搜狗地图面向SPA和Hybrid的前端工程体系实践

搜狗地图前身是图行天下,成立于 1999 年,是国内第一家互联网地图服务网站,2005 年被搜狐收购后改名为“搜狗地图”。所以这个刚“开始”做的地图产品比大多数人预料的还要老。
讲历史主要不是为了科普,也不是倚老卖老,而是从侧面阐明我们在进行工程化改造时所面临的项目特征:一个有着近 20 年历史包袱、模块结构混乱的“老家伙”(PS:搜狗地图目前的 PC Web 地图可以完美兼容 IE5╮(╯▽╰)╭)。
这样的老项目不可能短时间内切换到全新的技术栈,也不可能大胆地使用一些比较潮的技术和框架,更多的是从策略的角度进行优化。所以我分享内容更加贴近于经验而不是技术本身,相比较其他三位的话题,我所分享内容的方方面面几乎是每个人都熟悉的,我们的工作便是综合这些成熟且稳定的“常识技术”进行工程优化。
前端工程体系并不是一个固有名词,每个团队由于组织、业务以及架构上的不同,对于前端工程体系的理解的也不尽相同。在进入正题之前必须区分的两个概念是:工程化与工程体系。
工程化是一个动词,意指将业务项目进行工程改造,比如合理的模块化、前后分离等等;而工程体系是一个名词,可以理解为工程化的外在表现以及辅助框架,比如构建、测试、部署等等。
搜狗地图前端团队对前端工程体系的理解是:工程体系本质上是一种服务,其服务的对象是技术团队所采用的技术以及组织架构。而架构本身也定位为一种服务,其服务的对象是具体的业务。所以在这一层三角关系之中,业务是决定所有服务的核心和出发点。我们经常将的一句话是:技术不能脱离业务。我也希望这句话能够成为每一个技术开发者和决策者的座右铭。

从业务出发进行工程优化的第一步是提炼业务特征,从而选择合理的技术和组织架构。我们从四个方面提取业务特征:场景、类型、设备以及平台。
以 Web 地图业务为例,从进入页面到展示完整地图的工作流程大致如下:
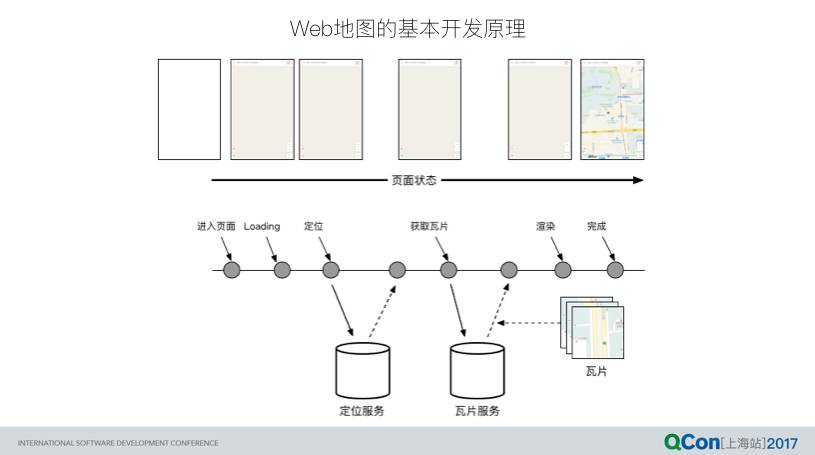
地图可以说是将按需加载发挥到极致的最佳实践业务。大家可以想象一下,以街道为维度将北京市的全貌绘制到浏览器中,浏览器能否承载如此大的工作量?即使抛开技术的局限性,单纯从需求的角度来讲,用户通常只需要查看以当前位置或者搜索位置为中心的有限区域内的地图。所以对于地图来说,第一步也是最重要便是定位:
进入页面后首先请求定位服务,此时页面的状态是 loading,也有人将其称为骨架页面;
定位成功后,用户所在位置的经纬度以及对应比例尺数据决定后续瓦片数据的获取;
瓦片数据请求成功后,浏览器端 JS 代码将其排列组合最终展示出完整的局部地图。
精确定位是非常复杂的功能,感兴趣的可以自行查阅相关资料。
除了 Web 地图以外,搜狗地图前端业务的另一种主要形式是 Hybrid。将这两种业务形式进行归纳总结,提取的业务特征大致如下:
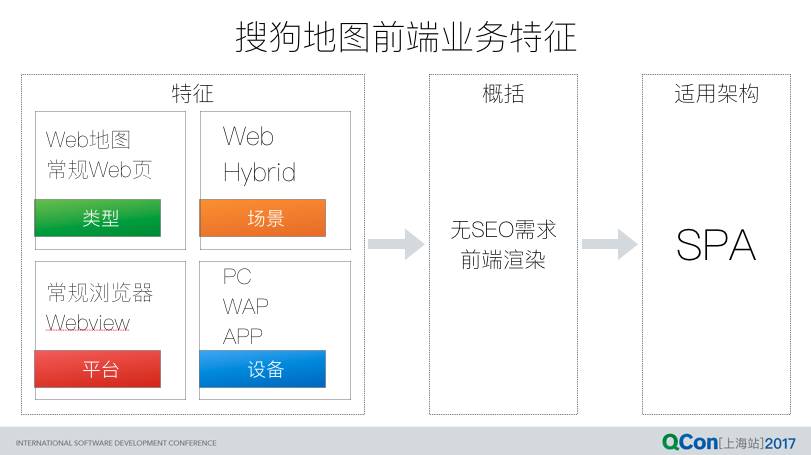
业务特征决定技术架构,最终提炼出适用于搜狗地图前端业务的架构类型便是目前较流行的单页应用—SPA。
不依赖与服务端渲染的 SPA 不论是从架构层面,还是从开发和部署层面都带来很多便利。HTML 文档可以作为一种静态资源与 js、css 等一同部署,然而从缓存处理方面,需要单独处理 HTML 这种“特殊”的静态资源。它的特殊之处便在于:HTML 是所有其他静态资源的入口。
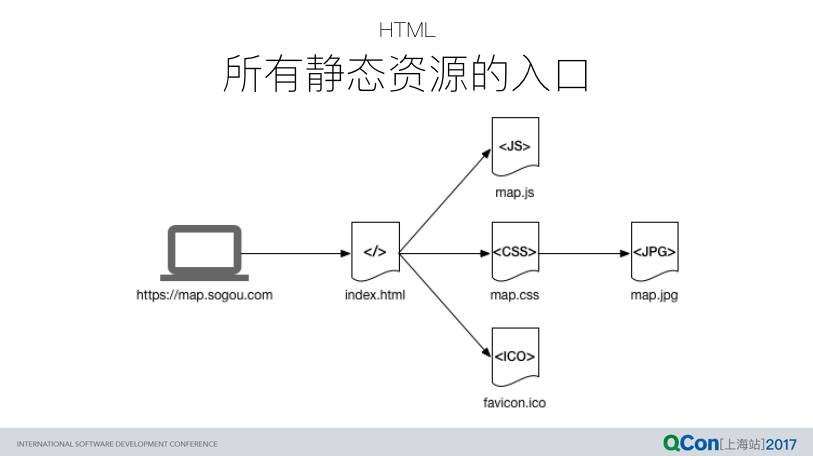
HTML 的特殊性决定它不能使用 http 强制缓存策略,只适用于协商缓存:
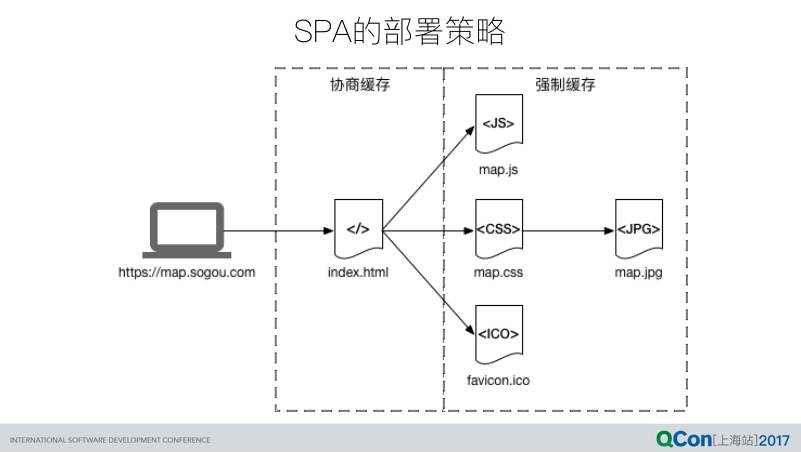
这样可以保证各类型资源实时性的同时,最大化利用 http 缓存,对于常规的 SPA 项目(比如 Web 地图)是一种比较普适的方案。然而协商缓存必须要求一次真实有效的 http 请求以便服务器进行缓存有效性判定,离线场景下并不适用。而离线是 Hybrid 应用较普遍的场景之一,后续会提到如何在协商缓存理念基础上的优化策略。
搜狗地图 Hybrid 架构经历了三个阶段,最初始的方案是:Web 多页项目 + 多 Webview。也就是说,每个 Webview 承载一个 Web 页面,页面之间的切换就是 Webview 之间的切换,页面之间的通信便是 Webview 间的通信。
这种架构一个最大的问题是:各页面之间的通信非常不顺畅,而且影响用户体验。如下所示的是一个非常普遍的场景:
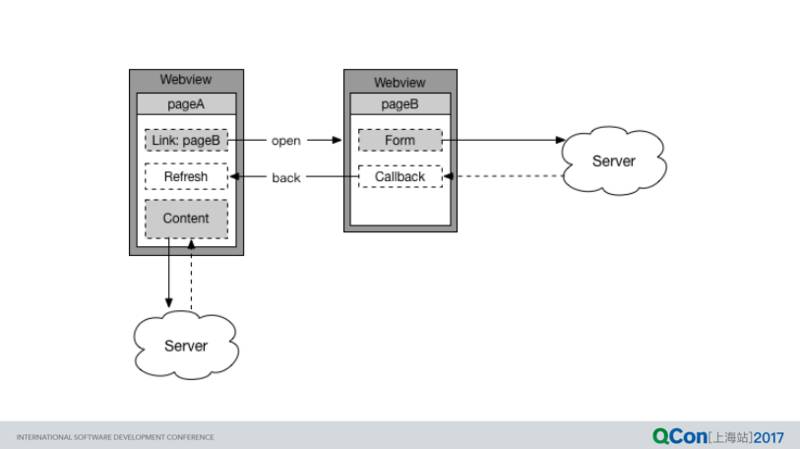
pageA 包括两个部分:pageB 的入口、由服务端数据驱动的 Content;
pageA 打开 pageB 的方式是新建一个 Webview;
