那些一键抠图的软件是怎么做到的?这些语义分割方法了解一下
选自Medium
作者:Bharath Raj
机器之心编译
参与:Geek AI、张倩
分类问题是为整个图像分配一个标签,而语义分割则是将从属于同一类的对象看成一个整体,为图像中的每一个像素点分配一个标签。本文对一些经典语义分割方法和基于深度学习的语义分割方法进行了讨论,此外还讨论了常见的选择和应用损失函数的方法。
语义分割。

经典方法
在深度学习时代到来之前,大量的图像处理技术被用来将图像分割成一些感兴趣的区域(ROI)。下面列出了一些常用的方法。
灰度分割
这是最简单的语义分割形式,它包括将一个区硬编码的规则或某个区域必须满足的特定的标签属性赋予这个区域。可以根据像素的属性(如灰度值)来构建这样的规则。「分裂-合并」算法就是一种用到了灰度分割技术的方法。该算法递归地将图像划分成若干子区域,直到可以为划分出的子区域分配一个标签,然后通过合并将相邻的带有相同标签的子区域融合起来。
该方法存在的问题是,规则必须是硬编码的。此外,仅使用灰度信息来表示复杂的类(比如人)是极其困难的。因此,需要特征提取和优化技术来恰当地学习这些复杂类所需的表征形式。
条件随机场
不妨考虑通过训练模型为每个像素分配一个类来分割图像。如果我们的模型不完美,我们可能会得到自然界中可能不存在的带有噪声的分割结果(如图中所示,狗像素与猫像素混合在一起)。
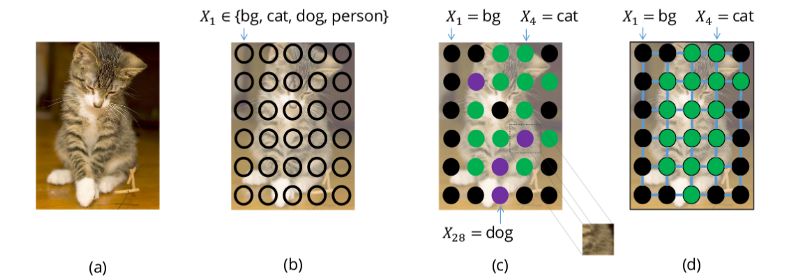
可以通过考虑像素之间的先验关系来避免这些问题,如果目标是连续的,那么相邻的邻像素往往具有相同的标签。使用条件随机场(CRF)对这样的关系进行建模。
