基于孪生网络的目标跟踪算法汇总
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:王智卓
https://blog.csdn.net/WZZ18191171661/article/details/88369667
已授权转载
对于视觉目标跟踪(即单目标跟踪)任务而言,在2017年之前,大量的跟踪都是在相关滤波算法的基础上做出改进的,经典的算法包括KCF、DSST等。随着深度学习技术的兴起,跟踪领域中的学者们也开始去尝试着将深度神经网络应用该领域中,前期大家更多的是关注预训练的神经网络的使用;而从2017之后,以SINT和Siamese fc为代表的孪生网络跟踪器受到了研究者们的关注,主要的原因还是Siamese fc算法给大家展现了一个超快的跟踪速度,而且跟踪精度也不差。当前,跟踪领域主要分为两条主线,即基于相关滤波和基于孪生网络的跟踪器,本文主要的想法是对基于孪生网络的跟踪算法进行总结,看看学者们都做了那些改进工作,都在解决什么样的问题,只有搞清楚了别人做的工作以及别人这么做的研究,我们才有可能去超越别人,发出更好的Paper,下面就让我们进入今天的正题吧!

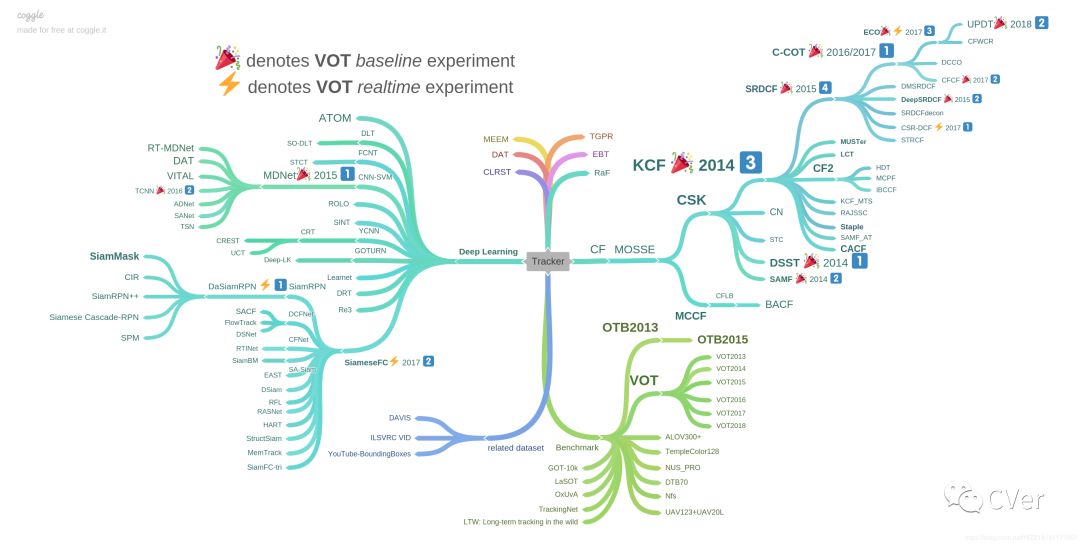
首先来看一张比较丑陋的发展路线图,这张图中我绘制了整个基于孪生网络的跟踪算法的发展路线图,按照从右向左的顺序展现了当前比较好的基于孪生网络的跟踪算法,绿色表示的是对应的年份,红色对应的是跟踪算法的名称。短短的两年时间,这条分支上已经出现了众多性能优异的跟踪算法,尤其是CVPR2019发表的SiamRPN++和CIR算法更加凸显了孪生网络的性能,使得基于孪生网络的跟踪算法的性能在真正意义上超越了基于相关滤波类的跟踪算法。为了大家更好的熟悉当前跟踪领域的方向,下图展示了跟踪大牛-王强的个人总结。
下面就开始我们的基于孪生网络的跟踪算法之旅吧!!!
1 SINT
论文:https://arxiv.org/abs/1605.05863
项目:
https://taotaoorange.github.io/projects/SINT/SINT_proj.html
代码:https://github.com/taotaoorange/SINT
1.1 论文整体框图
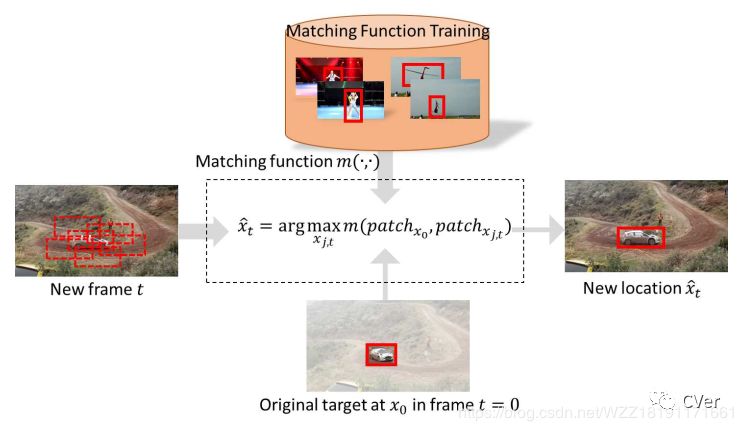
这篇论文可以说是基于孪生网络的开山之作,即首次开创性的将目标跟踪问题转化为一个patch块匹配问题,并神经网络来实现。
1.2 算法实现步骤
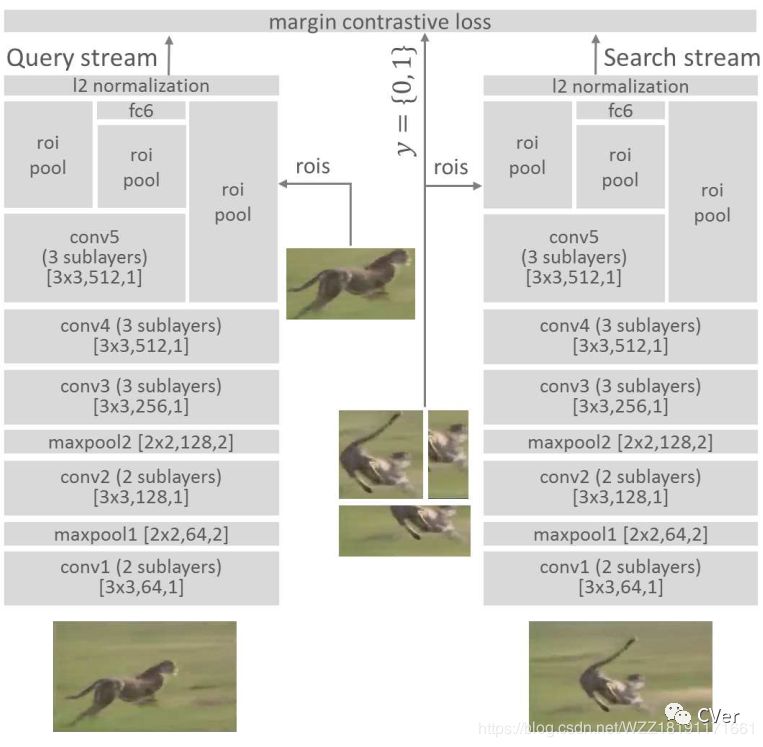
步骤1:获取ALOV数据集,并进行预处理;
