使用PaddleFluid和TensorFlow实现图像分类网络SE_ResNeXt | 文末超大福利

专栏介绍:Paddle Fluid 是用来让用户像 PyTorch 和 Tensorflow Eager Execution 一样执行程序。在这些系统中,不再有模型这个概念,应用也不再包含一个用于描述 Operator 图或者一系列层的符号描述,而是像通用程序那样描述训练或者预测的过程。
本专栏将推出一系列技术文章,从框架的概念、使用上对比分析 TensorFlow 和 Paddle Fluid,为对 PaddlePaddle 感兴趣的同学提供一些指导。
视觉(vision)、自然语言处理(Nature Language Processing, NLP)、语音(Speech)是深度学习研究的三大方向。三大领域各自都诞生了若干经典的模块,用来建模该领域数据所蕴含的不同特性的模式。上一篇文章介绍了 PaddleFluid 和 TensorFlow 的设计和核心概念,这一篇我们从图像任务开始,使用 PaddleFluid 和 TensorFlow 来写一个完全相同的网络,通过这种方式了解我们的使用经验如何在不同平台之间迁移,从而帮助我们选择便利的工具,集中于机器学习任务本身。
这一篇我们使用图像分类中的 SE_ResNeXt [1][2] 作为实践任务。
SE 全称 Sequeeze-and-Excitation,SE block 并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中。SENet block 和 ResNeXt 的结合在 ILSVRC 2017 的分类项目中取得 了第一名的成绩。在 ImageNet 数据集上将 top-5 错误率从原先的最好成绩 2.991% 降低到 2.251%。
如何使用代码
本篇文章配套有完整可运行的代码,代码包括以下几个文件:

在终端运行下面的命令便可以使用 PaddleFluid 进行模型的训练,训练过程如果未在当前工作目录下的 cifar-10-batches-py 目录中检测到训练数据(无需手动创建 cifar-10-batches-py 文件夹),会自动从网络中下载训练及测试数据。
python SE_ResNeXt_fluid.py
在命令行运行下面的命令便可以使用 TensorFlow 进行模型的训练,训练中模型验证以及模型保存:
python SE_ResNeXt_tensorflow.py
注:本系列的最新代码,可以在 github 上的 TF2Fluid [3] 中随时 获取。
背景介绍
卷积神经网络在图像类任务上取得了巨大的突破。卷积核作为卷积神经网络的核心,通常被看做是在局部感受野上将空间上(spatial)的信息和通道(channel)上的信息进行聚合的信息聚合体。 通常,一个卷积 Block 由卷积层、非线性层和下采样层(Pooling 层)构成,一个卷积神经网络则由一系列堆叠的卷积 block 构成。随着卷积 Block 的层数的加深,感受野也在不断扩大,最终达到从全局感受野上捕获图像的特征来进行图像的描述的目标。
Squeeze-and-Excitation (SE)模块
图像领域很多研究工作从不同角度出发研究如何构建更加强有力的网络学习图像特征。例如,如 Inception 结构中嵌入了多尺度信息:使用多个不同卷积核,聚合多种不同感受野上的特征来获得性能增益;将 Attention 机制引入到空间(spatial)维度上等,都获得了相当不错的成果。
除了上角度,很自然会想到,是否可以从考虑特征通道(channel)之间的关系出发,增强网络性能?这正是 Squeeze-and-Excitation 模块的设计动机。
SE block 由两个非常关键的操作,Squeeze 和 Excitation 构成, 其核心思想是:显式地建模特征通道之间的相互依赖关系,通过自适应学习的方式来获取每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征(有用 feature map 权重增大 )并抑制对当前任务用处不大的特征(无效或效果小的 feature map 权重减小),达到更好的模型效果。
