Facebook开发者大会KeyNotes - 自监督学习减少99%标注、跨语种表示学习等
【导读】Facebook F8(开发者大会)刚在美国时间4月30日-5月1日于美国加利福尼亚州的圣何塞举行。第二天的大会介绍了Facebook中较为前沿的AI算法,如自监督学习、跨语种表示学习、图像理解、弱监督视频理解等。本文介绍F8中几个算法的亮点。
自监督学习
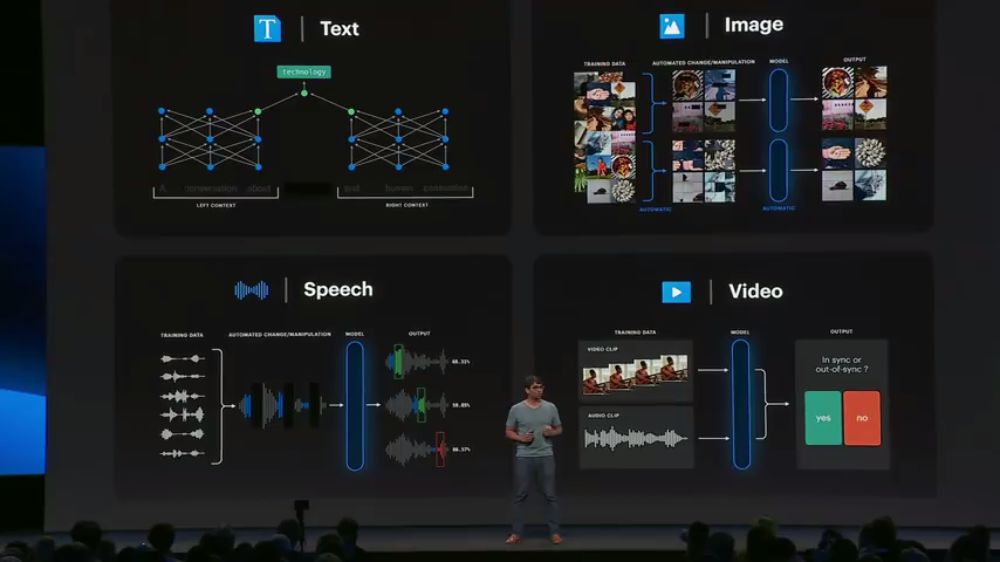
有监督学习依赖大量的人工标注,而弱监督学习可以将数据自身的一部分特性作为标签,通过预测这些标签来在没有人工标注的情况下预训练模型。例如,可以通过句子/图像的一部分,来预测句子/图像的剩余部分。由于不需要人工标注,我们可以基于大量的未标注数据来预训练模型:
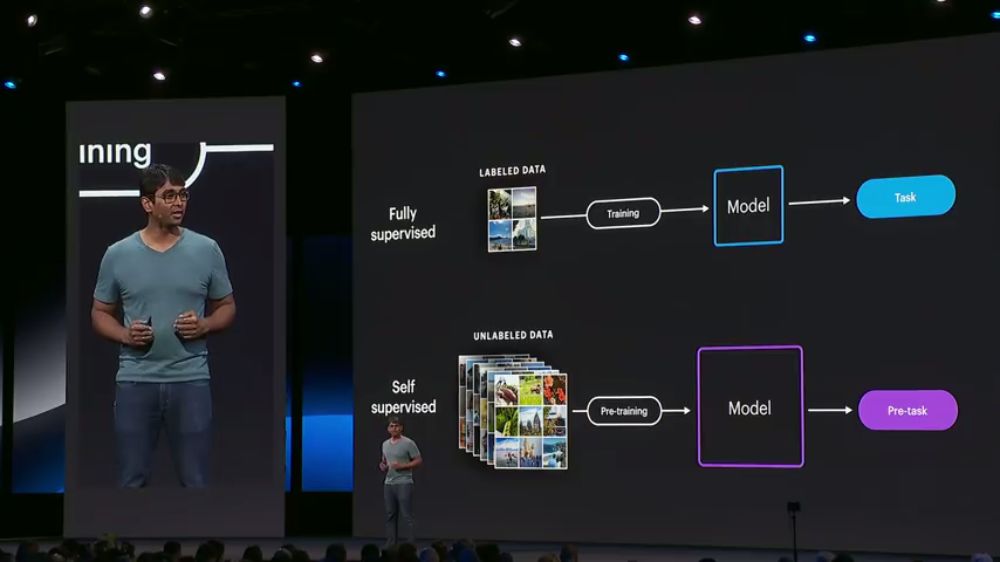
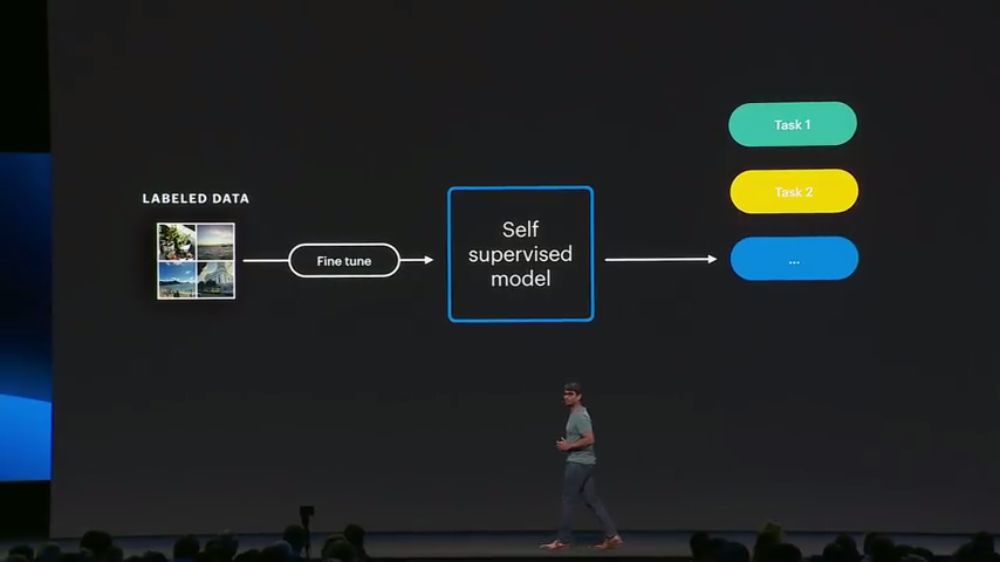
预训练完成后,我们使用少量的标注数据,来Fine-tuning模型:
在某些任务上,自监督学习可以仅使用原先150分之1的训练数据:

也就是说,我们可以用更少的标注数据,来更好地理解内容:
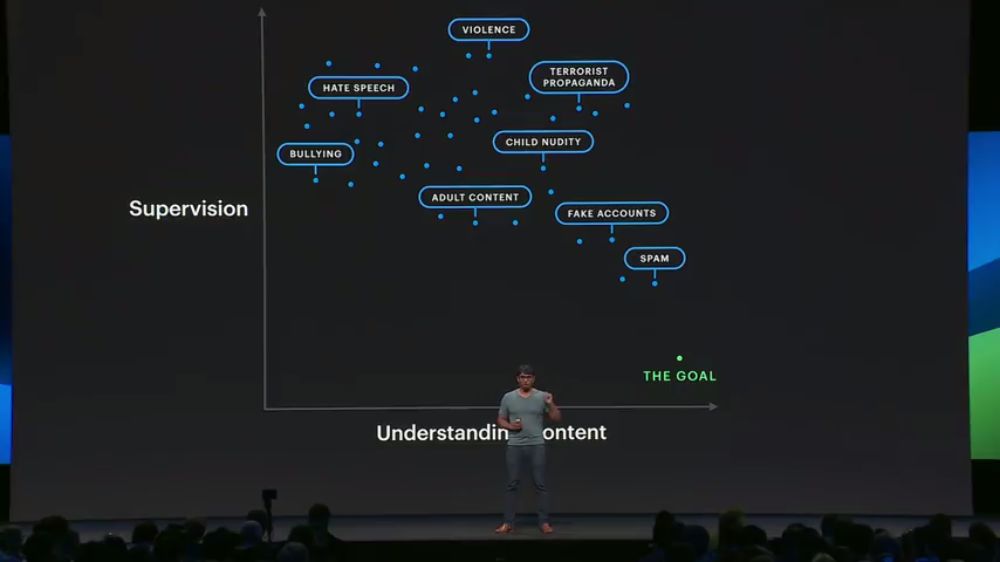

跨语种表示学习
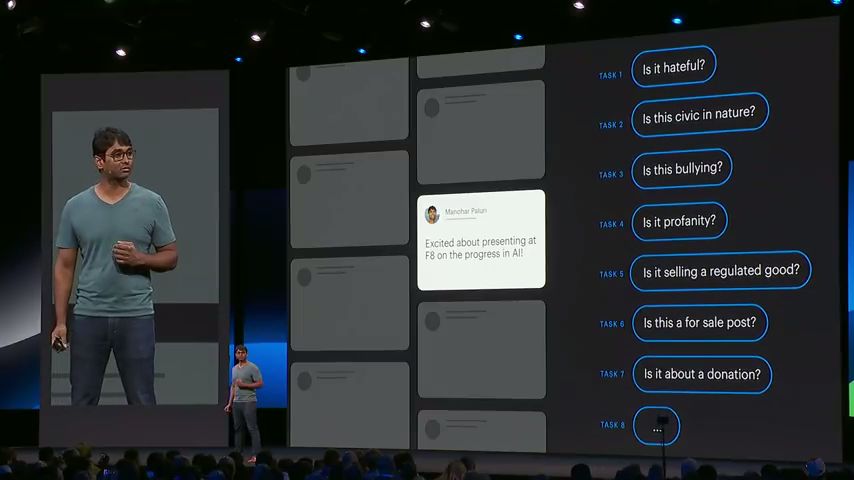
