CVPR热点论文作者面对面解读 | 李飞飞团队、康奈尔团队、密歇根大学团队
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
2019年计算机视觉顶会CVPR前不久刚在美国长滩闭幕。Robin.ly在大会现场独家采访20多位热点论文作者,为大家解读论文干货。本文推出三篇爆款文章作者解读:
斯坦福李飞飞团队与上海交通大学合作项目:6D目标姿态估计
DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion
康奈尔Kilian Weinberger教授团队:无人驾驶中的智能传感技术-3D目标检测研究
Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving
密歇根大学Jason Corso教授团队:BubbleNets检测视频资料真伪研究
BubbleNets: Learning to Select the Guidance Frame in Video Object Segmentation by Deep Sorting Frames

1
密集融合方式:6D目标姿态估计
6D 目标姿态估计对许多重要的现实应用都很关键,例如机器人抓取与操控、自动导航、增强现实等。斯坦福大学李飞飞团队致力于研究如何提高姿态估计的准确率和推断速度,并在CVPR发表了论文“DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion“。这项研究希望给机器人提供在不同情况下对操作物体的位置和姿态的识别能力,从而能实现更精准的抓取和分拣操作。
本论文的第一作者Chen Wang在CVPR2019墙报展示现场给我们做了详细讲解。Chen Wang现在是上海交通大学博士生学生,此项研究是他在斯坦福大学实习时合作进行的研究。以下是论文讲解实录:
Chen Wang在CVPR现场讲解“6D目标姿态估计模型”研究
“我们在研究中发现,从 RGB-D 输入中提取 6D 姿态信息时,很多点是被其他对象遮挡住的,这就会导致识别性能发生明显下降。在前人的工作中,一种流行的方法是利用全局特征进行 6D 位姿估计。但是当发生了遮挡,全局特征很大程度上会受到影响,导致预估测结果不佳。在这项工作中,我们生成了基于像素的密集融合方式,在不同的通道中先分别处理 RGB 和深度信息,以生成基于像素的颜色嵌入和带有 PointNet 结构的几何嵌入。然后我们利用 RGB 和密集度之间的对应关系就可以实现像素级别的融合并进行预测。
我们的工作和前人的工作之间的主要区别是,我们可以从这些未被遮挡的点开始基于像素进行预测。墙报上展示了我们在 YCB 视频数据集上测试的结果。图中 X 轴代表遮挡的程度,Y 轴代表的是位子估计的准确度。我们可以看到,虽然遮挡范围越来越大,但与前人的工作相比,我们的结果鲁棒性更好。我们在这两个数据集中取得了目前效果最好的RGB-D 姿态估计效果。相关的所有代码和信息已经发布在网上,大家如果有兴趣可以去查看。
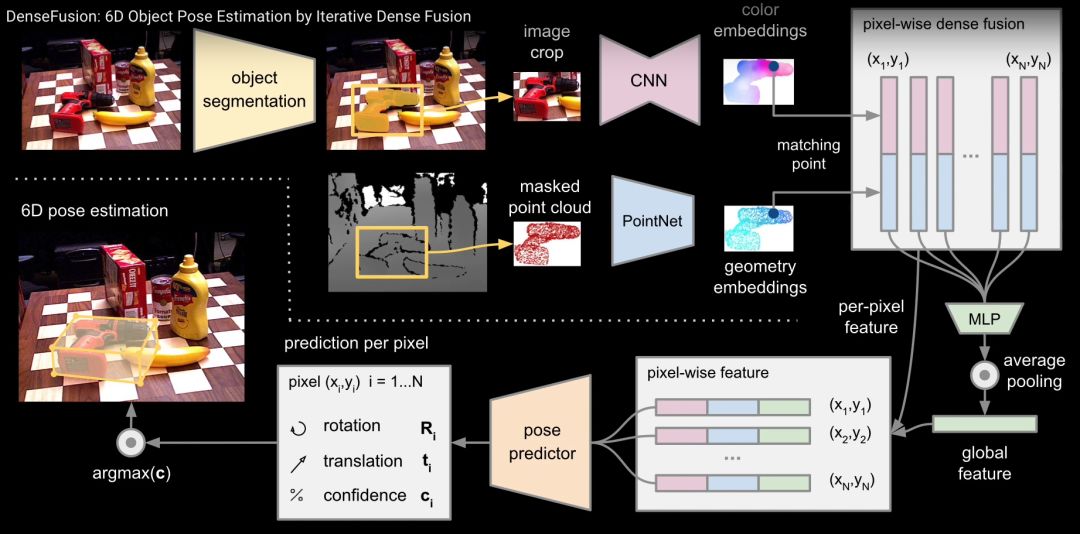
论文图示:6D目标姿态估计模型 (来源 Chen Wang)
我现在播放的演示视频中包含了两个部分的内容。第一部分是对框架的分析,在墙报中也有所展示。接着,这是我们在 YCB 视频数据集上的测试结果。相比前人的工作,我们在重度遮挡的场景中获得的姿态估计结果更加准确和可靠。视频的第二部分展示的是我们如何使用这种训练好的模型在真实的机器人抓取实验中进行测试。这里展示的是机器人视角。这是我们利根据DenseFusion 姿态估计结果将模型数据点反向投影回图像帧的示例。我们可以看到,大多数点都与它的实际位置吻合较好。这样机器人就可以知道操作对象物体的位置和姿态,能够使用预定义的抓取策略来抓取这些对象。这就是我们的技术在拾取,组装等一些场景中的应用。“