下图是 SE Block 示意图,来自 参考文献 [1] 中的 Figure 1。
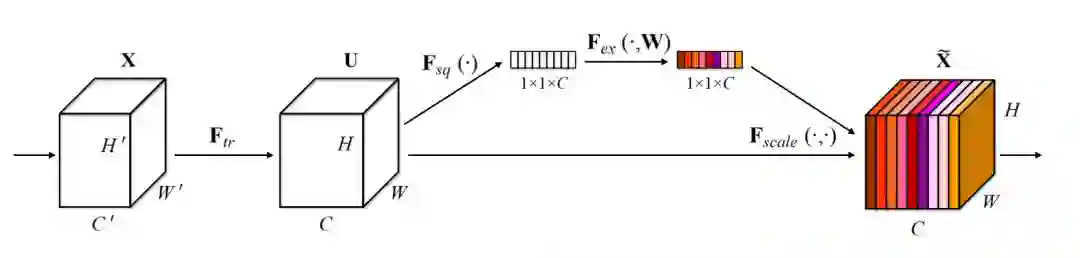
▲ 图 1. SE block示意图
Squeeze 操作,图 1 中的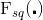
通过一个全局的 pooling 操作,沿着空间维度进行特征压缩,将每个二维的特征通道(channel)变成一个实数。这个实数一定程度上具有全局的感受野。Squeeze 操作的输出维度和输入 feature map 的特征通道数完全相等,表征着在特征通道维度上响应的全局分布,Squeeze 使得靠近输入的层也可以获得全局的感受野,这在很多任务中都是非常有用。
Excitation 操作,图 1 中的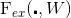
类似与门机制。通过参数WW的作用,为每个特征通道学习一个权重,其中 可学习参数WW用来显式地建模特征通道间的相关性。
Scale 加权操作:
最后一步,将 Excitation 的输出的权重看做是经过特征选择后每个特征通道的重要性,然后通过 scale 逐通道对原始特征进行 reweight,完成在通道维度上的对原始特征的重标定(recalibration)。
当 SE block 嵌入原有一些分类网络中时,不可避免会增加需要学习的参数和 引入计算量,但是 SE block 带来的计算量较低,效果面改善依然非常可观,对大多数任务还是可以接受。
SE模块和Residual Connection叠加
图 2 是 SE 模块和 ResNet 中的 Residual Connection 进行叠加的原理示意图,来自参考文献 [1] 中的 Figure 3。
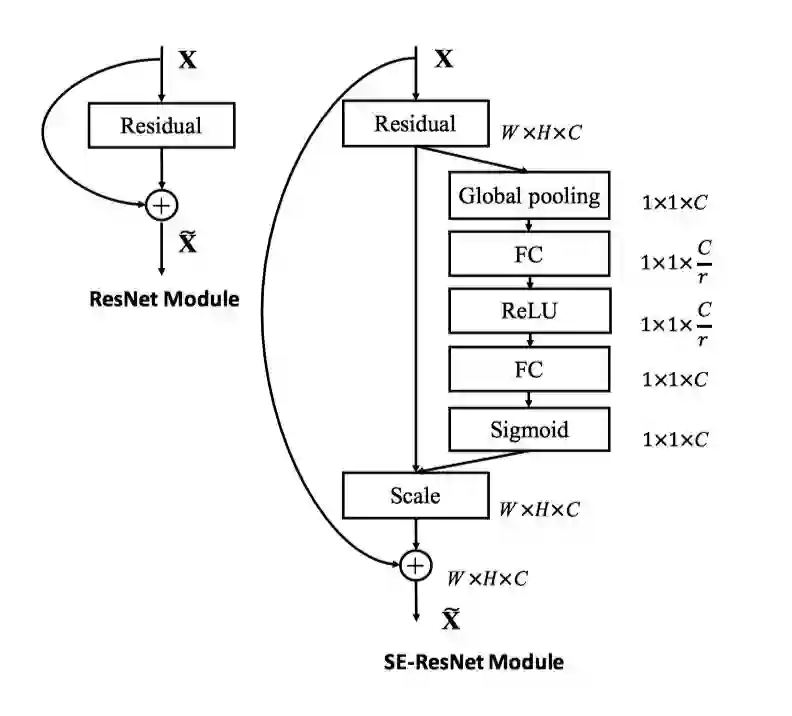
▲ 图 2. SE 模块与Residual Connection叠加
SE 模块可以嵌入到含有 Residual Connection 的 ResNet 的模型中,图 2 右是 SE 叠加 Residual Connection 的示意图。论文中建议在 Residual Connection 的跨层连接进行 Addition 操作前,而不是 Addition 操作之后叠加 SE 模块:前对分支上 Residual 的特征进行了特征重标定(recalibration),是由于如果主干上存在 0 ~ 1 的 scale 操作(extraction 步骤),在网络较深时候,反向传播算法进行到网络靠近输入层时,容易出现梯度消散的情况,导致模型难以优化。
ResNeXt 模型结构
深度学习方法想要提高模型的准确率,通常会选择加深或加宽网络。但是随着网络深度或者宽度的增加,网络参数(例如:特征通道数,filter size 等)量也显著增加,计算开销增大。ResNeXt 网络结构设计的初衷是希望在不增加参数复杂度的前提下,提高网络的性能,同时还减少了超参数的数量。
在引出 ResNeXt 网络之前,我们首先回顾图像分类领域两个非常重要的工作:VGG 和 Inception 网络(这两个网络的设计细节 PaddleBook 的图像分类 [4] 一节有详细的介绍)。VGG 网络通过堆叠相同形状的网络模块,这一简单策略来构建深度网络,之后的 ResNet 也同样使用了这一策略。这个策略降低了超参数的选择,在许多不同的数据集和任务上依然 有效工作,展示了很好的鲁棒性。
Inception 的网络结果经过精心设计,遵循:split-transform-merge 策略。在一个 Inception 模型中:(1)split:输入通过 1×1卷积被切分到几个低维 feature map;(2)transform:split 步骤的输出经过一组(多个)filter size 不同的特定滤波器(filters)映射变换;(3)merge:通过 concatenation 将 transform 步骤的结果融合到一起。