pageB 中的表单提交数据到服务端,成功后返回 pageA;
pageA 需要获取经 pageB 修改后的服务端数据,最简单粗暴也是最省事的办法就是:刷新。
这种方案存在的致命缺陷在于,pageA 并不知道 pageB 是否提交了表单 [注],所以返回 pageA 后不论 pageB 操作与否都要进行刷新。不论是从节省流量还是用户体验的角度来讲都是负面的。
注:pageA 其实有办法获取 pageB 是否进行了提交。一种方案是通过 localstorage 的 storage 事件,然而兼容性非常不理想;另一种方案是通过 native 提供特定的接口,这种方案虽然兼容性好但是需要客户端的开发工作。
在上述问题的基础上进行优化的第一步,是结合 SPA 架构 和 Webview 自身的缓存机制。
Webview 的缓存机制包括以下几种:
LOAD_CACHE_ONLY- 不使用网络,只读取本地缓存数据LOAD_DEFAULT- 根据 cache-control 决定是否从网络上取数据LOAD_NO_CACHE- 不使用缓存,只从网络获取数据LOAD_CACHE_ELSE_NETWORK- 只要本地有,无论是否过期,或者 no-cache,都使用缓存中的数据
其中 LOAD_DEFAULT 是最接近常规浏览器的缓存机制,在这种模式下,结合上文提到的 SPA 缓存策略,与常规的 Web 页面并无二致。然而 App 并不是常规的浏览器,其使用场景(手机)的特殊性要求我们在一些特殊的方面进行优化,比如缓存清理和离线使用。

其中第一条是历史原因,公司运维层面将 CDN 缓存有效期固定位 1 小时,迁移优化成本较高。http 缓存过期后并不会自动清理,之所以常规浏览器不用顾忌这个问题是由于 PC 设备储存空间大,并且可以使用电脑管家之类的优化软件手动清理。虽然手机等移动设备的储存空间也不断加大,但仍然有相当一部分设备的储存空间十分感人(我自己用的 16G 的 iphone 7P,感同身受╮(╯▽╰)╭)。
如果放任过期的 http 缓存不管便会造成 app 占用的空间越来越大,极端的用户可能一气之下就把 app 卸载了,我自己便曾经在阴阳师和狂野飙车之间做过抉择,最终卸载了阴阳师╮(╯▽╰)╭。
