《软件方法(下)》第8章 分析类图-类关系测试题
第8章 分析 之 分析类图
墙上挂了根长藤,长藤上面挂铜铃
《长藤挂铜铃》;词:元庸,曲:梅翁,唱:逸敏
8.1 步骤3-1 识别类和属性
在业务建模和需求工作流,我们的思考焦点一直在待开发系统的边界外。现在,思考的焦点从外观过渡到内部机理。
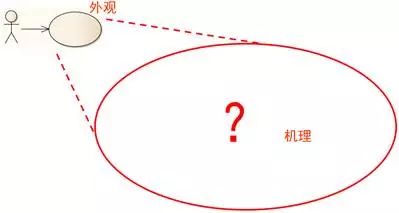
图8-1 思考系统的内部机理
系统如何构成,仅仅是软件开发组织考虑的事情,涉众不需要在意——只要系统能满足需求规约里阐明的各种需求。系统为了满足这些需求,必须封装一定的知识。如何组织这些知识,才能让建模人员的大脑更好地把握系统的复杂性,是分析和设计的关键。
8.1.1 核心域和非核心域
一个软件系统封装了若干领域的知识,其中一个领域的知识代表了系统的核心竞争力,是系统和其他系统区分的关键所在。这个领域称为"核心域",其他领域称为"非核心域"。更通俗的说法是"业务"和"技术",但使用"核心域"和"非核心域"更严谨。[1]核心域不一定是物流、医疗、金融等非计算机领域,也可以是计算机和软件领域。图8-2展示了不同系统的核心域和非核心域概念:
系统 |
核心域概念 |
非核心域概念 |
文档处理器(如Microsoft Word) |
文档、页、行、字…… |
CStringArray、CFileDialog、MSXML…… |
电子商务网站(如淘宝网) |
商品、订单、会员…… |
</div>、ActionForm、SessionFactory…… |
图8-2 不同系统的核心域、非核心域概念
随着信息化的深入,组织内部封装在软件(即业务实体)中的领域逻辑比例越来越大,深度越来越深,组织之间的竞争越来越依赖于软件的竞争。市场的激烈竞争,又使得组织越来越聚焦于一个领域,为组织提供软件的软件组织也越来越专注于一个领域,甚至逐渐成为组织里的一个部门。将来,独立的软件组织也许将不复存在,或者说,所有组织都是软件组织。从当前的趋势看,软件的运行形态越来越"互联网化",说"所有组织都是互联网组织"也可以。成熟的"互联网公司"都有自己清晰的领域定位,京东是商场,新浪是媒体……
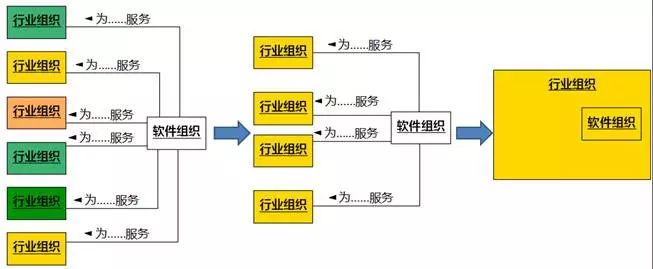
图8-3 软件组织位置的变化
以2015-2017年我上门提供服务的组织为例,名字带"软件"、"科技"、"网络"等词语的组织比例已经不到一半,更多的是其他行业组织,例如“***汽车技术有限公司”、“航天**集团第*研究院”、“**市规划国土房产信息中心”、 “**飞机设计研究院”、“**银行软件中心”……。
如果软件在组织中的分量不重,关键的领域逻辑还是封装在人脑中,使用一些通用软件就足够了,例如Microsoft Office、QQ、微博、微信。Microsoft Office没有为某个行业而定制,协和医院和北京四中买到的Microsoft Office是一样的。如果我们要的不仅仅是"书写文档"的软件,而是要"编写采购计划"的软件,也就是说,软件中要封装"采购计划"的领域逻辑,这就不是Microsoft Office能胜任的。[2]这个时候,组织需要的是封装了"采购计划"相关逻辑的"采购业务系统"。
每个组织都有自己独特的"文化"。组织的员工不是标准化的,而是要适合组织的"文化",这样才有办法在竞争中获胜。引进的软件系统和员工一样,也要体现组织的"文化",所以不同组织可能还需要不同特色的"采购业务系统"。
综上所述,市场上需要花样繁多的各种系统,这是竞争和分工导致的必然结果。很多系统之间可能在关键的点上有微妙差别,但许多内在机制是类似的。如果能高效复用这些机制,软件组织就能以较低成本变出各种系统来满足市场。
8.1.2 基于核心域的复用
"复用"一词实际上没有听起来的那么阳春白雪,设计的目的就是复用。如图8-4所示,软件的开发是动态变化的过程,从第一个功能,到第二个功能……第一个版本,到第二个版本……第一个系统,到第二个系统……。组织发展到一定程度,甚至要维护许多个系统组成的系统家族。设计的好坏之分在于,让已有系统满足新需求时,付出的代价有多大。换句话说,就是以前做的工作可以复用的比例有多高。
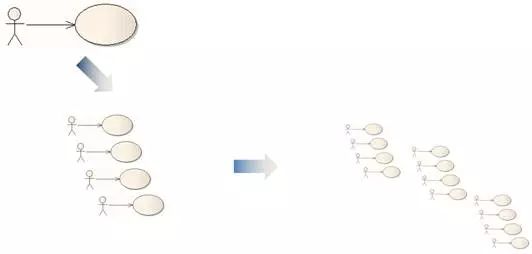
图8-4 功能→功能集→系统族
有一些"敏捷"论调宣传"开发系统不需要设计,只需要把它分解成小块,一块一块地做就可以了"。按这样的说法,盖大楼也很简单,不需要画图纸,一块砖一块砖往上垒就是。可惜,高下之分就在于:有的团队稳稳地把楼盖上去了,而有的团队在盖第二层时,第一层出问题需要维修,好不容易弄好了,盖第三层时,下面两层又出问题……虽然最终有可能也把楼盖起来,但这样的水平能竞争过别人吗?
软件开发方法的发展史,就是不断提升复用级别的历史。比起很多年以前,现在的软件开发在图形界面、网络协议、数据存取等基础设施领域的复用上,已经达到了相当的高度。例如要做图8-5这样的一个点名抽奖工具,需要人工编辑的介质(即所谓"源代码")只需要几十行字符,其它部分的逻辑已经由基础设施封装了。
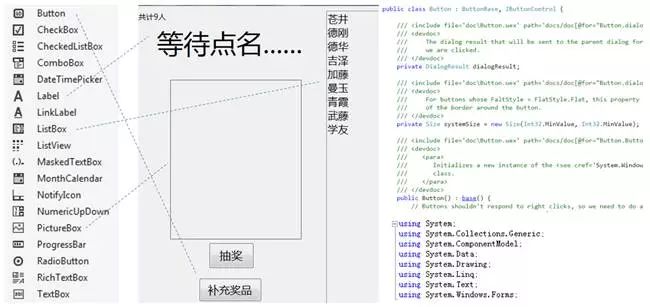
图8-5 基础设施的复用已经到了一定高度
遗憾的是,目前大多数软件组织的复用仅停留在基础设施领域的复用,即使有自己的"内部开发平台",也仅是根据自己所开发系统的需要对基础设施作进一步封装。特别是"互联网公司",其津津乐道的"架构"往往就是基础设施的架构。
在一些软件开发大会常可以看到这样的场景:某电子商务网站的架构师上台讲了一通,接着某视频网站的架构师上台也讲了一通,咦,两个演讲内容如此相似?原来,他们讲的都是自己系统中非核心域的知识,根本不涉及核心域的知识。究其原因也许并非不为,而是不能——开发人员对自己所开发系统的核心域研究太浅。许多“网红程序员”在网上谈论的内容大多是某种语言或框架的新特性,少有探讨他当前所开发系统的复杂领域逻辑,也是同样的原因:并非不为,而是不能。
非核心域(也就是别人的核心域)的优势仅仅是暂时的,竞争对手也能通过同样的渠道获得。A采用了某种新的工具,短时间内获得了对B的竞争优势,但随后B也获得了该工具,A的竞争优势很快就消失了,利润流进了工具厂商的口袋。非核心域的改进是必要的,但不充分,还要在核心域上深入挖掘,让竞争对手无法轻易从第三方获得。对于软件组织来说,在核心域上深入挖掘,达到基于核心域的复用,是获得和保持竞争力的根本手段。
对软件开发组织里的个人来说,专注于某个核心域也越来越重要。过去说“我是一名Java程序员,我可以用Java来开发物流系统、保险系统、医院系统”,现在要说“我是一名物流领域的开发人员,擅长用Java实现”。
要做到这一点基于核心域的复用,有一定的难度,因为能带来利润的系统,往往被迫关注的领域比较多,"负载"比较高。
开发一个基础设施领域的系统,例如操作系统,只需要关注计算机的资源,不需要关注顾客、订单、病历等具体某个应用领域的概念。按道理,开发应用系统也应该可以不管基础设施,但遗憾的是,当前现实中大多数情况下还是要管。例如,开发一个"棒医生在线"网站,不仅仅需要具备医疗卫生领域知识,还需要懂Linux,懂MySQL,懂Apache……。
另外,基础设施领域有大量已出版教材和先行例子,高校也为计算机和软件相关专业学生开设了相应课程(Linus Torvalds就是在大学教材中MINIX案例的激发下编写了Linux)。这样,开发人员的大脑比较容易把握基础设施领域的复杂性,对显式建模的要求没有那么高。在2017年2月1日用"操作系统"为关键字搜索当当网(dangdang.com),得到10461种图书。其中一步步教读者如何自己编写操作系统的书也不在少数。
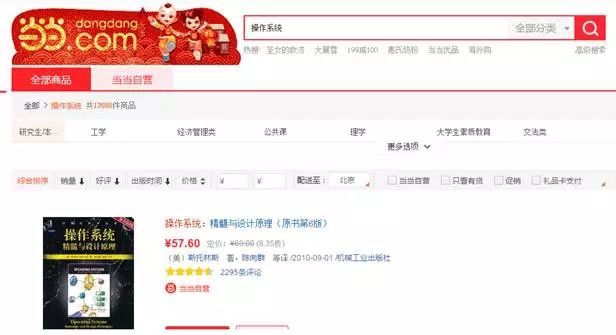

图8-6 当当网搜"操作系统"
很多能够带来利润的系统,它的核心域却没有那么多人去研究。很少有类似这样的书,把一家电厂的流程,各种概念之间的关系,用某种方式(UML的类图、序列图、活动图,以前的数据流图、E/R图)表达得清清楚楚。
在这方面,不少媒体有误导。媒体会访问某些"知名程序员"对建模的看法,得到的回答可能是"对我来说不重要"。这里面的原因是:基础设施领域的程序员更容易得到媒体青睐成为"知名程序员", "芯片"、"操作系统"、"编译器"等词汇上的光环更容易撩拨媒体从业人员的兴奋点。
开发团队A研发出了Aware,获得市场的认可,开发团队B利用Aware研发出Bware,也同样获得市场的认可。根据我们上面所说的,研发Aware和Bware各有各的复杂度。但是需要批评一种现象——开发团队B里的某个开发人员在使用Aware的过程中产生了错觉,以为研发Aware才是“技术”,把大量的精力用来思考Aware的核心域知识,却对Bware的核心域知识不屑一顾。不客气地说,媒体热爱的一些"知名程序员“就是以上描述的实例。一边拿着公司的薪水,却不好好思考如何吃透公司的核心域做好公司的项目,把大量精力投入到自己的小爱好上,在网络上博得名声。
★某开发人员喜欢钻研“底层”。明明本职工作是编写一段计费的C#代码,他偏偏要花时间深入研究到编译器、操作系统甚至硬件,而且确实也搞清楚了一些门道。虽然工作是耽搁了,但该开发人员却获得了“勤奋好钻研”的名声。其实还有另一个更值得钻研的“底层”:怎样才能使这段代码更容易维护和扩展?这段代码达到的功能和性能对涉众意味着什么?……
过分热衷于钻研“底层”,这样的行为更像是偷懒而不是勤奋,毕竟比起离开电脑去搞清楚质管部和生产部之间有什么利益上的冲突,研究MSIL的语法要容易得多,愉快得多。
所谓“底层”也只是另一个领域的知识,那个领域自有另外的人去研究。玩票式的钻研,在真正专注研究这个领域的研究者看来,实在是不值一提。但是人性的弱点如此,正如钱钟书所说:“蝙蝠碰见鸟就充作鸟,碰见兽就充作兽。人比蝙蝠就聪明多了。他会把蝙蝠的方法反过来施用:在鸟类里偏要充兽,表示脚踏实地;在兽类里偏要充鸟,表示高超出世。向武人卖弄风雅,向文人装作英雄;”[钱 1982]
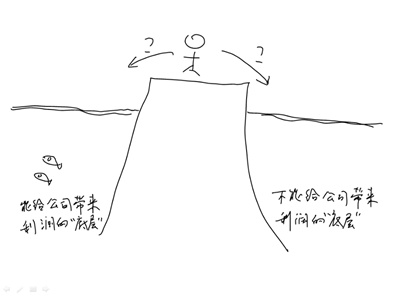
图8-7 另一个“底层”——藏在涉众心底里的各种希望和担心
和我们生活工作密切相关的软件,媒体关注得太少。一名白领,早上起来用微波炉热牛奶,开电视看新闻,坐电梯下楼,刷卡坐地铁,手机刷微信朋友圈,打卡进公司,用公司的业务系统工作。上面这句话中涉及到的七个系统中,估计只有微信的开发人员能登上媒体的版面。大多数开发人员做的软件和"知名程序员"不一样,让"知名程序员"来做这些软件,未必做得来。微波炉的软件是谁写的?Linus Torvalds能做好一个医院信息系统吗?好软件、复杂软件的判断标准是能带来利润的软件,不能主观地认为做A领域就比做B领域高级和复杂。做"电厂燃料管理系统"的开发人员没有必要仰视“××编译器”或“××操作系统”的开发人员。
市场经济中,不存在哪个领域比其他领域更核心。如果像过去"以粮为纲"、"以钢为纲"一样,扭曲市场信号,硬性指定某个领域(芯片、操作系统)更核高基,造就的多半是骗取纳税人金钱的投机分子。
图8-8是一款Windows 10认证的主板的广告。今天我们买硬件,硬件包装盒上会写"兼容Windows 10",大家对此已经习以为常。其实细想起来是比较奇怪的,按道理应该是软件兼容硬件,怎么反过来了?因为Windows在操作系统领域的优势大于该硬件在自己领域的优势。

