一次性付费进群,长期免费索取教程,没有付费教程。
教程列表见微信公众号底部菜单
进微信群回复公众号:微信群;QQ群:460500587
![]()
微信公众号:计算机与网络安全
ID:Computer-network
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等。
Scrapy是一个为爬取网站数据、提取结构性数据而设计的应用程序框架,它可以应用在广泛领域:Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
尽管Scrapy原本是设计用来屏幕抓取(更精确的说,是网络抓取),但它也可以用来访问API来提取数据。
在使用Scrapy爬取数据前需要先了解Scrapy的选择器。网络爬虫原理就是获取网页返回,然后提取所需的内容。获取网页返回很简单,重点就在提取内容上。简单网页用re模块提取可以将就,复杂一点的提取内容就麻烦了。
Scrapy提取数据有自己的一套机制。它们被称作选择器(seletors),通过特定的XPath或者CSS表达式来“选择”HTML文件中的某个部分。
XPath是一门用来在XML文件中选择节点的语言,也可以用在HTML上。CSS是一门将HTML文档样式化的语言。选择器由它定义,并与特定的HTML元素的样式相关联。
Scrapy的选择器构建于lxml库之上,这意味着它们在速度和解析准确性上非常相似,所以看您喜欢哪种选择器就使用哪种吧,它们从效率上看完全没有区别。
1、XPath选择器
XPath是一门在XML文档中查找信息的语言。XPath可用来在XML文档中对元素和属性进行遍历。XPath含有超过100个内建的函数。这些函数用于字符串值、数值、日期和时间比较、节点和QName处理、序列处理、逻辑值等。
在XPath中,有7种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)。XML文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
做个简单的XML文件,以便演示。执行命令:
cd
mkdir scrapy
cd code/scrapy
mkdir -pv scrapy/seletors
cd scrapy/seletors
vi superHero.xml