步骤2:搭建如图所示的类似AlexNet的网络架构(引入ROI Pooling层);
步骤3:在训练数据中获取patch块,开始训练网络,获得最终的模型,即所谓的相似度函数;
步骤4:使用预训练好的网络进行跟踪,即所谓的patch块匹配,输出相应的结果。
1.3 算法创新点
创新1- 创造性的将目标跟踪任务转化为patch块匹配问题;
创新2-设计了相应的网络架构,尝试着去解决这个问题;
2 Siamese-fc
论文:https://arxiv.org/abs/1606.09549
项目:
http://www.robots.ox.ac.uk/~luca/siamese-fc.html
代码:https://github.com/bertinetto/siamese-fc
2.1 论文整体框图
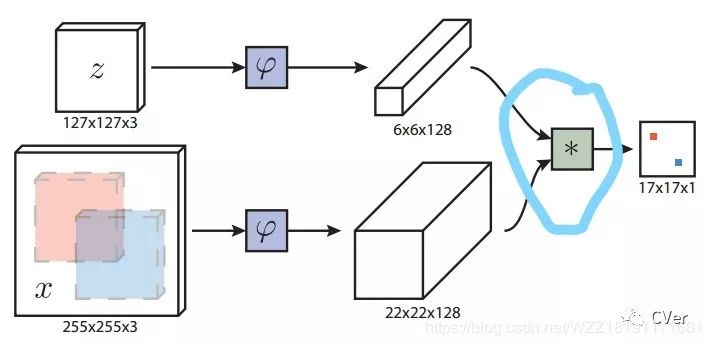
这个框图与众不同的是它是一个端到端的跟踪网络,而且速度很快!这篇论文使得基于孪生网络的跟踪器火了起来,让研究者们看到了新的希望。
2.2 算法实现步骤
步骤1:获取VID数据集,并进行预处理操作获得相应的patch块数据;
步骤2:将获取的patch数据输入到上图所示的网络架构中进行训练,从而获得最终的模型;
步骤3:将训练好的模型分别应用在视频中的第一帧和后续帧中,通过相关操作获得最终的结果;
2.3 算法创新点
创新1-设计了一个端到端的跟踪网络;
创新2-获得了一个很快的跟踪速度,Titan xp 58fps;
创新3-使用了一个更大的数据集来训练网络;
创新4-提到了很多关键的细节,包括网络中padding的影响,以及网络输入的大小等。
3 CFNet
论文:
http://openaccess.thecvf.com/content_cvpr_2017/papers/Valmadre_End-To-End_Representation_Learning_CVPR_2017_paper.pdf
项目:
http://www.robots.ox.ac.uk/~luca/cfnet.html
代码:https://github.com/bertinetto/cfnet
3.1 论文整体框图
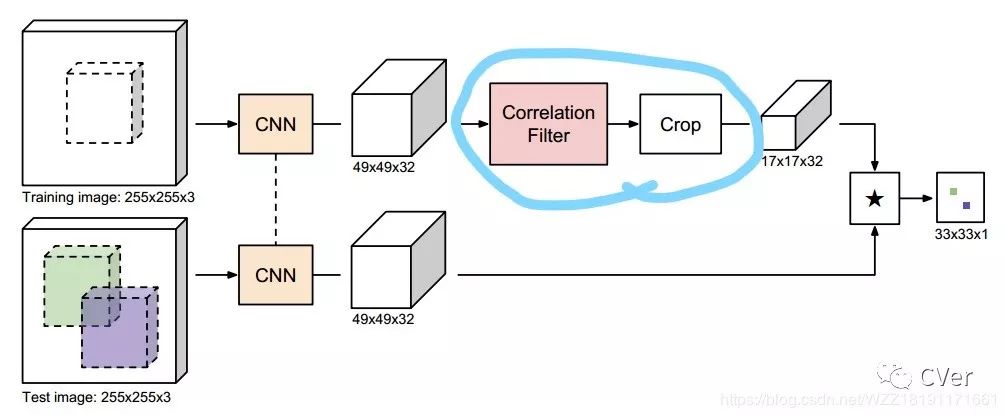
这篇文章整体思路和Siamese-fc算法的思路基本相同,不同之处在于将相关滤波(CF)整合为一个网络层,并将其嵌入到基于孪生网络的框架中,如图中蓝色的区域所示。
3.2 算法实现步骤
如Siamese-fc所述
3.3 算法创新点
创新1-将相关滤波操作变成了一个单一的网络层,并嵌入到网络中;
创新2-调整了网络的架构,比如输入等;
创新3-向我们展示了严格的理论推导过程,值得去学习!!!
