64], loadX2;st.shared.v4.f32 [writeS + 4*4*64], loadX4;st.shared.v4.f32 [writeS + 4*6*64], loadX6;// our loop needs one bar sync after share is loadedbar.sync 0;// Increment the track variables and swap shared buffers after the sync.// We know at this point that these registers are not tied up with any in flight memory op.track0 += ldx*8;track2 += ldx*8;track4 += ldx*8;track6 += ldx*8;writeS ^= 4*16*64; // 又见magic number!其意义是A和B在共享内存中一共占4*16*64=4096字节,但是共享内存一共分配了8192字节的两组,每次载入后用这个操作切换到另外一组,其目的是实现一个流水线,在一个warp载入数据进一组时另一个warp就可以操作另一组已经完成载入的数据了// Additional loop code omitted for clarity.}
tex.1d.v4.f32.s32 loadX0, [tex, track];track += ldx*2;tex.1d.v4.f32.s32 loadX2, [tex, track];track += ldx*2;tex.1d.v4.f32.s32 loadX4, [tex, track];track += ldx*2;tex.1d.v4.f32.s32 loadX6, [tex, track];track += ldx*2;
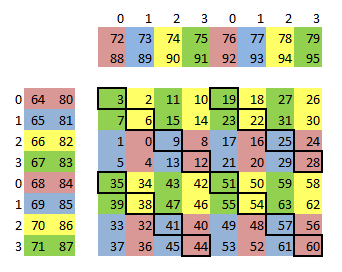
readAs = ((tid >> 1) & 7) << 4;图中线程 2*i 和 2*i+1 会用到同一段 A,可以写作 (i/2) % 8。这段位操作就是这个表达式的位操作实现。<<4 实现了每段 A 的列向量间隔 16 字节,这是向量载入 4 个浮点数的大小。
readBs = (((tid & 0x30) >> 3) | (tid & 1)) << 4 + 2048;
而不是直接计算,这也是为了避免 bank 冲突的技巧,在每个线程的实际计算中 4 个完全等价于 1 个矩阵。
readAs = ((tid >> 1) & 7) << 4;readBs = (((tid & 0x30) >> 3) | (tid & 1)) << 4 + 2048;while (track0 < end){// Process each of our 8 lines from sharedfor (j = 0; j < 8; j++){// We fetch one line ahead while calculating the current line.// Wrap the last line around to the first.prefetch = (j + 1) % 8; // +1代表预读取// Use even/odd rows to implement our double buffer.if (j & 1) // 在两组寄存器j0和j1直接切换{// 共享内存到寄存器的传输还是使用向量指令// 在maxas的代码中可见j0Ax<00-03>是4个连续的寄存器,一个指令就可以完成到这4个寄存器的传输而无需一一写出ld.shared.v4.f32 j0Ax00, [readAs + 4*(prefetch*64 + 0)];ld.shared.v4.f32 j0By00, [readBs + 4*(prefetch*64 + 0)];ld.shared.v4.f32 j0Ax32, [readAs + 4*(prefetch*64 + 32)];ld.shared.v4.f32 j0By32, [readBs + 4*(prefetch*64 + 32)];}else{ld.shared.v4.f32 j1Ax00, [readAs + 4*(prefetch*64 + 0)];ld.shared.v4.f32 j1By00, [readBs + 4*(prefetch*64 + 0)];ld.shared.v4.f32 j1Ax32, [readAs + 4*(prefetch*64 + 32)];ld.shared.v4.f32 j1By32, [readBs + 4*(prefetch*64 + 32)];}}// swap our shared memory buffers after reading out 8 linesreadAs ^= 4*16*64;readBs ^= 4*16*64;// Additional loop code omitted for clarity.}
FFMA R0, R4, R5, R0; # R0, R4 在 bank 0,R5 在bank 1,R0和R4产生bank冲突
0-63 号分配给 C 矩阵;
64-71 和 80-87 分配给 A 矩阵,72-79 和 88-95 分配给 B 矩阵(分配两倍于实际大小用于流水线预读取)。
FFMA R2, R4.reuse, R5, R2; # 此处指定R4将会被重用,将其放入缓存FFMA R0, R4.reuse, R5, R0; # R0和R4本来产生bank冲突,但因为上一条指令缓存了第二个操作数R4,只要到bank中取R0即可,从而避免了bank冲突FFMA R0, R5, R4, R0; # R0和R4的bank冲突依然会发生,因为所缓存的R4在第2个操作数,但本指令中R4落在第3个操作数上。