Inception 模型期望通过较低的计算量来近似大的密集的滤波器的表达能力。尽管 Inception 模型的精度很好,但是每个 Inception 模块要量身定制滤波器数量、尺寸,模块在每一阶段都要改变,特别是当 Inception 模块用于新的数据或者任务时如何修改没有特别通用的方法。
ResNeXt 综合了 VGG 和 Inception 各自的优点,提出了一个简单架构:采用 VGG/ResNets 重复相同网络层的策略,以一种简单可扩展的方式延续 split-transform-merge 策略,整个网络的 building block 都是一样的,不用在每个 stage 里对每个 building block 的超参数进行调整,只用一个结构相同的 building block,重复堆叠即可形成整个网络。
实图 3 来自参考文献 [2] 中的Figure 1,展示了 ResNeXt 网络的基本 building block。
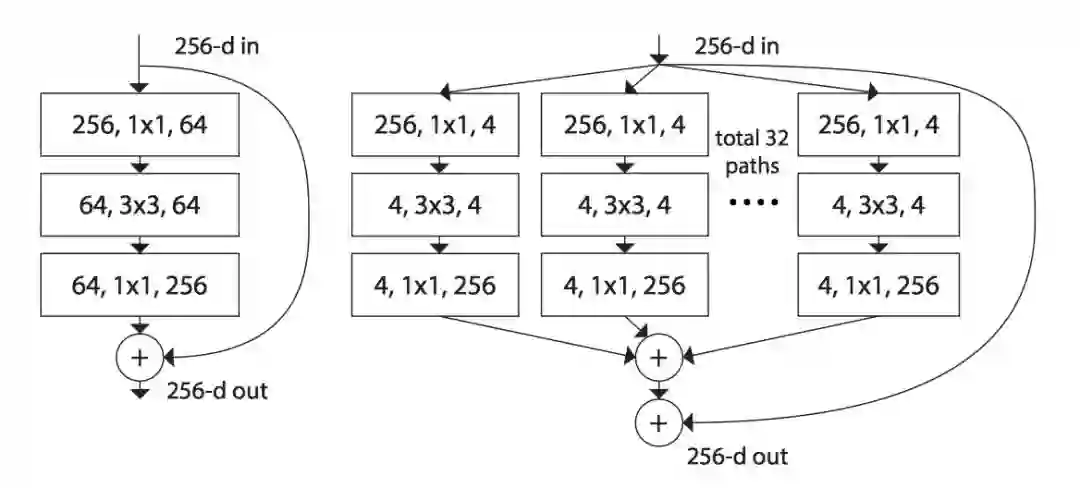
▲ 图 3. ResNeXt网络的基本building block
解释图 3 之前要先介绍一个名词 cardinality,是指 building block 中变换集合的大小(the size of the set of transformation)。图 3 中 cardinality=32,将左边的 64 个卷积核分成了右边 32 条不同 path,最后将 32 个 path 的输出向量的所有通道对应位置相加,再与 Residual connection 相加。
图 3 再结合上一节中介绍的“SE 模块和 Residual Connection 叠加”,便构成了最终的 SE_ResNeXt 网络的 building block,重复堆叠即可形成整个 ResNeXt。
CIFAR-10 数据集介绍
至此,介绍完 ResNeXt 模型的模型原理和基本结构,我们准备开始分别使用 PaddleFluid 和 TensorFlow 构建训练任务。
这一篇我们使用 cifar10 数据集 [5][6] 作为实验数据。cifar-10 数据集包含 60000 个 32*32 的彩色图像,共有 10 类,图 4 是 cifar10 数据集的 10 个类别。图 4 是 cifar-10 数据集的 10 个类别示意图。

▲ 图 4. cifar10数据集
cifar10 数据集有 50000 个训练图像和 10000 个测试图像,被划分为 5 个训练块和 1 个测试块,每个块有 10000 个图像。测试块包含从每类随机选择的 1000 个图像。
下载数据
运行训练程序时, 如果在当前执行目录下没有 cifar-10-batches-py 目录,或是 cifar-10-batches-py 目录下没有已经下载好的数据,PaddleFluid 和 TensorFlow 的数据读取模块会调用 data_utils [7] 中的 download_data 方法自动 从网站上下载 cifar-10 数据集,无需手动下载。
加载cifar-10数据集
PaddleFluid
1. 定义网络的输入层:
上一篇基本使用概念中介绍过 PaddleFluid 模型通过 fluid.layers.data 来接收输入数据。图像分类网络以图片以及图片对应的类别标签作为网络的输入:
IMG_SHAPE = [3, 32, 32]
images = fluid.layers.data(name="image", shape=IMG_SHAPE, dtype="float32")
labels = fluid.layers.data(name="label", shape=[1], dtype="int64")在上面的代码片段中, fluid.layers.data 中指定的 shape 无需显示地指定第 0 维 batch size,框架会自动补充第 0 维,并在运行时填充正确的 batch size。