4 DSiam
论文:
http://openaccess.thecvf.com/content_ICCV_2017/papers/Guo_Learning_Dynamic_Siamese_ICCV_2017_paper.pdf
代码:https://github.com/tsingqguo/DSiam
4.1 算法整体框图
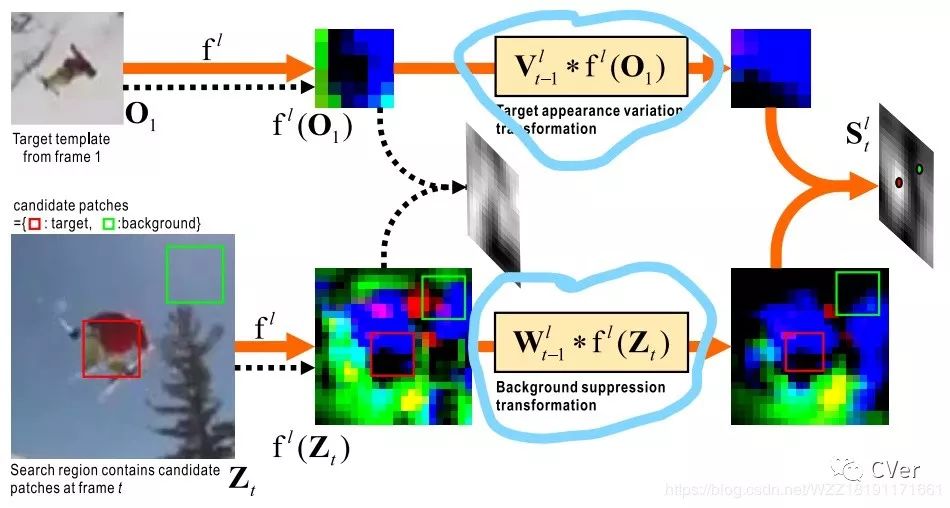
该算法在siamese-fc框架的基础上面添加了目标外观变换转换层和背景抑制变换层来提升网络的判别能力,即增强了模型在线更新的能力。
4.2 算法实现步骤
步骤1:获取ILSVC-2015数据集(又名VID),并进行预处理操作;
步骤2:搭建如上图所示的网络模型,引入了circular convolution (‘CirConv’) and regularized linear regression (‘RLR’)层,进行模型的训练过程;
步骤3:将预训练好的模型分别应用在第一帧和后续帧中,并进行模型在线更新操作,通过相关操作获取对应的得分映射,得到最终的结果。
4.3 算法创新点
创新1-为了提升模型的泛化能力,分别在x和z分支中外观变化转换层和背景抑制转换层;
创新2-尝试着融合基准网络的不同层;
创新3-严格的理论推导,值得学习。
5 SINT++
论文:
http://openaccess.thecvf.com/content_cvpr_2018/papers/Wang_SINT_Robust_Visual_CVPR_2018_paper.pdf
项目:
https://sites.google.com/view/cvpr2018sintplusplus/
Poster:
https://drive.google.com/file/d/1Tn-WkOM3gkCX7Upp5X-YELxUbLAE3o8a/view?usp=sharing
5.1 算法整体框图
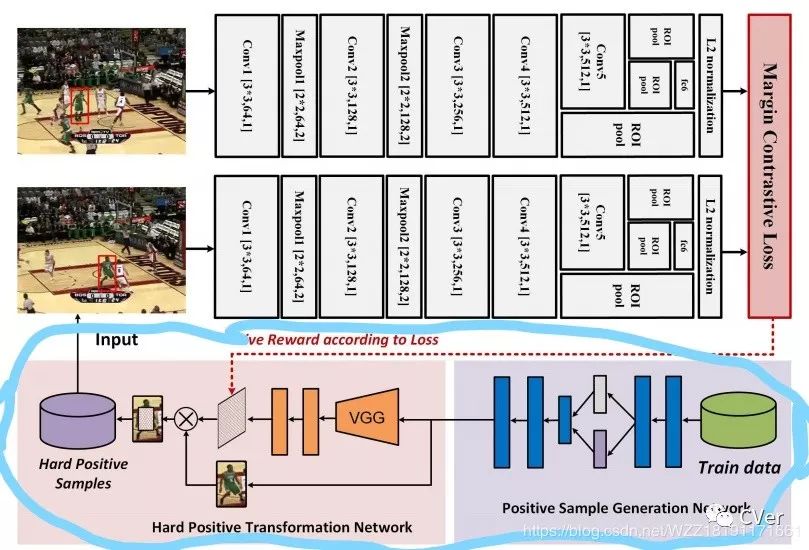
看到名字大家就能猜到这篇文章是SINT算法的改进版,主要的改进部分如图中篮框所示,目的是为了生成多样性的输入正样本块,使用到了AE(AutoEncoder)和GAN网络。
5.2 算法实现步骤
步骤1:分别从VOT-2013、VOT-2014和VOT-2016中收集一部分数据集,进行预处理操作;
步骤2:将获取到的训练集依次输入到正样本块生成网络和正样本块转换网络中去生成多样性的这样本块;
步骤3:将获取的样本块输入到SINT网络中进行训练,获得相应的网络模型;
步骤4:将整个预训练网络分别应用在第一帧和后续帧中,获取最终的结果。
5.3 算法创新点
创新1-使用PSGN网络获得多样性的样本图像,从而提升了算法的鲁棒性;
创新2-使用HPTN网络来处理目标遮挡问题,提升算法的鲁棒性;
创新3-将AE和GAN这种比较热的概念应用到跟踪算法中,即所谓的应用创新。
6 SA-Siam
论文:
http://openaccess.thecvf.com/content_cvpr_2018/papers/He_A_Twofold_Siamese_CVPR_2018_paper.pdf
6.1 算法整体框图
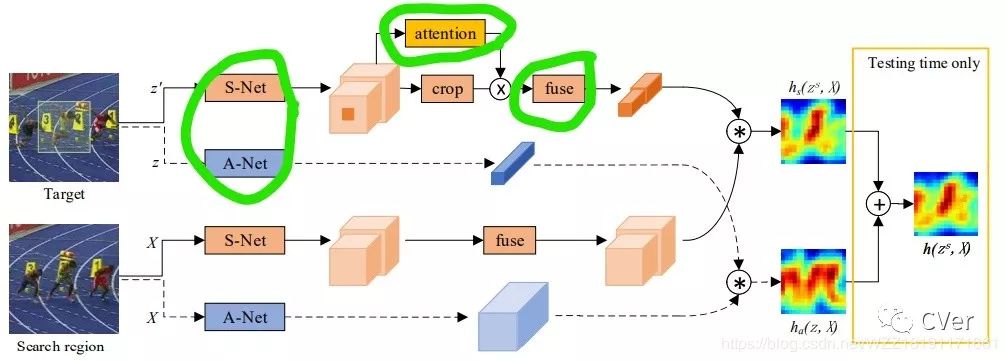
该算法中的主要改动如图中绿框所示,即双网络分别学习不同的特征、在Z分支添加注意力机制和多层特征的融合。
6.2 算法实现步骤
步骤1:获取ILSVRC-2015中的彩色图片作为训练集,进行预处理操作;
步骤2:利用训练集数据分别训练两个不同的网络分支,即A-Net和S-Net,获得相应的网络模型;
步骤3:将整个网络整合在一起并将其应用在视频中获取相应的得分映射图;
6.3 算法创新点
创新1-使用两个网络分别获取网络的语义特征和外观特征;
创新2-对两个分支网络进行单独训练;
创新3-在语义分支网络中使用了注意力机制和特征融合;
7 RASNet
论文:
http://openaccess.thecvf.com/content_cvpr_2018/papers/Wang_Learning_Attentions_Residual_CVPR_2018_paper.pdf
7.1 算法整体框图
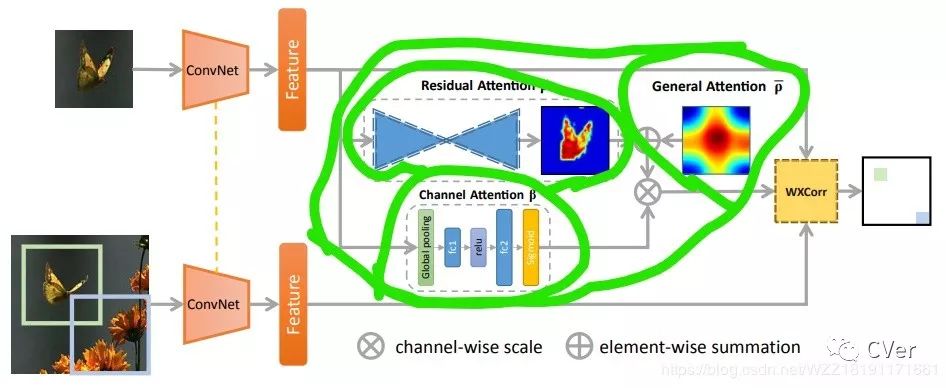
该算法中最大的特色是将Attention机制应用的淋漓尽致,使用到了3个注意力机制,包括残差注意力块,通道注意力块和通用注意力块。当时注意力机制比较火,刚好跟踪领域中应用的人比较少,通过注意力机制可以使得整个网络可以根据目标的变化而自适应的进行调整。不过遗憾的是作者论文说会开源代码却一直没有开源,然而该项目的github strat还高达68,让人很失望。
7.2 算法实现步骤
步骤1:获取ILSVRC15数据集作为训练集,并进行数据预处理操作;
步骤2:搭建如上图所示的网络架构,分别训练获得残差注意力块和通道注意力块;
步骤3:将预训练的注意力模块应用到视频中,进行相关操作获得最终的结果。
7.3 算法创新点
创新1-多个注意力机制使得网络不需要进行在线更新操作,其实更新操作换做注意力机制来做!