论文信息
DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion
作者:Chen Wang, Danfei Xu, Yuke Zhu, Roberto Martín-Martín, Cewu Lu, Fei-Fei Li, Silvio Savarese
研究机构:斯坦福大学、上海交通大学
论文链接:
https://arxiv.org/abs/1901.04780
2
无人驾驶中的智能传感技术:3D目标检测
自动驾驶汽车依靠各种传感器来感知环境。每种类型的传感器都有自己的优点和缺点。LiDAR提供精确的距离信息,并且能够探测到小物体,但是成本比较高,如何在保证传感器的精准基础上降低成本,是计算机视觉领域的一个重要研究方向。论文“Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving” 研究了在无人驾驶中如何使用LiDAR以外的技术来获取精准数据。
该文的作者来自康奈尔大学Kilian Weinberger教授和Bharath Hariharan教授团队的博士生Yan Wang、Wei-Lun Chao、Divyansh Gary。Weinberger教授曾获得ICML, CVPR, AISTATS和KDD等会议的最佳论文奖、AAAI Senior Program Chair奖,并当选ICML 2016和AAAI 2018的大会日程主席。以下为论文分享访谈实录和视频:

康奈尔大学Kilian Weinberger和Bharath Hariharan团队在CVPR2019现场接受Robin.ly访谈
Wenli: 请简要介绍一下 “3D Object Detection for Autonomous Driving”这篇文章。当初为什么选择这个课题?文章中的亮点是什么?
Yan Wang:
我们认为 3D 目标检测是自动驾驶汽车系统中的一个重要且基本的问题。目前人们只关注基于激光雷达(LiDAR)的目标检测,对纯视觉的 3D 检测技术的兴趣相对则没有那么高。但是只依靠LiDAR, 系统会不够鲁棒,而且LiDAR价格昂贵。所以我们想寻找一个成本比较低的替代方案,比如基于视觉深度估计的3D目标检测。但是在我们做之前,该方向准确性还很低,所以我们认为有很多工作可以做。
Divyansh Gary:
具体一点说,我们实际上是利用图像数据进行了高精度的 3D 目标检测。我们在文章中讨论了激光雷达的表征方法及其重要性。我们从左右两个摄像头上获取了图像,计算了图像中每个像素之间的距离并估计了密集Disparity。我们想把相关结果转换成一个三维的表征方法,叫伪LiDAR。它跟 LiDAR 类似,但是它是从图片中得到的。这种方法可以用来训练卷积神经网络,并应用于目标检测,发挥跟 LiDAR 类似的作用。我们仅仅通过转变表征方式就让准确度从20%上升到了70%。
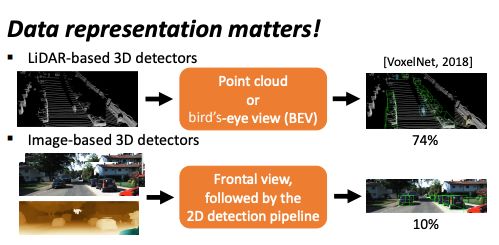
论文图示:对比LiDAR和图像数据的3D检测效果(来源 Yan Wang)
Wei-Lun Chao:
现在很多论文都在讨论新的深度学习架构。但我们发现基于图像的检测技术准确性不如 LiDAR,并不是因为原始数据不够好,或深度学习框架不够好,而是因为人们表征数据的方式存在问题。在这篇文章中,我们提出了一个通用框架,人们可以利用这个框架将任何新的深度估算网络和优质的检测器结合在一起以发挥最佳的效果。我认为这就是最重要的创新点。
Wenli:你们下一步的计划是什么?你们认为这项技术多久可以商业化?
