【知识图谱】陈华钧:知识图谱与深度学习优势互补,将破解更多金融科技难题
作者: 陈华钧 来源: 恒生技术之眼
知识图谱的早期理念来自于Web之父Tim Berners Lee于1998年提出的Semantic Web,最初理想是把基于文本链接的万维网转化成基于实体链接的语义网。本质而言,知识图谱是一种语义网络,旨在从数据中识别、发现和推断事物、概念之间的复杂关系,是事物关系的可计算模型。知识图谱的构建涉及知识建模、关系抽取、图存储、关系推理、实体融合等多方面的技术,应用则涉及到语义搜索、智能问答、语言理解、决策分析等多个领域。
深度学习的概念源于人工神经网络的研究,由Hinton等人于2006年提出,是机器学习中一种基于对数据进行表征学习的方法,通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。深度学习的好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。将深度学习的方法融入知识图谱的应用中,是当下的研究热点之一。
深度学习与知识图谱获取
知识图谱构建涉及信息抽取相关任务,这里主要介绍深度学习在关系抽取和事件抽取中应用。
关系抽取
关系抽取目的是抽取句子中已标记实体对之间的语义关系。传统的关系抽取主要是基于特征工程的分类器模型对文本关系进行分类。近几年来,随着深度学习的发展,利用深度学习模型解决关系抽取的方法也迅速增长,例如Piecewise CNN、Attention-Based Bi-LSTM、Capsule Network等。但是,无论是传统模型还是深度学习的模型,都受到训练数据标注不足的限制,而人为标注又费时费力。因此,2009年斯坦福大学研究者首次提出利用结构化的知识图谱来标注训练数据,称为远程监督。
不过,远程监督会出现噪音,对此,研究者们提出很多降噪的方法。例如Label-Free Distant Relation Extraction via Knoweldge Graph Embedding (EMNLP2018)一文提出一种基于知识图谱嵌入的弱监督方法,将实例的具体标签替换为软标签向量表示,并没有原始数据产生的噪音标签,也就不会受到噪音的影响;选择性的注意力机制引入句子级别的注意力机制来对同一包中的多个实例施加不同的权重,从而降低噪音样本带来的影响。此外,还可利用强化学习、对抗学习的方法来缓解噪音问题。
事件抽取