创新2-通过残差注意力机制和通道注意力机制在缓解网络过拟合的同时提升网络的判别能力;
创新3-考虑到视频中的时空信息,并通道注意力机制来获得。
8 SiamRPN
论文:
http://openaccess.thecvf.com/content_cvpr_2018/papers/Li_High_Performance_Visual_CVPR_2018_paper.pdf
项目:http://bo-li.info/SiamRPN/
代码(PyTorch):
https://github.com/songdejia/Siamese-RPN-pytorch
代码(TensorFlow):
https://github.com/makalo/Siamese-RPN-tensorflow
8.1 算法整体框图
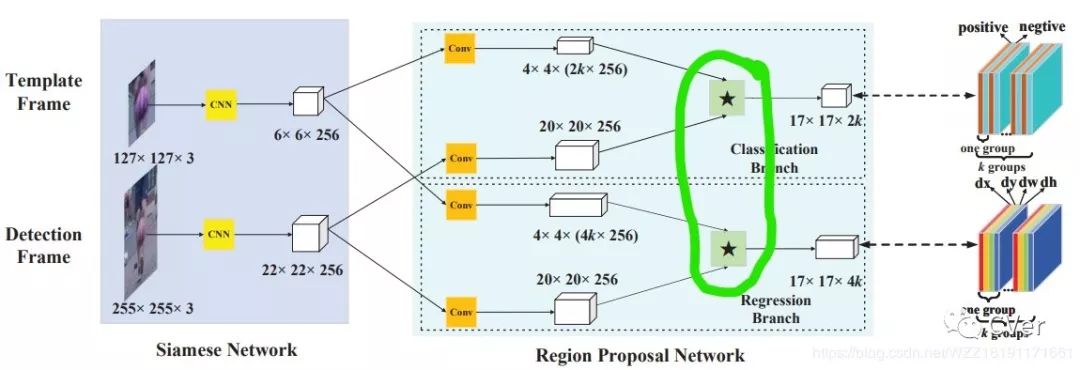
这篇论文做了一个很好的工作,虽然思路简单但是很多人却没有去过尝试,即将目标检测中的RPN模块应用到跟踪任务中来,即如图中绿色区域的分类和回归分支,由于回归分支的存在使得该算法可以去掉原始的尺度金字塔,因此该算法在提升精度的同时达到的提速。将原始的相似度计算问题转化为回归和分类问题。
8.2 算法实现步骤
步骤1:获取VID和 Youtube-BB数据集作为训练数据集,并进行数据预处理;
步骤2:搭建如上图所示的网络框架,同时进行分类分支和回归分支的训练,获得网络模型;
步骤3:应用预训练的模型到视频中通过分类和回归操作初步获得目标;
步骤4:使用NMS等多个tricks进行后处理操作,获得最终的目标。
8.3 算法创新点
创新1-将RPN的思路应用到跟踪领域中,在提速的同时提升了精度;
创新2-引入1x1卷积层来对网络的通道进行升维处理;
创新3-尝试着去使用更大的数据集,光Youtube-BB就几千个视频序列,所以数据也是至关重要的!!
创新4-使得基于孪生网络的跟踪算法的性能有了大幅度的提升,让我们看到了希望!!!