CRF 是一种用于结构化预测的统计建模方法。与离散分类器不同,CRF 在进行预测之前可以考虑相邻的上下文环境,比如像素之间的关系。这使得它成为语义分割的理想候选建模方案。本节将探讨把 CRF 用于语义分割的方法。
图像中的每一个像素都与一组有限的可能状态相关联。在我们的例子中,目标标签是一组可能的状态。将一个状态(或标签 u)分配给单个像素(x)的成本被称为一元成本。为了对像素之间的关系建模,我们还考虑了将一对标签(u,v)分配给一对像素(x,y)的代价,这被称为成对代价。我们可以考虑相邻的像素对(网格 CRF)或者考虑图像中的所有像素对(密集 CRF)。
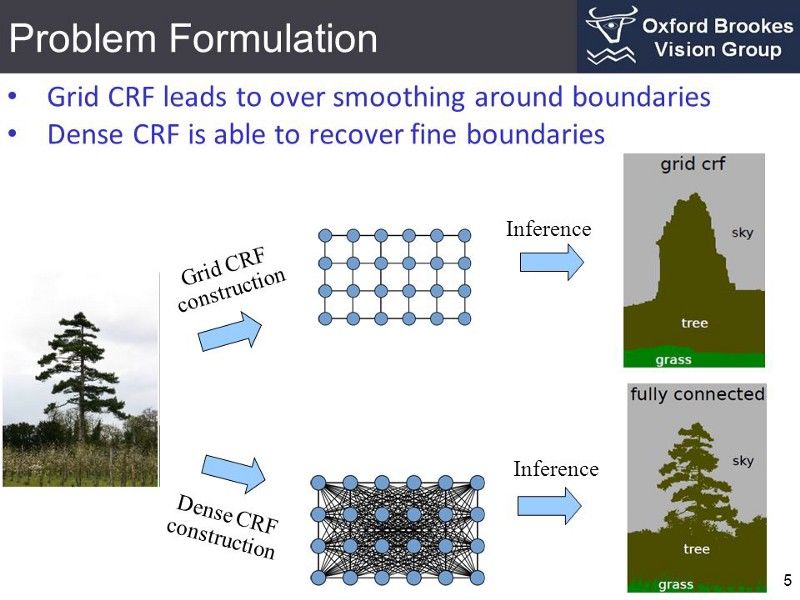
所有像素的一元成本和成对成本之和被称为 CRF 的能量(或成本/损失)。通过最小化能量,可以得到一个好的分割输出结果。
深度学习方法
深度学习极大地简化了进行语义分割的工作流程,并且得到了非常好的分割结果。在本节中,我们将讨论用于训练这些深度学习方法的流行的模型架构和损失函数。
1. 模型架构
全卷积网络(FCN)是最简单、最流行的用于语义分割的架构之一。在论文「FCN for Semantic Segmentation」中,作者使用 FCN 首先通过一系列卷积操作将输入图片下采样至一个较小的尺寸(同时得到更多的通道)。这组卷积操作通常被称为编码器(encoder)。然后通过双线性插值或者一系列转置卷积对编码后的输出进行上采样。这组转置卷积通常被称为解码器(decoder)。
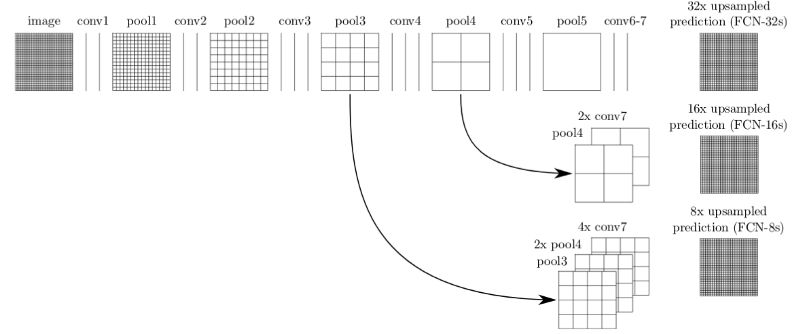
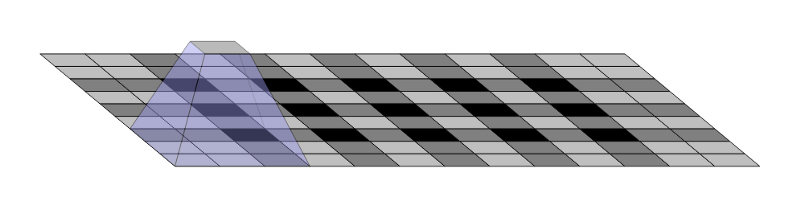
尽管这个基础的架构很有效,但是它也有一些缺点。其中一个缺点就是由于转置卷积(或称反卷积)操作的输出不均匀重叠而导致棋盘状伪影的存在。