事件抽取需要从包含事件描述的文本中抽取事件触发词和对应的事件论元,将事件划分成对应的类型,并找出每一个论元对应的角色。传统的机器学习方法在事件抽取特征提取过程中还是会依赖依存分析、句法分析、词性标注等传统的外部自然语言处理工具,造成误差积累。此外,有些语言和领域并没有这类处理工具,而且特征也需要人工设定。2015 年起基于深度学习的事件抽取方法逐渐成为研究热点,相比于传统机器学习,深度学习方法可以:
▲减少对外部 NLP 工具的依赖,甚至不依赖 NLP 工具,实现端对端的训练;
▲让输入蕴含更为丰富的语言特征,比如使用词向量;
▲自动提取句子特征, 避免了人工特征设计的繁琐。
在统计模型基础上,事件抽取方法可以分为流水线和联合模型两大类,前者先做事件检测,然后做元素抽取,在流水线框架中应用卷积神经网络,比较经典的模型有DMCNN等;后者两步同时做,遵循联合架构来进行具有丰富局部和全局特征的结构化预测,比较经典的模型有JRNN等。
表示学习与知识图谱推理
尽管现在大规模知识图谱层出不穷,但依然面临严重的知识不全的问题,补全知识图谱的一种方式是从已有的知识中推理出新的知识,补全缺失的连接,知识图谱表示学习可被用来解决这一问题。知识图谱表示学习将知识图谱中的元素映射到向量空间,为它们学习向量空间的表示,并借由向量空间表示之间的计算来拟合三元组的真值,从而达到补全知识图谱的目的。典型的知识图谱表示方法包含TransE、DistMult、ANALOGY等,分别依据不同的向量空间假设学习训练得来。
除了表示学习之外,知识图谱推理方法还包括规则学习推理,规则因其精确且人可理解的形式而成为了传统推理的一种重要介质。以前规则通常是人工定义,并通过推理机如HermiT和Pellet进行新知识推理和不一致性检测等。但人工定义规则产量低形式不够丰富且依赖专家知识,因此也涌现出了自动规则学习相关的研究工作如AMIE、AMIE+等,同时由于传统离散的符号推理机在大规模数据集下推理性能较低,也出现了可导的演绎推理机如TensorLog相关的研究。
表示学习和规则作为两种重要的知识推理方式,很多工作在研究如何结合两者并让两者相辅相成,例如Iterative Learning Embedding and Rules for Knowledge Graph Reasoning (WWW2019) 一文提出将表示学习与规则学习相结合,利用表示学习降低规则学习的搜索空间,利用规则学习解决表示学习所面临的知识图谱稀疏性问题等。其他一些类似工作如将规则加入到表示学习中来增强表示学习结果的RUGE,利用表示学习来增强规则学习效果的如RuLES,以及直接从表示学习结果中学习规则的如DistMult。总体来说,知识图谱的推理方式有多种且呈互相融合并优势互补的趋势。