Wei-Lun Chao:
我想能让我们的方法准确度达到 LiDAR 的水平。另外,LiDAR 是能够直接获得深度信息的,但现在我们是使用神经网络来从图片中估计深度,所以我们要想办法提高模型处理速度。最后,我们还希望能够将系统推广到不同的应用场景,将不同的传感器,激光雷达和相机整合起来。能否以及何时商业化应该取决于不同公司的标准。
Divyansh Gary:
的确已经有一些公司联系过我们,想了解我们的研究能否应用于他们的车辆。我们希望一年之内就能实现合作。
Wenli: 许多自动驾驶公司当前所使用的智能传感技术是什么?你们对此有什么看法?
Kilian Weinberger:
我们特别关注无人车使用 LiDAR 是不是绝对必要。LiDAR 是一种主动式传感器,性能非常好,能够在黑暗中工作,通过检测发送激光脉冲在检测目标上反射的信息来测量距离。但是 LiDAR非常昂贵,会增加汽车的成本。
相比之下,相机是一种被动式传感器,跟 LiDAR 的工作原理有着本质的不同。但是我们在论文中提到,如果使用正确的方式处理基于相机的立体图像数据,即便使用被动式传感器也可以获得非常精确的结果。所以我们试图挖掘 LiDAR 和立体图像处理技术之间的区别,从而找到技术上的突破点。

论文图示:不同传感器测量效果图 (来源 Yan Wang)
Wenli: 能举一个具体的例子吗?
Kilian Weinberger:
LiDAR 的一个优势是,当它离检测目标很远时预测仍然非常准确。双目摄像头的工作原理是,你可以测量目标在左右图像中分别显示的位置,进而测量Disparity。但是如果存在Disparity估计误差,即使小于1个像素,对于较远的物体都意味着超过一个车身的距离。这时你只需要几个 LiDAR 数据点进行辅助,就可以通过这几个LiDAR点移动整个观测物体的深度估计来消除这个误差。但是物体距离相机很近,立体成像的预测结果会很准,误差问题就几乎不存在了。
Wenli: 你们认为相机和 LiDAR 相结合是比较有前景的行业趋势吗?单独使用相机能够实现高级自动驾驶吗?
Kilian Weinberger:
这个问题已经有人研究过了。但是我们仅仅通过改变数据处理方式就能使立体成像技术更可靠,这个技术也可以泛化到其他场景。在这个基础上再结合 LiDAR 的数据就可以获得非常准确的结果。我认为如果没有 LiDAR 的辅助,单纯依靠相机也可以实现比较准确的检测结果。比如可以使用高分辨率相机,或者其他的主动式传感器。目前这方面还需要进一步的研究。
Bharath Hariharan:
我同意 Kilian 的观点。我认为我们的技术起到了四两拨千斤的效果。我们甚至没有太关注跟基于相机的 3D 重建相关的研究,这个领域还有很多待开发的工具,尤其是在自动驾驶汽车这样的领域。我个人认为相机能做的事情还很多,我们还需要进行更深入的探索。我建议大家还是先尽量使用已有的数据来摸索正确的数据处理和使用方法。
论文信息
Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving
作者:Yan Wang, Wei-Lun Chao, Divyansh Garg, Bharath Hariharan, Mark Campbell, Kilian Q. Weinberger
研究机构:康奈尔大学
论文链接:
https://arxiv.org/abs/1812.07179
3
BubbleNets:检测视频资料真伪
CVPR接收的论文“BubbleNets: Learning to Select the Guidance Frame in Video Object Segmentation by Deep Sorting Frames”研究如果检测出“伪视频”。以下是该论文的作者,来自密西根大学的Jason Corso教授以及助理研究科学家 Brent Griffin给我们介绍他们的研究。

Jason Corso教授以及助理研究科学家Brent Griffin在CVPR2019接受Robin.ly采访
Wenli: 能介绍一下这篇论文吗?当初为什么选择这个研究方向?
