手把手教你用20行代码的CNN模型做商品推荐
在推荐系统和搜索引擎当中,最常做的事情就是比较两个对象的相关度。在搜索引擎里,我们关注query-document的相关度;在商品推荐里,我们可以关注title-title的相关度。
相关度模型里面比较简单的就是向量空间模型,Vector Space Model,BM25等等,这些方法都是通过将文本映射到一个很大的向量空间,然后计算相似度。有很多feature engineering会把人们总结出来的知识加到引擎里,但他们需要花费大量精力去处理知识。
随着深度学习的兴起,Google,微软,百度等公司相继公开了自己用深度学习自动提取文本特征的算法。前几日我读了Google 2015年的一篇文章“Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks”,在eBay公开的小数据集上试了试,效果蛮好。
你只需要下载eBay开源的代码,添加20行代码就可以出来玩了。
Sentence to Matrix
采用CNN的第一步就是需要将单句想象成一个图片,那么每一个词就是一个宽度为d的向量,将整个句子的词整合到一起就成了一个d*|s|的图片。
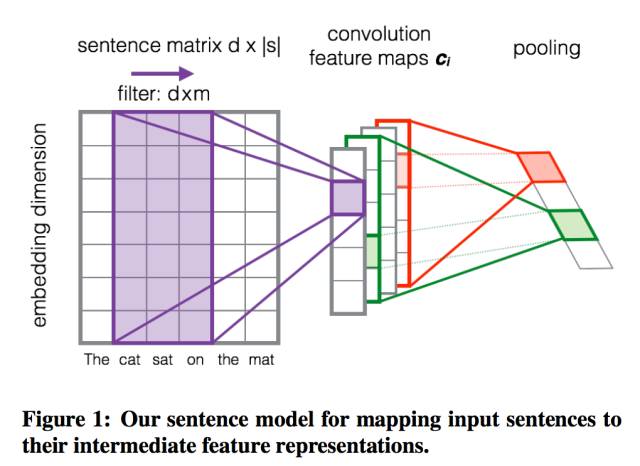
具体的实现非常简单,eBay的代码里已经定义了src_input_distributed作为原文的单词向量,我们只需要通过一行代码扩展一下词向量的维度(传统的图片表面上看是2维的,但因为有三种不同的基础颜色,所以其实是3维的)。
src_input_expanded=tf.expand_dims(
src_input_distributed, -1)
Convolution Layer
在由单词特征组成的图片上我们增加一层CNN,目的是通过训练找到每段文本当中能够区别相关性的词组,比方说“costume headband”, “short size”等等。
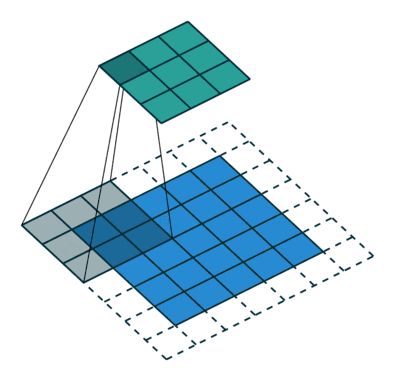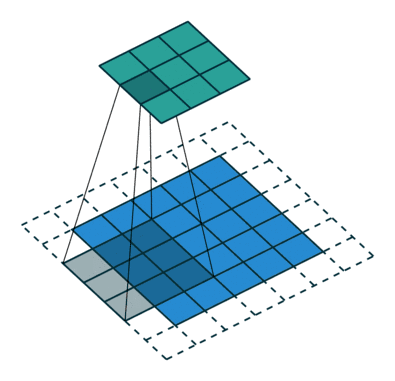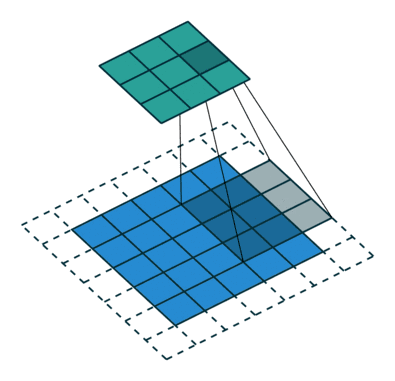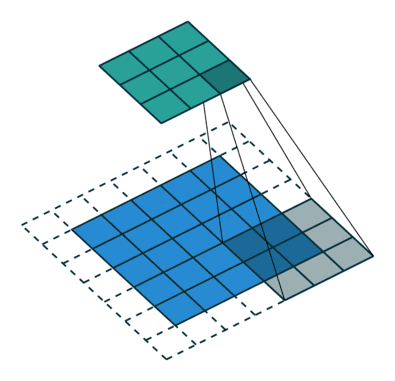
通常有两种不同类型的卷积层:窄卷积(Narrow)和宽卷积(Wide),他们的区别在于我们如何对文本特征矩阵进行Padding。窄卷积相当于不做Padding,对于长度|s|的文本和长度m的卷积,生成|s|-m+1个特征,宽卷积则会生成|s|个特征。
在一篇叫做“A convolutional neural network for modelling sentences”的经典论文里有提到,宽卷积能在注意句中词汇的同时,注意到接近边界的单词,而窄卷积则因为边界单词被看到的次数较少,忽略了这些信息。Google的论文当中采用的做法是宽卷积,但我在实践当中给每个句子结尾加上足够数量的单词作为补充,所以我的代码里实现的是窄卷积。
Pooling Layer
在卷积层之后,我们采用一层Pooling结构,常见的Pooling有两种,平均化(average pooling)和最大值(max pooling),这两种Pooling的本质都是将一组特征映射到一个值上。
Average Pooling和Max Pooling都有各自的弱点,在Average Pooling的情况下,所有的特征都会被考虑到,最强的那些信号会被弱化,这一点在使用tanh这样的非线性变化时非常显著。