在这里创建了scrapy的工作目录scrapyProject,并在该目录下创建了选择器的工作目录seletors。在该目录下创建选择器的演示文件superHero.xml。superHero.xml的代码如下:
1 <superhero>
2 <class>
3 <name lang="en">Tony Stark </name>
4 <alias>Iron Man </alias>
5 <sex>male </sex>
6 <birthday>1969 </birthday>
7 <age>47 </age>
8 </class>
9 <class>
10 <name lang="en">Peter Benjamin Parker </name>
11 <alias>Spider Man </alias>
12 <sex>male </sex>
13 <birthday>unknow </birthday>
14 <age>unknown </age>
15 </class>
16 <class>
17 <name lang="en">Steven Rogers </name>
18 <alias>Captain America </alias>
19 <sex>male </sex>
20 <birthday>19200704 </birthday>
21 <age>96 </age>
22 </class>
23 </superhero>
很简单的一个XML文件,在浏览器中打开这个文件,如图1所示。
![]()
后面的选择器都以该文件为示例。在superHero.xml中,<superhero>是文档节点,<alias>Iron Man</alias>是元素节点,lang="en"是属性节点。
从节点的关系来看,第一个Class节点是name、alias、sex、birthday、age节点的父节点(Parent)。反过来说,name、alias、sex、birthday、age节点是第一个Class节点的子节点(Childer)。name、alias、sex、birthday、age节点之间互为同胞节点(sibling)。这只是个最简单的例子,如果节点的“深度”足够,还会有先辈节点(Ancestor)和后代节点(Descendant)。
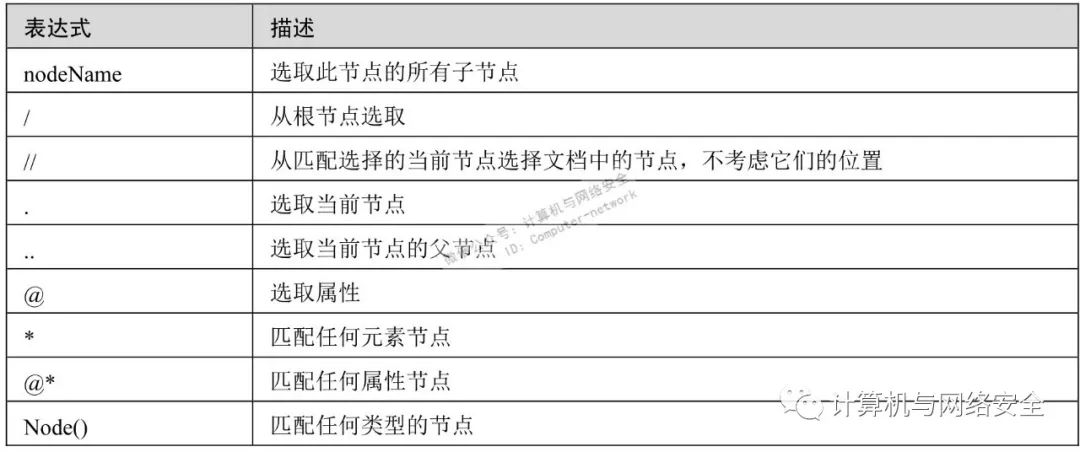
XPath使用路径表达式在XML文档中选取节点。表1中列出了最常用的路径表达式。