图8-8 广告:Windows 10认证的主板
8.1.3 分离核心域和非核心域
要达到基于核心域的复用,有必要将核心域和非核心域分开考虑,将分析和设计分开考虑。人脑的容量有限,过早把各个域的知识混杂,会增加不必要的负担,导致开发人员腾不出脑力来思考核心域中更深刻的问题。一些宣传"简单设计"、"敏捷设计"的文章和书籍,所举例子涉及到的领域逻辑也真是比较"简单"。
Martin Fowler在《重构》("Refactoring: Improving the Design of Existing Code")[Fowler 1999]的第一章举了一个影片出租店的例子,先展示快而脏的代码,然后再不断重构,得到更合理的结构,内容确实很容易打动新手。类图如图8-9所示。
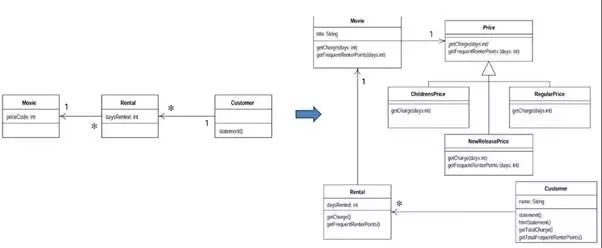
图8-9 《重构》中的例子
不过,如果具备一些领域建模知识,一眼就可以知道图8-9左侧类图犯了后文阐述的“照猫画虎”的错误,类图长得像用例图。系统的重要价值在于封装了Movie和Price之间的秘密。根本就不需要先走很多弯路再回正路。摸着石头过河是难免的,但应该在不得不摸的时候才摸,不应该假装看不见前人已修好的桥,无论大小事都主动追求摸着石头过河。
如图8-10所示,假设三个域要考虑的因素分别是a、b、c个,如果分开考虑,找到域和域之间映射的规律,负担最小可以变成a+b+c;如果混在一起考虑,大脑的负担最大会达到a×b×c。[3]
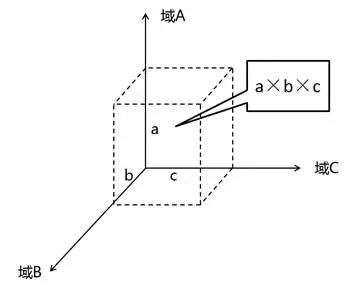
图8-10 大脑负担的复杂度
更为复杂的是,同一个核心域可能要映射到多个互相竞争的非核心域,即所谓"多平台"。例如Sports Interactive的《Football Manager(足球经理) 2017》游戏[FM2017],就有PC版、Mac版、Linux版、iPad版、Android版。核心域和非核心域如果不能很好地分离,开发的成本会大大增加。
★软件不是从天上掉下来,是人脑开发的。人脑的容量和运算速度有限,待解决问题的规模一旦变大,就必须分而治之。我们可以想象,如果外星人占领了地球,改造人类,把人类的大脑容量和运算速度提升到当前的一亿倍,那么一个现在看起来非常复杂的系统,那时只需大脑一转就搞定了,不需要显式建模。可惜,外星人没来,就算人类中有天才,大脑比其他人好五倍,超过五倍的复杂度,也要和普通人一样服从客观规律。
我们看一个"人员管理"领域的类图,如图8-11所示。
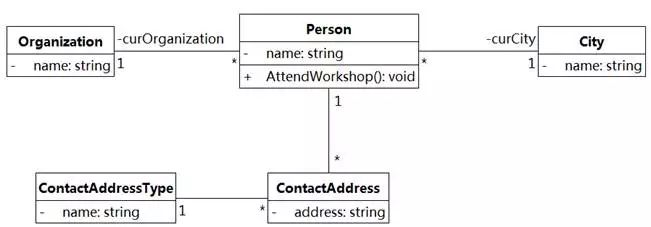
图8-11 核心域类图
如果将图8-11中的Person类映射为C#实现,可能会得到图8-12的C#代码[4]:

图8-12 类的C#实现(用Enterprise Architect映射)
如果将图8-11中的类映射到关系数据库,会得到图8-13所示的数据库结构:
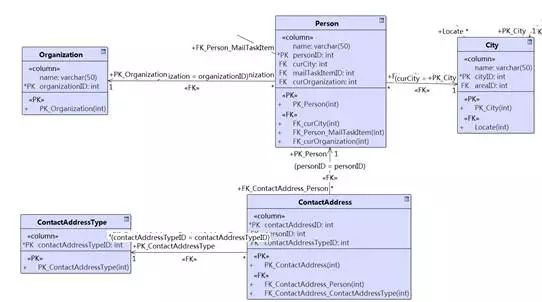
图8-13 将类图映射到数据库模型(用Enterprise Architect映射)
核心域知识和非核心域知识是独立的,域和域之间的映射规律,与域中的个体不直接相关。如果将图8-11中的Person改成Dog,City改成Cat,映射的套路没有变化。如果我们调整了域之间的映射套路,映射结果也会按照我们的调整有规律地变化,与域中的个体依然无关。
一些建模工具如Enterprise Architect和Rhapsody,可以完成类图和状态机图到非核心域的映射。即使没有强有力的自动映射工具,开发团队也可以针对几个典型的用例,归纳出最佳映射套路,编写出实现。然后,将分析模型和典型用例实现作为案例训练程序员,让程序员能够举一反三,按图施工。
以上只是提到了核心域和非核心域的分离,并没有指定思考领域概念的方法和表达领域概念的形式。可以用面向对象的方式思考,也可以用面向过程、面向××的方式思考。思考的结果可以用类图表达,也可以用E/R图等其他图形表达,甚至可以用文本表达。不过,当领域逻辑复杂时,可视化展示的图形比起文本更能帮助人脑把握大局。
如图8-14的类图,和只有自上而下顺序的文本相比,二维图形更容易让开发人员看出这些类之间的规律,更好地切割系统。
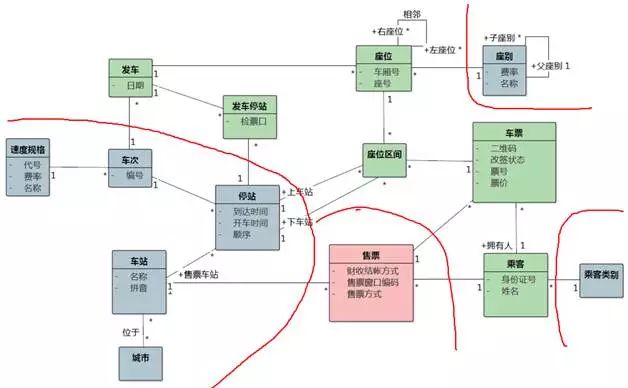
图8-14 售火车票的领域类图
图8-15是Miro Samek在他的书[Samek 2008]中举的计算器例子。小小计算器要做到没有漏洞,其中的思考也很复杂。如果不先用层次状态机的图形对领域逻辑显式建模,再根据模型通过工具或人工映射到实现,而是直接下手实现,领域逻辑靠临时脑补,得到的代码必定破绽百出。[5]
★有利润的系统,其内部都是复杂的。千万不要幼稚地以为"我的系统不复杂"。
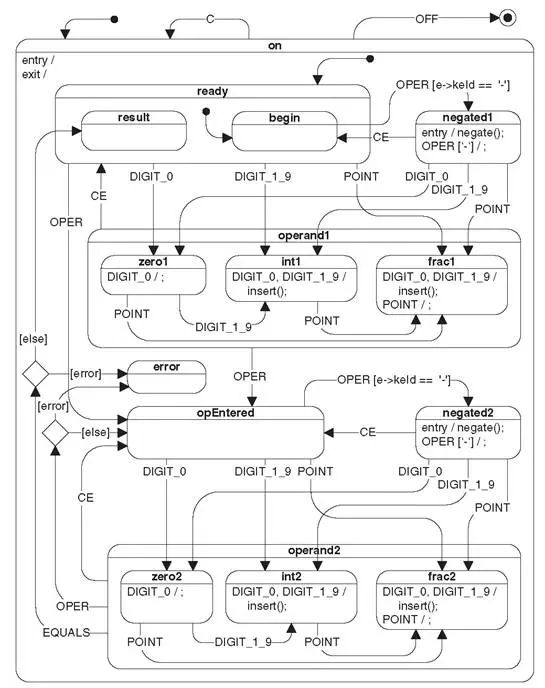
图8-15 复杂的状态机图
扫码或访问http://www.umlchina.com/book/quiz8_1_1.htm完成在线测试,做到全对以获得答案。