Max Pooling是被运用最广泛的方法,但这样做很容易在训练数据上过拟合。为了减轻这一问题,人们发明了不同的梯度下降算法。最近又出现了前k大的特征值Pooling这一方法(k-max pooling),或者动态提取前k大特征值,用于建造更深的网络。
pooled_outputs = []
# convolutional layer的数量以及大小
filter_sizes = [2, 3, 4, 5]
num_filters = [256, 128, 128, 64]
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope('maxpool-{0}'.format(filter_size)):
# 设立不同大小的矩阵进行convolution
filter_shape = [filter_size, word_embed_size,
1, num_filters[i]]
W = tf.Variable(tf.truncated_normal(
filter_shape, stddev=0.1), name='W')
b = tf.Variable(tf.constant(
0.1, shape=[num_filters[i]]), name='b')
conv = tf.nn.conv2d(
src_input_expanded,
W, strides=[1,1,1,1], padding='VALID')
h = tf.nn.relu(tf.nn.bias_add(conv, b), name='relu')
# 设立不同大小的max pool
pool = tf.nn.max_pool(
h, strides=[1,1,1,1], padding='VALID',
ksize=[1,MAX_SEQ_LENGTH-filter_size+1,1,1])
pooled_outputs.append(pool)
# 展开pooling layer的输出成为一个tensor
feature_size = sum(num_filters)
pool = tf.concat(3, pooled_outputs)
pool_flat = tf.reshape(pool, [-1, feature_size])
Matching Layer
在我们得到Pooling Layer生成的针对单句的向量后,定义一个相似度矩阵M对向量进行变换和降维,最后两个句子的相似向量可以这样计算:
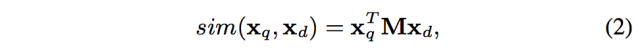
这个简单的模型可以看做一个noisy channel,他常常被运用到信息检索和问答系统当中。在我实际应用的过程中,只对source sentence实现了相似矩阵变换。
src_M = tf.get_variable('src_M',
shape=[feature_size, seq_embed_size],
initializer=tf.truncated_normal_initializer())
src_seq_embedding = tf.matmul(pool_flat, src_M)
Final Result
只需要实现上面的这些内容,就可以放进eBay公开的“Sequence Semantic Embedding”代码里进行测试了,他们定义好了loss和optimizer。