图神经网络与知识图谱
近年来颇受关注的零样本学习,主要用于处理无训练样本目标类的分类,其优势在于利用类与类之间潜在的语义关系解决训练样本缺失的问题。类与类之间潜在语义关系的表现形式主要有:
▲类的属性描述,如类别“猫”相关的“是否有尾巴”、“眼睛大与否”等描述其特征的属性;
▲类的语义表示向量在空间内的分布;
▲类与类间的层次结构组织而成的类知识图谱。
在这三种形式中,知识图谱中蕴含的类间语义关系既包含清晰的层次结构,也包含关于类在知识图谱中对应实体的属性描述,如“猎豹”的“栖息地”、“所属物种”等。在深度学习的大背景下,如何依靠神经网络强大的计算能力学习以知识图谱组织的图结构数据,图卷积神经网络发挥了重要的作用。图卷积神经网络以图结构数据为输入,其中每个类作图中节点表示,类间关系即关联节点和节点的边,经过卷积计算和节点间信息的传播,每个类的信息在语义空间中进行更好的融合,同时可进行一定程度的推理,对于零样本学习语义特征空间的学习有着重要的意义。
如何赋能金融?
目前利用深度学习进行时间序列预测的方法,例如,长期短期记忆模型(LSTM),可以有效地学习来自原始数据的特征表示。但是,这些模型大多数不足以学习数据隐含的语义信息,导致预测结果不够准确,对数据变化的敏感度低,而且预测的结果不能被人类解释。
为了解决这些问题,可以将深度学习模型与知识图谱相融合,以增强原始数据的语义信息以及模型的可解释性。股票预测是一个经典的时间序列预测问题,接下来将以股票预测为例,分别从预测股票价格和预测股票趋势两个方面阐述深度学习模型和知识图谱相融合的方法和应用。
利用知识图谱增强数值数据的语义信息
以预测股票价格为例
“Deep Learning for Knowledge-Driven Ontology Stream Prediction”一文从语义网的角度重新审视LSTM,提出了一种新的基于语义嵌入的神经网络(STBNet),以解决时间序列预测问题。该模型不仅利用外部文本丰富数据流的语义,而且利用时间序列预测的背景知识潜在的语义信息。
以前的模型主要依赖原始数据中数值的表示,而这篇文章提出的STBNet模型将语义信息表示集成到混合神经网络中,基于本体流语义信息表示的相似性开发了一种新的注意力机制,然后在深度学习模型中结合本体流和数值分析,此外还利用卷积神经网络(CNN)学习文本词汇的表示,并以此来丰富STBNet中的本体流信息。