1. 请把左边的软件组织和右边领域概念画线对应 1 明源软件 a 农田、片块、变更、审批 2 上海数慧 b 患者、医生、药品、药房 3 浙江联众 c 售楼计划、价格管控、回款、诚意客户 A) 1-a,2-b,3-c B) 1-a,2-c,3-b C) 1-b,2-a,3-c D) 1-b,2-c,3-a E) 1-c,2-a,3-b F) 1-c,2-b,3-a |
2. 针对一个android上的点菜应用,请问以下哪些是核心域概念。 A) Dish B) Activity C) SQLiteDatabase D) Reservation E) Button F) Price |
3. 如果有人说"Linux代码超过千万行,也没有用UML建模、面向对象之类的啊?",应该怎么回答比较好? A) 人和人不一样,搞操作系统的是天才,不能比。 B) 操作系统领域的负载比较低。 C) 其实是用了UML建模的,只不过没有公布出来。 D) 因为Linux用了敏捷过程,敏捷以后就不用建模了。 |
4. 《程序员》杂志曾经刊登一篇译文,作者在白板上画了一个类图,然后开始掰着指头数这个类图缺什么,"没考虑到持久化","没考虑到对象的创建"……然后得出结论:画这个类图不如直接编码。请根据8.1.3的知识评价以上观点。 A) 不同意。作者不了解核心域和非核心域分离的重要。 B) 不同意。这个图会越来越细,逐渐添加作者认为缺少的那些东西。 C) 同意。Talk is cheap. Show me the code. D) 同意。代码才是最终结果,其他事情都是浪费。 |
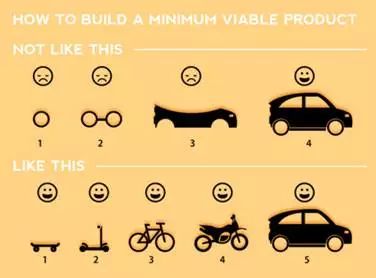
5. 以下是网络上较流行的描述"最小可行产品"(minimum viable product)开发过程的图(图片来自http://www.nickmilton.com/2015/07/lean-km-and-minimum-viable-product.html)。 8-16 "最小可行产品"(minimum viable product)开发过程 从本章内容出发,该图作者可能存在的认识上的最大错误是: A) 认为造汽车应该先从轮子造起。 B) 认为造滑板车一定比造汽车简单。 C) 认为应该小步改进,先给客户一个滑板车也是改进。 D) 认为客户目前停止不动,随便给个什么车都是救命。 |
8.1.4 三种分析类
本书采用面向对象的方法来构造系统——假设系统由"对象"这样一种东西构成,对象封装了数据和行为。在分析工作流,我们认为系统中的对象在一个虚的"对象空间"中运行。这个空间不是内存,也不是硬盘,只是人脑中的一个逻辑空间,将它想象成宇宙空间也未尝不可。在"对象空间"中,速度不是问题,对象的创建和对象之间的通信都非常快。
图8-17 虚的"对象空间"
注意上文提到的"假设"二字。面向对象就是一个假设,如果不认可系统由对象构成,也可以开发出系统,只不过用的方法不是面向对象方法。面向对象的思考方式比其他方法如面向过程要好一点,原因不是计算机喜欢面向对象或者面向对象更接近于计算机的底层(计算机更"喜欢"人类用机器语言编码,一千万行指令写在一起依次执行),而是面向对象的思考方式和人类的认知相当贴近,更有利于人脑去把握问题的复杂性。
具有共同特征的对象集合归为"类"。归类是人类认知的一种基本技能,其哲学讨论可以追溯到柏拉图的理念论(Theory of Forms)[Plato]。
依照Ivar Jacoson[Jacobson 1992]的思想,在分析工作流我们进一步假设系统中存在三种类:边界类(Boundary Class)、控制类(Control Class)和实体类(Entity Class)。在模型中,我们通过不同的构造型(Stereotype)来表达。很多UML工具已经内置了这些构造型。即使不用构造型区分,从"某某界面","某某控制"等类的名字也可以了解该类在系统中扮演的角色。
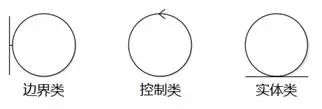
图8-18 三种分析类的构造型
图8-19展示了三种分析类的责任、和用例的关系以及命名。
构造型 |
责任 |
和用例的关系 |
命名 |
边界类 |
输入、输出以及简单的过滤 |
每个有接口的外系统映射一个边界类。 |
外系统名称+接口 |
控制类 |
控制用例流,为实体类分配责任。 |
每个用例映射一个控制类。 |
用例名称+控制 |
实体类 |
系统的核心,封装领域逻辑和数据。 |
用例和实体类的关系是多对多的,一个用例可以由一到多个实体类协作实现,一个实体类可以参与一到多个用例的实现。 |
领域概念名称 |
图8-19 分析类的责任、和用例的关系以及命名。
"每个有接口的外系统映射一个边界类"里的"外系统"不仅仅包括系统执行者,还包括仅接受系统输出信息的外系统。以下面将要开发的"时间→发送公开课通知"用例为例,该用例进行过程中,系统会向软件开发人员发送公开课通知,同时还要向UMLChina助理反馈发送通知的进展。软件开发人员和UMLChina助理在这个用例中仅仅是接受输出,没有输入信息给系统,但系统可以分别设置一个边界类来封装向软件开发人员和UMLChina助理反馈信息的责任,如图8-20所示。
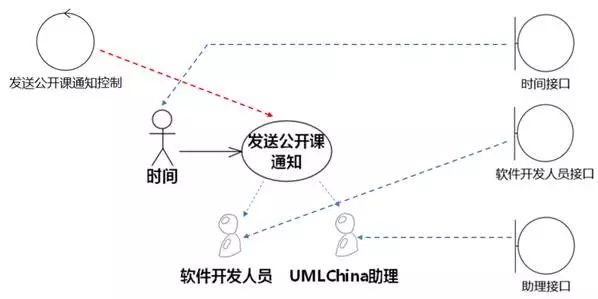
图8-20 外系统映射边界类,用例映射控制类
分析工作流的边界类不暗示任何实现方案。在总责任相等的前提下,它和实现的映射是多样的,可以用图形界面实现,也可以用非图形界面(包括文本、声音……)实现。即使使用图形界面实现,也不能简单认为一个边界类对应一个窗体。一个边界类的责任可以拆解到多个窗体上,一个窗体也可以和多个外系统交互。如何组织这些责任,应该从外系统的角度来考虑,而不是从用例或实体类的角度来考虑
图8-21中,“助理接口”边界类被圈住的几个责任来自不同用例的步骤,但在使用图形界面实现时,可以放在面向助理的、通知专用的窗体中。
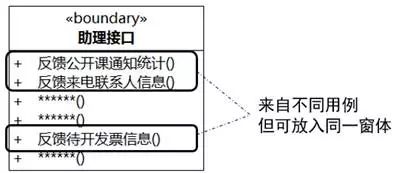
图8-21 边界类责任的组织
类似的例子还有:一份申请,需要通过系统审批三次,也就是三个不同的用例。在图形界面实现中,可能不需要准备三个窗体,部门主管、财务、副总三个审批人可以在同一窗体上工作,但部门主管、财务、副总各自有对应的分析边界类。
如果某个外系统和系统的交互很多,对应边界类的责任可能会有很多。另一种做法是按"外系统+用例"的组合映射边界类,这样可以减少一个边界类上的操作个数。不过,这样的做法已经暗示“按用例来划分边界”,所以还是建议尽量保持一个外系统一个边界类,如果操作很多,可以将从外系统角度观察可能要分在一组的操作移到一起,EA等工具可以随意定制属性和操作的上下显示顺序。
控制类是可选的,如果在分配责任时发现控制类只起到传递的作用,没有起到分解和分配的作用,那么就可以把控制类去掉。
图8-22展示了三种分析类之间的协作。
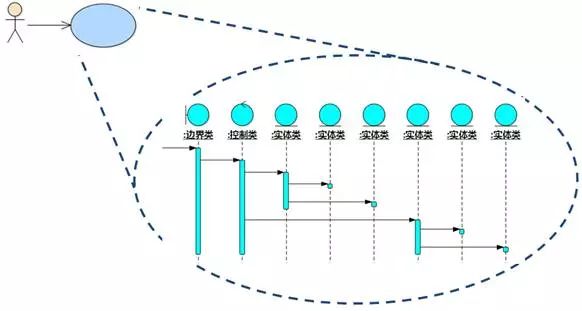
图8-22 三种分析类在系统中的协作
执行者先把消息发给边界类对象,边界类对象能履行的就履行,无法履行的责任,再发给控制类对象。控制类对象就像总裁办,不做具体工作,只是将责任分解后分配给实体类对象。实体类按照它们之间的耦合程度聚集成若干聚合(也有可能一个类单独形成聚合),控制类对象发送消息时,先发给聚合的整体对象(也称聚合根),再由聚合根分配给聚合内的其他对象。最后,由边界类对象反馈信息,完成一个交互回合。
边界类与执行者、控制类与用例的映射关系很明显,所以识别边界类和控制类不需要太多思考。思考的主要工作量应该花在识别实体类上。一个用例需要哪些实体类协作实现、如何协作,一个实体类会参与哪些用例的实现,这是一个多对多的映射,需要由分析员的大脑决定哪种映射最好。
有的分析方法学如ICONIX[Doug 2007]提倡Robustness Diagram,认为可以通过它来帮助寻找类。开发人员一用确实感觉很舒服,噼里啪啦就发现好多类,有一种"我已经取得了不小成绩"的错觉,不过要是仔细看看,就知道"发现"的多是边界类、控制类。这些类用不着刻意去发现,只要按照图8-19的套路映射即可。最难的工作——寻找实体类以及它们之间的协作,Robustness Diagram却是寥寥带过。所以,本书不推荐开发人员额外花时间画Robustness Diagram。应该把精力放在识别实体类上,画分析序列图时再直接按照上面的套路映射相应的边界类、控制类。
★建模的每一个成果都应该是经过艰苦思考得到的。轻易得到的内容可能就不需要优先花时间建模了,所以我们一定要对那些砍瓜切菜一样的建模方法和轻易得到的正确无用的废话心怀警惕。这些不假思索得到的东西,没有门槛,没有竞争力。
三种分析类的划分也同样只是一种思考的方式。不认可这种思考方式,也可以开发出系统,只不过系统的结构可能不那么好。边界类(B)、控制类(C)和实体类(E)的划分和实现中的MVC概念有不同,后文再讨论这个问题。
8.1.5 识别分析类和属性
目前已有的工件是用例规约,它可以作为识别类的开始。阅读用例规约的基本路径、扩展路径、字段列表和业务规则部分,针对表示名词或事件的词汇,逐个思考,这是不是系统要记住的概念?如果是,那么它是类,还是某个类的属性?
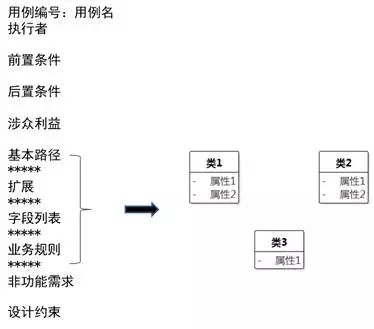
图8-23 从用例规约提炼类和属性
★之前做需求启发时,如果为了整理领域知识画了类图,在此处可以挑系统相关的部分,结合用例规约的内容精化。
如果您有关系数据库建模的经验,也可以这样思考:如果系统采用关系数据库来保存数据,那么数据库里应该会有哪些表?这样思考得到的表和实体类基本上是一一映射的。表对应类,列对应属性,行对应对象,关系对应关联。如果数据建模技能掌握得好,得到的数据模型符合1NF、2NF和3NF,那么用数据建模的思考方式得到的类图极有可能也是合格的。反过来也可以说,如果类建模做得好,映射得到的关系数据库模型也会有合理的结构。
当然,我们画类图的目的不仅是为了得到数据库,面向对象和数据库也没有必然的绑定关系。任何系统都可以用面向对象的方式来构造,不管它用什么方式来持久存储对象。
例如,我们坐电梯上楼时,在电梯里按了按钮5。电梯到了5层,会把门打开。电梯肯定记住了某些东西才能这么做。可以认为它记住了一个整数5,代码会这样写:
int destinationFloor=5;
但是,这样的做法,背后的类型是int,这是基础设施领域的概念,不是电梯调度领域的概念,说明我们的复用级别是基于基础设施域,没有基于核心域。图8-24表达了电梯调度系统的恰当抽象。
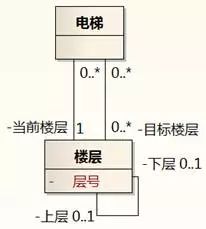
图8-24 电梯调度领域概念
图8-24中的规律只和核心域(电梯调度领域)有关,和如何用非核心域映射无关。例如,一部电梯去往多个目标楼层,这"多个目标楼层"在电梯对象里用数组、列表还是集合来表示,不影响核心域的概念。
接下来将从《软件方法(上)》给出的UMLChina系统两个用例的用例规约提炼类。先把两个用例规约列出如下:
用例编号:UC1
用例名:发送公开课通知
执行者:时间(主)
……
基本路径:
1. 当到达时间周期时,系统选择下一个适合发邮件的发件邮箱以及下一个待发往的邮箱地址
2. 系统使用所选发件邮箱向所选待发往的邮箱地址发送公开课通知邮件
3. 系统记录邮件发送情况
扩展路径:
1a. 没有正在生效的通知任务:
1a1. 用例结束
1b. 有正在生效的通知任务,但没有指定发件邮箱:
1b1. 系统向UMLChina助理的电子邮箱地址发邮件告知正在生效的通知任务没有指定发件邮箱
1b2. 用例结束
1c. 有正在生效的通知任务,有指定发件邮箱,但没有适合发邮件的发件邮箱:
1c1. 用例结束
1d. 没有下一个待发往的邮箱地址:
1d1. 系统结束正在生效的通知任务
1d2. 系统向UMLChina助理的电子邮箱地址发邮件告知正在生效的通知任务已结束
1d3. 用例结束
字段列表:
2. 公开课通知邮件=主题+内容
2. 邮件主题的模板:
[联系人称呼]您好,欢迎您参加[公开课举办城市][公开课开始日期]-[公开课结束日期]的[公开课主题]公开课
2.邮件内容的模板:
[联系人称呼]您好,
欢迎您参加[公开课举办城市][公开课开始日期]-[公开课结束日期]的[公开课主题]公开课
开课时间: [公开课开始日期]-[公开课结束日期]([周*、周*])(9:00-12:00,13:10-17:10)
上课地点: [公开课举办城市]
费用:每人[公开课费用]元,含午餐。交通、住宿费请自理。
[报名交费信息]
[大纲]
2. 发送邮件需要用到的信息:发件邮箱SMTP服务器地址、发件邮箱账户名、发件邮箱密码
3. 邮件发送情况=邮箱地址+发送时间+发件邮箱+是否成功
业务规则:
1. 时间周期缺省为5秒
1. 定位适合发邮件的发件邮箱的规则:从正在生效的通知任务指定的发件邮箱中找出以下值最大而且值大于0的邮箱: (当前时间-邮箱上次发送时间)-邮箱最小发件时间间隔
1. 定位下一个待发往的邮箱地址的规则:针对正在生效的通知任务,随机选取符合以下条件的邮箱地址:联系人符合公开课通知任务条件,而且联系人有邮箱地址尚未被正在生效的通知任务通知
1. 联系人符合公开课通知任务条件的规则:联系人当前所在城市所属分区与公开课举办城市所属分区相同,而且联系人不属于"拒绝公开课通知联系人",而且联系人不属于该公开课"已通知联系人",而且联系人当前所在组织不属于该公开课"已通知的组织"
********************************** 背景知识: 为了尽可能减少干扰,公开课通知的总原则是:能不通知就不通知。 如果某位软件开发人员已经表明不想接到公开课通知,就不应再发公开课通知邮件给他,该人员成为"拒绝公开课通知联系人";如果某位软件开发人员已经在QQ、微信等其他途径咨询过某次公开课,也不应再发该次公开课的邮件给他,该人员成为该次公开课"已通知联系人";如果某组织的领导(例如研发总监、培训经理……)已经询问过某次公开课事宜,就不必再通知该组织里的开发人员该次公开课的信息,该组织成为该次公开课"已通知的组织"。 可以推测系统可能有另外的一个或多个用例会修改这些信息,但这些问题留到后面再考虑。 ********************************** |
用例编号:UC2
用例名:创建公开课通知任务
执行者: UMLChina助理
……
基本路径:
1. UMLChina助理选择公开课,请求创建通知任务
2. 系统验证所选公开课适合创建通知任务
3. 系统反馈设置通知任务界面
4. UMLChina助理提交公开课通知任务
5. 系统反馈公开课通知任务
6. UMLChina助理确认
7. 系统保存通知任务
8. 系统反馈已经创建通知任务
扩展路径:
2a. 所选公开课已存在正在生效的通知任务:
2a1. 系统反馈所选公开课已存在正在生效的通知任务,询问是否停止所选公开课正在生效的通知任务
2a2. UMLChina助理选择停止所选公开课正在生效的通知任务
2a2a.选择不停止:
2a2a1. UMLChina助理选择不停止所选公开课正在生效的通知任务
2a2a2. 用例结束
2a3. 系统停止所选公开课正在生效的通知任务
2a4. 返回3
字段列表:
4. 通知任务=公开课+{发件邮箱}*+{已通知的组织}*+{已通知的联系人}*+是否立即生效
7. 通知任务=4+创建时间+创建人
业务规则:
2. 公开课适合创建通知任务的规则:该公开课没有正在生效的通知任务,而且公开课的开始日期应该是当前日期的3天或更长时间之后
接下来,我们来抽丝剥茧,逐句分析用例规约。
步骤 |
1. 当到达时间周期①时,系统②选择下一个适合发邮件的发件邮箱③以及下一个待发往的邮箱地址④ |
补充约束 |
1. 时间周期缺省为5秒⑤ 1. 定位适合发邮件的发件邮箱的规则:从正在生效的通知任务⑥指定的发件邮箱⑦中找出以下值最大而且值大于0的邮箱: (当前时间-邮箱上次发送时间⑧)-邮箱最小发件时间间隔⑨ 1. 定位下一个待发往的邮箱地址的规则:针对正在生效的通知任务,随机选取符合以下条件的邮箱地址:联系人⑩符合⑪公开课⑫通知任务条件,而且联系人有邮箱地址尚未被正在生效的通知任务通知⑬。 1. 联系人符合公开课通知任务条件的规则:联系人当前所在城市⑭所属分区⑮与公开课举办城市⑯所属分区相同,而且联系人不属于"拒绝公开课通知联系人"⑰,而且联系人不属于该公开课"已通知联系人"⑱,而且联系人当前所在组织⑲不属于该公开课"已通知的组织"⑳。 |
①时间周期。这是执行用例"发送公开课通知"的时间周期,可以看作和时间交互的边界类“时间接口”的一个属性。

图8-25 UMLChina系统类图1
②系统。"系统"的概念是需求工作流的概念。在需求工作流,我们把系统看作一个整体对外提供服务。在分析工作流中,"系统"的概念已经被打碎成各个类,所以"系统"这个词不需要识别成类。图8-26表达了不同工作流视角下的待开发系统。
工作流 |
如何称呼当前要开发的系统 |
原因 |
业务建模 |
某某系统 |
研究对象是组织。组织中有很多系统,需要指出系统的名字。 |
需求 |
系统 |
研究对象是当前要开发的系统,不需要再说名字。 |
分析 |
很多个类 |
研究焦点进入系统的内部,思考系统内部的构成。 |
图8-26 各工作流如何称呼当前要开发的系统
有些开发人员在这里会犯错误,把"系统"识别成一个类,画成这样:
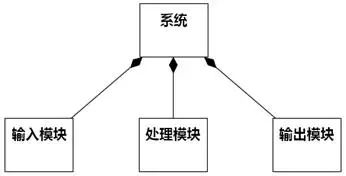
图8-27 无意义的类图
这种图只是简单功能分解的另一个变体,对剖析系统的复杂性没有帮助,却给开发人员带来一种虚假的成就感:我描述了几个类之间的关系,而且还是组合关系,已经开始剖析系统的复杂性了呢!
③下一个适合发邮件的发件邮箱。"发件邮箱"映射为类。"下一个适合发邮件",映射为类的状态属性,深入建模后,再消除这些状态属性。

图8-28 UMLChina系统类图2
④下一个待发往的邮箱地址。"邮箱地址"本来应该是"联系人"的一个属性,但"下一个待发往的"这个定语说明"邮箱地址"有"下一个待发往"这样的状态属性,另外考虑到联系人会有多个不同用途的邮箱地址,所以把"邮箱地址"独立出来变成一个类,"下一个待发往"作为"邮箱地址"的状态属性。