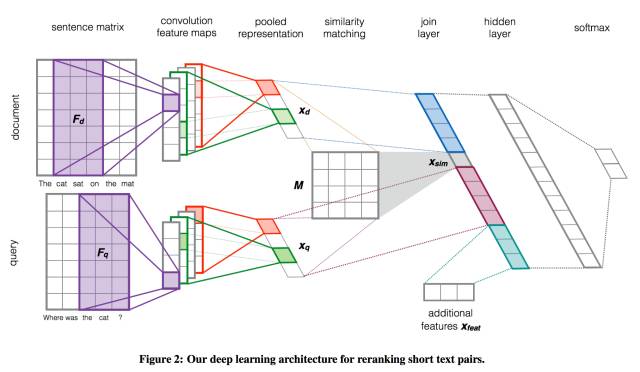
整个训练模型如下图所示:
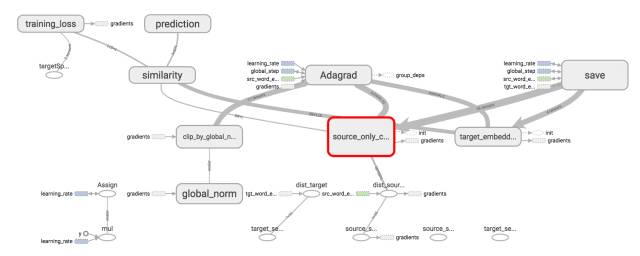
我们只是实现了红色方框标出的部分,一个source sentence encoder,长这样:
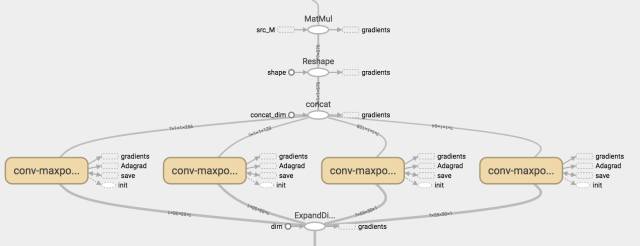
自下而上就是一个word embedding组成的矩阵,四个不同大小的convolutional/pool,然后把结果连接起来,与相似矩阵相乘。
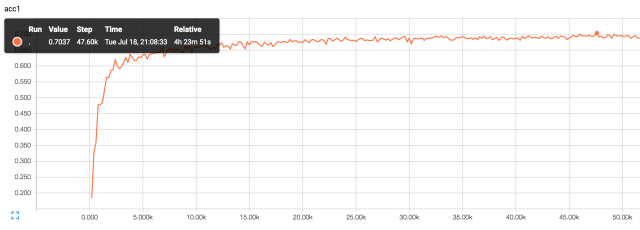
我实现的比较简单,还没有来得及调整参数,添加regularization,大约5万轮top1 accuracy就达到了0.7037:
Learning to Rank
在Google的论文里面,最精华的部分还是他们对结果进行排序的结构。
相似矩阵计算出来的向量相似度并不是最终得分,论文将query,document单独特征,特征向量内积,和一些额外的特征放到一起,形成一个join layer,然后通过一个隐藏层计算最终结果。
通过这样的结构,我们可以把query,document对结果的独立影响考虑进去,相当于基于query,document特征,学习了一个偏置(bias)。加入的额外特征可以用来描述用户或者其他对象对相似度的影响,比方男性用户,女性用户对于“shoes”的偏好是不一样的。
无独有偶,今年WSDM的文章“Joint Deep Modeling of Users and Items Using Reviews for Recommendation”也提到了连接独立的特征和相似矩阵生成的特征,自动的学出所有简单的特征组合以及权重。
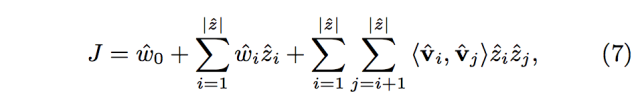
Conclusion
我其实是机器学习这一方面的门外汉,从前在MSRA的机器学习小组实习,但所有的计算公式都等着同组的大牛去推演,所以理论方面所知甚少,在这里班门弄斧了。
最近开始在产品里面套用简单的CNN来解决一些问题,效果还真是立竿见影,让我蛮开心的。深度学习的一大好处就是能够最大程度上减少人手工选择特征的工作量,但是也引入了不少难题,比方说如何获取大量有用的数据;如何搭建一个系统保存每一个对象的特征;如何搭建一个系统去支持模型,每秒处理大量请求。
路漫漫其修远兮,各位读者要是喜欢的不妨分享激励一下作者。
本文提到三篇论文大家可以看看:
- Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks
- Joint Deep Modeling of Users and Items Using Reviews for Recommendation
- A convolutional neural network for modelling sentences
eBay的开源代码:
https://github.com/eBay/Sequence-Semantic-Embedding
CNN的简单实现:
https://github.com/eBay/Sequence-Semantic-Embedding/pull/1/commits/be11d8154df9bc806e7c623d5fcf609e54e45b75
★推荐阅读★
加入「AI从业者社群」请备注个人信息,添加小鸡微信 liulailiuwang