9 SiamFC-tri
论文:
http://openaccess.thecvf.com/content_ECCV_2018/papers/Xingping_Dong_Triplet_Loss_with_ECCV_2018_paper.pdf
代码:
https://github.com/shenjianbing/TripletTracking
9.1 算法整体框图
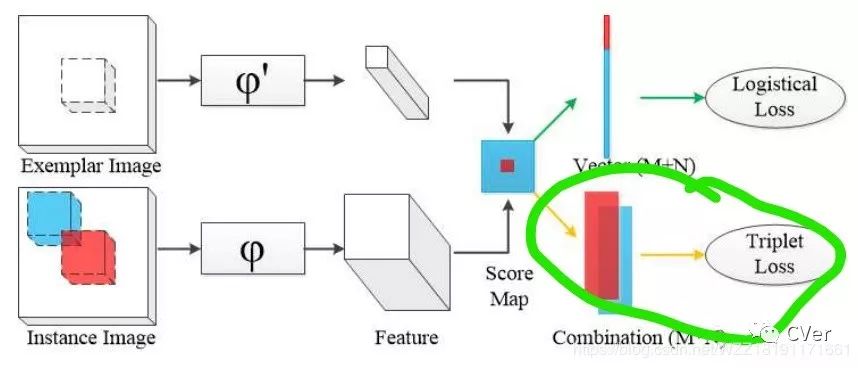
该文的主要工作是将孪生网络领域中使用广泛的triplet loss应用到跟踪问题上来,可以说是一个应用创新。
9.2 算法实现步骤
和siamese-fc基本类似,增加了triplet分支块。
9.3 算法创新点
创新1-将triplet loss应用到孪生网络中,使得网络可以获得更鲁棒的特征表示。
10 StructSiam
论文:
http://openaccess.thecvf.com/content_ECCV_2018/papers/Yunhua_Zhang_Structured_Siamese_Network_ECCV_2018_paper.pdf
代码:
https://github.com/xiaobai1217/StructSiam
10.1 算法整体框图
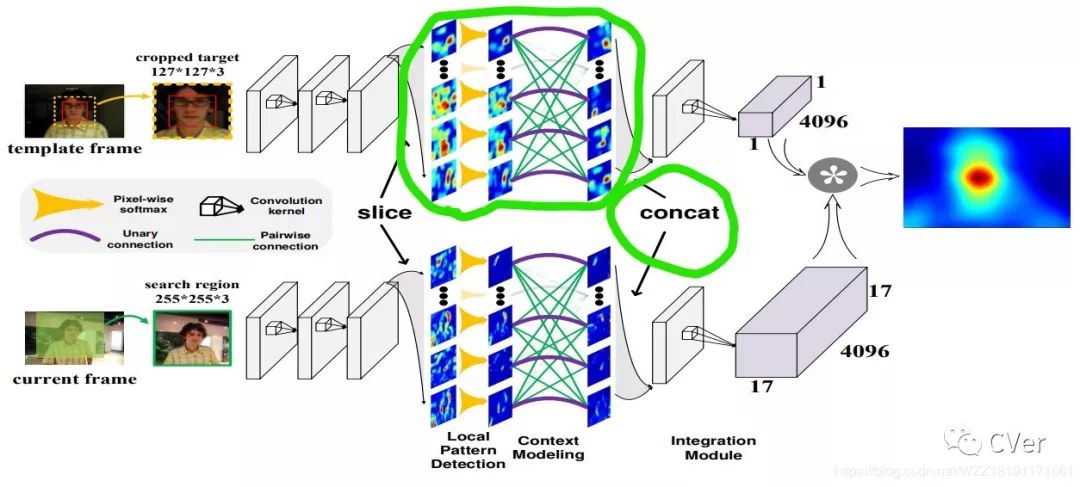
10.2 算法实现步骤
步骤1:获取ILSVRC VID数据集作为训练集,并进行预处理操作;
步骤2:搭建如上图所示的网络框架,需要关注的是局部模式检测层和纹理模型的构建,从而获得相应的模型;
步骤3:使用预训练模型通过相关操作获得一个更准确的得分映射图;
步骤4:进行后续的加窗等后处理操作;
10.3 算法创新点
创新1-使用局部结构学习方法来减缓模型对非刚体运动变化的敏感程度;
创新2-通过多个局部结构块的任意组合可以形成更丰富的纹理;
创新3-将相似性比较问题转化为一个局部特征块的比较问题。
11 DaSiamRPN
论文:
http://openaccess.thecvf.com/content_ECCV_2018/papers/Zheng_Zhu_Distractor-aware_Siamese_Networks_ECCV_2018_paper.pdf
Silde:
https://drive.google.com/file/d/1dsEI2uYHDfELK0CW2xgv7R4QdCs6lwfr/view
代码:
https://github.com/foolwood/DaSiamRPN
11.1 算法整体框图
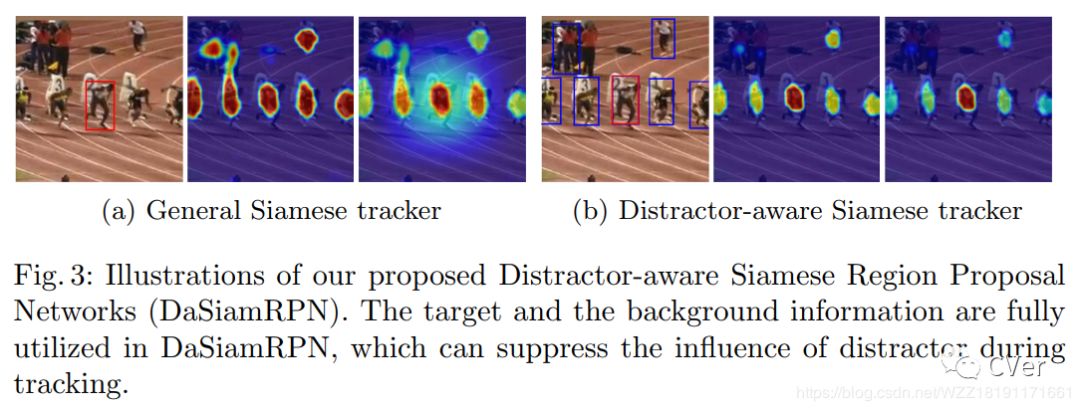
该论文是对SiamRPN论文的初步改进版,主要解决的问题是正负样本块不均衡问题和样本块的丰富性问题,即更关注于输入数据的问题。
11.2 算法实现步骤
基本和siamrpn类似。
11.3 算法创新点
创新1-发现训练正负样本块不均衡问题会影响网络判别相似目标的能力,不如两个穿着黄色衣服的人;
创新2-引入一个高效的采样策略来解决该问题;
创新3-引入一个局部到全局的搜索策略来解决long-term跟踪问题,这个问题正在变得越来越重要!!!