图8-29 UMLChina系统类图3
⑤时间周期缺省为5秒。映射为"时间周期"属性的缺省值。

图8-30 UMLChina系统类图4
为了防止滥发邮件,邮箱提供商会规定每个邮箱每天发送邮件总量以及发送时间间隔,如果违反规定,邮件会暂时无法发出,邮箱甚至会被关闭。过于频繁地检测是否有符合条件的发件邮箱,没有意义,但如果检测时间间隔太长,导致可以发邮件时发件邮箱却空置,也影响发邮件的效率。5秒应该是合理的值。
⑥正在生效的通知任务。"通知任务"映射为类,"正在生效"映射为状态属性。
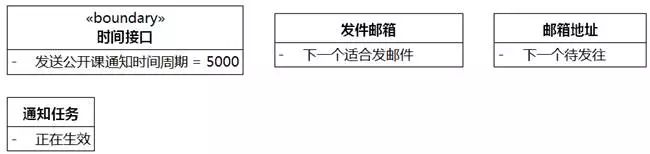
图8-31 UMLChina系统类图5
⑦指定的发件邮箱。"通知任务"关联到"发件邮箱",同时调整一下类的位置。
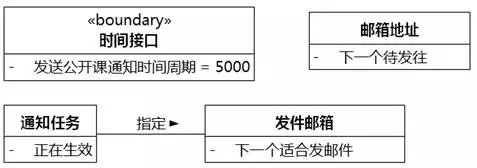
图8-32 UMLChina系统类图6
⑧上次发送时间。"发件邮箱"的属性。
⑨最小发件时间间隔。"发件邮箱"的属性。
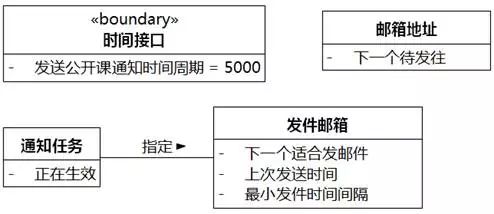
图8-33 UMLChina系统类图7
⑩联系人。映射为类。
⑪符合。映射为“公开课”和“联系人”之间的关联。
⑫公开课。映射为类。
⑬通知。映射为“邮箱地址”和“公开课”之间的关联。
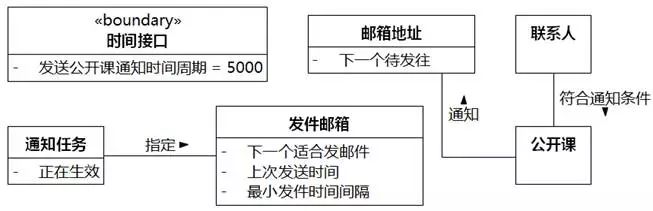
图8-34 UMLChina系统类图8
1. 联系人符合公开课通知任务条件的规则:联系人当前所在城市⑭所属分区⑮与公开课举办城市⑯所属分区相同
⑭联系人当前所在城市。"城市"映射为类,和"联系人"建立关联。"当前所在城市"是关联中"城市"的角色名称。
⑮所属分区。"分区"映射为类,和"城市"建立关联。
⑯公开课举办城市。"公开课"和"城市"建立关联,"举办城市"是关联中"城市"的角色名称。
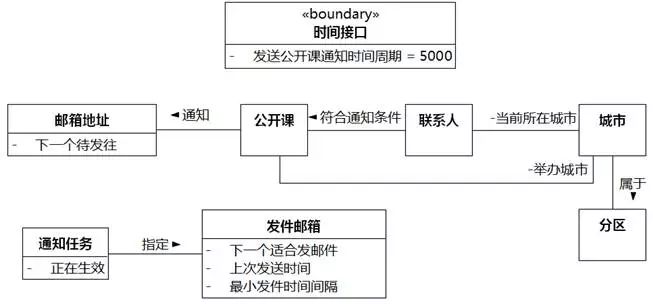
图8-35 UMLChina系统类图9
⑰"拒绝公开课通知联系人"。"拒绝公开课通知"映射为"联系人"的一个状态属性。
⑱该公开课"已通知联系人"。在"联系人"和"公开课"中间再加一个名称为"通知"的关联。深入建模后,会慢慢精简这些关联。
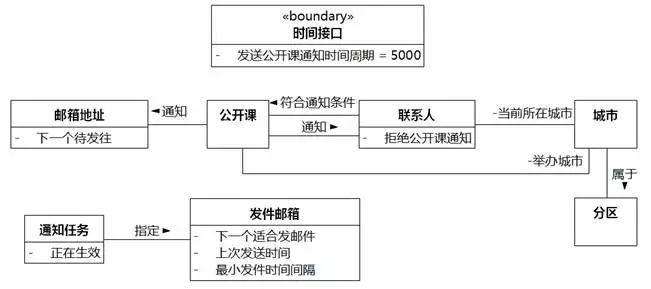
图8-36 UMLChina系统类图10
⑲联系人当前所在组织。"组织"映射为类,和"联系人"建立关联。"当前所在组织"是关联中"组织"的角色名称。
⑳该公开课"已通知的组织"。在"组织"和"公开课"中间再加一个名称为"通知"的关联。
这时,类图上的类已经比较多了,我们调整类图中各个类的位置,让关联线尽可能不交叉。
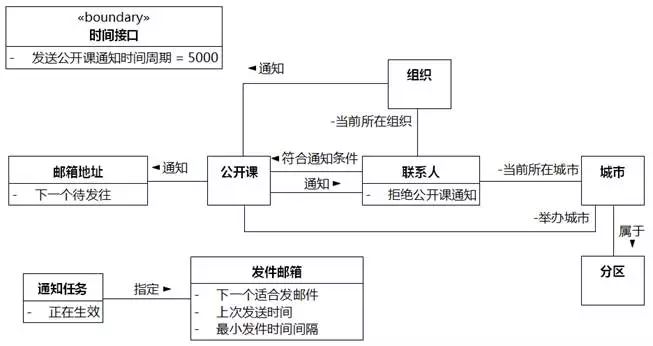
图8-37 UMLChina系统类图11
步骤 |
2. 系统使用所选发件邮箱向所选待发往的邮箱地址发送公开课通知邮件 |
补充约束 |
字段列表: 2. 公开课通知邮件=主题+内容 2. 邮件主题的模板: [联系人称呼 2.邮件内容的模板: [联系人称呼]您好, 欢迎您参加[公开课举办城市][公开课开始日期]-[公开课结束日期]的[公开课主题]公开课 开课时间: [公开课开始日期]-[公开课结束日期]([周*、周*])(9:00-12:00,13:10-17:10) 上课地点: [公开课举办城市] 费用:每人[公开课费用 [报名交费信息 [大纲 2. 发送邮件需要用到的信息:发件邮箱SMTP服务器地址 |
公开课通知邮件。"公开课通知邮件"映射为类。
主题+内容。"主题"、"内容"映射为"公开课通知邮件"的属性。
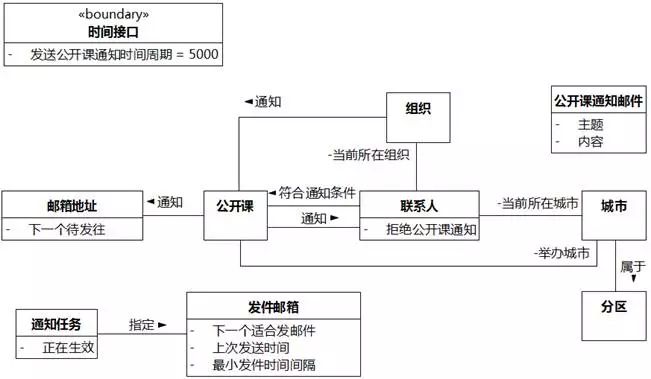
图8-38 UMLChina系统类图12
联系人称呼。"称呼"映射为"联系人"的属性。
公开课开始日期。"开始日期"映射为"公开课"的属性。
公开课结束日期。"结束日期"映射为"公开课"的属性。
公开课主题。"主题"映射为"公开课"的属性。
公开课费用。"费用"映射为"公开课"的属性。
报名交费信息。"报名交费信息"映射为"公开课"的属性。
大纲。"大纲"映射为"公开课"的属性。
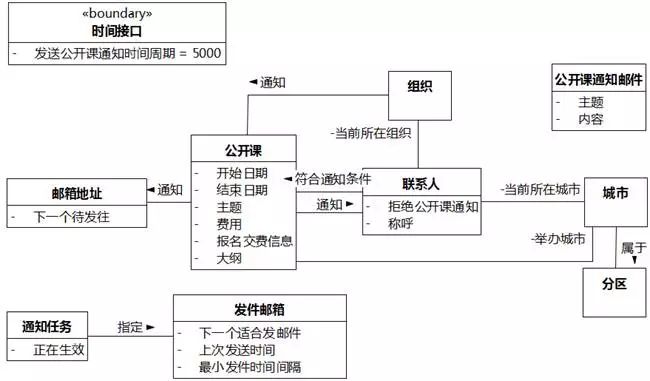
图8-39 UMLChina系统类图14
SMTP服务器地址。"SMTP服务器地址"映射为"发件邮箱"的属性。
发件邮箱账户名。"账户名"映射为"发件邮箱"的属性。
发件邮箱密码。"密码"映射为"发件邮箱"的属性。
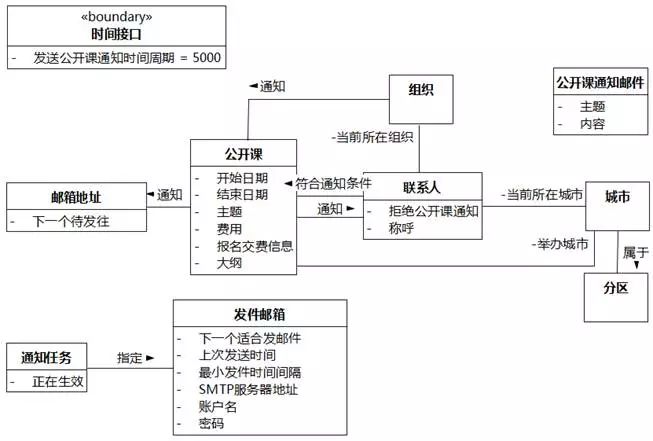
图8-40 UMLChina系统类图14
步骤 |
3. 系统记录邮件发送情况 |
补充约束 |
3. 邮件发送情况=邮箱地址+发送时间+发件邮箱+是否成功 |
系统记录邮件发送情况。"邮件发送"映射为类。
邮件发送情况=邮箱地址+发送时间+发件邮箱+是否成功。添加"时间"和"成功"属性,建立"邮件发送"和"邮箱地址"之间的“发往”关联,建立"邮件发送"和"发件邮箱"之间的“使用”关联,建立"邮件发送"和"公开课通知邮件"之间的关联。
如果一封发往某邮箱地址的电子邮件发送失败,可以再次发送,使用的发件邮箱可以是之前的发送用过的发件邮箱,也可以是新的邮箱。也就是说,同一封电子邮件直到发送成功为止可能会发生多次发送事件,关联到哪个发件邮箱是由各次发送事件决定的。电子邮件发往哪个邮箱地址,只和电子邮件有关。
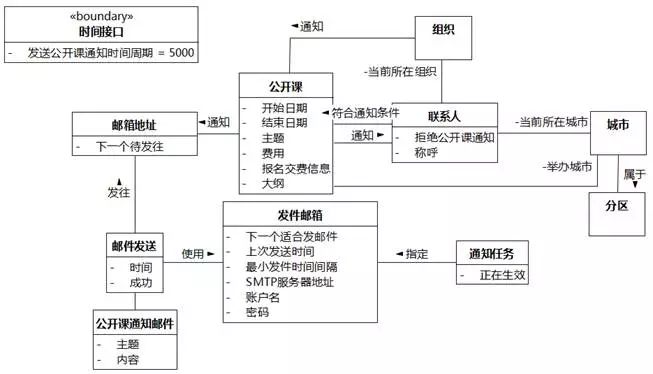
图8-41 UMLChina系统类图15
1a. 没有正在生效的通知任务:
1a1. 用例结束
1b. 有正在生效的通知任务,但没有指定发件邮箱:
1b1. 系统向UMLChina助理的电子邮箱地址发邮件告知正在生效的通知任务没有指定发件邮箱
1b2. 用例结束
1c. 有正在生效的通知任务,有指定发件邮箱,但没有适合发邮件的发件邮箱:
1c1. 用例结束
1d. 没有下一个待发往的邮箱地址:
1d1. 系统结束正在生效的通知任务
1d2. 系统向UMLChina助理的电子邮箱地址发邮件告知正在生效的通知任务已结束
1d3. 用例结束
UMLChina助理的电子邮箱地址。"助理"映射成类,"邮箱地址"映射成“助理”的属性。此处没有将“助理”关联到现成的“邮箱地址”,因为公开课通知不需要发往助理的邮箱地址,联系人的邮箱地址需要懂得的属性它不需要知道,例如"下一个待发往"、"某次公开课已通知"。当然,这个“邮箱地址”属性后面还会再精化。
通知任务已结束。"已结束"映射为"通知任务"的状态属性。
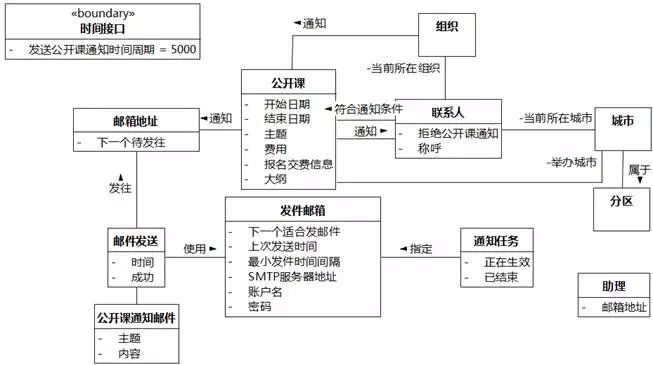
图8-42 UMLChina系统类图16
第一个用例分析完毕,接下来看第二个用例。
1. UMLChina助理选择公开课,请求创建通知任务
UMLChina助理。UMLChina助理是系统执行者,首先映射一个边界类"助理接口"。
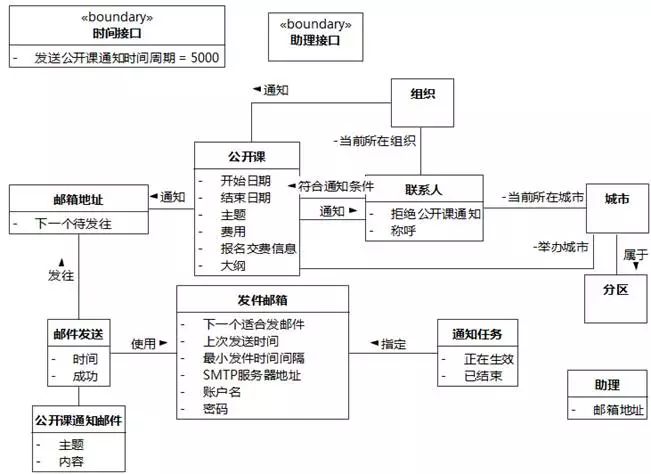
图8-43 UMLChina系统类图17
这里要注意一点:“UMLChina助理”执行者和"助理"类并没有必然的对应关系,也就是说系统执行者和实体类没有必然的对应关系。类图中之所以存在“助理”类,是因为系统要维护助理的信息。
例如,乘客坐电梯上楼,乘客是电梯系统的执行者,但电梯系统可能不需要"乘客"实体类,因为它不需要记住乘客的信息。当然,有朝一日,电梯升级为维稳电梯,用例规约里有:
乘客提供身份标识
系统验证身份标识合法
系统记录乘客信息和入厢时间
这时,电梯系统里就有"乘客"实体类了,因为系统要记住乘客的信息。某个概念是否映射实体类的依据是系统是否要记住它,和是否有同名的执行者无关。
和执行者对应的是边界类。电梯系统没有"乘客"类,但会有"乘客接口"类,目前的实现形式多为图8-44所示。
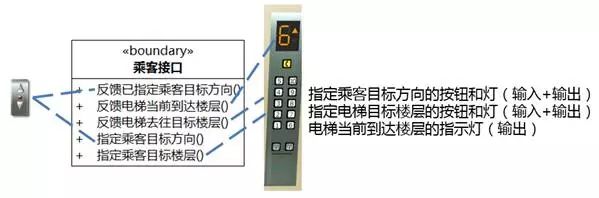
图8-44 乘客接口的虚与实
步骤 |
2. 系统验证所选公开课适合创建通知任务 |
补充约束 |
业务规则: 2. 公开课适合创建通知任务的规则:该公开课没有正在生效的通知任务 |
该公开课没有正在生效的通知任务。在"公开课"和"通知任务"之间建立关联。
当前日期。和本领域没有特定关系,不识别。
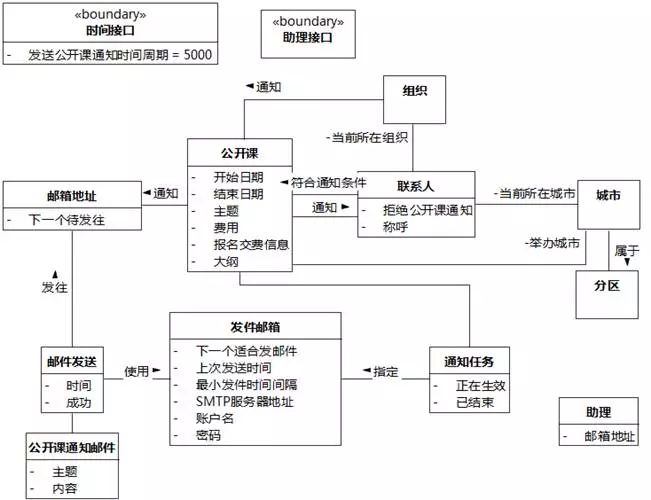
图8-45 UMLChina系统类图18
步骤 |
7. 系统保存通知任务 |
补充约束 |
字段列表: 7. 通知任务=4+创建时间+创建人 |
通知任务=4+创建时间+创建人。"创建时间"映射为"通知任务"的属性。在"通知任务"和"助理"之间建立关联,"助理"的角色为"创建人"。
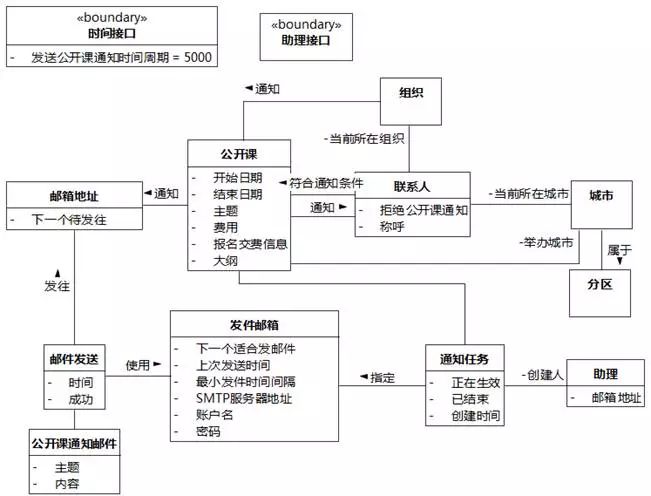
图8-46 UMLChina系统类图19
至此,用例规约里的概念已经提炼完毕。接下来的工作就是进一步精化类图,在此之前,我们来看看识别类和属性时的一些要点。
8.1.6 识别分析类和属性的要点
8.1.6.1 关于中英文命名
该用中文就用中文,该用英文就用英文,该用日文就用日文。中英文命名问题和设计工作流(编码、设计数据库……)中碰到的问题是类似的。分析类虽然不包含设计工作流的知识,但它是设计工作流的基础。反对在设计工作流中使用中文命名(类名、属性名、表名、字段名……)的理由可能是编译器不支持、DBMS不支持、切换输入法太麻烦、版式不好看等。编译器、DBMS因素随着时代的发展慢慢地不再是问题,版式、切换输入法问题在画图建模中不存在,所以用中文名称不是大问题。当然,如果开发团队是国际化的,就是另外一种情况。
总之,分析类和属性(包括后面要添加的操作)的名称应该以方便开发团队思考和交流领域知识为首要考虑因素。
EA提供了别名(Alias)。名称可以用英文——其实不是英文,是编译器广泛支持的符号集合。除名称外,再加一个别名用于显示。不过,建议暂时不用。如果熟悉的领域词汇是中文名,在那时还需要花时间去想一个英文名,分散了建模中思考的精力,更不用说模糊的汉语拼音和错误的英文会给后续工作带来的麻烦了。