一副图片是一个 3-D Tensor。PaddleFluid 中卷积操作使用 channel-first 的数据输入格式。因此在接收 原始图像 数据时,shape 的三个维度其含义分别是:channel、图片的宽度以及图片的高度。
2. 使用 python 语言编写的 data reader 函数
PaddleFluid 中通过 DataFeeder 接口来为对应的 fluid.data.layersfeed 数据,调用方式如下:
train_reader = paddle.batch(train_data(), batch_size=conf.batch_size)
feeder = fluid.DataFeeder(place=place, feed_list=[images, labels])在上面的代码片段中:
1. 仅需要用户编写 train_data() 这样一个 python 的 generator。这个函数 是 PaddleFluid 要求提供的 data reader 接口,函数名字不限。
2. 实现这个 data reader 接口时只需要考虑:如何从原始数据文件中读取数据,返回一条以 numpy ndarrary 格式的训练数据。
3. 调用 paddle.batch(train_data(), batch_size=conf.batch_size) 接口会将数据首先读入一个 pool 中,进行 shuffle,然后从 pool 中依次取一个一个的 mini-batch。
完整代码请参考 train_data() [8],这里不再直接粘贴代码片段。
TensorFlow
1. 定义 placeholder
在 TensorFlow 中,通过定义 placeholder 这样一个特殊的 Tensor 来接受输入数据。
IMG_SHAPE = [3, 32, 32]
LBL_COUNT = 10
images = tf.placeholder(
tf.float32, shape=[None, IMG_SHAPE[1], IMG_SHAPE[2], IMG_SHAPE[0]])
labels = tf.placeholder(tf.float32, shape=[None, LBL_COUNT])
需要注意的是:
TensorFlow 中的卷积操作默认使用 channel-last 数据格式( 也可以在调用卷积的接口中使用 channel-first 的数据格式),images 这个 placeholder 的 shape 和 PaddleFluid 中 images 形状不同。
在 placeholder 中,batch size 这样运行时才可以确定具体数值的维度使用 None 代替。
2. 通过 feeding 字典为placeholder 提供数据
TensorFlow 通过 session 管理运行一个计算图,在 调用 session 的 run 方法时,提供一个 feeding 字典,将 mini-batch 数据 feed 给 placeholder。
下面的代码片实现了 加载 cifar-10 数据进行训练。
image_train, label_train = train_data()
image_test, label_test = train_data()
total_train_sample = len(image_train)
for epoch in range(1, conf.total_epochs + 1):
for batch_id, start_index in enumerate(
range(0, total_train_sample, conf.batch_size)):
end_index = min(start_index + conf.batch_size,
total_train_sample)
batch_image = image_train[start_index:end_index]
batch_label = label_train[start_index:end_index]
train_feed_dict = {
images: batch_image,
labels: batch_label,
......