12 DenseSiam
论文:https://arxiv.org/abs/1809.02714
代码:
http://www.votchallenge.net/vot2018/trackers.html
12.1 算法整体框图
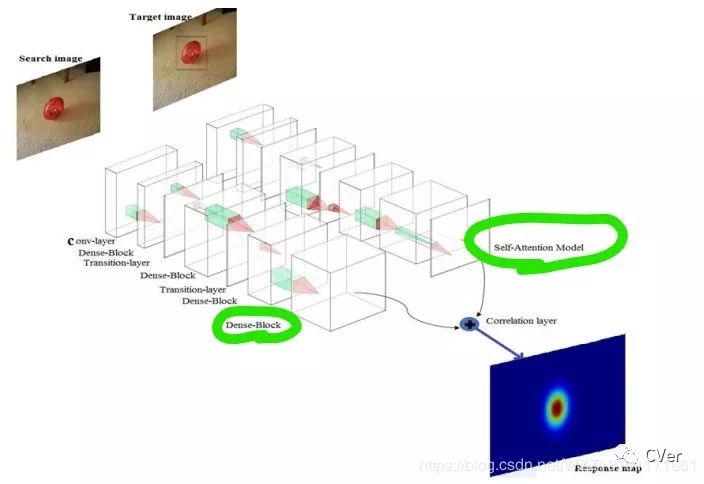
该论文主要工作是将Dense-Block应用到跟踪网络中来,是一个类似于残差块的东西,不过它是密集型链接,该思路借鉴于图像分类,同时在目标图像分支增加了注意力模块提升模型的自适应能力。
12.2 算法实现步骤
步骤1:获取ILSVRC1数据集作为训练数据集,进行数据预处理操作;
步骤2:搭建如上图所示的网络,关注于Dense=Block块的搭建细节和注意力机制的实现细节,获得网络模型;
步骤3:将预训练的模型应用到视频中获取一个好的score_map,获得初步结果;
步骤4:进行加窗等后处理操作获得最终结果。
12.3 算法创新点
创新1-使用Dense-Block来获取更鲁棒的特征表示;
创新2-构建了一个相对于AlexNet网络更深的一个网络;
创新3-添加注意力机制来提升得分相应的效果。
13 MBST
论文:https://arxiv.org/abs/1808.07349
代码:https://github.com/zhenxili96/MBST
13.1 算法实现框图
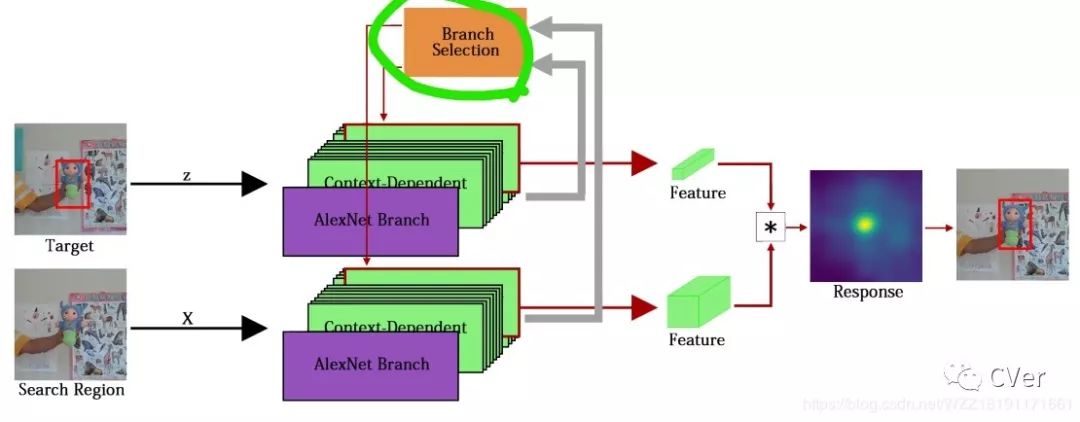
该篇论文主要的思路是同时训练多个孪生网络分支,然后使用分支选择模块选择出最好的分支块计算输出结果。
13.2 算法实现步骤
类似siamese-fc。
13.3 算法创新点
创新1-同时使用多个网络分支获取不同的特征,类似于机器学习中的集成算法;
创新2-使用分支选择器选择出最好分支后再进行输出;
但是该算法的运行速度应该很慢吧!!!
14 Siam-BM
论文:https://arxiv.org/abs/1809.01368
项目:https://77695.github.io/Siam-BM
代码:https://github.com/77695/Siam-BM
14.1 算法整体框图
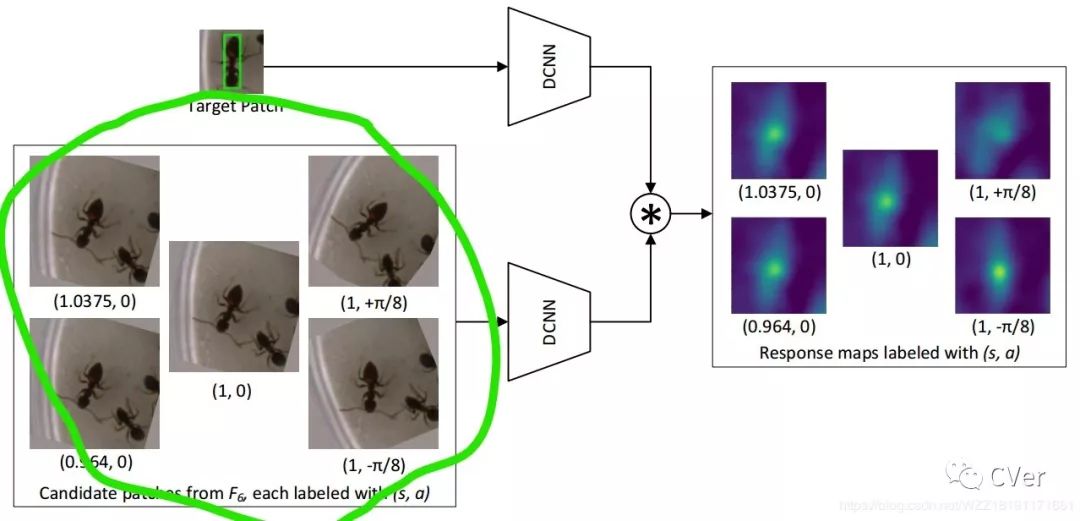
这篇论文的主要思路是通过角度评估模块和空间mask模块分别来解决目标的大尺度旋转和网络区分相似目标的能力。
14.2 算法实现步骤
步骤1:获取ILSVRC-2015数据集中的彩色图片作为训练集,并进行预处理操作;
步骤2:构建上图的网络主要关注角度评估块和mask模块的构造,获得最终的网络模型;
步骤3:将预训练的模型应用到视频中,获取多个可能的得分映射图,选择最好的映射图作为初步结果;
步骤4:进行加窗等后处理操作,返回最终的结果。
14.3 算法创新点
创新1-针对siamese-fc中没有考虑到的角度评估问题提出了解决方案,尽量不影响算法速度;
创新2-根据目标的比例选择出合适的mask来提升算法区分相似目标的能力;
15 C-RPN
论文:https://arxiv.org/abs/1812.06148
15.1 算法整体框图
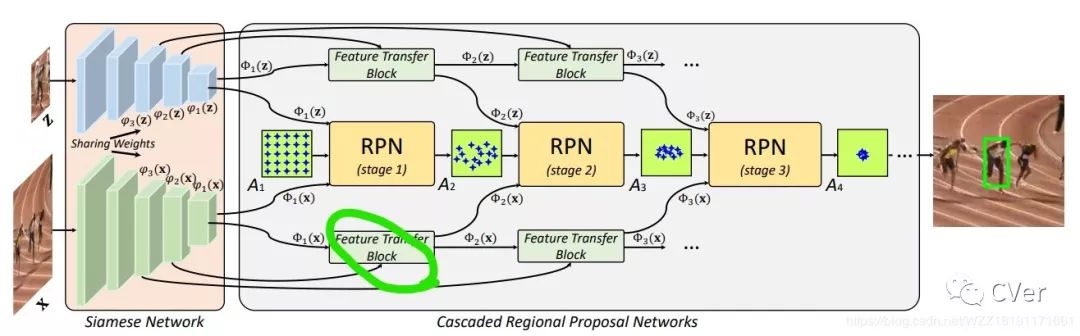
这篇文章的主要思路是为了区分相似的目标作者使用了堆叠SiamRPN的思路可以在网络的前期抑制掉一些比较简单的样本块,在后期的网路中可以获得更加具有代表性的样本块;同时通过多级的回归操作可以使得输出的BB更加准确,会在一定程度上提升算法的精度,其实目标检测中也有类似的算法。
15.2 算法实现步骤
步骤1:同时获取VID和YT-BB数据集作为训练集,并进行预处理操作;
步骤2:搭建如图所示的网络架构,首先训练第一阶段的SiamRPN,训练好之后接着训练下一个阶段的;
步骤3:使用特征转换模块将不同级的SiamRPN级联起来,使用最后的SiamRPN进行分类和回归,输出最终的结果。
15.3 算法创新点
创新1-使用一个简单的级联思路来处理相似样本块和正负样本块不均衡问题;
创新2-使用特征变换块将不同的SiamRPN的信息融合起来;
创新3-使用多级回归获得更准确的BB;
创新4-使用了很大的训练数据集!!!