另一个缺点是,由于编码过程中损失了一部分信息,导致边界的分辨率很低。
研究人员提出了一些解决方案来提高基础 FCN 模型的性能。下面是一些被证明行之有效的流行的解决方案:
U-Net
U-Net 是对简单的 FCN 模型架构的一种升级方案。它具有从卷积块的输出到相应的同一级的转置卷积块的输入之间的跳跃连接。
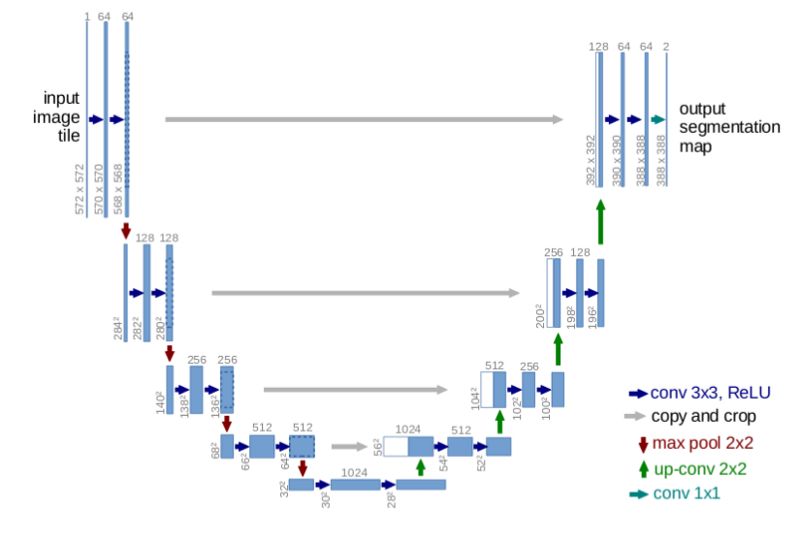
这种跳跃连接让梯度可以更好地流动,并提供了来自多个尺度的图像大小的信息。来自更大尺度(较上层)的信息可以帮助模型更好地分类。来自更小尺度(较底层)的信息可以帮助模型更好地进行分割。
Tiramisu 模型
Tiramisu 模型类似于 U-Net,而不同的是,它使用 Dense 块进行卷积和转置卷积(正如 DenseNet 的论文中所做的那样)。一个 Dense 块由若干层卷积组成,其中所有较早的层的特征图会被用作所有后续层的输入。生成的网络具有极高的参数效率,可以更好地利用较早的层的特征。
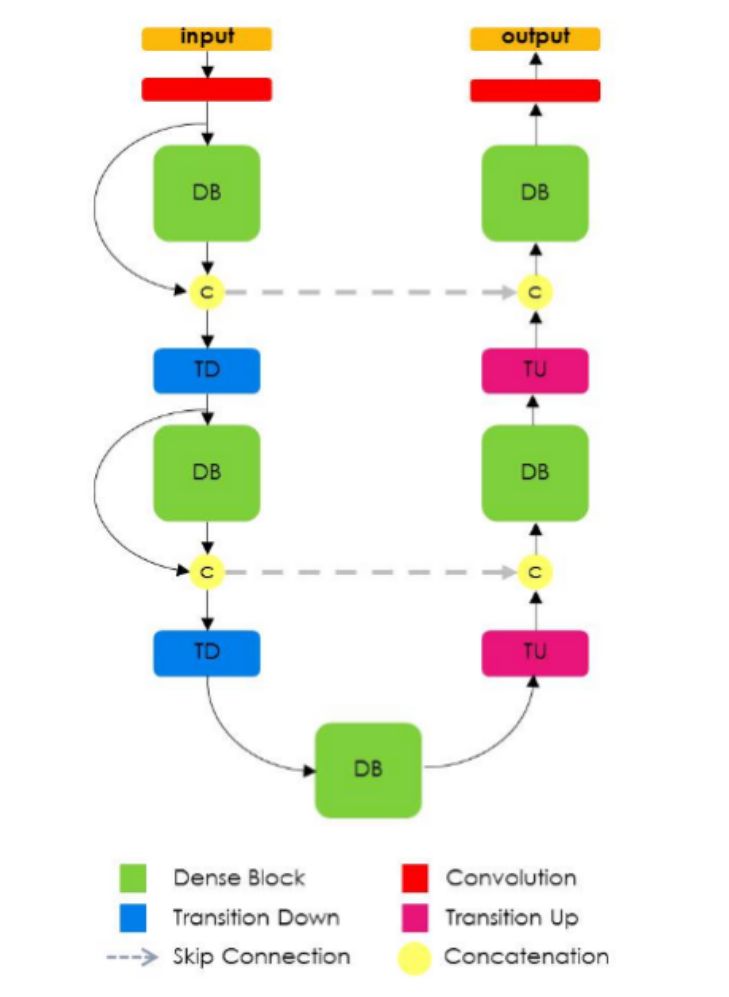
Tiramisu 网络
这种方法的缺点是,由于几个机器学习框架中的连接操作的性质,它的内存效率不是很高(需要大型 GPU 才能运行)。
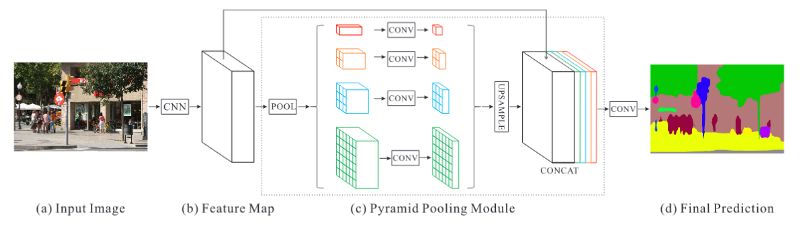
多尺度方法
一些深度学习模型显式地引入了整合来自多个尺度的信息的方法。例如,金字塔场景解析网络(PSPNet)使用四种不同尺寸的卷积核和步长来执行池化操作(最大池化或平均池化),从而输出卷积神经网络(如 ResNet)的特征图。然后,它使用双线性插值对所有池化输出和卷积神经网络的输出特征图的尺寸进行上采样,并在相应的通道上将它们连接起来。最后对这个连接的输出进行卷积操作从而生成预测结果。