所以这并不是最终合理的方案,但是这次探索给了进一步的优化工作灵感:是不是可以吸取协商缓存的理念,同时结合 Webview 自身的缓存机制呢?以此为方向便产生了目前采用的 协商缓存理念的 Hybrid 模板更新策略。
模板是什么?前文提到了模板并不是静态的离线包,而是具备动态数据解析功能的逻辑模块。这个理念来源于 SSR(服务端渲染)中的 html 模板,这应该是前端工程师们再熟悉不过的名词了,前几年尚未实现前后端分离开发时,html 模板可以说是折磨前端工程师的主力之一。
模板以压缩包的形式传输,进入 App 之后如果处于 Wifi 环境则会自动检查并下载最新版本的模板包。并且在 App 进程运行以及挂起期间不会进行多次检查。
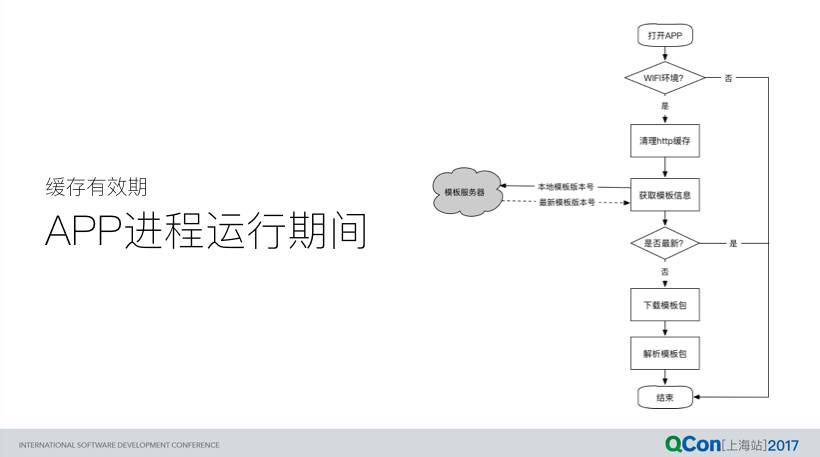
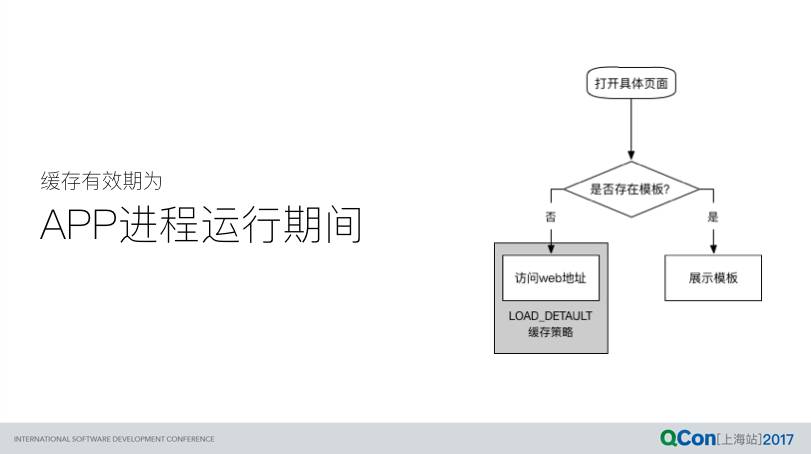
具体每个模板包对应的页面,进入之后并不会检查模板包的版本,只要本地存在便展示,否则 fallback 展示线上的 Web URL。这种策略是为了尽可能减少具体业务页面的解析时间。作为 fallback 的 Web 地址采用 WebView 的 LOAD_DEFAULT 缓存策略,有效期为 CDN 缓存(1 小时)。另外,如果用户通过任务管理器手动杀死了 App 进程,下次进入 App 之后首先会清理之前残留的 http 缓存文件。
综上,搜狗地图的前端工程体系简易架构大致如下:
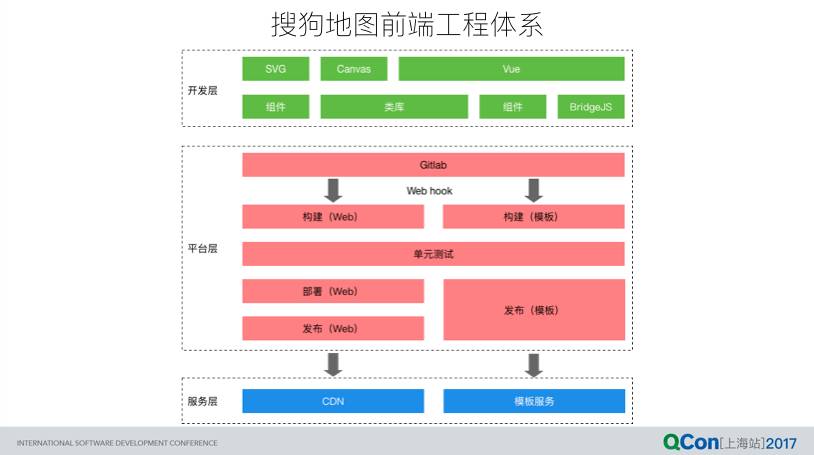
与常规 Web 项目的不同点在于,地图项目大量使用 SVG 和 Canvas,组件库包括两者相关的组件。另外,负责与 native 通信的 bridageJS 是 Hybrid 应用所特有的。平台层由 Gitlab 把关,Webhook 触发自动构建、测试和部署。另外,模板包可以由开发人员直接部署,不需要经过公司运维,这也是与常规 Web 项目相比的优势之一。
由于每个模板包都会对应一个 fallback 的 Web 地址,所以在构建流程中需要针对两种场景分别构建。模板文件对于 App 来说其实就是本地文件,所以模板文件中对于其他文件的引用统一使用相对地址,并且由于模板本身就是增量的,无需在静态文件名中加入 hash 指纹。构建工具有 Node.js 为底层平台,使用特殊的环境变量结合 EJS 引擎区分构建,如下:

至此便是搜狗地图目前针对 SPA 和 Hybrid 项目的整体工程体系,当然这并不是终点,甚至称不上是最佳实践。此次分享的目标也并不是剖析我们团队的工程实践,更多的是将这一路走来的探索历程分享给大家,希望能够给同样面临老项目改造的团队一些启发。
最后简单提一个优化的案例。模板也是分模块的,不能将所有的业务集中在一个模板中,否则任何一个微小的修改都会造成整个模板包的更新,而且随着业务的不断扩展,模板包的体积越来越大,下载和解析时间最终会超过用户的心理承受界限。所以我们在模板颗粒度划分方面做了一些优化:将逻辑无耦合的业务定义为一个模板包,比如用户中心与详情页,两者除了登录信息共享以外,几乎不存在逻辑上的耦合,所以将两者划分为两个模板。在此基础上将共用的类库文件提取出来单独作为一个模板。
如果让我给这套工程体系打分可能只达到了 60 分的及格线,但是对于一个“历史悠久”的团队而言,这仍然是非常可观的“一大步”。后续仍然需要不断进行优化和迭代,比如会后与支付宝的同学一起探讨的更新率问题。技术的道路远没有尽头,回到一开始的那句话:技术永远服务于业务。总结这次的 QCon 之行,我看到了优秀的技术从业者们以实际业务为中心的探索和务实精神,收获的不仅仅是技术的增长,更重要的是扩宽了眼界。
最后,感谢主办方 InfoQ 的邀请,完整 PPT 下载:
http://pstatic.geekbang.org/pdf/59e70891128ee.pdf?e=1508760364&token=eHNJKRTldoRsUX0uCP9M3icEhpbyh3VF9Nrk5UPM:1mRPXq7EOTBw4vlLA_ufMgHkSsM=
「前端之巅」是 InfoQ 旗下关注前端技术的垂直社群,加入前端之巅学习群请关注「前端之巅」公众号后回复“加群”。投稿请发邮件到 editors@cn.infoq.com,注明“前端之巅投稿”。

活动推荐:
AI 之火有目共睹,不谈 AI 都快不好意思出门了。那么,目前到底都有哪些 AI 落地案例呢?机器学习、深度学习、NLP、图像识别等技术又该如何用来解决业务问题?AICon2018 全球人工智能技术大会上,我们集齐了国内外可供参考的最新 AI 落地案例和技术探索,或许可以给你一些启发,点击“阅读原文”了解详情!