}上面代码片段中的 train_data() [7] 完成了原始数据的读取。与 PaddleFluid 中只需考虑读取一条数据由框架完成组 batch 不同,train_data 读取所有数据,由用户程序控制 shuffle 和组 batch。
构建网络结构
使用不同深度学习框架的核心就是使用框架提供的算子构建神经网络模型结构。PaddleFluid 和 TensorFlow 各自提供的基本算子的详细说明,可以在各自官网获取。
这一篇提供了代码文件 SE_ResNeXt_fluid.py [9] 和 SE_ResNeXt_tensorflow.py [10] 分别是用 PaddleFluid 和 TensorFlow 写成的 ResNeXt 网络,两个文件中的网络结构完全相同,并且代码结构也完全相同。核心都是 SE_ResNeXt 这个类,如下面代码片段所示:
class SE_ResNeXt(object):
def __init__(self, x, num_block, depth, out_dims, cardinality,
reduction_ratio, is_training):
...
def transform_layer(self, x, stride, depth):
...
def split_layer(self, input_x, stride, depth, layer_name, cardinality):
...
def transition_layer(self, x, out_dim):
...
def squeeze_excitation_layer(self, input_x, out_dim, reduction_ratio):
...
def residual_layer(self, input_x, out_dim, layer_num, cardinality, depth,
reduction_ratio, num_block):
...
def build_SEnet(self, input_x):
...
SE_ResNeXt_fluid.py [9] 和 SE_ResNeXt_tensorflow.py [10] 中 SE_ResNeXt 类有着完全相同的成员函数,可以通过对比在两个平台下实现同样功能的代码,了解如何使用经验如何在两个平台之间迁移。
2-D卷积层使用差异
2-D 卷积是图像任务中的一个重要操作,卷积核在 2 个轴向上平移,卷积核的每个元素与被卷积图像对应位置相乘,再求和。卷积核的不断移动会输出一个新的图像,这个图像完全由卷积核在各个位置时的乘积求和的结果组成。图 5 是当输入图像是 4-D Tensor 时(batch size 这里固定是 1,也就是 4-D Tensor 的第一维固定为 1),2-D 卷积的可视化计算过程。
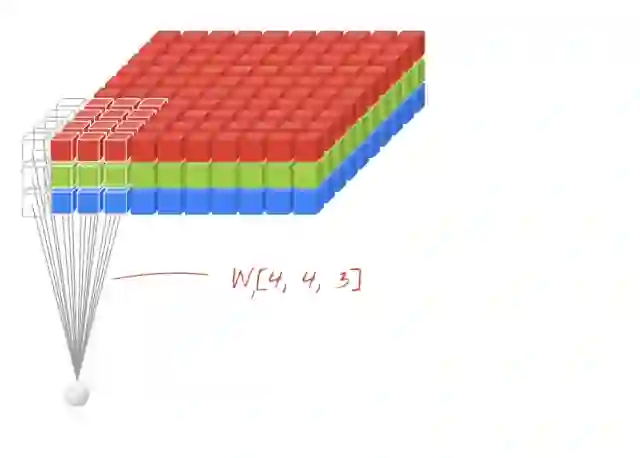
▲ 图 5. RGB 3通道图像输入上的2-D卷积
作者 : Martin Görner / Twitter: @martin_gorner
卷积计算的一些细节在 PaddleFluid 和 TensorFlow 中略有不同,在这里我们稍作解释。
下面是 PaddleFluid 2-D 卷积调用接口:
fluid.layers.conv2d(
input,
num_filters,
filter_size,
stride=1,
padding=0,
dilation=1,
groups=None,
act=None,
...)1. 在PaddleFluid卷积使用"channel-first"输入数据格式,也就是常说的“NCHW”格式。
如果输入图像是“channel-last”格式,可以在卷积操作之前加入 fluid.layers.transpose operator,对输入数据的各个轴进行换序。
2. PaddleFluid 中卷积计算的 padding 属性用户需要自己进行计算,最终输出图像的 height 和 width 由下面公式计算得到:


padding 属性 可以接受一个含有两个元素的 python list,分别指定对图像 height 方向和 width 方向填充。如果 padding 是一个整型数而不是一个 list 使,认为 height 和 width 方向填充相同多个 0。
这个逻辑同样适用于 stride 和 dilation 参数。
下面是 TensorFlow 2-D 卷积调用接口:
tf.layers.conv2d(
inputs,
filters,
kernel_size,
strides=(1, 1),
padding='valid',
data_format='channels_last'
...)1. 在 TensorFlow 卷积默认使用"channel-last"输入数据格式,也就是常说的“NHWC”格式。
2. TensorFlow 中卷积计算的 padding 属性可以指定两种模式:“valid”:不填充;"same":卷积计算完毕输出图像的宽度和高度与输入图像相同。
正则项使用差异
L2 正则项作为预防过拟合的手段之一,在神经网络训练中有着重要作用。PaddleFluid 平台和 TensorFlow 中添加 L2 正则的 使用接口略有不同。
PaddleFluid
在 PaddleFluid 中使用 L2 正则这样的标准正则项较为简单,L2 正则作为 optimizer 的一个参数,直接传递正则项系数即可。
optimizer = fluid.optimizer.Momentum(
learning_rate=conf.learning_rate,