Atrous 卷积(膨胀卷积)是一种可以在不增加大量参数的情况下,结合多尺度的特征的高效的方法。通过调节膨胀率(dilated rate),同一个卷积核的权值可以在空间中拓展地更远。这使其能够学习更多的全局上下文。
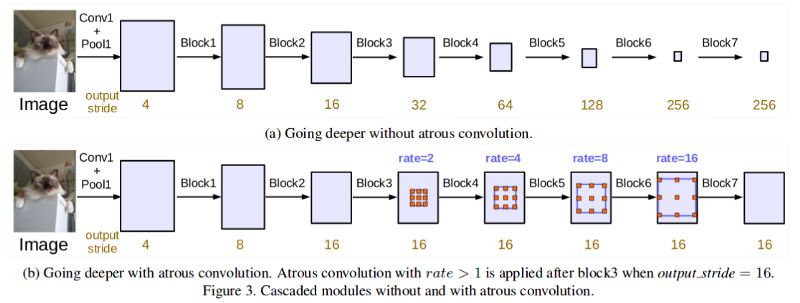
DeepLabv3 网络的论文使用了不同膨胀率的Atrous 卷积捕获来自多个尺度的信息,从而避免了显著的图像尺寸损失。他们通过级联的方式(如上图所示)和以并行的 Atrous 空间金字塔池化的方式(如下图所示)对 Atrous 卷积进行了实验。
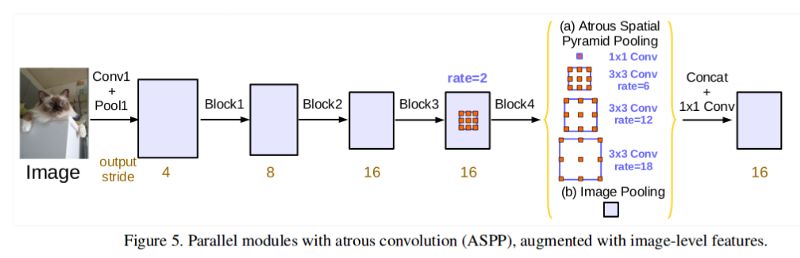
CNN-CRF 的混合方法
一些方法使用卷积神经网络作为特征提取器,然后将特征作为一元成本(势)输入给密集 CRF(Dense CRF)。由于CRF具有对像素间关系建模的能力,这种 CNN-CRF 的混合方法得到了很好的分割结果。
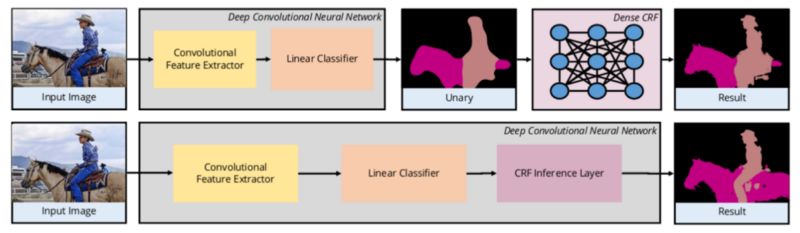
某些方法将 CRF 包含在了神经网络中,正如「CRF-as-RNN」(https://www.robots.ox.ac.uk/~szheng/papers/CRFasRNN.pdf)一文中所描述的,其中密集 CRF被建模为一个循环神经网络。这种端到端的训练如上图所示。
2. 损失函数
和一般的分类器不同,语义分割必须选择不同的损失函数。下面是一些常用的语义分割损失函数。
通过交叉熵实现的像素级 softmax用于语义分割的标签尺寸与原始图像相同。标签可以用one-hot编码的形式表示,如下图所示:
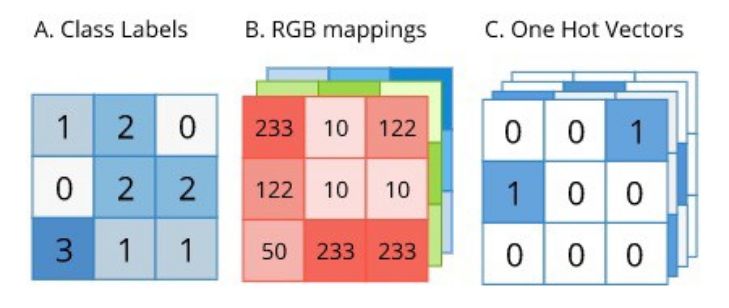
由于标签以方便的one-hot编码的形式存在,它可以直接被用作计算交叉熵的参考标准(目标)。然而,在应用交叉熵之前,必须对预测的输出在像素级上应用 softmax,因为每个像素可能属于我们的任何一种目标类。
焦点损失(Focal Loss)
《Focal Loss for Dense Object Detection》一文中介绍的焦点损失是对标准的交叉熵损失的一种改进,用于类别极度不平衡的情况。
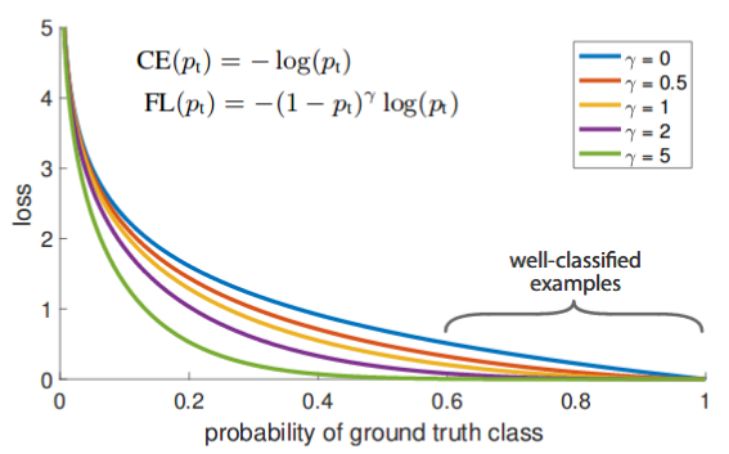
让我们看看如下图所示的标准交叉熵损失方程(蓝色)。即使在我们的模型对像素的类的置信度很高的情况下(比如 80%),它也存在一定的损失值(这里大约是 0.3)。另一方面,当模型对一个类的置信度很高时,焦点损失(紫色,gamma=2)不会对模型造成如此大的影响(即置信度为 80% 的情况下损失接近于 0)。
让我们用一个直观的例子来探究一下为什么这很重要。假设我们有一个 10000 像素的图像,像素只有两个类:背景类(one-hot编码形式下表示为 0)和目标类(one-hot编码形式下表示为 1)。假设图像的 97% 是背景,3% 是目标。现在,假设我们的模型以 80% 的置信度确定某像素是背景,但只有 30% 的置信度确定某像素是目标类。
使用交叉熵时,背景像素损失等于 (10000 的 97%)*0.3 = 2850,目标像素损失等于(10000 的3%)* 1.2 = 360 。显然,由于置信度更高的类造成的损失占主导地位,模型学习目标类的动机非常低。相比之下,对于焦点损失,由于背景像素的损失等于(10000 的 97%)* 0,即0。这让模型可以更好地学习目标类。