Brent Griffin:
在目前的视频对象分割方法中,半监督算法的效果是最好的,但前提是我们要手动提供注释帧以及待分割对象的边界信息。如果选择的注释帧不正确,也会影响结果的准确性。这项研究的目的就是理解半监督算法如何自动检测被处理过的媒体文件,因为我们确实已经遇到了这个领域的实际应用问题。
Wenli: 这是个比较新的领域,你们如何评判检测结果的好坏?
Brent Griffin:
我们最开始只遵循使用第一个注释帧的方法,但发现我们想要在视频中删除的对象可能一直在不停运动,这样一来注释效果就比较差。后来我们发现只使用中间帧的效果也很好。我们的一个客户公司不知道如何选择最好佳注释帧,希望我们的能够自动化这个过程。听起来很难实现,但实际上我们能够利用 DAVIS(Densely Annotated VIdeo Segmentation)数据集找到一种方法来获取其中包含的注释信息,并将这些信息转换成 60 个原始视频中所包含的75万个训练样例,用于训练BubbleNets,最后再进行注释筛选。问题就在于,我们如何利用这些有限的注释视频示样例生成大量训练样例,如何理解视频的内容。这涉及到很多参数。如果你的训练样例有限,很容易就会导致过度拟合。
Jason Corso:
最开始我们只是在寻找一个最好的注释帧,然后对帧质量进行回归处理。当时我们并没有足够的训练数据,于是就采用了一种非常传统的冒泡排序算法,比较成对的帧中哪一个帧的注释信息质量更好。通过将现代的深度学习与传统的排序算法结合起来,在整个视频中重复这样的操作,我们就能够处理更大的训练数据集。
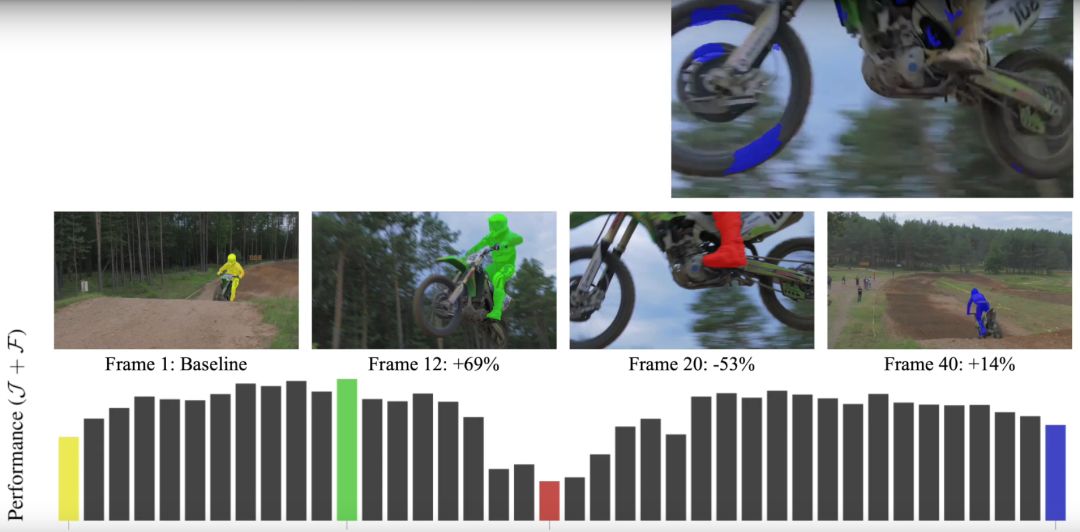
论文图示:对比不同注释帧的注释信息质量(来源:密西根大学)
Wenli: 这个方法是论文中最大的技术突破吗?
Brent Griffin:
结合冒泡排序框架实际上可以将这个问题转变为我们能够解决的,有意义的机器学习或深度学习问题。我认为这并不意味着 BubbleNets 就是最佳解决方案,一定还有提高的空间。我们希望其他研究人员能够继续这方面的工作,弄清如何通过自动选择注释帧来解决这个问题。BubbleNets 只是这个过程中重要的开端。
Jason Corso:
这个方法也是我们实验室“混合智能”研究方向的一个具体实例,将人类智能与计算机算法结合起来,充分利用两者的优势,另辟蹊径的解决问题。
Wenli: 这个方法目前有什么商业应用前景?面临的挑战是什么?