8.1.6.2 命名中不带冗余信息
不要在类名的最后加"类"字;不要在类名的前后加"Class"或"C";不要在类名的最后加"情况"、"信息"、"记录"、"数据"、"表"、"库"、"单"等词。
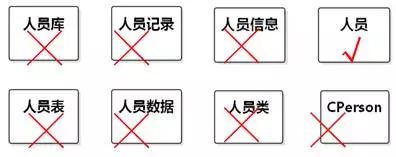
图8-47 类名后面不需要加冗余词
如果系统关注的焦点是"数据处理",处理的数据是什么内容无所谓,"信息"、"数据"也可以作为一个类的名称,但它和"人员"不属于一个领域,不在一个抽象级别。如图8-47。
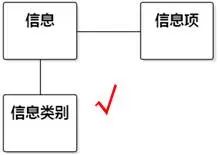
图8-48 "信息"作为类
当然,如果一个带有以上后缀的词在领域中已经存在很久,成为了领域的术语,直接使用无妨。例如"订单"带有"单"字,实际上描述的是一次"购买",但"订单"已经在领域中广泛使用,可以作为类名。
属性名称前不需要加类名。
如图8-49。按"类的属性"念出来,"人员的姓名"很好,"人员的人员姓名"冗余了。
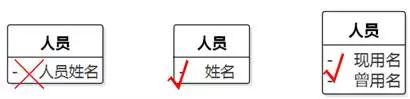
图8-49 属性名称前不需要加类名
英文名用单数。
如图8-50。"顾客"的实例是一名顾客,"顾客们"的实例是什么?一个集合?
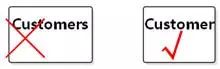
图8-50 英文名用单数
设计工作流中的数据库表名也应该用单数。有一些开发人员习惯在最后加s(当然,复数未必是加s),甚至有一些框架直接就在表名后面加上s,理由是表里有很多行。这个问题和上面提到的类名称后面加个"类"字是一样的,都是一种冗余。"类"、"表"的概念已经隐含了"多个对象"、"多行"的意思。说"我是一个类,我的名字叫顾客"就够了,不需要说"我是一个类,我的名字叫顾客类"或者"我是一个表,我的名字叫顾客们"。
8.1.6.3 命名要一致
同一个概念要用一致的词汇表达。例如"宝贝"还是"商品"?"顾客"、"客户"还是"会员"?如果没有差别,应该统一到同一个词汇,如果有差别,应该在类图上表达其中差别。如果还没有思考到如何在类图上表达,可以先在类的说明中阐述确切含义。
如图8-51,左侧的几个概念中,"宝贝"和"商品"、"顾客"和"客户"含义相同,把它们合并,同时在类图上更精细地表达"用户"、"顾客"、"会员"概念之间的差别。
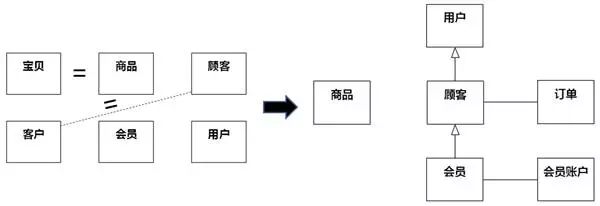
图8-51 理清混淆的概念
8.1.6.4 切勿照猫画虎
如果用例规约是完整的,从用例规约中找到实体类应该问题不大。不过,有的开发人员根本没有写用例规约,也不具备基本的对象建模技能,会发现自己找不到合适的类甚至找不到类。
类图长得像用例图。
例如,一个电商系统,开发人员一开始心里有一个想法,要做一个“搜索商品”的功能。那么要实现这个功能,需要什么类呢?开发人员干脆就按看到的表面现象来找类,得到的类图长得非常像用例图,如图8-52。
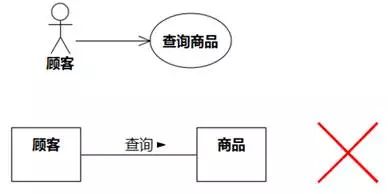
图8-52 长得像用例图的类图
显然,系统之所以能够为顾客查询“屏幕尺寸为4.6-5.0英寸的Android手机”,不是因为它记住了哪位顾客查询过哪件商品,而是因为它记住了各种商品的类别和特征。正确的类图应该类似于图8-53。
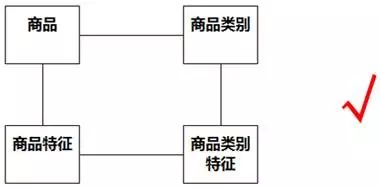
图8-53 更合适的类图
类长得像过程。
没有基本的面向对象抽象思维的开发人员,可能会按照面向过程的思路噼里啪啦把代码写出来,然后就感觉似乎不需要什么类来帮忙了。即使出于赶时髦需要类,他就把过程名称加上or或er作为类名称,然后把原来的过程作为or或er类的操作,有时还用上一些泛化关系来做点缀,如图8-54所示。这样做表面上似乎是面向对象了,实际上是换汤不换药,没有得到面向对象的好处。
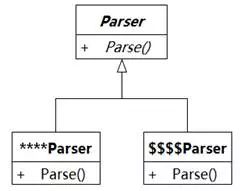
图8-54 伪面向对象抽象
碰到这种情况,可以思考如果按照面向过程的思路来编码,什么地方的代码最复杂?长长的“算法”中定义的变量,往往就是候选的实体类。
类长得像报表。
在没有用例规约的情况下,开发人员可能是根据手上的一些类似于报表的需求素材来找类。如果缺少抽象能力,就会把报表直接变成类,照抄报表的每一栏作为属性,如图8-55所示。
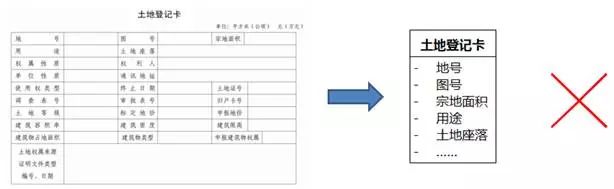
图8-55 长得像报表的类
报表只是视图,把更为本质的多个实体类的一些属性组织在一起。针对这种情况,可以用下文介绍的类和属性检验规则来深入思考背后的领域概念。
正如第一章所说,需求和设计不是一一对应的。设计源于需求,高于需求。
8.1.6.4 使用核心域术语
一个领域之所以能作为“领域”为人认知,必定存在一套日益完善和精确的术语体系。每个术语有其独特的、其他领域术语不能替代的内涵。分析模型中的名称应该来自核心域的术语体系。
建模人员可能会用自己熟悉的领域的术语体系去代替不那么熟悉的核心域术语体系,还引以为豪。例如,面对一段集装箱领域装箱规则的描述,建模人员立即在大脑中把它转换成自己熟悉的概念:栈、链表、树……认为这是“透过现象看本质”,甚至宣称“我就是程序,程序就是我”!
Fred Brooks在《人月神话》[Brooks 1995]中引用了James Coggins的一段话:
The problem is that programmers in O-O have been experimenting in incestuous applications and aiming low in abstraction, instead of high. For example, they have been building classes such as linked-list or set instead of classes such as user-interface or radiation beam or finite-element model.
问题是面向对象程序员在开发错综复杂的应用时,关注的是低层次,而不是高层次的抽象。例如,他们开发了很多像链表或集合这样的类,而不是用户界面、射线束或者有限元模型。
不同领域有不同的难题,因为觉得困难,所以对真正要解决的核心域问题视而不见,却花精力去做那些自己熟悉的、他人已解决的其他领域问题,是一种逃避。
涉众常使用的词汇不一定是合格的领域术语。涉众经常使用一些不严谨的称呼,例如用颜色来表征:绿本(小产权证)、绿卡(永久居民卡)、绿单(预约单)。这些称呼中的信息是不稳定的,如果政府决定改用其他颜色,括号里的概念不变,括号外的称呼就得变化了,即使已经形成了习惯一直沿用下去,真实的内涵和字面的意思已经大相径庭。
这样的现象是正常的。正如第7章所说,涉众关注的是涉众利益,不关注系统需求,更不用说分析了。某类涉众的领域知识可能会很片面,对领域概念认识不深刻。怎么能寄望一个使用陌陌约会的屌丝青年清楚社交六度空间理论呢?
为了精确地使用领域术语,建模人员需要同时精通两方面的知识——领域知识和建模知识,才有可能得到深刻反映领域内涵的分析模型。缺少领域知识的建模好手固然比两方面知识都不具备的小白要好,但得到好模型的最大障碍还是对领域知识的理解不足。
这时,建模人员需要领域专家的帮助。帮助可以是直接的——建模人员和领域专家一起工作;也可以是间接的——建模人员阅读专业书籍。建模人员和领域专家两个身份可以合一,建模人员慢慢具备领域专家的能力,或者领域专家慢慢掌握建模技能。至于哪条融合的路线更好,没有标准的答案,应该视市场更需要 “懂软件技术的医学人士”还是“懂医学技术的软件人士”而定。
8.1.6.5 核心域透镜
为了避免核心域概念被非核心域概念掩盖,我们可以采用一种如图8-56所示的“核心域透镜”的思考方式,从核心域视角去看所有的事情。
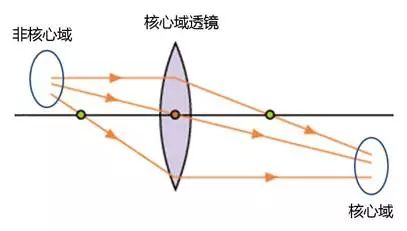
图8-56 用核心域透镜映射各种概念
例如,以“学习和考试”作为核心域,经过透镜前后的概念对比如图8-57。
原描述 |
映射后的核心域概念 |
原描述过去变体 |
原描述将来变体(猜想) |
Powerpoint |
演示工具 |
黑板、玻璃幻灯片、赛璐珞幻灯片 |
全息 |
检查IP地址 |
检查重复听课学生 |
看脸、看签名 |
检查新的协议地址 检查大脑芯片标识 |
点击“开始”按钮 |
开始考试 |
观察到考生开始书写 |
? |
向数据库“答题”表添加一条答题记录 |
答题 |
在答卷上涂黑一格 |
? |
图8-57 经过透镜前后的概念对比
再以上文提炼的UMLChina系统类图,即图8-58为例,被圈住的部分属于“发邮件”领域的概念。使用电子邮件的方式来通知学员举办公开课的信息,只是现在的手段。这个手段是变化的,过去也许是通过电话和传真,将来也许是通过短信、QQ和微信。如果通过“举办公开课”的核心域透镜映射,就可以得到“通知手段”、“通知”、“通知信息”、“联系方式”等相对于核心域更稳定的概念。这方面的改进会在下文的精化过程中进一步描述。
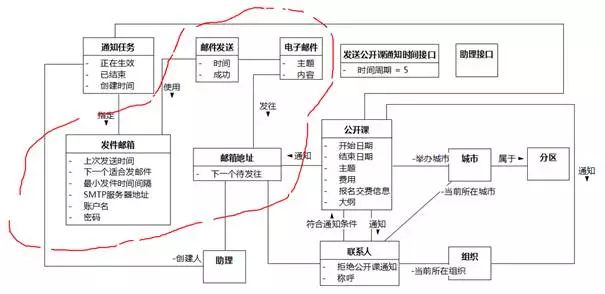
图8-58 当前的UMLChina类图中的非核心域概念(被圈住部分)
核心域透镜也有助于减少前文所说的开发人员迷恋“底层”的现象。例如要思考“电子邮件”的内涵,未必就是要思考SMTP、POP3/IMAP,从核心域透镜的视角看,思考关系链、信息载体等概念对开发好当前系统更有帮助。
8.1.6.6 属性要直接描述类
类和属性连在一起说"类的属性",应该能直接说得通,否则类和属性的搭配是不合适的。这个时候应该找到或建立合适的类,把该属性移进去。“属性要直接描述类”这个要求和关系数据库的第三范式“任何非主属性不依赖于其它非主属性”相似。
例如图8-59,“联系人的组织名称”中间隔了个“组织”,不能直接说通,需要添加一个“组织”类,把“名称”挪过去。

