从理论到实战,一篇文章掌握推荐系统之矩阵分解
十年前,Netfliex 发起了 Netflix 奖公开竞赛,目标在于设计最新的算法来预测电影评级。竞赛历时 3 年,很多研究团队开发了各种不同的预测算法,其中矩阵分解技术因效果突出从众多算法中脱颖而出。
这篇文章有两个目的:
介绍如何用矩阵分解来建模电影评级。我将用具体的例子来阐述 PCA 和 SVD 的工作原理。你可能已经读过一些解释,譬如用户和项目被表示为潜在因子向量空间里的向量,评级被定义为两个向量之间的点积。如果你还不太理解这些概念,希望你在读完这篇文章后能明白其含义。
派生和实现一种基于矩阵分解预测评级的算法。该算法很简单,仅需要 10 行 Python 代码。我将应用该算法并在实际数据集上评估它的性能。
我试图让本文的数学内容通俗易懂,但不会过于简化,同时我也尽量避免枯燥的语句。我希望本文对机器学习初学者有所帮助,对有经验的人而言有所见解。
这篇文章分为四部分。第一部分清楚地定义了将阐述的问题,提出了一些对 PCA 的见解;在第二部分,我们将回顾 SVD,看看它是如何对评级建模的;第三部分展示了如何将 SVD 知识应用于评级预测中,并派生出一个基于矩阵分解的预测算法;在最后一部分,我们将调用 Surprise 库,用 Python 代码实现一个矩阵分解算法。
在这里,我们将谈论的问题是评级预测问题。我们的数据是评级历史数据,即用户对项目的评级,值区间是 [1,5]。我们可以把数据放在一个稀疏矩阵 R 中:

矩阵的每一行对应一个给定用户,每一列对应一个给定项目。譬如,在上面的矩阵中,Alice 对第一个项目的评级是 1,Charlie 对第三个项目的评级是 4。在我们的问题中,我们将认为项目是电影,在后面会交替使用“项目”和“电影”这两个术语。
矩阵 R 是稀疏的(99% 以上的内容是缺失的),我们的目标是预测那些缺失的内容,即问号处的值。
有很多不同的技术可用于评级预测,在这里我们将分解矩阵 R。该矩阵分解与 SVD(Singular Value Decomposition,奇异值分解)是根本相关的。SVD 是线性代数的亮点之一。它的结果很美丽。如果有人告诉你数学很差劲,你可以向他们展示看看 SVD 能做什么。
这篇文章的目的在于解释如何能将 SVD 用于预测评级。但在我们进入第二部分的 SVD 之前,我们需要回顾一下什么是 PCA。PCA 只稍稍逊色于 SVD,但也仍然很酷。
让我们暂时忘记推荐问题。我们将用到 Olivetti 数据集,它是 40 个人的脸部灰度图像集,一共有 400 个图像。第一组 10 个人的图像如下:

每一个图像的大小是 64 x 64 像素。我们将扁平化每个图像,于是可以得到 400 个向量,每个向量里有 64 x 64 = 4096 个成员。我们可以将数据集表示为一个 400 x 4096 矩阵:

PCA(Principal Component Analysis,主成分分析)算法可以将 400 个这样的人展现为下面的图:

看起来很恐怖吧?
我们将这些人叫做主成分,他们所代表的脸部图像叫做特征脸部。可以用特征脸部做很多有趣的事情,如脸部识别或优化 tinder 匹配。它们之所以被叫做特征脸部,是因为它们实际是 X 的协方差矩阵的特征向量(这里我们不会给出细节,感兴趣的读者可以参看文末的参考文献)。
这里,我们获取了 400 个主成分,因为原始的矩阵 X 有 400 行(更确切的说,是因为 X 有 400 个评级)。你可能已经猜到,每一个主成分实际上是一个向量,与原始的脸部有着相同的维度,即有 64 x 64 = 4096 个像素。
我们会把这些图像叫做“令人毛骨悚然的图像”。现在,关于它们的一个惊人的事情是,它们可以恢复所有的原始面孔。
让我来解释下怎么回事。400 个原始脸部中的每一个(即矩阵的 400 个原始行中的每一行)可以表示为这些令人毛骨悚然的图像的(线性)组合。也就是说,我们可以将第一个原始脸部的像素值表示为第一个图像的一小部分,加上第二个图像的一小部分,再加上第三个图像的一小部分,等等,直到最后一个图像。这一方法对其他原始脸部也适用:它们都能被表示为每一个令人毛骨悚然的图像的一小部分。我们可以将其表示为数学的方式如下:

我们做了一个动态图,正是对这些数学公式的翻译:gif 的第一帧是第一个令人毛骨悚然的图像的贡献,第二帧是第二个令人毛骨悚然的图像的贡献,等等,直到最后一个。
如果你想尝试重现这些动态图,我写了一个 Python notebook(http://nbviewer.jupyter.org/github/NicolasHug/nicolashug.github.io/blob/master/assets/mf_post/creepy_guys.ipynb)。
注意:用那些令人毛骨悚然的图像来表示原始脸部,这一点并没有什么特别的。我们可以随机选取 400 个独立的向量(每个向量是 64 x 64 = 4096 像素),仍然能够重现这些脸部。降低维度是让这些令人毛骨悚然的图像在 PCA 中变得特别的原因,我们将在第三部分讨论这个问题。
实际上,我们对这些令人毛骨悚然的图像有些过于严厉了。它们其实并不恐怖,反而很典型。PCA 的目标就在于揭示典型的向量,每一个图像代表着隐藏在数据下的一个特征。理想情况下,第一个图像将代表譬如一个典型的年长一些的人,第二个图像将代表一个典型的滑头滑脑的人,而其他图像可以代表一些如喜欢微笑的人、表情悲伤的人、有着大鼻子的人等等概念。有了这些概念,我们可以将脸部定义为或多或少年长、或多或少滑头滑脑、或多或少微笑,等等。实际上,PCA 所揭示的概念并没有那么清晰,没有一个清楚的语义能让我们像在这里一样把任何令人毛骨悚然的图像或典型图像相关联起来。但是,有一个重要的事实是,每一个图像捕获了数据的某一个特征。我们把这些特征叫做 潜在因子(潜在,是因为它们一直在那里,我们只需要用 PCA 来揭示它们)。即每个主成分(令人毛骨悚然的或典型的图像)捕获一个特定的潜在因子。
到目前为止还是挺有趣的,但是我们其实是对用矩阵分解进行推荐感兴趣,对吧?那么我们的矩阵分解在哪里,它与推荐有什么关系? PCA 实际上是即插即用的方法,它适用于任何矩阵。如果矩阵包含图像,它将显示一些典型的图像,从而构建出所有原始图像。如果矩阵包含土豆,PCA 将显示一些可以恢复所有原始土豆的典型土豆。如果你的矩阵包含评分,那么接下来我们来看看怎么做到。
除非另有说明,我们的评级矩阵 R 是完全密集的,即没有缺失的内容。所有评分都是已知的。这当然不是实际推荐问题中的场景,但请先按这样假设。
我们的评级矩阵如下所示,行代表用户,列代表电影:

看起来是不是很熟悉? 我们没有用像素来表示每一行的脸部,相反,现在我们用评级来表示用户。就像之前 PCA 给出一些典型的图像,现在它将给我们一些典型的用户,或者一些典型的评价者。
在理想情况下,与典型用户相关的概念将具有明确的语义含义:我们将获得典型的动作电影迷、典型的浪漫电影迷、典型的喜剧迷,等等。实际上,典型用户背后的语义并没有被明确定义,但为了简单起见,我们假设它们如此(这不会改变任何东西,只是为了便于解释)。
于是,我们的每个初始用户(Alice,Bob 等)可以表示为典型用户的组合。例如,Alice 可以被定义为动作电影迷的一小部分、喜剧电影迷的一小部分、浪漫电影迷的一大部分,等等。至于 Bob,他可以更加热衷于动作电影:

该表示方法对所有用户都适用。(实际上,系数不一定是百分比,但表示成百分比更方便我们思考)。
如果我们对评级矩阵进行转置会发生什么?我们没有把用户当成行,而是把电影当作行,由评级定义如下:

在这种情况下,PCA 不会显示典型的人脸或典型的用户,而是显示典型的电影。再次,我们将把典型的电影背后的语义意义相结合,这些典型的电影可以构造我们所有的原始电影。对所有其他电影也是如此。
我们来回顾一下第一部分的内容:
矩阵 R 上的 PCA 将给出典型的用户。这些典型的用户被表示为向量(长度与用户相同,就像令人毛骨悚然的图像与原始脸部长度相同)。因为它们是向量,我们可以将它们放在我们称为 U 的矩阵的列中。
矩阵 RT 上的 PCA 将给出典型的电影。这些典型的电影也是向量(长度与电影相同),我们可以将它们放在我们称为 M 的矩阵的列中。
SVD 能为我们做什么呢?简而言之,SVD 是 R 和 RT上的 PCA。
SVD 能同时给出矩阵 U 和 M。你能同时拿到典型的用户和典型的电影。通过将 R 分解为三部分,SVD 给出 U 和 M。下面是矩阵分解表达式:

SVD 算法以矩阵 R 为输入,输出 M、Σ和 U,使得:
R 等于 MΣUT。
M 的列能重造 R 的所有列(我们已经知道了这一点)。
U 的列能重造 R 的所有行(我们已经知道了这一点)。
M 的列是正交的,U 的列也是正交的。主成分都是正交的。这实际上是 PCA(和 SVD)的一个及其重要的特征,但对于推荐而言我们并不关心(之后会讲到这点)。
Σ是一个对角矩阵(之后会讲到这点)。
我们可以基本总结上述所有这些点为:M 的列是跨越 R 的列空间的正交基,U 的列是跨越 R 的行空间的正交基。
当我们计算和使用评级矩阵 R 的 SVD 时,实际上,我们是在对评级进行特别的、有意义的建模。我们将在这里描述该建模。
简单起见,我们先忘记矩阵Σ:它是一个对角矩阵,所以它仅仅是充当 M 或 UT的标量。因此,我们将假装我们已经将其合并到其中的一个矩阵上了。我们的矩阵分解是:
现在,用这种分解,让我们来看看用户 u 对项目 i 的评级,我们将其表示为 rui:
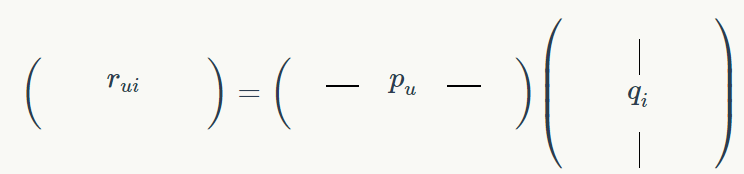
由于定义矩阵乘法的定义方式,rui的值是两个向量的点积的结果:向量 pu,它是 M 的一行,特定于用户 u;向量 qi,它是 UT的列,特定于项目 i:
其中⋅表示点积。是否还记得我们是如何定义用户和项目的?

