Bandit算法在携程推荐系统中的应用与实践


文章作者:携程技术团队
编辑整理:Hoh
内容来源:《携程人工智能实践》
出品平台:DataFun
注:转载请在后台留言“转载”。
导读:携程作为全球领先的 OTA 服务平台,为用户提供诸多推荐服务。下面我们介绍几个在实际推荐场景中面临的问题:
假设一个用户对不同类别的内容感兴趣程度不同,那么推荐系统初次遇到这个用户时,如何快速地知道他对每类内容的感兴趣程度呢?
假设我们有若干广告库存,如何知道给每个用户展示哪个广告能获得最大的点击收益?如果每次都推荐效果最好的广告,那么新广告何时才有出头之日呢?
如果只推荐已知用户感兴趣的物品,会导致马太效应。例如,在实际的场景中,部分优质物品由于初始推荐策略 ( 如热门推荐策略等 ) 被推荐的次数变多,这导致用户购买或点击的次数较多,形成的用户购买轨迹也较多。这种策略会导致头部物品得到大量曝光,而中长尾物品的曝光次数很少。如何才能科学地为用户推荐一些新鲜的物品来平衡系统的准确性和多样性呢?
Bandit 算法源于赌博学,一个赌徒去摇老虎机,一个老虎机共有 n 个外表一模一样的臂,每个臂的中奖概率为 Pi,他不知道每个臂中奖的概率分布,那么每次选择哪个臂可以做到收益最大化呢?这就是多臂赌博机 ( Multi-armed Bandit,MAB ) 问题。
将 MAB 问题进行抽象,假设老虎机共有 n 个臂,每个臂的中奖概率为 Pi,用户可以对每个臂进行尝试,每次尝试若成功则中奖概率为 1,若失败则中奖概率为 0。用户不知道每个臂的中奖概率,需要调整尝试策略,最终找到中奖概率最大的臂。
Bandit 算法能较好地平衡探索和利用问题 ( E&E 问题 ),无须事先积累大量数据就能较好地处理冷启动问题,避免根据直接收益/展现实现权重计算而产生的马太效应,避免多数长尾、新品资源没有任何展示机会。利用 Bandit 算法设计的推荐算法可以较好地解决上述问题。
01
▬
Context-free Bandit 算法
1. 置信上限 ( Upper Confifidence Bound,UCB )
Context-free Bandit 算法的思想在于采用一种乐观的态度,根据每个臂预期回报的不确定性的上界值进行选择,确定每次选出的臂。每个臂尝试的次数越多,预期回报的置信区间越窄;每个臂尝试的次数越少,预期回报的置信区间越宽。对于某个臂 ai,计算相应的预期回报分数,即:
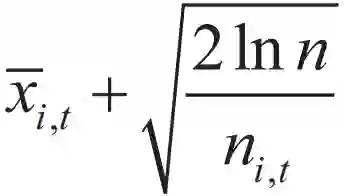
其中第一项:
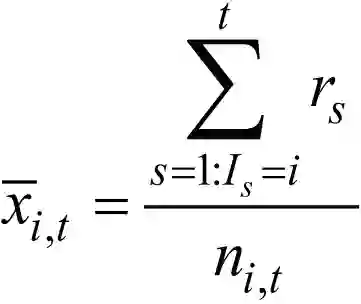
为第 i 个臂到当前时刻 t 的平均回报,称为利用项 ( Exploitation Term );后一项为置信度,即对第一项的回报估计的确信程度,称为探索项 ( Exploration Term ),rs 为在 s 时刻观察到的收益,ni,t 为第 i 个臂到当前时刻 t 的选择次数,n 为总选择次数。平衡选择已有较好表现的物品和具有潜在贡献的物品。如果物品的置信区间很宽 ( 被选次数很少,且不确定 ),那么它会倾向于被多次选择,即探索,这是算法冒风险的部分。如果物品的置信区间很窄 ( 备选次数很多,且能确定其好坏 ),那么均值大的倾向于被多次选择,即利用,这是算法保守稳妥的部分。
2. 汤姆森取样 ( Thompson Sampling )
汤姆森取样是一种通过贝叶斯后验采样 ( Bayesian Posterior Sampling ) 进行探索与利用的方法。采用贝叶斯思想,对奖赏分布的参数假设一个先验分布,根据观测到的奖赏更新后验分布,根据后验分布选择臂。
对于臂的奖赏服从伯努力分布,中奖概率 ( 被点击的概率 ) 即平均奖赏 θk∈[0,1]。假设第 k 个臂的奖赏分布固定但未知,即参数 θk 未知。在 Bernoulli Bandit 问题中,采用 Beta 分布对第 k 个臂的中奖概率建模,因为 Beta 分布是二项分布的共轭分布。如果先验分布为 Beta(α,β),在观测到伯努力二元选择 ( Bernoulli Trial ) 后,后验分布变为 Beta(α+1,β) 或 Beta(α,β+1)。
如果候选物品被选中的次数很多,那么 Beta 分布随着 αk+βk 的增大会变得更加集中,即这个候选物品的收益已经确定,用它产生的随机数基本在分布的中心位置附近,且接近这个分布的平均收益。
如果一个候选物品的 α+β 很大,且 α/(α+β) 也很大,那么该候选物品是一个好的候选项,其平均收益也很好。
如果一个候选物品的 α+β 很小,且分布很宽,即没有给予充分的探索次数,无法确定好坏,那么这个较宽的分布有可能得到一个较大的随机数,在排序时被优先输出,并用给予次数进行探索。