图8-59 属性要能直接描述类
在缺少抽象的“照猫画虎”式建模中,这种错误比较常见。例如,一张工作居住证上确实有该人员聘用单位名称。建模人员对照工作居住证,一项一项把它搬到类图上的类中。
如果确定每个联系人只就职于一个组织,而且系统只关注组织的名称,可以将“名称”合并到“联系人”成为一个属性“组织名称”,如图8-60。不过,如果以上的假设发生变化,这样的做法应变成本很高。

图8-60 特定条件下可以简化
要特别说明的是,习惯于关系数据库建模的建模人员有时会犯这样的错误,在一个类里放上另外一个类的属性作为“外键”。比如针对上面的例子,建模人员会想:“联系人”里放“组织名称”确实不合适,但是放个“组织编码”作为外键总可以吧?其实也不可以。"组织编码"是“组织”的属性,是封装在“组织”中的秘密,“联系人”不应该拥有“组织”的属性,它通过关联拥有“组织”对象,通过访问“组织”对象公开的操作间接访问“组织”的属性。
“联系人”里放“组织编码”不合适,放一个无意义的标识“组织ID”呢?同样也不可以。对象有标识,这是一个共识,而如何表达对象的标识,这是另一个领域的知识,而且实现规律和核心域知识无关。分析类中不需要主键、外键属性。
在设计工作流,需要把类图映射到关系数据库时,确实需要把"组织"表的主键(可能是"编码"也可能是系统生成的代理主键)放在"联系人"表中作为外键,但正如上文所说,这同样是另一个领域的知识,而且映射规律和核心域知识无关。
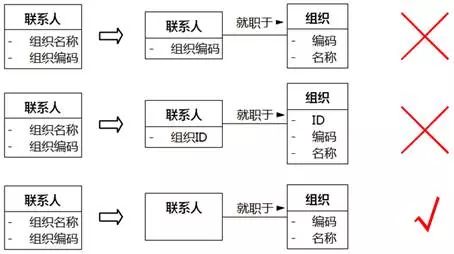
图8-61 不需要外键属性
下面我们用“属性直接描述类”检验规则检查一下UMLChina系统的例子:
(1)用例规约中提到“联系人当前所在城市所属分区与公开课举办城市所属分区相同”——“联系人”的“城市”的“分区”,需要如图8-62分解。
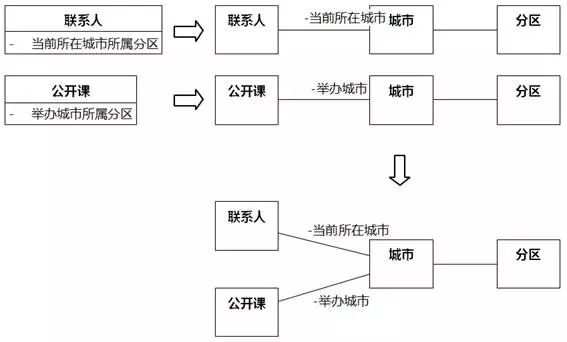
图8-62 分离不直接描述类的属性——UMLChina系统例1
(2)用例规约中“通知任务的创建人和创建时间”。实际上是“通知任务”的“创建事件”的“时间”、“通知任务”的“创建事件”的“创建人”,而这个创建人就是公司助理。此时应分解为三个类,考虑到一个通知任务只有一个创建事件和它关联,而且不考虑创建事件的其他属性,可以把“创建”合并到“通知任务”中,如图8-63。
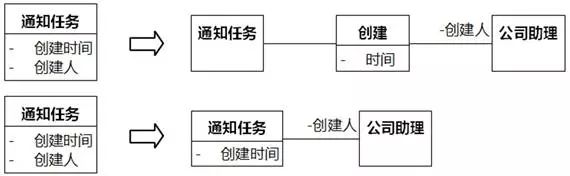
图8-63 分离不直接描述类的属性——UMLChina系统例2
有时,属性不直接描述类的情况比较隐蔽。如图8-58中的“公开课”类,说“公开课的主题”,“公开课的大纲”是可以的,但是实例化后会发现,很多“公开课”对象的“主题”和“大纲”是一样的,不同“公开课”对象的不同属性值主要体现在“开始日期”、“结束日期”和“城市”上。当发现针对一些属性,有很多对象的值相同,而且这些属性刚好组成了一个领域概念,应该分离出这个概念。如图8-64,可以分离出“课程”,把这两个属性移到“课程”中。
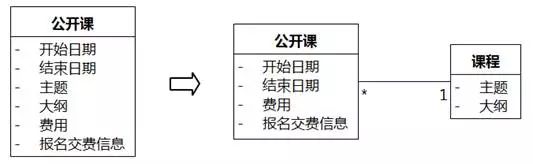
图8-64 分离有大量相同值的属性到另一个类——UMLChina系统例子3
这里经常会有异议,认为“公开课”也应该有“主题”和“大纲”属性,因为一门课程的主题和大纲会随时间变化,我们需要像快照一样,复制课程当时的属性值,记住在某时某地举办公开课时的主题和大纲,否则维护的信息是不真实的。如果按照这样的思路,和公开课关联的所有类的属性都需要复制到公开课中,因为联系人的姓名、城市的名称也会改变。再推下去,就需要一个巨大的类,把所有通过关联线连在一起的类的所有属性组合在一起。
应对这种情况的一种做法是针对特别需要关注的视图另外加报表类,例如“公开课通知”,这个报表类和“公开课”、“课程”不关联,而且对象的值不会变化。当然,如果一开始没有创建某个视图的报表,对象的值发生变化后,想从其他视图推导出该视图不一定行得通。
如图8-65所示,报表ReportA、ReportB、ReportC、ReportD记录了某个时间点A、B、C不同属性组合的情况。假设现在需要一种新的报表,里面包含属性a2,想要追溯某个时间点上a2相关的记录已经是不可能的。因为a2已经变化,其他报表没有保存下来。
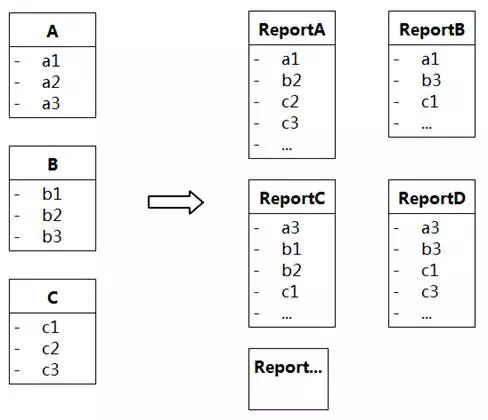
图8-65 从不同的类提取属性组成报表
但这样的情况也是正常的,系统仅仅需要映射领域的一小部分知识。比起记住“某个姓名曾经在某个城市名称上过课“来说,记住“某人曾经在某个城市上过课”更加本质。
如果要更充分地记录历史,可以针对“课程的主题和大纲发生变化”这个领域事实建模,也就是说,为对象建立不同的版本,或者记录对象所有的属性值变化,如图8-66。

图8-66 跟踪对象的属性值变化
(3)如图8-67所示,“发件邮箱”的“最小时间间隔”。这个“最小时间间隔”在很多“发件邮箱”对象中值相同,说明它其实不直接和具体每个发件邮箱相关,而是和发件邮箱的规格相关。例如,如果我们设定,针对1*3.com免费邮箱,发送邮件的最小时间间隔为70秒(通过了解该类邮箱的发件限制规则来推算这个时间值),那么就算注册了100个1*3.com免费邮箱,这个值都是一样的。同样,SMTP服务器、POP3服务器……等属性的值,也只和发件邮箱的规格相关,和具体的每个发件邮箱无关。应该分离出“发件邮箱规格”,和“发件邮箱”关联。
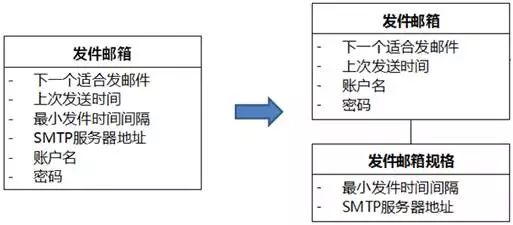
图8-67 分离有大量相同值的属性到另一个类——UMLChina系统例子4
前文提到有一种属性是状态属性。针对状态属性的检查原则刚好反过来——连在一起说"属性的类"应该能直接说得通。例如,“待举办”的“公开课”、“已通知”的“联系人”。严格来说,状态属性不是真正的属性,最后应尽量用状态机来封装状态转换的逻辑,然后删除状态属性。后文会专门阐述。
8.1.6.7 属性在本领域内不可以再分解
复杂属性
如果属性再分解就得到其他领域的概念,那么这个属性可以留在类中。如果可以继续分解成本领域的概念,可以考虑把这个属性独立出去变成另一个类。
如图8-68中,"联系人"的"称呼"属性的类型是String。String属于基础语义领域,已经不属于人员管理领域,那么"称呼"可以留在“联系人”中作为属性存在,而"组织"还可以像右侧所示分解成“名称”、“办公地址”等,这些概念依然属于人员管理领域,所以可以考虑将“组织”分离为一个类,“联系人”关联到“组织”。
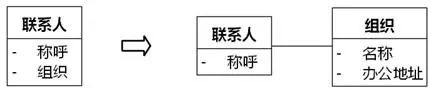
图8-68 分离可以在本领域内分解的属性
注意:分离或不分离的理由是“是否另一个领域”而不是“是否简单”。就拿“称呼”分离到String来说,String其实不简单。以.NET Framework 4.5为例,其中的String类有123个操作,远远超过人员管理领域程序员编写的某个类所拥有的操作。
多重性大于1的属性
另一种可以再分解的形式是多重性大于1的属性。例如,一个人员会有多个电话,如果放在“人员”类中作为“电话1”、“电话2”、“电话3”……属性,该类的很多对象的“电话3”属性可能会出现空值,或者放不下更多的电话号码,还有人会建模成一个“电话”属性,属性值里用逗号分隔各个电话号码,这样也模糊了属性的含义。此时应该把多重性大于1的属性分离到另一个类,设置要进一步抽象,如图8-69。
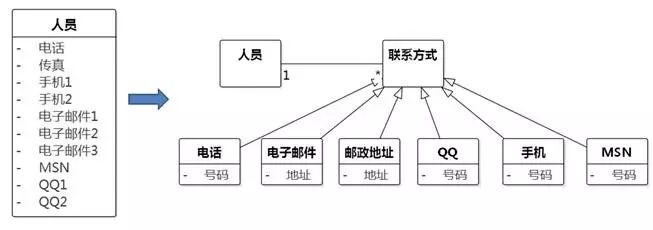
图8-69 分离多重性大于1的属性
有的建模人员会在“人员”里放上一个数组或列表,这样做也是不对的。人员有多个电子邮件,这是一个领域的知识;用编程语言如何实现一对多的关联,是另一个领域的知识。
8.1.6.8 属性对所有对象都有意义
前文说到“类的属性”的检验规则如果说不通,那么类和属性放在一起是不合适的,但这只是必要条件,不是充分条件,即使说得通也未必合适。如图8-67,人的姓名,人的▲▲(▲▲是男性特有的器官),人的〇〇(〇〇是女性特有的器官)好像都说得通,但如果问:是不是所有对象都应该有这个属性呢?得到的答案就不同了。
是不是所有人都应该有姓名——是。
是不是所有人都应该有▲▲——不是,只有一部分人有。
是不是所有人都应该有〇〇——不是,只有一部分人有。
说明“人”发生了分裂,分裂成“男人”、“女人”两个子集(子类)。
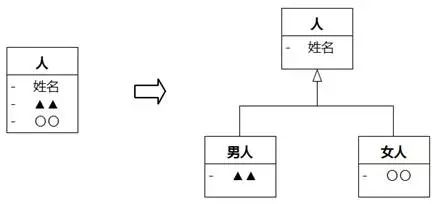
图8-67 分解只属于部分对象的属性到子类
扫码或访问http://www.umlchina.com/book/quiz8_1_2.htm完成在线测试,做到全对以获得答案。

1. 为什么面向对象分析设计方法比面向过程好? A) 面向对象更适合人脑去把握系统的复杂性 B) 面向对象和需求的映射更直接 C) 面向对象方法更容易掌握 D) 面向对象更符合计算机的底层 2. 以下给类和属性命名,最合理的是__________ A 3. 以下说法正确的有(多选): A 实体-关系图和数据流图也可以描述分析模型 B 和设计工作流的对象相比较,分析工作流的对象的特点是仅存在于内存中,不保存到硬盘 C 每个用例映射一个分析边界类 D 识别分析类时,精力应该重点放在实体类上 E 识别分析类时,类名称以涉众常用的称呼为准 F 系统外部有执行者,使用面向对象方法分析,系统内部一定有相应的实体类 4. 铁路售票处,售票员使用售票系统来售票,在用例进行过程中,系统需要不断向旅客反馈车次、车票和价格信息,系统还需要和银行系统交互。"售票"用例的分析序列图中,会出现_____个边界类,_____个控制类,_____个实体类。 A) 1,2,3 B) 3,1,2 C) 不定,1,3 D) 3,1,不定 E) 3,2,3 F) 3,1,3 G) 不定,1,不定 H) 3,3,3 5. 从以下用例规约抽取类,哪些类应该抽取出来? 游客选择航线、航期, 系统显示该航期的剩余仓位。 游客选中仓位所在层, 系统显示该层平面图。 游客选择仓位, 系统验证该仓位可以预订, 系统保存仓位预订, 系统提示预定成功。 A) 层 B) 仓位保存 C) 航线 D) 仓位验证 E) 系统 F) 仓位 6. 当我们把待开发系统称为“系统”时,说明我们在思考________问题: A 业务建模 B 需求 C 分析 D 设计 7. 当我们把待开发系统称为“UMLChina系统”时,说明我们在思考________问题: A 业务建模 B 需求 C 分析 D 设计 采购单-零件编号 上面这段文字还用来提醒一些反驳说“容器”、“框架”的实现很复杂的开发人员,想想,你是用框架、容器的,还是做框架、容器。对,它博大精深属于它自己,你有你自己的博大精深。 8. 要实现验钞机的“验钞”功能,恰当的抽象是? A) B) C) D)
|