![]()
下面用XPath选择器来“采集”XML文件中所需的内容,先做好准备工作。执行命令:
python3
from scrapy.selector import Selector
with open('./superHero.xml','r') as fp:
body=fp.read()
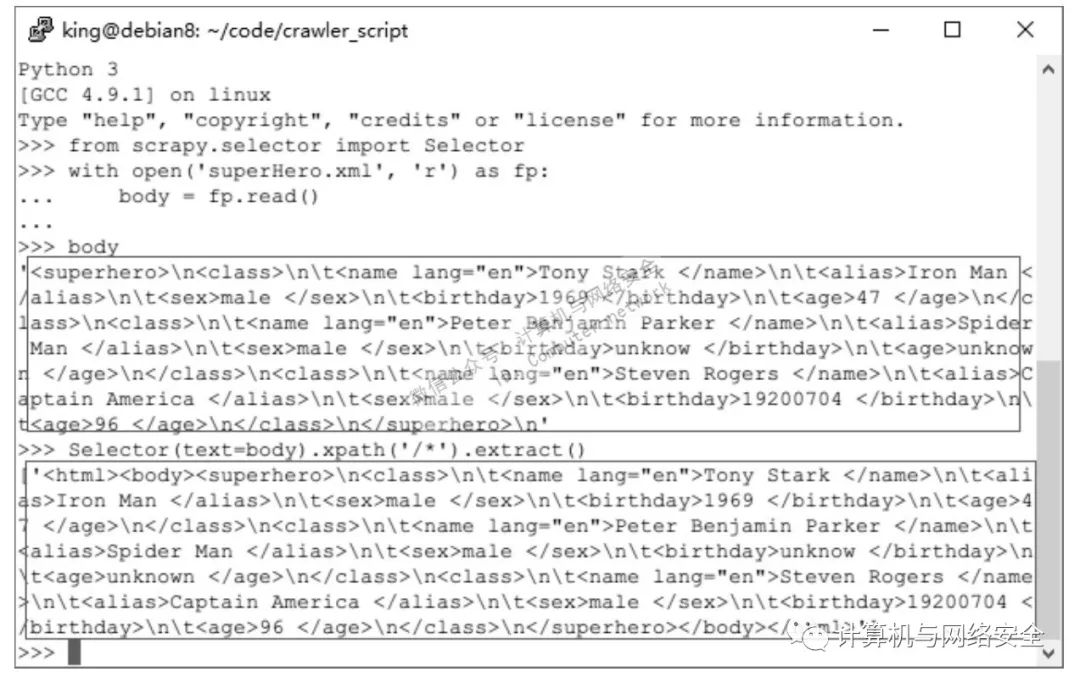
Selector(text=body).xpath('/*').extract()
首先启动Python,导入scrapy.selector模块中的Selector,打开superHero.xml文件,并将其内容写入到body变量中,最后使用XPath选择器显示superHero.xml文件中的所有内容。
执行结果如图2所示。
![]()
选择器在从根节点选择所有节点时得到的数据和直接从文件中读取的数据有点不一样。
因为示例文件并不是一个标准的html文件,所以在选择器中被自动添加了<html>和<body>标签。
也就是说在选择器看来,示例文件的根节点并不是<superhero>,而是<html>。
现在来看如何使用XPath选择器“收集”数据,如图3所示。
![]()
以上是XPath中最常用的几个方法,非常简单。
“隐藏”得不太深的数据直接用XPath选择器挑选数据就可以了。
复杂一点的,用配套选择就能很方便地搞定。
只要有点耐心,再复杂的数据也可以分离出来。
2、CSS选择器
CSS
(层叠样式表,Cascading Style Sheets)规则由两个主要的部分构成,选择器以及一条或多条声明。
selector {declaration1;declaration2;…declarationN}
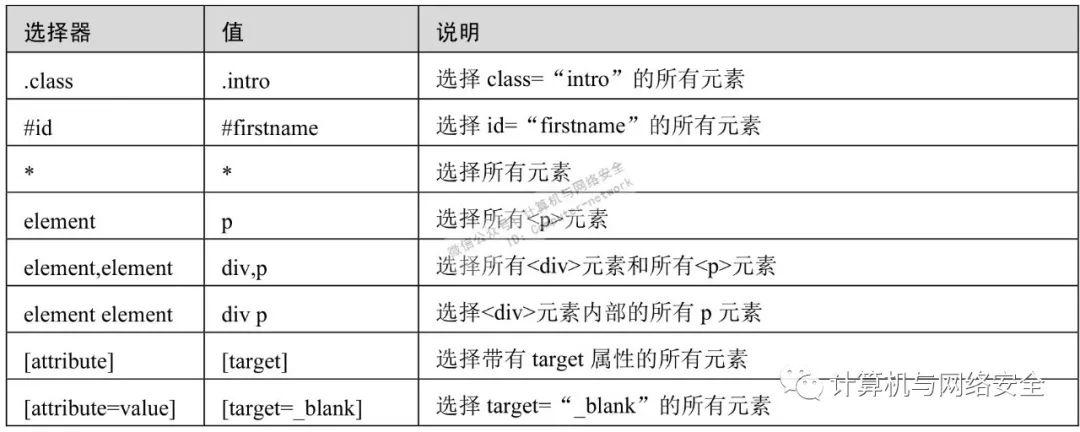
下面介绍一下与爬虫密切相关的选择器,表2中列出了CSS经常使用的几个选择器。
![]()
与XPath选择器相比较,CSS选择器稍微复杂一点,但其强大的功能弥补了这点缺陷。
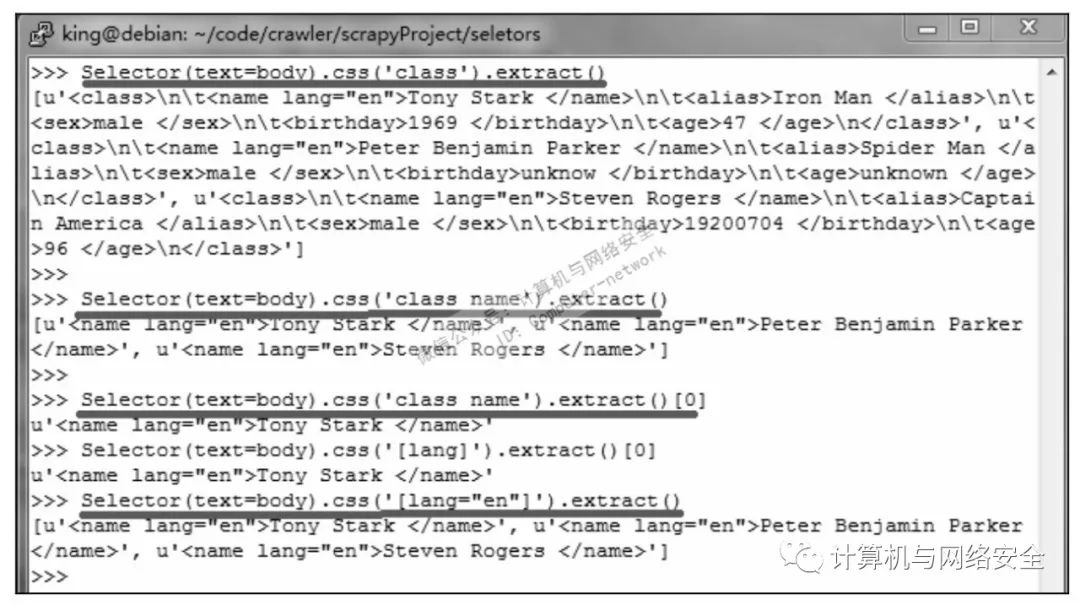
下面就来试验一下CSS选择器如何收集数据,如图4所示。
![]()
因为CSS选择器和XPath选择器都可以嵌套使用,所以它们可以互相嵌套,这样一来收集数据会更加方便。
微信公众号:计算机与网络安全
ID:Computer-network