那么,向量 pu和 qi的值恰好对应于我们分配给每个潜在因子的系数:

向量 pu表示用户 u 对每个潜在因素的亲和度。类似地,向量 qi表示项目 i 对潜在因素的亲和度。Alice 被表示为(10%,10%,50%,...),这意味着她对动作片和喜剧片兴趣不大,但她似乎喜欢浪漫片。对于 Bob,他似乎更喜欢动作电影超过其他任何电影。我们还可以看到,Titanic 主要是一部浪漫电影,绝对没有半点喜剧的元素。
所以,当我们使用 R 的 SVD 时,我们将用户 u 对项目 i 的评级建模如下:
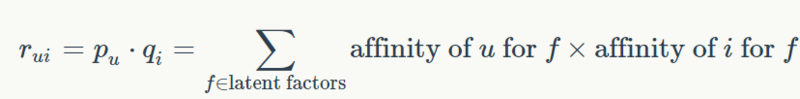
换句话说,如果 u 具有 i 所认可的因子,那么评级 rui将会很高。相反,如果 i 不是 u 喜欢的项目(即系数不匹配),那么评级 rui将会很低。在我们的例子中,Alice 对 Titanic 的评价将会很高,而 Bob 的评分要低得多,因为他对浪漫电影的热情不高。然而,他对“玩具总动员”的评级将高于 Alice。
我们现在已经具备足够的知识将 SVD 应用于推荐任务。前面我们一直假定矩阵 R 是密集的。但实际情况下,它显然是稀疏的(因为我们的目标正是使它更密集)。我们将在下一部分中谈谈如何做到这一点。
现在既然我们已经很好地了解了什么是 SVD 以及如何对评级建模,我们就可以触及问题的核心了:将 SVD 应用于推荐,或者,将 SVD 用于预测缺失的评级。我们先回到稀疏矩阵 R:
我们的目标是预测矩阵中问号的值。
然而,R 的 SVD 并没有定义。它不存在,所以根本不可能计算它。但是不用担心,我们接下来讲讲怎么办。
如果 R 是密集的,我们可以很容易计算 M 和 U:M 的行是 RRT的特征向量,U 的列是 RTR 的特征向量。相关联的特征值组成对角矩阵Σ。有一些很有效的算法可以计算这些。
但是,R 是稀疏的,矩阵 RRT和 RTR 并不存在,所以它们的特征向量也不存在,而且我们不能把 R 分解为 MΣUT的乘积。但我们还是能找到一些办法。曾被用过一段时间的第一个选择是,对 R 的缺失内容进行填充,比如用行(或列)的平均值填充。一旦得到密集矩阵,我们就可以用传统算法来计算其 SVD。这种方法可行,但结果往往有很高的偏差。我们宁愿用另外一种方法,基于最小化问题。
计算 RRT和 RTR 的特征向量并不是计算密集矩阵 R 的 SVD 的唯一方法。实际上,我们可以找到矩阵 M 和 U,如果我们能找到所有满足如下条件的向量 pu和 qi(pu组成 M 的行,qi组成 UT的列):
对所有的 u 和 i,rui=pu⋅qi
所有的向量 pu是相互正交的,所有的向量 qi也如此。
对所有的用户和项目,找出这种向量 pu和 qi可通过解决下面的优化问题(同时遵循正交约束)来完成:

唯一的区别是,这次某些评级是缺失的,即不完整。请注意,我们并没有将缺少的项目视为零:我们纯粹是忽略它们。此外,我们将会忘记正交性约束,因为即使它们对于解释有用,通常限制向量也不能帮助我们获得更准确的预测。
Simon Funk 因他的这一解决方案曾获得 Netflix 奖的前 3 名。他的算法被其他团队大量使用、研究和改进。
这个优化问题不是凸的。也就是说,很难找到使得该总和最小的向量和的值(并且最优解甚至可能不是唯一的)。然而,有大量技术可以找到近似解。我们这里将使用 SGD(Stochastic Gradient Descent,随机梯度下降)方法。
梯度下降是一种非常经典的技术,用于查找函数的最小值(有时是局部的)。如果你听说过用于训练神经网络的反向传播,那么 backprop 只是一种计算梯度的技术,它后来被用于梯度下降。SGD 是梯度下降的十亿种变体之一。我们不会详细介绍 SGD 如何工作(在网上可以找到很多好的资源),但一般情况如下。