8.2 步骤3-2 识别类之间的关系
目前我们已经得到的工作成果是图8-46。接下来,我们开始讲解如何识别类之间的关系。
首先要说明的是:先识别类和属性、再识别类之间的关系这个思考顺序只是一个微小的思考周期内的顺序,而要建模一张类图,需要很多个思考周期。也就是说,识别类和属性→识别类之间的关系→识别类和属性→识别类之间的关系→……是交错进行的。阅读用例规约或其他素材,一边思考一边建模,不管识别出类、属性还是关系,画上去就是,并不需要假装看不见类的关系先只识别类和属性,等画完了类和属性再识别类之间的关系。
类之间的关系有三种:泛化(Generalization)、关联(Association)和依赖(Dependency)。依赖是一个大杂烩。可以这样认为,如果B变化,A也需要变化,但A和B之间没有泛化或关联关系,那么A依赖于B。
8.2.1 泛化和关联的区别
泛化和关联是面向对象的两种基本复用机制。在泛化关系中,子类通过继承超类而拥有超类的特征;在关联关系中,对象通过组装其他对象而拥有其他对象的特征。如图8-68所示。
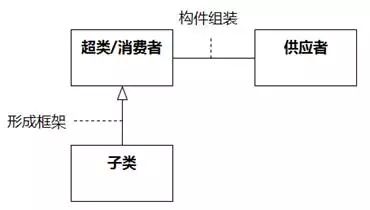
图8-68 面向对象的两种基本复用机制
泛化表示集合关系,两个类形成泛化,意味着超类的对象集合包含了子类的对象集合;而关联表示个体关系,两个类形成关联,意味着一个类的对象个体组装了另一个类的对象个体。如图8-69所示。
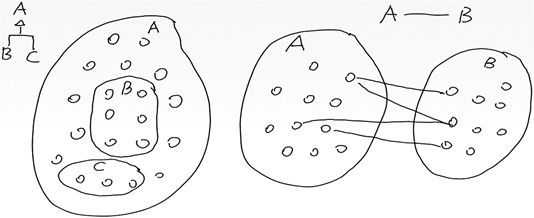
图8-69 泛化和关联的本质区别
集合关系还是个体关系,这是泛化和关联的本质区别。仅仅从自然语言的表达来推断,很多时候是不可靠的。
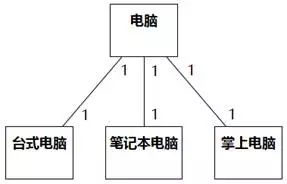
例如,自然语言"人有男有女"说的是泛化关系。因为意思不是一个人的个体组装了若干男人个体和若干女人个体,而是说人的集合包含了男人的集合和女人的集合。但是,自然语言"人有手有脚"说的却是关联关系。因为意思不是人的集合和手、脚的集合有包含关系,而是说一个人的个体组装了若干手和脚的个体。您可以自行体会一下“人有车有房”和“人有高富帅有屌丝”的区别。
对于比较熟悉的领域,例如刚才的男女手脚,拍脑袋就可以知道是泛化还是关联,那拍脑袋就可以了。如果进入陌生的领域,有时回溯到集合和个体的本质区别是必要的。下面列举一些错例参考。
泛化被误作关联的情况是比较多的:
图8-70中,“员工有调度员、装卸工、配货员”指的是员工的对象集合包含了调度员、装卸工、配货员的对象结合,不是指一个员工对象由调度员对象、装卸工对象、配货员对象构成。正确的关系是右侧的泛化关系,而不是左侧的关联(此处是组合)关系。
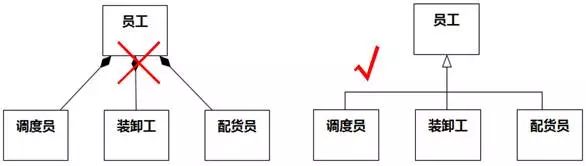
图8-70 泛化被误作关联 例1
很多系统经常需要设置一些参数,有人会把参数建模成图8-71左侧的类图,把超时时间、锁定设置、频带等作为参数的属性。属性其实就是关联(此处是组合)的一种变体,8-71左侧和右侧是等同的。
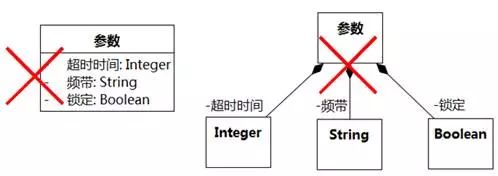
图8-71 泛化被误作关联 例2
图8-71的意思是一个参数个体由若干个具体参数个体组成,这不符合领域内涵。更符合领域内涵的是“具体参数是参数的一种”或者“参数的集合包含各具体参数的集合”,也就是说,泛化关系更合适。还有一种做法是把具体的参数全部抽象为“名称”和“值”两个属性。如图8-72。
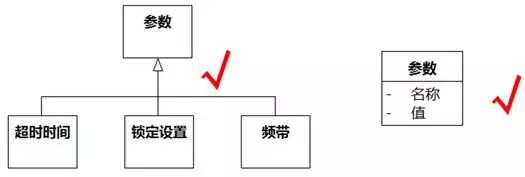
图8-72泛化被误作关联 例2 更正
如果按图8-71的方式建模,参数类只有一个对象,但这个对象有很多个属性。当需要为系统设置一种新的参数时,就需要修改类结构,增加新的属性。如果按图8-72的方式建模,只需要增加新的参数对象即可,类结构不需要改变。
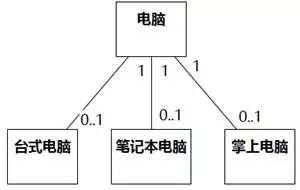
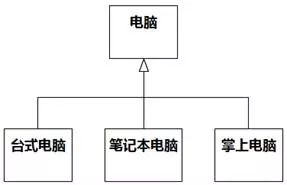
一些1对0..1的关联,有可能是泛化关系。例如,有人认为1台电器可以是1台洗衣机,也可以不是;1台电器可以是1台电视机,也可以不是;1台电器可以是1台空调,也可以不是,于是画出图8-73。
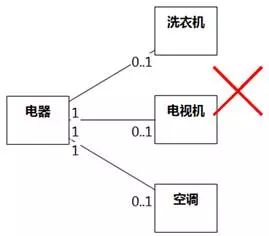
图8-73的意思是一台电器可能由一台洗衣机、一台电视机、一台空调组装而成,这是错误的,应该是电器的集合包含洗衣机、电视机和空调的集合,即泛化关系。如图8-74。
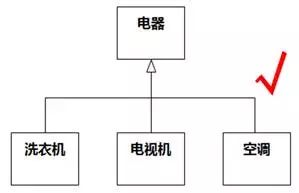
图8-74 泛化被误作关联 例3 更正
关联被误作泛化的情况:
几个类拥有相同的部分时,有人可能会把相同的部分变成超类,和这几个类形成泛化关系。如图8-75,经理、组长和组员都有账户,于是把账户提升为超类,意思是“经理是账户的一种”或“账户的集合包含经理的集合”,这是错误的。
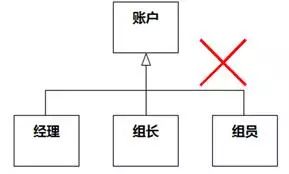
图8-75 关联被误作泛化 例1
经理和账户的正确关系应该是关联(此处是组合),即使有泛化关系,也应该抽象出更合适的领域概念,例如“人员”,如图8-76。
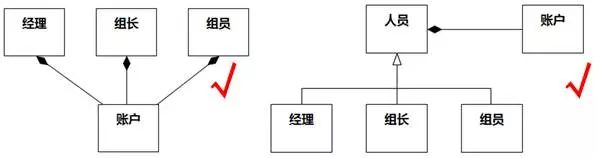
图8-76 关联被误作泛化 例1 更正
图8-77是Meilir Page-Jones在他的书中举的一个极端的例子。
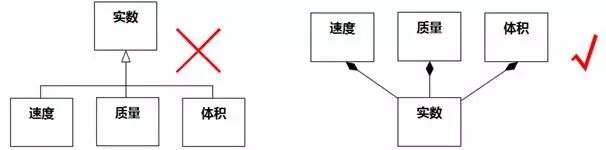
图8-77关联被误作泛化及更正 例2
8.2.2 识别泛化关系
8.2.2.1 识别泛化的思路
直接形成
首先,类图中的两个类可能会直接形成泛化关系,如图8-78所示。严格的做法是针对每两个类,思考“A是B的一种吗?”,再反过来思考“B是A的一种吗?”不过如果真的要这样做,工作量还是挺大的。类图中有n个类,就需要思考2C2 n=n(n-1)次。n=11时,就是100次了!实际工作中,往往是先扫描一遍,大脑迅速过滤出可能值得这样思考的类,针对这些类思考即可。
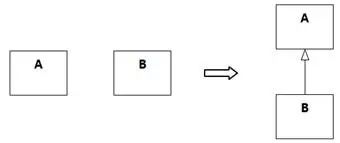
图8-78 直接形成-两个类之间直接形成泛化关系
像图8-78这样,类图上已有的两个类有泛化关系但未识别的情况并不多,因为之前从用例规约识别类和属性时很有可能已经发现了。
自下而上(从特殊到一般)
更多的情况是发现类图上已有的两个或多个类有共同特征,于是抽象出共同的超类,如图8-79所示。
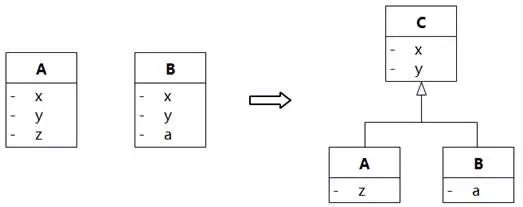
图8-79 自下而上-两个类之上有共同的超类
以UMLChina案例项目的领域为例,可能会存在如图8-80的自下而上的识别过程:
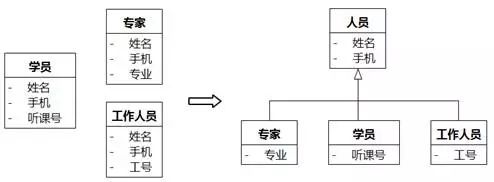
图8-80 自下而上识别泛化 例子
关联实际上就是扩展的属性,如果多个类关联到同一个类,也可以考虑泛化出共同的超类。
自上而下(从一般到特殊)
如图8-81所示,这个识别思路就是“8.1.6.8 属性对所有对象都有意义”里的思路,此处就不再重复叙述。
图8-81 自上而下-一个类分裂出子类
人类认识世界的过程就是自上而下(从一般到特殊)的过程。例如对生物的认识,原始人的概念很简陋,第一部辞书《尔雅》中已有简单的分类:草木虫鱼鸟兽,今天的生物分类学按域、界、门、纲、目、科、属、种分层,已经达到一个庞大的数字。
8.2.2.2 泛化进一步讨论
8.2.2.2.1 Liskov替换原则相关问题
可能您已经从一些书上看到过如图8-82的矩形和正方形问题,有时这个问题被换成椭圆和圆。
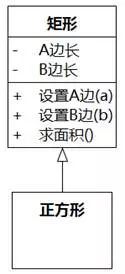
图8-82 被广泛讨论的正方形矩形问题
图8-82中,正方形是矩形的子类。按照设想,设置矩形的A边长为4,再设置B边长为5,此时求面积得到4×5=20,但如果正方形的面积是20,边长应该是√20=2√5才对。
矩形和正方形的问题经常伴随着Liskov替换原则(LSP)的讨论。LSP是Barbara Liskov在1988年提出的关于基类型和子类型的原则[Liskov 1988],原文如图8-83所示。Bertrand Meyer[Meyer 1997]使用契约的观点解释了为什么正方形和矩形之间泛化关系违反了LSP:子类操作的后置条件弱于超类。