02
▬
Contextual Bandit 算法
Context-free Bandit 算法没有充分利用实时推荐的上下文特征 ( 用户偏好特征、场景特征等 ),在某一时刻对所有用户展示的物品 ( 本文案例中指创意文案 ) 是相同的。事实上,针对同一个文案,不同的用户在不同的情境下的接受程度是不同的。而 Contextual Bandit 算法充分利用了这些特征。
每个臂包含特定的随时间变化的上下文特征 xt,并且其回报 rt 和上下文特征 xt 直接相关,即存在一个函数 f,使得 rt=f(xt),其中 xt 为实际应用中抽象出的辅助选择每个臂的特征。根据不同的互联网推荐系统场景可以产生不同的用户特征和物品特征,不同的有关函数 f 的假设会得到不同的模型,选择最大化期望回报策略:
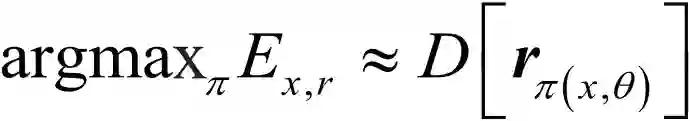
其中 Ex,r 为期望。对应 Context-free 的 Thompson Sampling 算法,算法3给出一种相应的 contextual bandit 算法:Linear Thompson Sampling 算法。


03
▬
场景应用
1. 文案创意选择
传统的 Test-rollout 策略分为 Testing Period 和 Post-testing Period,它在给定的测试周期内分配等量流量,挑选出指标表现最优的文案并切换全流量。但其存在下述缺陷。
在初始阶段,一部分用户会收到质量较低 ( 表现为 CTR 较低 ) 的文案,这会损害用户体验的效果,也会影响用户的参与度。
文案的表现会随着场景信息 ( 时间、地点等 ) 的变化而变化,在测试周期内得到的结论不一定适用于文案的整个生命周期。
org.apache.commons.math3.distribution.BetaDistribution
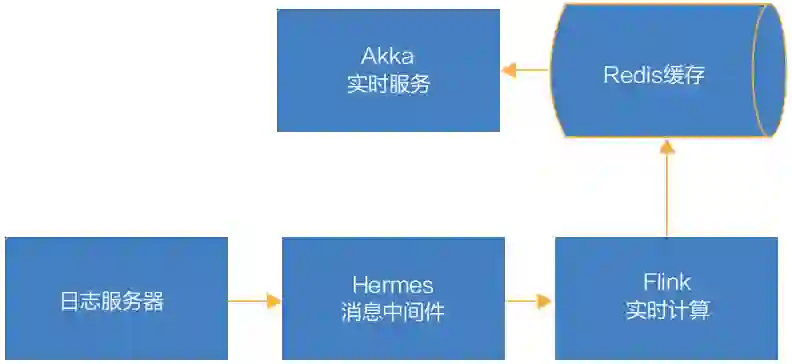
图 1 系统整体处理流程
αkt+1=αkt+Skt
βkt+1=βkt+Fkt
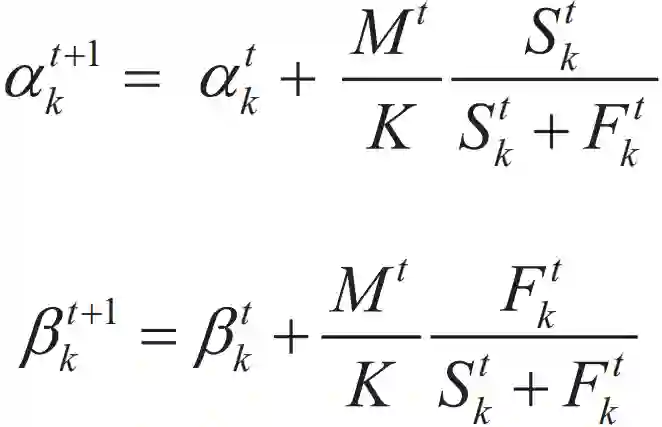





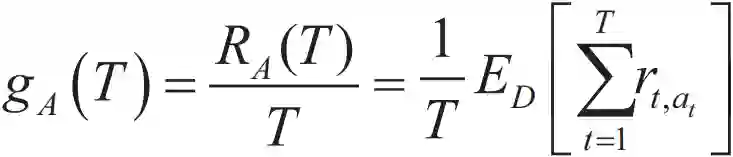
使用历史日志数据 D={(x,a,ra)},要求每个臂以 1/K 概率被选择,满足独立同分布。
奖赏的反事实性:当 Bandit 算法推选的臂不等于日志中的 a 时,则无法观测到奖赏 rπ(x)。





Jittering Technique:数据集中的每条记录在每个扩展数据 SB 中出现了 K 次。为了防止潜在的过拟合风险,在 context 特征上引入一小部分高斯噪声 ( Gaussian Noise ),这也是一种在神经网络领域中常用的技巧。
5. 实践经验
如果您喜欢本文,欢迎点击右上角,把文章分享到朋友圈~~
—— 新书推荐 ——
扫描下方二维码,进入购书页面
目前可享50元优惠~


社群推荐:
欢迎加入 DataFunTalk 技术交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信(微信号:DataFunTalker),回复:交流群,逃课儿会自动拉你进群。
关于我们:

一个在看,一段时光!👇