1, 0, 2, 3, 5, 4, 6, 7, 33, 32, 34, 35, 37, 36, 38, 39, 45, 44, 46, 47, 41, 40, 42, 43, 13, 12, 14, 15, 9, 8, 10, 11,17, 16, 18, 19, 21, 20, 22, 23, 49, 48, 50, 51, 53, 52, 54, 55, 61, 60, 62, 63, 57, 56, 58, 59, 29, 28, 30, 31, 25, 24, 26, 27
--:-:-:-:1 FFMA R37, R71.reuse, R72.reuse, R37;--:-:-:-:1 FFMA R36, R71.reuse, R73.reuse, R36;#前2条指令对第3个操作数缓存了R72和R73,它们被接下来的2条指令用到--:-:-:-:1 FFMA R38, R69.reuse, R73, R38;--:-:-:-:1 FFMA R39, R69.reuse, R72, R39;#前4条指令对第2个操作数缓存了R69和R71,它们被接下来的4条指令用到--:-:-:-:1 FFMA R45, R71.reuse, R74.reuse, R45;--:-:-:-:1 FFMA R44, R71, R75.reuse, R44;--:-:-:-:1 FFMA R46, R69.reuse, R75.reuse, R46;--:-:-:-:1 FFMA R47, R69, R74.reuse, R47;
01:-:-:-:0 FFMA R1, R66.reuse, R72.reuse, R1;--:-:-:-:1 LDS.U.128 R80, [R106+0x200];--:-:-:-:1 FFMA R0, R66, R73.reuse, R0;--:-:-:-:0 FFMA R2, R64.reuse, R73.reuse, R2;--:-:-:-:1 LDS.U.128 R88, [R107+0x200];--:-:-:-:1 FFMA R3, R64, R72.reuse, R3;--:-:-:-:0 FFMA R5, R67.reuse, R72.reuse, R5;--:-:-:-:1 LDS.U.128 R84, [R106+0x300];--:-:-:-:1 FFMA R4, R67, R73.reuse, R4;--:-:-:-:0 FFMA R6, R65.reuse, R73.reuse, R6;--:-:1:-:1 LDS.U.128 R92, [R107+0x300];--:-:-:-:1 FFMA R7, R65, R72.reuse, R7;
矩阵先传输至共享内存。之所以不从寄存器直接传输到主显存是因为按照现有的线程布局无法利用 GPU 的超大带宽。要充分利用 GPU 的带宽我们希望每个 warp 的 32 个线程所同时传输的数据是连续的,这样一个时钟周期里就可以一下子传输 128 字节的数据,如果这些数据离得太远,在最坏可能下需要分 32 次才能传输出去。
矩阵是分成在列上对齐的两对。按图 6 所示的 maxas 的寄存器分配,每一列上有八个寄存器。比如第一列有寄存器 3,7,1,5,属于同一个矩阵的一列,以及 35,39,33,37,属于令一个矩阵的一列。由于结果矩阵 C 也是按照行优先储存的,如果将寄存器 3,7,1,5 拷贝到 4 个连续的寄存器(maxas 中命名为 cs<0-3>),35,39,33,37 拷贝到 cs<4-7>,就可以用向量储存指令在两个指令内将 8 个数拷贝到共享内存中对应的位置。图 7 中的左图是这个过程的示意图,可以看作将图 2. 的矩阵每隔四列抽出一条来拼在一起。完成后在共享内存中得到一个的矩阵,其中每一列都是连续的且对应于 C 矩阵中的一列。这时候改变一下线程次序,令 warp 中一个线程传输该列上一个字节的数据,就可以完成一次传输 32 个连续的浮点数。这个共享内存中的缓冲区可以利用之前为载入 A 和 B 所分配的空间,在完成 C 的计算后 A 和 B 的数据已经没有用了。
tid31 = tid & 31;tid32 = tid & 32; // 只可能取两个值,0 为第一个warp,32为第二个warp// Remove the high bits if present from the last loop's xor.// Also remove the 2048 added onto readBs.// 之前对A和B在共享内存中分配了两倍于所需的容量(4096字节),一块用于已载入数据的计算,一块用于载入下一段A和B,每一块的前2048字节存放A,后2048字节存放B//这个AND操作等价于取第一块存放A的内存来存放CreadAs &= 0x7ff; // 本线程左上角数据在64x64矩阵中的行坐标readBs &= 0x7ff; // 本线程左上角数据在64x64矩阵中的列坐标// Write to shared using almost the same shared mapping as before but collapse readBs down to stride one.writeCs = (readBs / 4) * 64 + readAs; // 本线程左上角数据在64x64矩阵中的相对左上角的一维偏移,根据行坐标和列坐标计算出。64/4是行优先储存矩阵进行向量传输的跨度。对于线程0这就是图7左图中的绿色格子中最上面的一个。// Read out with a mapping amenable to coalesced global writesreadCs = ((tid32 << 3) + tid31) << 2; // 本线程在读取时开始的一维偏移,不考虑用于将元素个数转换为字节数的<<2操作,可以看到每个warp中的31个线程的编号tid31对应连续的readCs,也就是图7右图中的一整列黄色格子,第一个warp对应左边一列,第二个warp对应右边一列,中间相隔4行,也就是64*4==32<<3(第二个warp中tid32就是32)个元素。