在进入 Python 算法实现部分之前,我们还要决定一个事情:向量 pu和 qi的大小应是多少?我们很确认的是,所有向量 pu和 qi的长度要相同,否则我们不能进行点积运算。
为了回答这个问题,我们回顾一下第一部分里的 PCA 和令人毛骨悚然的图像。那些令人毛骨悚然的图像能重构所有的原始脸部图像。
但是,实际上,我们不需要用到所有的特征图像来很好地近似每一个原始脸部。我实际上撒谎了:第一部分里你所看到的动态图只用到了前 200 个令人毛骨悚然的图像(而不是 400 个)。但你看不出区别,是吧?为了进一步说明这一点,这里是第一个原始脸部的重建,用到了 1 到 400 个图像,每次增加 40 个图像进入重建。

最后一张图片是最完美的重建,你可以看到,仅仅用 80 个特征图像(第三个图片)就足够识别原始的人脸。
你可能想知道为什么第一张照片看起来不像第一个令人毛骨悚然的图像,为什么令人毛骨悚然的图像比原始图片有更高的对比度:这是因为 PCA 首先减去所有图像的平均值。你看到的第一张图像实际上对应于第一个令人毛骨悚然的图像加上平均脸的贡献。如果这对你来说有点难理解,不用担心。我们在做推荐时并不在乎这些。
所以这里给出的信息是:你不需要所有的典型图像就能很好地近似初始矩阵。SVD 和推荐问题同样如此:你不需要所有典型的电影或所有典型的用户就可以获得良好的近似值。
这意味着,当我们把用户和项目表示为下面的形式时(SVD 能给出这些):

我们可以用一小部分典型的电影或用户得到一个良好的解决方案。这里,我们将把 pu和 qi的大小限制在 10。也就是说,我们只考虑 10 个潜在因子。
你有权对此持怀疑态度,但实际上我们对这个近似值有很好的保证。关于 SVD(和 PCA)的一个奇妙的结果是,当我们仅使用 k 个因子时,我们获得原始矩阵的最佳低阶近似(了解少数因子)。尽管细节很有趣,但详细原因是有一定技术难度的,已经超出了本文的范围,所以我推荐斯坦福大学课程笔记(Fact 4.2)。(注意:在课程笔记的第 5 节中,作者提出了一种从 SVD 中恢复缺失条目的方法,这种启发式技术就是我们上面提到的技术,但它不是最有效的方法。推荐中最有效的方法是优化已知的评级,正如我们用 SGD 所做的那样)。
在前一部分,我们已经描述了如何用随机梯度下降方法寻找 SVD 问题的近似解。其步骤如下:

下面是该算法的 Python 实现。
def SGD(data):
'''Learn the vectors p_u and q_i with SGD.
data is a dataset containing all ratings + some useful info (e.g. number
of items/users).
'''
n_factors = 10 # number of factors
alpha = .01 # learning rate
n_epochs = 10 # number of iteration of the SGD procedure
# Randomly initialize the user and item factors.
p = np.random.normal(0, .1, (data.n_users, n_factors))
q = np.random.normal(0, .1, (data.n_items, n_factors))
# Optimization procedure
for _ in range(n_epochs):
for u, i, r_ui in data.all_ratings():
err = r_ui - np.dot(p[u], q[i])
# Update vectors p_u and q_i
p[u] += alpha * err * q[i]
q[i] += alpha * err * p[u]一共只有 10 行代码,非常简洁。
一旦我们运行 SGD 过程,就可以估计所有的向量 pu和 qi。之后,我们可以用向量 pu和 qi的点积来预测所有的评级:
def estimate(u, i):
'''Estimate rating of user u for item i.'''
return np.dot(p[u], q[i])就这样,我们的任务完成了。想要自己尝试吗? 我做了一个 IPython Notebook(http://nbviewer.jupyter.org/github/NicolasHug/nicolashug.github.io/blob/master/assets/mf_post/Matrix%20factorization%20algorithm.ipynb),可以在一个实际的数据集上运行该算法。我们将用到 Surprise 库,它是一个很好的库,用于快速实施评级预测算法(但我可能会带有偏见,因为我是 Surprise 库的主要开发人员)。要使用它,你只需要通过 pip 来安装它:
pip install scikit-surprise正如你在 notebook 上可以看到的,我们得到约 0.98 的 RMSE 值。RMSE 表示均方根误差,计算公式如下:

你可以将其视为某种平均错误,其中大的错误会被严重处罚(因为它们进行了平方运算)。RMSE 为 0 意味着所有的预测都是完美的。RMSE 为 0.5 意味着,平均而言,每个预测值偏离实际值 0.5。
那么 0.98 算是一个好的 RMSE 吗?其实真的不是那么糟糕。如该 Notebook 所示,某邻域算法只能达到 1 的 RMSE。一个更复杂的 MF 算法(与我们的算法相同,除了评级是无偏的和我们使用了正则化)可以达到约 0.96 的 RMSE。这个算法在文献中被称为“SVD”,但现在你知道它不算是一个真正的 SVD,因为有缺失的评级。它只是(大部分)灵感来自 SVD。
我希望你现在可以了解到 PCA 和 SVD 之美,以及如何调整 SVD 用于解决推荐问题。如果你想体验一下 Surprise 库,文档中也有很多很酷的东西。
如果你对本文有任何想法或意见,请在我的博客的评论中告诉我。非常感谢任何形式的批评。
感谢 Pierre Poulain 对本文的宝贵意见。
本文中,我试图避免太过理论,而提供可视化的具体例子来说明如何使用 PCA 和 SVD。但理论不容忽视,它其实很有趣。如果你想进一步深入了解本文所涵盖的各种主题,可能需要阅读一些资源:
Jeremy Kun 在 PCA 和 SVD 上的帖子很棒。这篇文章的第一部分受到这两个帖子的启发。https://jeremykun.com/
我个人认为,Aggarwal 关于推荐系统的教科书是最好的推荐系统资源。你可以找到关于各种矩阵分解变体的细节,其中涵盖了大量其他科目。http://charuaggarwal.net/
如果你想更多地了解“SVD”算法及其可能的扩展,请从 BellKor 团队查看文章。他们获得了 100 万美元的 Netflix 奖金。https://datajobs.com/data-science-repo/Recommender-Systems-%5BNetflix%5D.pdf
PCA 可以用于很多有趣的东西,而不仅仅是乱七八糟的脸部图像。Jonathon Shlens 的教程提供了对 PCA 作为对角化过程的深刻见解,并提供了与 SVD 的链接。https://arxiv.org/abs/1404.1100
此外,斯坦福大学课程笔记涵盖了我们提出的一些主题(低等级近似等),更多侧重于理论。http://theory.stanford.edu/~tim/s15/l/l9.pdf
对于线性代数,唯一值得阅读的书是 Gilbert Strang 的“LA 简介”。他的麻省理工学院课程的技术含金量也很高。http://math.mit.edu/~gs/linearalgebra/
当然,Surprise 是一个很好的推荐系统库(但是我也可能带有偏见)。http://surpriselib.com/
查看英文原文:http://nicolas-hug.com/blog/
本文系 Nicolas Hug 原创文章,已经授权 InfoQ 公众号翻译并转发传播。
今日荐文
点击下方图片即可阅读

影响关系型数据库分片的关键因素是什么?
作为大数据先行者的 TalkingData,将在 9 月 11 日 TalkingData T11 智能数据峰会上,用自己的方式为企业讲述如何聆听数据的奥妙,将传统行业与新兴技术结合,完成向数据驱动型企业的转型升级。更多精彩点击「 阅读原文 」查看详情,报名从速,精彩享不停。