Brent Griffin:
总的来说,我认为对象分割在机器人技术,自动驾驶车辆领域有比较重要的应用。比如在我们实验室另外的项目中会使用机器人进行视频对象分割和视觉伺服控制。我们能够使用基于计算机视觉开发的机械装置快速跟踪目标和控制机器人。这项工作是与丰田研究所合作的,他们对我们所取得的进展感到非常兴奋。
Jason Corso:
我认为公众也很关注这方面技术的应用。我在来时的飞机上读到了一篇关于在几年前的选举前夕,候选人的演讲视频如果被动了手脚可能造成的影响的文章。通常人们在篡改视频和图像时总是会留下一些蛛丝马迹,很难做到不留下任何痕迹,所以我们通常能够利用这些痕迹检测一个视频是否被人为修改过。针对双JPEG压缩之类比较复杂的情况,比如视频显示其内容发生在某一天的某个地点,我们可能会从其他相关数据中发现,根据天气或车辆的GPS信息,这是不可能的。最简单的方法当然就是将其跟原始视频进行对比,就能发现其中的问题。从科学和社会的角度来看,这是一个值得重视的问题。
我们正在推动的“混合智能”领域的研究有很多问题亟待解决。比如一个研究项目是获取 YouTube 上的行车记录仪视频,其中记录的通常是比较罕见的交通事件。但训练自动驾驶模型通常需要大量数据训。我们开发的一个技术能够从 YouTube 中获取大量单眼数据,但是我们无法直接利用单眼数据对场景进行全面重建,还需要借助人工的辅助,比如提供车辆的品牌信息,标记事故中的车辆等等。人工智能方法无法提供这类信息,所以一个很重要的工作就是充分结合机器的自动操作和人工的辅助功能。
Wenli: 您创办了一个公司叫Voxel51,在本次 CVPR 会议上推出了“AI for Video”平台和 Scoop 产品。能介绍一下这家公司吗?
Jason Corso:
公司是在 2018 年 10 月成立的,在此之前经历了大约两年的技术开发阶段。从 2016 年开始,我们的目标是打造一个软件平台,让计算机视觉专家和非专业人士都能够大规模利用我们在计算机视觉和机器学习领域获得的进展。
我们在本次 CVPR 大会上推出了该平台的第一个版本,包含有三个主要的用例。第一个用例是帮助计算机视觉或机器学习专家建立模型进行视频对象分割。他们通常不太了解后端操作,不清楚如何打造一个系统来实现在一天内处理数千小时视频的功能。我们的平台可以帮助他们把模型导入 Voxel51 的软件开发工具包并在几小时内部署在平台上,更快的实现他们的目标。
另外,你可能有大量的数据,但没有财力负担人工数据标记。这样的公司目前有很多,但是价格不菲,标记一帧大约需要 30 或 50 美分。现在你完全可以将视频上传到我们的平台,应用我们的“Sense” 技术提供的对车辆,道路和人进行的内容丰富的标签和注释,比如车辆的制造商,类型,颜色,姿态,精度都在90%以上。我们希望能够跟有相关需求的一级公司合作。
第三个是,该平台也可以用于应用程序开发。我们在平台上构建的一叫做 Scoop 的程序演示了这一功能。人们无需任何培训就能获取大型数据集以及关于其内容的详细介绍。这个工具的界面非常友好,可以快速完成我们称之为“分面搜索(faceted searches)”的操作。人们可以使用 Scoop 对数据进行筛选,只提取需要的数据,也可以将自己的标签数据上传到 Scoop 进行后续操作。
论文信息
BubbleNets: Learning to Select the Guidance Frame in Video Object Segmentation by Deep Sorting Frames
作者:Brent A. Griffin, Jason J. Corso
研究机构:密西根大学
论文链接:
https://arxiv.org/abs/1903.11779
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、算法竞赛、图像检测分割、人脸人体、医学影像、自动驾驶、综合等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~


如有AI领域实习、求职、招聘、项目合作、咨询服务等需求,快来加入我们吧,期待和你建立连接,找人找技术不再难!
推荐阅读
最新AI干货,我在看