Dice 损失
Dice 损失是另一种流行的损失函数,用于类极度不平衡的语义分割问题。Dice 损失在《V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation 》一文中被提出,它被用于计算预测出的类和真实类之间的重叠。Dice 系数(D)如下所示:
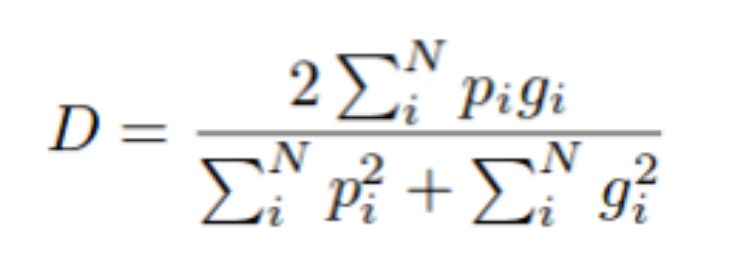
Dice 系数
我们的目标是最大化预测类和真实参考标准之间的重叠部分(即最大化 Dice 系数)。因此,我们通常将(1-D)最小化来实现相同的目标(由于大多数机器学习程序库只提供最小化损失函数的操作)。
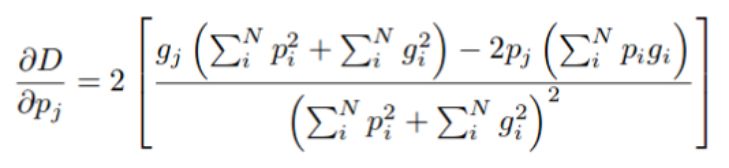
Dice 系数的求导过程
虽然 Dice 损失对类不平衡的样本很有效,但计算其导数的公式(如上所示)在分母中有平方项。当这些值很小时,我们就可以得到很大的梯度,导致训练不稳定。
应用场景
语义分割技术被用于了各种各样的真实生活场景下的应用。下面是语义分割的一些重要的用例。
自动驾驶
语义分割用于识别车道、车辆、人和其他感兴趣的物体。其结果可用于智能决策,以正确引导车辆。
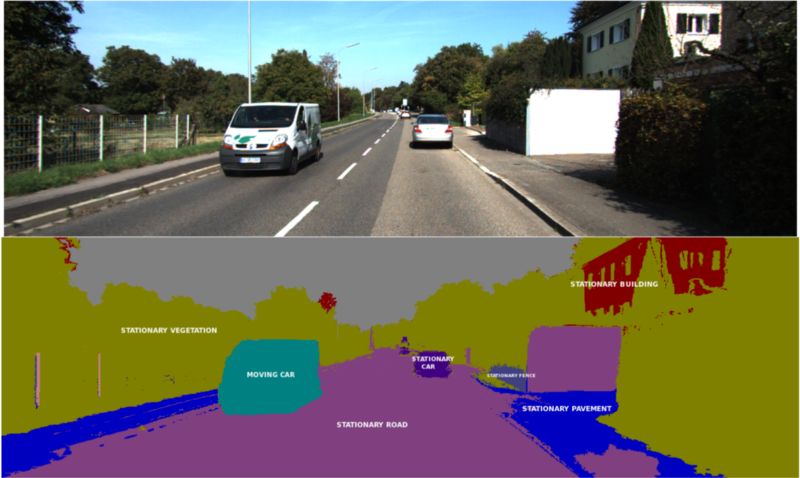
自动驾驶汽车的限制之一是:语义分割模型必须是实时运行的。解决上述问题的一个方法是将 GPU 与车辆进行本地集成。为了提高上述解决方案的性能,可以使用更轻量级(参数更少)的神经网络,或实现适用于边缘计算的技术。
医学影像分割