图8-83 Liskov替换原则的原文
关于如何纠正,也有很多方案,但大多数是从实现技巧的角度来解决问题。我们尽量从领域知识的角度看问题。
矩形的定义是:至少有三个内角是直角的四边形。由此衍生的性质有:对边平行且相等、对角线互相平分且相等、面积=长×宽……这些是矩形的共性,没有问题。之所以出现冲突,是因为我们不知不觉地把常见矩形的特征(邻边可以不等长)当成了所有矩形的共性。更合理的泛化关系应该如图8-84所示。
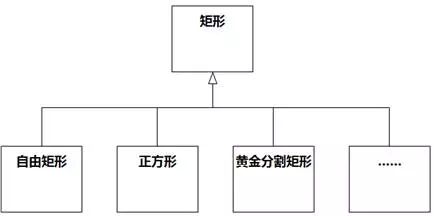
图8-84 更合适的矩形类层次结构
在图8-84中,正方形不是自由矩形的一种。自由矩形、正方形和黄金分割矩形(边长比为黄金分割比0.618····:1)等是互相不重叠的矩形子集(子类),而且各子集的并集等于超集(超类)。如果能遵循这样的思路,那么建立的泛化关系应该符合Liscov替换原则。
矩形对象的属性是封装的,外部调用者只能通过公开的操作修改和访问属性,如“设置A边(a)”、“设置B边(b)”、“计算面积()”等。
操作和属性不一一对应也不应该一一对应,这是面向对象的优点。对于有些矩形来说,“设置A边(a)”操作只是给A边长赋值为a,而对另一些矩形来说,“设置A边(a)”操作既修改了A边长,也修改了B边长,甚至有的矩形还不让修改呢!
以更常见的“银行账户”类来举例更容易帮助理解。“银行账户”类有一个属性“余额”,但对外不能提供“修改余额(金额)”、“修改状态(状态)”等操作,应该提供的是“存款(金额)”、“取款(金额)”等。
当外部调用者向“银行账户”对象发送“取款(2000)”消息时,引起“银行账户”对象内部的变化不仅仅有(1)余额减少了相应金额,可能还要有:
(2)减去0.1%的手续费;
(3)如果余额已经低于某个设置值,某个在内部表示状态的属性值会改变;
(4)创建一个和该账户关联的“交易”对象记录取款的细节。
改进后的矩形类图可以如图8-85所示。超类中实现“求面积”,但不实现“设置A边(a)”、“设置B边(b)”的操作,留给子类来实现。
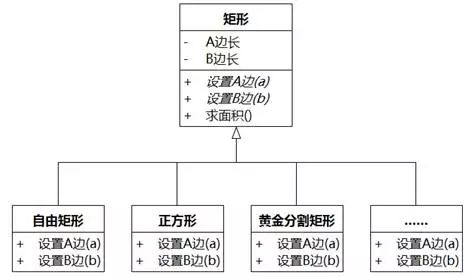
图8-85 改进后的矩形泛化类图
或者如图8-86,把超类“矩形”到底保留几个边长属性以及如何求面积的实现下放到子类。这样的处理相当于把邻边互有依赖的领域知识放在属性中,而不是放在操作中。
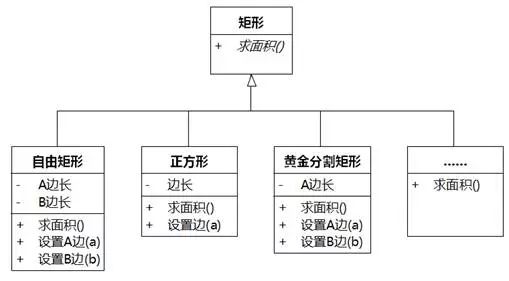
图8-86 另一种矩形类图
在日常应用中也有类似于矩形和正方形的情况。例如,会员的Email和QQ可以自由变化,但有一种会员,我们姑且称为“腾讯专属会员”,他的Email只能用他QQ号下的QQ邮箱,Email和QQ两个属性之间有依赖,那么图8-87左侧关系是不合适的,应该改为右侧的关系。
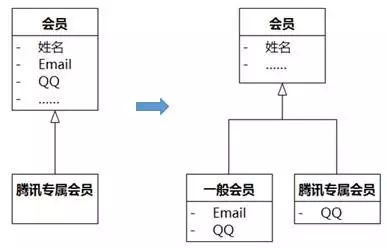
图8-87 会员和腾讯专属会员
8.2.2.2.2 尽量不要跨领域使用泛化关系
分析工作流的类建模关注的是核心域概念及其关系,但有时候建模人员会不自觉地引入非核心域的内容。例如,若干学员组成小组,建模人员想到了如何实现小组有多个学员的问题,决定用List来实现,于是有图8-88。
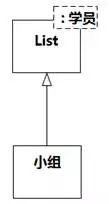
图8-88 通过泛化来复用另一个领域
图8-88的问题是把本来应该隐藏在背后的非核心域概念显式引入到核心域类图中。前文已经说过,域之间的映射往往是有规律的,即使实现时由于某种偏好就是要通过泛化来复用,也没有必要逐一画出来。当然,更合理的实现是通过关联来复用List,如图8-89所示。
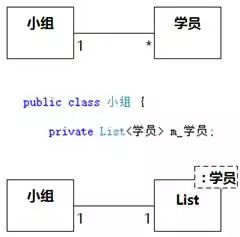
图8-89 通过关联来复用List
8.2.2 识别关联关系
8.2.2.1 关联的三种形式
UML规定了关联的三种形式:普通关联、聚合(Aggregation)和组合(Composition)。
说到这里,我们有必要归纳类的关系如图8-90。
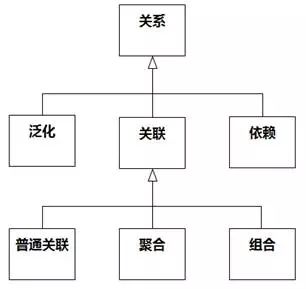
图8-90 类的关系
有些书和文章里提到“泛化和组合”,其实是不合适的,因为泛化和组合不在一个抽象级别上。说“泛化和关联”可以。
在图形表示上,普通关联是一根直线,聚合的整体一端是空心菱形,组合的整体一端是实心菱形。
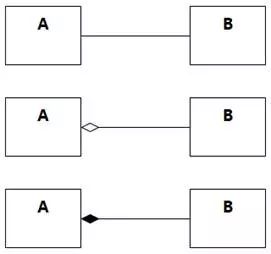
图8-91 三种关联的图示
当然,更重要的是含义不一样。之所以分出聚合/组合这样的特殊关联,考虑的出发点是责任分配。通过建立这种关联,使整体把部分封闭起来。在责任分配时,不管外部对象想要发消息给聚合/组合结构里的哪一个对象,都应该先把消息发给整体对象,再由整体对象分解和分配给聚合/组合里的对象。
类图上会有很多类,类之间关系的密切程度不一样。有些类相互之间关系更密切,当推断或观察到这些类之间的协作的频率远超过它们和外部其他类的协作频率时,通过聚合/组合来封装它们是合算的,因为这样可以大大减少外部对这些类调用的复杂度。
引入聚合/组合,相当于把类图分区,每个区找一个区长作为责任分配的起点。这是一项十分重要的分析技能。例如图8-92就是一张餐饮领域的类图,可以看出右上角“顾客”分区的领域概念和左上角“餐台”分区的领域概念所受的影响因素应该有较大差别。
聚合/组合和公司的部门划分类似。公司不划分部门,老总一个个员工派任务也能达到目标,只是效率不高,而且不管出现什么改变都要打开老板的“代码”来修改。分了部门之后,老板就爽多了,只需要和部门经理打交道。当然,分部门也不能乱分,否则效果还不如不分。如果公司分了部门之后发现部门内部员工之间交互甚少,反倒是串门的很多,那很可能公司的部门分割是乱点鸳鸯谱了。
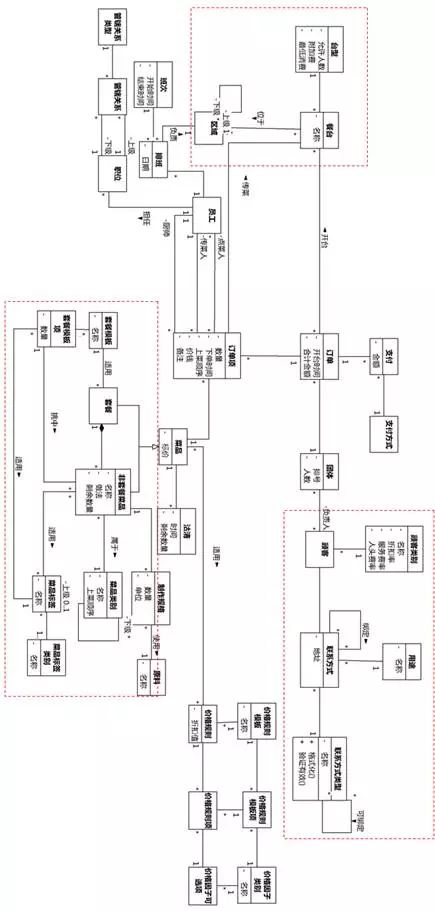
图8-92 餐饮领域类图分区
上面关于责任分配的描述,对于聚合和组合都是合适的,所以表达时使用的是聚合/组合。那么,聚合和组合的区别是什么?
组合可以看作是更强的聚合,相对于聚合来说,组合还要满足以下要求:
(1)整体对象被销毁,部分对象也要销毁;
(2)部分对象只属于一个整体对象;
(3)整体对象负责部分对象的创建和销毁。
也就是说,部分对象只应该作为整体对象的一部分存在,不应独立存在,所以部分类的命名往往有整体类的味道,如图8-93所示,“订单”和“订单项”之间的关联是组合,但接下来的“订单项”和“商品”之间的关联不是组合;同样,“报告”和“报告审核”之间的关联是组合,但接下来的“报告审核”和“人员”之间的关联不是组合。
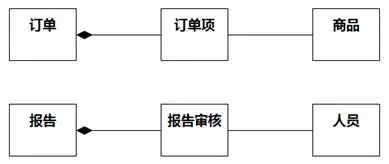
图8-93 部分类的命名有整体类的味道
如果暂时无法确定聚合还是组合合适,那么可以先通通建模为聚合或组合,后面有足够证据时再修改。
聚合/组合务必慎用。如果没有足够的证据,应该先建模为普通关联。有的建模人员懒得给普通关联想合适的名字,干脆一概以“有”称之,例如“订单有顾客”,然后得到错误的聚合/组合关系,如图8-94所示。
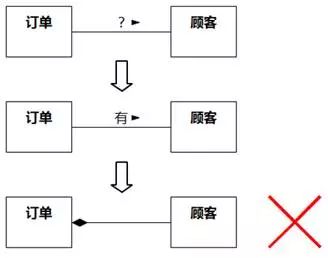
图8-94 错误的聚合/组合关系
8.2.2.2 识别关联的思路
之前在审查类和属性时,“属性要直接描述类”和“属性在领域内不可分解”这两种审查已经演变出了一些关联关系。
接下来识别关联也没有什么妙招。和识别泛化一样,严格的做法同样是针对每两个类思考系统是否要维护两者之间的关联,如果需要,再思考是否有明显的证据判断其为聚合/组合,然后再考虑多重性、关联名、角色名。
这样做也同样有工作量巨大的问题,所以一般来说只需要凭借对领域的理解,迅速定位最应该建立的关联。如果有遗漏,后面画分析序列图时也会发现。
8.2.2.2.1 关联是系统维护的关系
万事万物之间如果想找关系,总能找到关系的,但所研究系统需要关注的只是千万关系中的一小部分。只有所研究系统负责维护的关系,才有资格变成关联。
“8.1.6.4 切勿照猫画虎”里提到的“类图长得像用例图”的图8-52,有可能也错把系统不需要维护的关系当成了关联。系统很可能不需要记住哪个顾客查询过哪件商品,类似的情况还有,系统很可能不需要记住哪个顾客查询过哪张订单。如图8-95所示。
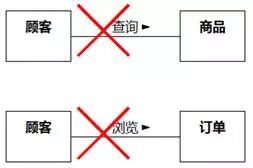
图8-95 系统不维护的不算关联
如果系统确实要维护查询和浏览的信息,两个类之间的关联当然可以存在,不过未必是直接关联,很可能是像图8-96。常见的电子商务系统中,需要维护的应该是图8-96上部的三个类:顾客、查询和查询条件,这样顾客可以反复使用之前设置过的查询条件。
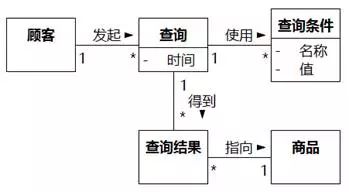
图8-96 顾客和商品之间的查询
8.2.2.2.2 关联名或角色名
如果问一位习惯于数据库建模的建模人员“A和B是什么关联”,他可能会回答“是一个一对多的关联”,因为他觉得说出关联两端的多重性就足够详细了。
在类建模中,关联的名字和角色的名字是很重要的。除非某个关联的名字已经一目了然,不会造成误解,否则应该尽量加上关联名或角色名,这样模型更能够讲出领域的故事。如图8-97,关联名和角色名串起几个类的概念,生动地展示了领域知识。
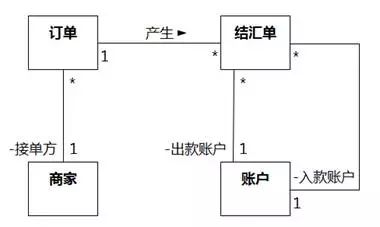
图8-97 模型要能讲故事
至于采用关联名还是角色名来描述关联,如果角色名更能说明问题,那么角色名优先。因为角色名在实现中往往会映射为变量名。特别是当两个类之间有多种关联的时候,通过角色名区分是必须的。如图8-98所示。
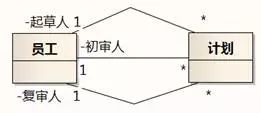
图8-98 两个类之间有多种关联
聚合/组合关联经常被认为不需要关联名或角色名,其实也是需要的。如图8-99。
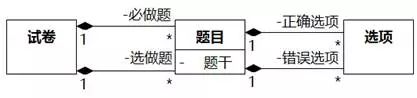
图8-99 聚合/组合的角色名
如果是给关联命名,最好给名称添加一个阅读方向,如图8-100所示,方向指示领域知识为“订单产生结汇单”。不过要注意,这个阅读方向只是为了方便理解领域知识,和关联的导航方向没有关系。有的建模工具不支持标注关联方向,可以通过统一偏向某一侧来表达阅读方向。
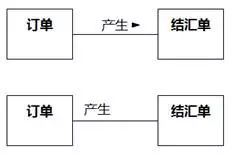
图8-100 关联名称的阅读方向
8.2.2.2.3 多重性
多重性表示关联两端允许的对象的数量,可选的表达如图8-101。
表示 |
含义 |
1 |
1 |
0..1 |
0到1 |
* |
0到多 |
1..* |
1到多 |
具体数字如2..8 |
2到8 |
图8-101 可选的关联多重性
很多建模人员纠结于“1”还是“0..1”好,“*”还是“1..*”好,过早分散了精力。一般来说,使用“1”(涵盖“1”和“0..1”)和“*”(涵盖“*”和“1..*”)就可以。当关联一端是“1”,另一端是“0..1”时,再强调“1”和“0..1”的区别。
对于多重性,建模人员容易出现的问题是把不同时间的对象快照合并成一个。例如,男人和女人可以有夫妻关系,那夫妻关系的多重性是多少?中国是一夫一妻制度,按道理应该1对1,如图8-102左侧。但有的建模人员会想,不对呀,有的人一生结好几次婚,那不是有几个配偶吗?是否应该如图8-102右侧?


图8-102 夫妻关联的多重性
图8-102左侧是正确的。在任何时间拍摄快照,拍到的应该是一个男人最多和一个女人有夫妻关联。即使有其他女人,当时的夫妻关联应该已经断开了,如果要表达关联,只能叫“前妻”。如图8-103所示。在某个时间拍快照,是有可能拍到一个男人存在多个前妻的。

图8-103 一个男人存在多个前妻
扫码或访问http://www.umlchina.com/book/quiz8_2_1.htm完成在线测试,做到全对以获得答案。

1. 类之间的关系有 A 扩展、包含、泛化 B 泛化、关联、依赖 C 请求、验证、回应 D 连接、聚合、组合 2. 区分泛化和关联的根本要点是 A 泛化是静态关系,关联是动态关系 B 泛化关注继承,关联关注包含 C 泛化是集合关系,关联是个体关系 D 泛化关注销售,关联关注成本 3. 是否采用"聚合/组合"关联,考虑的出发点是: A 对责任分配有帮助 B 人类语言表达上"A拥有B"能说得通 C 关联两端的多重性 D 类的属性个数 4. 以下类关系表达正确的是 A) B) C) D) 5. 以下说法正确的是: A) 不需要先识别出所有的类,再识别类之间的关系 B) 如果A变化,B也需要变化,那么A依赖于B C) 自然语言中带有“A有B”的描述,可以判断A和B是关联关系 D) 从用例规约的各个部分都有可能提炼出分析类 6. 以下犯了“把泛化当作关联”错误的是: A B C D 7. 关于影评网站“逗瓣”,针对以下概念之间的关系描述最合理的是: A) B) C) D) |




[1] 《软件方法》第六章已讨论过开发人员话语中“技术”一词的狭隘。
[2]当然,可以以Office为开发工具做二次开发,但此时使用的系统已经不是Office而是核心域的应用系统。
[3] ( a、b、c都大于时肯定成立)
[4] C#有一种实现套路是直接写Property,后文再评述这样的实现。
[5]有人提出一种改进的脑补方法——结对脑补,美其名曰“结对编程”。
http://www.umlchina.com/training/course180310.htm
3月10-11日(周六、周日)上海软件需求设计UML全程实作公开课
http://www.umlchina.com/training/course180317.htm
3月17-18日(周六、周日)广州软件需求设计UML全程实作公开课
http://www.umlchina.com/training/course180324.htm
3月24-25日(周六、周日)北京软件需求设计UML全程实作公开课