在这里,本体流的语义包含两种知识:(1)本体流的entailments,(2)对不同背景知识的注意力权重。STBNet利用股价、财经相关的推文、知识图谱三部分数据来预测S&P 500指数。其中,推文经过实词筛选,通过CNN和Soft Max提取文本特征,最终学习出推文对股价影响的程度,并以此结合描述逻辑的推理,生成通过entailment向量。
与股价相关的背景知识存在于知识图谱中,通过知识表示,计算S&P 500指数和每支股票的语义相似度,由此计算出每支股票对S&P 500指数的权重。最后对每支股票的股价加权,结合entailment向量,将新生成的数据输入LSTM预测股指S&P 500。
利用知识图谱增强模型的可解释性
以预测股票趋势为例
目前预测股票趋势的深度神经网络模型,虽然效果不错,但大多数具有两个共同的缺点:(1)当前方法对于股票趋势的突变不够敏感,(2)预测结果不能被人类解释。
为了解决这两个问题,“Knowledge-Driven Stock Trend Prediction and Explanation via Temporal Convolution Network”一文提出了一种新的知识驱动的时间卷积网络(KDTCN)模型,用于股票趋势预测和解释。首先,从财经新闻中提取结构化事件,并利用知识图谱引入外部知识来获取事件的向量表示。然后,将事件的向量表示和价格的数值向量表示结合起来预测股票趋势。通过评估预测准确性,来显示知识驱动的事件如何对股票趋势突变起作用。
实验证明,在股票趋势预测中加入知识驱动的事件,(1)可以提升整体的预测效果,对股票数据集当中的突变做出更快的反应,效果优于目前的最优方法;(2)基于知识图谱,将事件和事件之间的联系可视化,有助于对预测结果进行解释,特别是针对突变数据,这些解释以两种渐进的方式完成:一是可视化知识驱动的事件对突变预测结果的影响,二是将事件链接到外部的知识图谱来检索知识驱动的事件的背景知识。
金融领域应用展望
综上所述,知识图谱将和深度学习在更多层面形成互补,提升深度神经网络的可解释性、将图神经网络方法应用于知识图谱的推理与挖掘分析、利用知识图谱里面所蕴含的丰富的关联性知识帮助解决少样本和零样本学习的难题等等。此外,知识图谱技术和方法还将进一步与自然语言处理技术深度融合。未来,知识图谱将帮助金融行业构建有学识的人工智能,走向知识智能时代。具体说来,知识图谱能够:
▲提供更加智能的数据服务:知识图谱可以为金融问答系统、智能客服系统以及金融智能搜索等业务提供相应的支持,提升金融信息的检索效率,帮助构建知识型的智能金融客服,更加满足金融业务的实际需求;