语义分割技术也被用于在医学扫描影像中识别显著性元素。该方法对识别图像中的异常(如肿瘤)十分有效。提升算法的准确率并解决低召回率的问题对于这种应用十分重要。
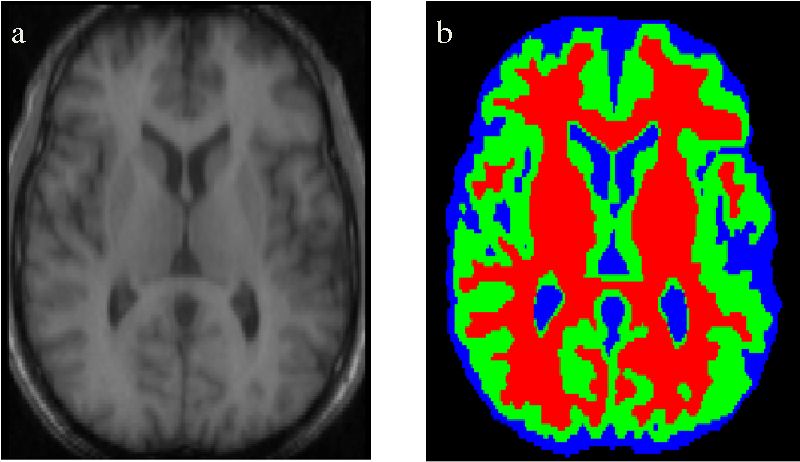
我们还可以将一些不那么关键的操作自动化处理,比如根据语义分割后的 3D 扫描影像估计器官的体积。
场景理解
语义分割通常是更复杂任务的基础,如场景理解和可视化问答(VQA)。场景理解算法的输出通常是一个场景图或一段字幕。
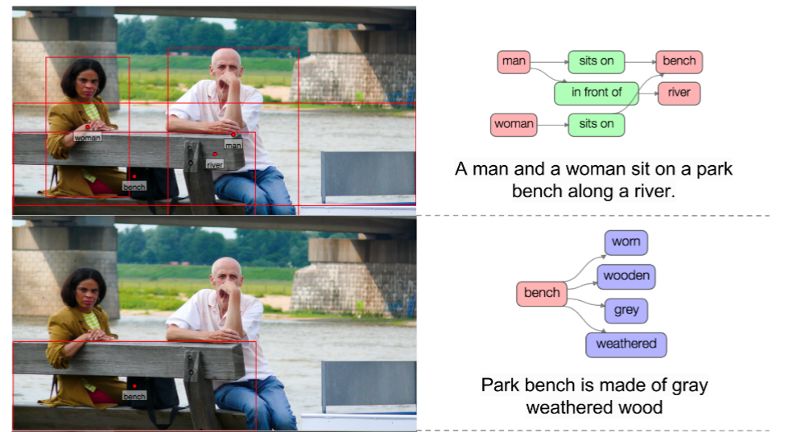
时尚产业
语义分割在时尚产业中被用来从图像中提取出服装对象,为零售商店提供类似的建议。更先进的算法可以在图像中「重新设计」特定的衣服。
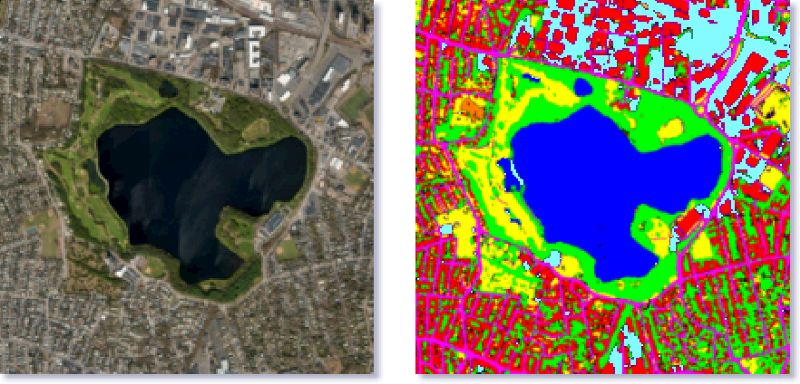
卫星(或航拍)图像处理
语义分割还被用于从卫星图像中识别土地类型。典型的用例包括对水体进行分割以提供准确的地图信息。其他高级用例包括绘制道路图、确定作物类型、确定免费停车位等等。
结语
深度学习技术极大地提升并简化了语义分割算法,为语义分割在现实生活中更广泛的应用铺平了道路。由于研究社区不断努力地提高这些算法的准确性和实时性能,本文中列举出的概念可能并不详尽。话虽如此,本文介绍了这些算法的一些流行的变体和他们在现实生活中的一些应用。

原文链接:https://medium.com/beyondminds/a-simple-guide-to-semantic-segmentation-effcf83e7e54?sk=3d1a5a32a19d611fbd81028cfd4f23fd
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