16 SiamMask
论文:https://arxiv.org/abs/1812.05050
项目:
http://www.robots.ox.ac.uk/~qwang/SiamMask/
代码:
http://www.robots.ox.ac.uk/~qwang/SiamMask/
16.1 算法整体框图
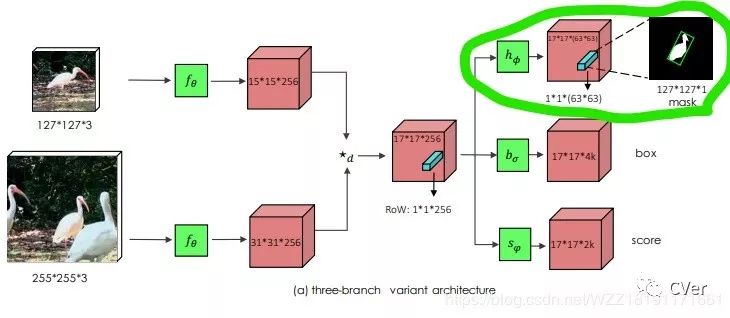
这篇文章的主要思路是在saimese-fc的基础上添加了mask分支,和mask-rcnn有异曲同工之妙,mask分支的存在使用检测的结果更加准确,同时该算法可以获取跟踪目标的BB和Mask,这在现实应用中有很多的用处!!!
16.2 算法实现步骤
步骤1:获取COCO、ImageNet-VID 和YouTube-VOS数据集作为训练数据集,并进行预处理;
步骤2:搭建如图所示的网络框架,关键在于RoW的引入和mask分支的实现,具体见论文,获得最终的模型;
步骤3:将预训练的模型应用在视频中,同时获取待跟踪目标的BB和Mask信息。
16.3 算法创新点
创新1-使用一个网络同时解决了视频目标跟踪和视频目标分割问题;
创新2-通过mask分支来提升跟踪的效果;
创新3-引入RoW模获得准确的mask;
创新4-使用超大的数据集做训练,一般人是不敢用这么大的数据的,跑模型就需要很长时间,设备的差距!!!
17 CIR
论文:https://arxiv.org/abs/1901.01660
代码:
https://gitlab.com/MSRA_NLPR/deeper_wider_siamese_trackers
17.1 算法整体框图
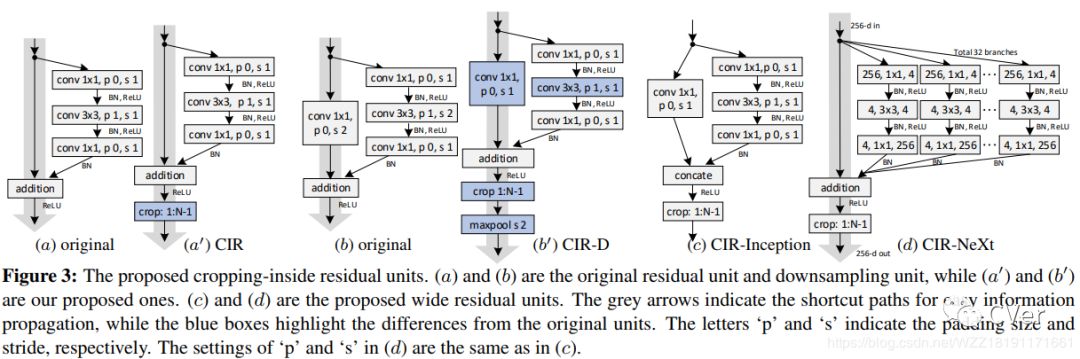
放在后面的都是用来压轴的,这是CVPR2019的一篇oral,仔细去看看你就会发现视觉目标跟踪近几年的oral论文小的可怜,而这篇论文能够成为oral肯定是解决了视觉目标跟踪中的一个大问题吧!没错,如果你是做跟踪的,你可能会发现我前面讲的这些算法的baseline网络都是AlexNet网络!!!很多人好奇干嘛不用ResNet、Inception等深度网络呢?其实跟踪领域中的很多学者们都尝试着用ResNet作为基准网络,但是却发现直接使用深层网络后后跟踪效果反而变差!!!这令人百思不得其解,因此这是孪生网络跟踪器中一个很重要的问题,结果这篇论文给出了我们一个详细的答案,最主要的原因是因为ResNet网络中都会有Padding操作,而这个操作会影响算法的平移不变性,使得网络更加关注图像中心。
17.2 算法实现步骤
步骤1:使用Siamese-fc或者SiamRPN的基本框架,我们仅仅将baseline网络更换成深层网络;
步骤2:针对ResNet中存在的pading问题加入了Crop层,思路即你既然会有影响我就把你去掉哈,思路及其简单去很有效果!
步骤3:作者设计了CIR和CIR-D块,然后通过堆叠这些块构建了深层网络,具体网络请看论文中;
17.3 算法创新点
创新1-深入的去探讨问题,而不是逃避问题,值得学习!!!
创新2-通过简单的Crop操作解决了一个关键的问题;
创新3-通过修改原始ResNet中的块构建出新的块;
创新4-论文中深刻的讨论了网络的输入大小、步长大小和padding操作的影响,并给出了合理的建议,这些建议有利于后续跟踪网络的自行设计!!!