▲帮助解决金融NLP所遇到的技术问题:例如实体语义消歧、文本语义理解、文本结构化等;
▲促进知识驱动的金融决策分析领域深入发展:在这方面,金融因果关联图谱的精细化构建及深入应用是一个趋势,包括围绕事件构建事理知识图谱、利用事件抽取技术提升新闻事件识别的敏感度、建立事件因果推理知识库、利用事理图谱分析技术对事件影响力传导进行深度分析等等;
▲提升金融预测能力:金融知识图谱在金融预测分析中具有重要的作用,是进行事件推理的基础,可应用于智能投研和智能投顾等领域。例如,当重大事件发生时,可根据产业链图谱推导出未来可能会受影响的公司;
▲让金融搜索更具价值:在智能投研、智能投顾和智能客服等场景,有了基于知识图谱的金融问答和语义搜索的帮助,不仅信息获取更加便捷,还可把各方面的相关信息组织成立体化信息,并且提供一定的分析预测结论;
▲赋能风险评估与反欺诈:风险评估是互联网时代的传统应用场景,是通过大数据、机器学习技术对用户行为数据分析后,进行用户画像,并进行信用和风险评估。引入知识图谱技术以后,可以进一步提升关系穿透、挖掘的能力,从而侦测欺诈行为,有助于关联交易关联账号识别、信息批露等风控控制,在风控领域的有较大的应用空间。
在刚过去不久的2018年,大规模自动化的知识图谱智能构建技术日趋成熟,越来越多受知识图谱技术支持的产品进入市场,越来越多的大数据研究人员认识到构建知识图谱是大数据价值发现的重要手段。随着知识图谱与深度学习等技术进一步融合,其必将为智能金融的发展提供更多助力。

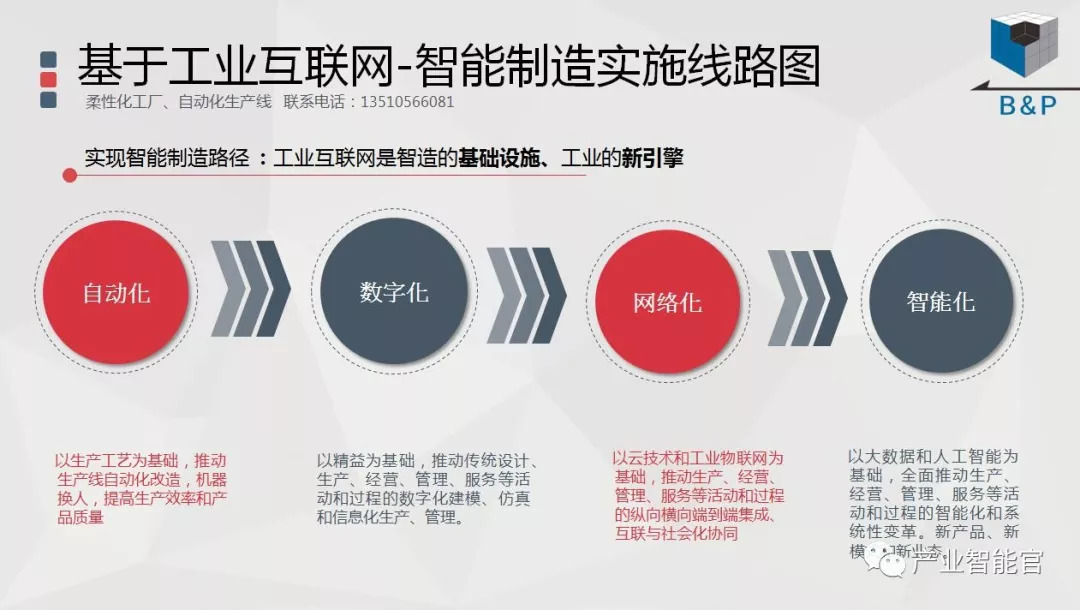
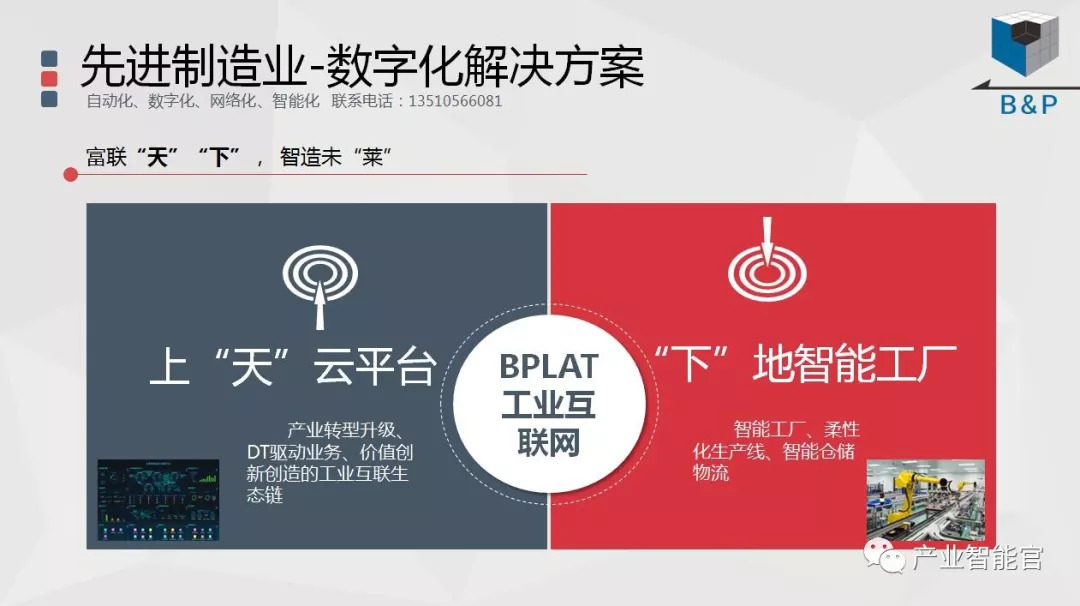
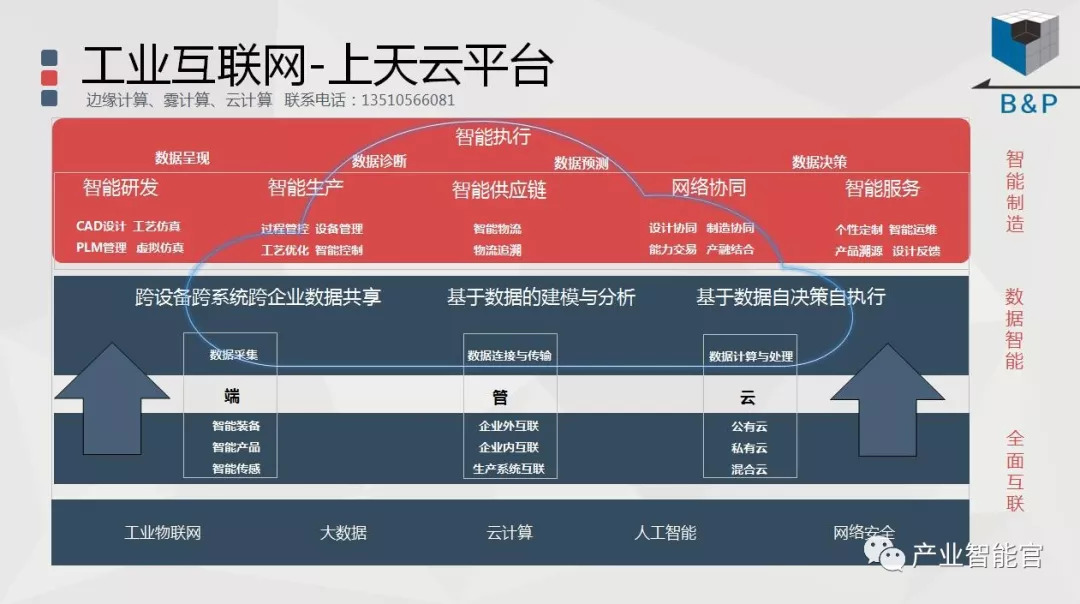
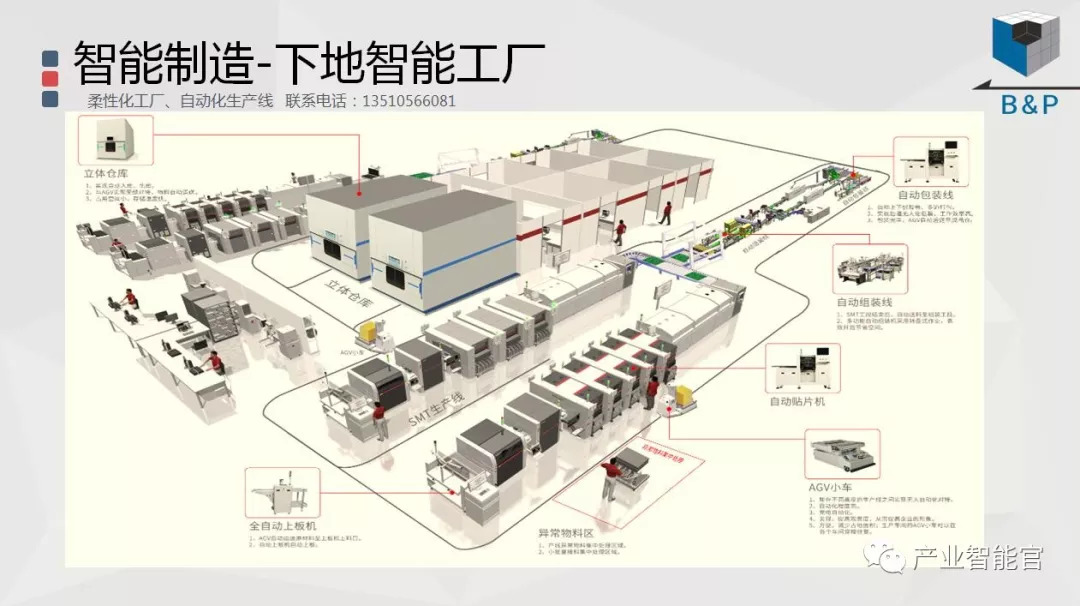
工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进产业OT(工艺+自动化+机器人+新能源+精益)技术和新一代信息IT技术(云计算+大数据+物联网+区块链+人工智能)深度融合,在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的机器智能认知计算系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。