momentum=0.9,
regularization=fluid.regularizer.L2Decay(conf.weight_decay))TensorFlow
在 TensorFlow 中,L2 正则作为损失函数的一部分,需要显示地为网络中每一个需要添加 L2 正则项的可学习参数添加 L2 正则。
l2_loss = tf.add_n([tf.nn.l2_loss(var) for var in tf.trainable_variables()])
optimizer = tf.train.MomentumOptimizer(
learning_rate=learning_rate,
momentum=conf.momentum,
use_nesterov=conf.use_nesterov)
train = optimizer.minimize(cost + l2_loss * conf.weight_decay)以上部分是 PaddleFluid 和 TensorFlow 使用中需要关注的一些差异,ResNeXt 模型在 两个平台训练的其它接口调用细节,可以在代码 SE_ResNeXt_fluid.py 和 SE_ResNeXt_tensorflow.py 中找到,这里不再粘贴所有代码,整个过程都遵循:
定义网络结构;
加载训练数据;
在一个 for 循环中读取 一个一个 mini-batch 数据,调用网络的前向和反向计算,调用优化过程。
总结
这一篇我们从图像领域的图像分类问题入手,使用 PaddleFluid 和 TensorFlow 实现完全相同 ResNeXt 网络结构。 来介绍:
1. 在 PaddleFluid 和 TensorFlow 中如何读取并为网络 feed 图片数据;
2. 如何使用 PaddleFluid 和 TensorFlow 中的 2-d 卷积,2-d pooling,pad 等图像任务中常用计算单元;
3. 如何运行一个完整的训练任务,在训练中对测试集样本进行测试。
可以看到 PaddleFluid 和 TensorFlow 的图像操作接口高度相似。PaddleFluid 能够支持与 TensorFlow 同样丰富的图像操作,这也是今天主流深度学习框架共同的选择。作为用户,我们的使用经验可以在平台之间 非常 简单的进行迁移,只需要略微关注接口调用细节的一些差异即可。
在下面的篇章中,我们将进一步在 NLP 任务中对比如果使用 PaddleFluid 和 TensorFlow 中的循环神经网络单元处理序列输入数据。并且逐步介绍多线程,多卡等主题。
参考文献
[1]. Hu J, Shen L, Sun G. Squeeze-and-excitation networks[J]. arXiv preprint arXiv:1709.01507, 2017.
[2]. Xie S, Girshick R, Dollár P, et al. Aggregated residual transformations for deep neural networks[C]//Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on. IEEE, 2017: 5987-5995.
[3]. TF2Fluid: https://github.com/JohnRabbbit/TF2Fluid
[4]. PaddleBook图像分类
http://www.paddlepaddle.org/docs/develop/book/03.image_classification/index.cn.html
[5]. Learning Multiple Layers of Features from Tiny Images, Alex Krizhevsky, 2009.
https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
[6]. The CIFAR-10 dataset: https://www.cs.toronto.edu/~kriz/cifar.html
[7]. data_utils
https://github.com/JohnRabbbit/TF2Fluid/blob/master/02_image_classification/data_utils.py#L35
[8]. train_data()
https://github.com/JohnRabbbit/TF2Fluid/blob/master/02_image_classification/cifar10_fluid.py#L43
[9]. SE_ResNeXt_fluid.py
https://github.com/JohnRabbbit/TF2Fluid/blob/master/02_image_classification/SE_ResNeXt_fluid.py
[10]. SE_ResNeXt_tensorflow.py
https://github.com/JohnRabbbit/TF2Fluid/blob/master/02_image_classification/SE_ResNeXt_tensorflow.py

以下是简单粗暴送福利环节
PaperWeekly × PaddlePaddle
深度学习有奖调研
50份礼品坐等抱走
限量版T恤√小白板√机械键盘√
参与方式
扫描下方二维码提交问卷
▼

我们将从成功作答的用户中抽取50位
赠送限量版礼品一份🎁
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 参与抽奖