18 SiamRPN++
论文:https://arxiv.org/abs/1812.11703
项目:http://bo-li.info/SiamRPN++/
18.1 算法整体框图
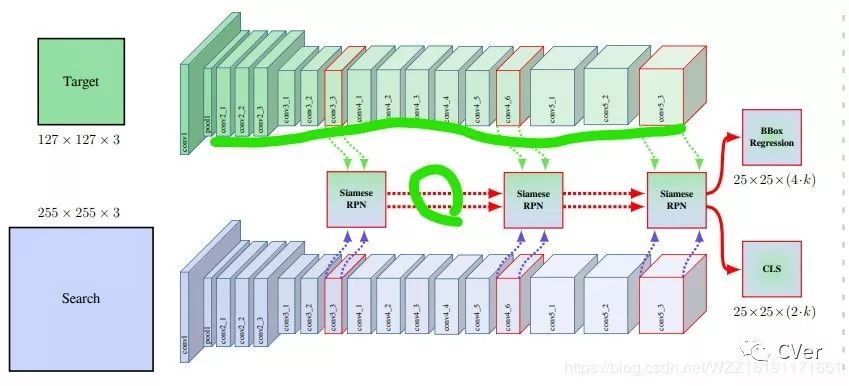
这也是CVPR2019中的一篇oral,而且是视觉目标跟踪的,所以看出跟踪在CVPR2019年有了很大的突破了,这是一个事实,后续会有更多优秀的论文投出,视觉目标跟踪距离真正的场景应用已经越来越近啦!!!这篇论文解决的第一个问题也是深层网络ResNet为何不能应用在孪生网络架构中提升性能!!!但是它提出了不同的方案,即作者发现原始的采样策略存在问题,原始的采样策略使得图像的中心一直有较大的权重,因此作者在中心进行移位,即偏移中心16-64个像素范围内进行均匀采样;而本文解决的另一个问题是相似目标的问题,对应的解决方案是抽取深度网络的多个特征层分别作分类和回归,并进行结果级联,思路和C-RPN很相似!!!
18.2 算法实现步骤
步骤1:获取COCO 、ImageNet DET、 ImageNet VID和 YouTube-BoundingBoxes Dataset数据集来作为跟踪数据集,并进行预处理操作,数据集超级大!!!
步骤2:搭建上图所示的网络,去掉了ResNet中的两个降采样层,并分别对conv3、conv4和conv5的最后一层上面做分类和回归操做,网络的训练顺序也是依次训练;
步骤3:将预训练的网络应用到视频中,获得最终的分类和结果作为初步结果;
步骤4:进行后续的NMS等tricks后处理操作。
18.3 算法创新点
创新1-深刻的分析问题,理解问题的本质,并提出解决方案;
创新2-使用多级级联的思路获取鲁棒的特征表示;
创新3-在多个数据集中都是state-of-art结果;
创新4-使得基于孪生网络的跟踪器真正超越了基于相关滤波器的跟踪算法!!!
好了,本文就先整理到这里,后续继续更新,下面引用王强大佬的一些未来的研究思路给大家。
高效的在线学习算法:进展到目前为止,我的所有实验研究表明。Siamese 网络无法真正意义上抑制背景中的困难样本。离线的学习从本质上无法区分两个长相相似的人或者车。而 CF 相关算法可以通过分析整个环境的上下文关系来进行调整。如果对于提升整个算法的上界(偏学术)的角度考虑,在线学习有必要。如果正常的工程使用,我认为目前的算法只要在相应的场景中进行训练就足够了。
精确输出表达:今年我们的工作提出额外的 mask 输出。可直接扩展的思路为关键点输出(CornerNet / PoseTrack),极点预测(ExtremeNet),甚至 6D pose 跟踪。本质上是通过网络可以预测任何与目标相关的输出。大家可以任意的发散思维。
定制网络架构:其中包含两个子方向,一个是追求精度的去探索究竟什么样的网络架构会有利于当前的跟踪框架的学习。另一个有价值的子方向是如何构建超快速的小网络用于实际工程。工程项目中有时并没有 GPU 的资源供使用,如何提供 “廉价” 的高质量跟踪算法也具有很强的实际意义。当对网络进行裁剪之后,很容易达到 500FPS 的高性能算法来对传统的 KCF 进行真正的替换。
离线训练学习优化:目前的跟踪算法在相似性学习方向还是过于简单,如果去设计更为有效的度量学习方案,应该会有一定的提升。同时我们也并没有很好的掌握网络的训练。当前的训练策略是将网络主干的参数进行固定,先训练 head。然后逐步放开。实际上我们发现,当直接将所有层全部放开一起训练的时候,网络的泛化性能会显著下降。另一个方面,train from scratch 的概念已经在检测领域非常普遍了。跟踪的网络目前我们的经验在跟踪方面并不 work。
更细粒度预测:这一条实际上是上一条的续集,就是专注于 score 分支的预测。现在大家的做法是 > 0.6 IoU 的都当做前景(正样本),但实际上正样本之间还是有较大的差异的。跟踪本质上也是不断预测一个非常细小物体帧间运动的过程,如果一个网络不能很好的分辨细小的差异,他可能并不是一个最优的设计选择。这也是 ATOM 的 IoUNet 主攻的方向。
泛化性能提升:非常推荐自动化所黄凯奇老师组的 GOT-10k 数据集,数据组织的非常棒。黄老师组在 one-shot learning 领域有着深厚的积淀,所以站在这个领域的角度,他们提出了严格分离训练集和测试集的物体类别来验证泛化性能。所以原则上所有 one-shot learning 方向的一些嵌入学习方法都可以移过来用。同时,我觉得 Mask-X-RCNN,segment everything 这个思路可以借鉴。本质上我也不得不承认,基于深度学习的跟踪算法存在泛化性能问题。我们有理由怀疑跟踪是否会在未知的类别上有较好的泛化性能,实际上肯定是会下降。
long-term 跟踪框架:截止到目前为止,虽然 VOT 组委会以及牛津这边的 OxUVA 都有专门的 long-term 的数据集,但 long-term 算法并没有一个较好的统一框架出来。关于这方面的研究似乎有点停滞,今年大连理工的文章非常可惜,我觉得质量非常不错。
参考资料
本文属于王智卓作者的个人总结,方便自己的同时方便大家,主要为大家提供了当前基于孪生网络跟踪算法都做过哪些改进,以及怎么改进进行了总结,方便大家做出更好的工作。
CVer目标跟踪群
扫码添加CVer助手,可申请加入CVer-目标跟踪群。一定要备注:目标跟踪+地点+学校/公司+昵称,不然不给通过

▲长按加群
这么硬的算法汇总,麻烦给我一个好看

▲长按关注我们
麻烦给我一个好看!