由图7右图可见很明显一个warp可以一次传输32个连续的浮点数。ldc4 = ldc * 4; // ldc是矩阵C在行优先储存中列方向的跨度,因子4代表其单位为字节而不是浮点数。cx = bx*64 + tid31; // cx可看作所要写入主显存的那一整列的在整个矩阵C中所对应的行数cy = by*64 + (tid32 >> 1); // cy可看作所要写入主显存的那一整列的在整个矩阵C中所对应的列数,显然对于同一个warp列数是一样的// Cy00, Cy04, Cy08, Cy12 是图7右图中上面那四个绿色格点在整个矩阵C中的偏移// 虽然它们在共享内存中相隔1列,在矩阵C中它们之间的间隔是4列,所有它们之间的偏移是ldc4*4Cy00 = (cy*ldc + cx) * 4 + C;Cy04 = Cy00 + ldc4 * 4;Cy08 = Cy00 + ldc4 * 8;Cy12 = Cy00 + ldc4 * 12;foreach copy vertical line of 8 registers from C into .v4.f32 cs0 and cs4{// 步骤1. 从不连续的寄存器到共享内存// Feed the 8 registers through the warp shuffle before storing to global// 这里有一个缺失的步骤,每个线程首先将其上下对其的两个4x4矩阵中取出同一列的各四个元素,此时它们为了避免bank冲突// 不得不位于不连续的寄存器上,这个步骤将其复制到8个连续的额外的寄存器cs0-cs7,上面的矩阵使用cs0-3,下面的使用cs4-7st.shared.v4.f32 [writeCs + 4*00], cs0; // 将连续的寄存器cs0,cs1,cs2,cs3用向量指令传输到共享内存中该4个数对应的位置st.shared.v4.f32 [writeCs + 4*32], cs4; // 和上一行同样的操作,因为上下两个4x4矩阵间隔32个数,需要对写入位置增加4*32字节的偏移// 步骤2. 从共享内存读取到寄存器,重用cs寄存器,不过此时并不用到其连续的特性// cs0, cs2, cs4, cs6位于同一行上,在行优先储存中相差64个元素,4*64字节ld.shared.f32 cs0, [readCs + 4*(0*64 + 00)];// cs1,cs3,cs5,cs7位于另一行上,由图7右图可见与上一行相差32个元素ld.shared.f32 cs1, [readCs + 4*(0*64 + 32)];ld.shared.f32 cs2, [readCs + 4*(1*64 + 00)];ld.shared.f32 cs3, [readCs + 4*(1*64 + 32)];ld.shared.f32 cs4, [readCs + 4*(2*64 + 00)];ld.shared.f32 cs5, [readCs + 4*(2*64 + 32)];ld.shared.f32 cs6, [readCs + 4*(3*64 + 00)];ld.shared.f32 cs7, [readCs + 4*(3*64 + 32)];// 步骤3. 将cs寄存器的数写入主显存,对于整个warp相当于将一列连续的32个浮点数写入主显存。逻辑上可以看作是步骤2的反过程,除了改列的位置在共享内存和主显存中有所不同。st.global.f32 [Cy00 + 4*00], cs0;st.global.f32 [Cy00 + 4*32], cs1;st.global.f32 [Cy04 + 4*00], cs2;st.global.f32 [Cy04 + 4*32], cs3;st.global.f32 [Cy08 + 4*00], cs4;st.global.f32 [Cy08 + 4*32], cs5;st.global.f32 [Cy12 + 4*00], cs6;st.global.f32 [Cy12 + 4*32], cs7;// 在下一次循环中输出本线程所计算的4个4x4矩阵的下一列,对应于C矩阵中的下一列,注意不要和图7中共享内存中的下一列混淆。Cy00 += ldc4;Cy04 += ldc4;Cy08 += ldc4;Cy12 += ldc4;// After processing forth set shift over to the stride 32 registers// 补充说明,4次循环后4个4x4矩阵的左边两个已经传输到主显存了,接下去要传输右边的两个。// 左边和右边两对4x4矩阵在C矩阵中对应的位置可以通过平移32列而重合,考虑到矩阵本身宽度有4列(在之前4次循环中已经通过 += ldc4 4次得到实现)// 实际需要额外平移的是左右两对4x4矩阵的间距32-4=28列,这是这就是28这个magic number的来由if (4th iteration){Cy00 += ldc4 * 28;Cy04 += ldc4 * 28;Cy08 += ldc4 * 28;Cy12 += ldc4 * 28;}}
 ,此时输入矩阵的载入和结果的输出会有相应的变化,但理解了 64 线程实现后这些变化就非常简单,在此无需赘述。对于比较大的矩阵 256 线程实现有一些性能上的优势,详细测试结果参见 maxas 文档。
,此时输入矩阵的载入和结果的输出会有相应的变化,但理解了 64 线程实现后这些变化就非常简单,在此无需赘述。对于比较大的矩阵 256 线程实现有一些性能上的优势,详细测试结果参见 maxas 文档。
登录查看更多
相关内容

Arxiv
7+阅读 · 2020年3月12日



相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2020年3月12日