Facebook对于文本信息,可能会使用多个NLP模型来提取不同的信息。例如信息是否有害、是否销售帖等,然而全球有6000+个语种。为每个语种单独训练是非常庞大的工程。另外,一些小语种会面临缺乏大量语料的问题。Facebook的解决方案是将不同语种映射到同一个表示空间中,用统一空间中的表示,为每个任务训练唯一的模型来覆盖多语种的应用。
之前的算法已经可以将不同语种的词映射到统一的空间:

而今年,他们已经可以在句子级别上做这样的映射:
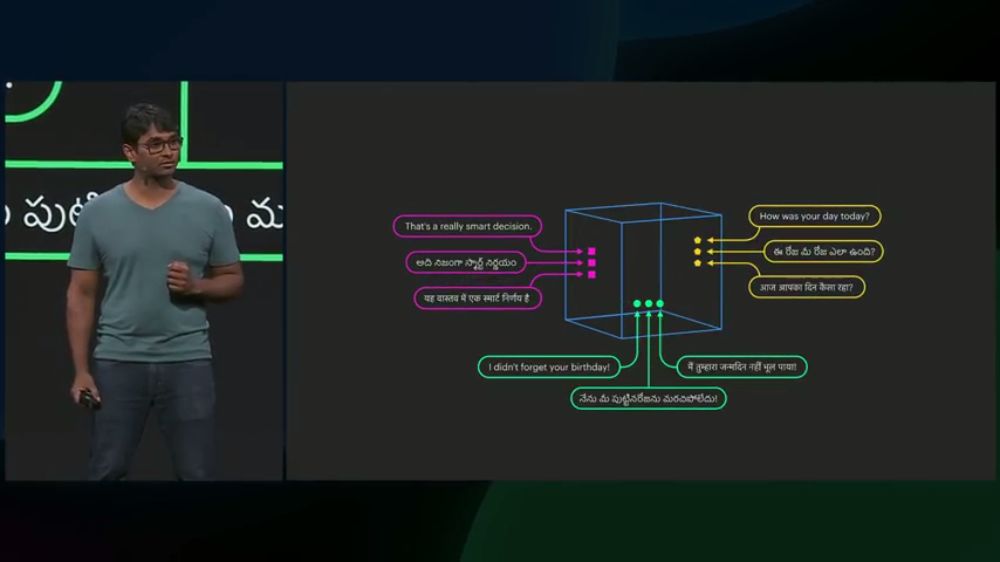
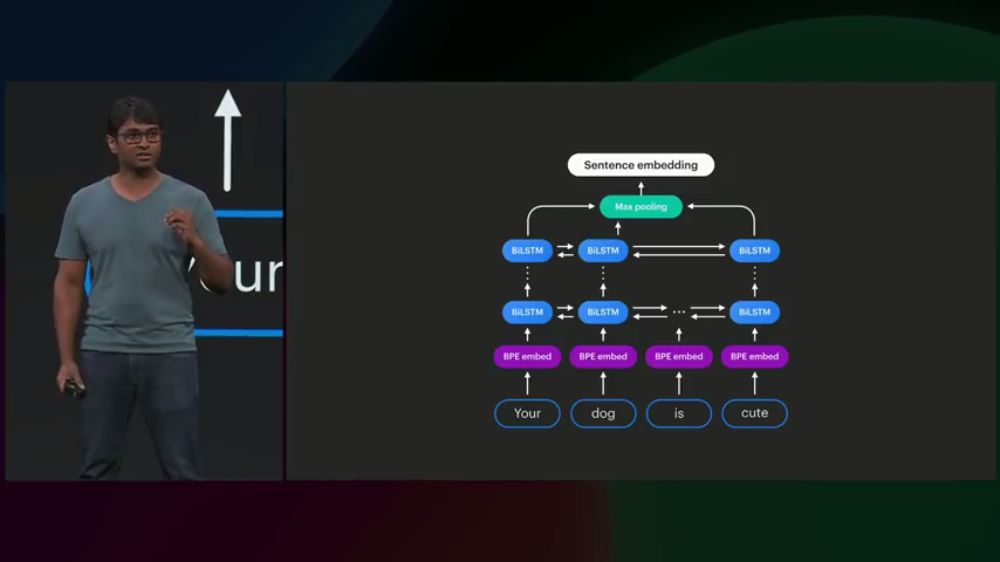
首先,用多层BiLSTM和Max-Pooling将句子映射成向量:
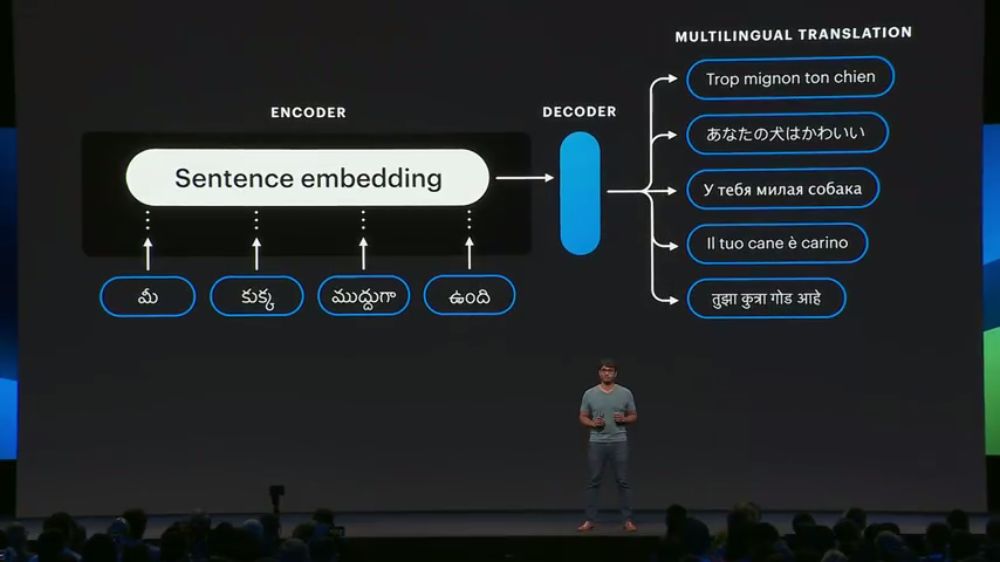
用统一的编码器和解码器进行多语种翻译任务。任务本身并不重要,重要的是通过该任务学习到的句子表示:
Facebook在93个语言、30个语系和22个文字系统上进行了上述训练:

用学到的句子表示,可以统一地为所有语种训练各种NLP任务:

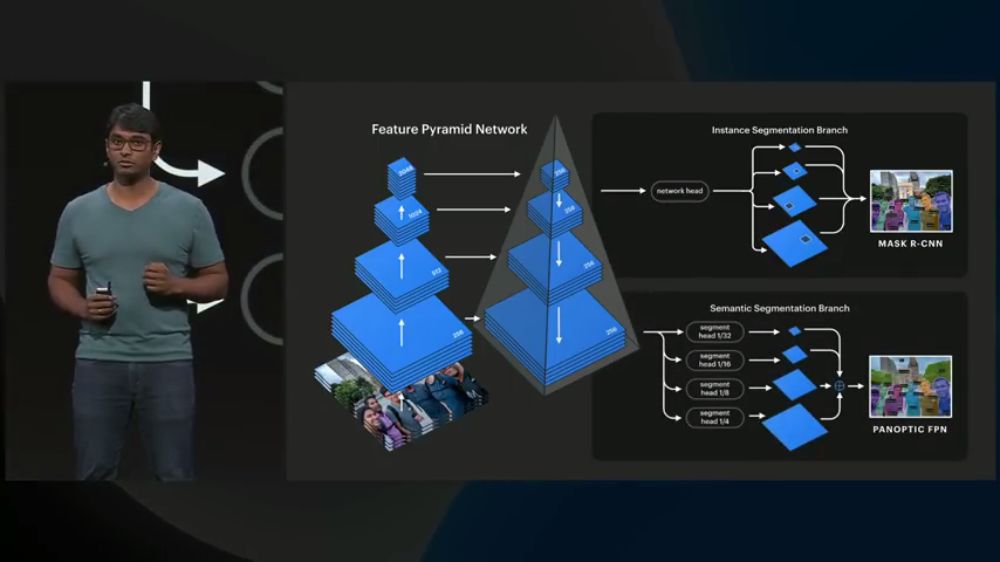
更加全面的图像内容理解
历史算法:

新算法(PANOPTIC FPN)可以更加全面地理解图像,对比上面的结果可以看出,PANOPTIC FPN可以捕捉到背景中的树、天空、建筑等信息,从而更加全面地理解图像:

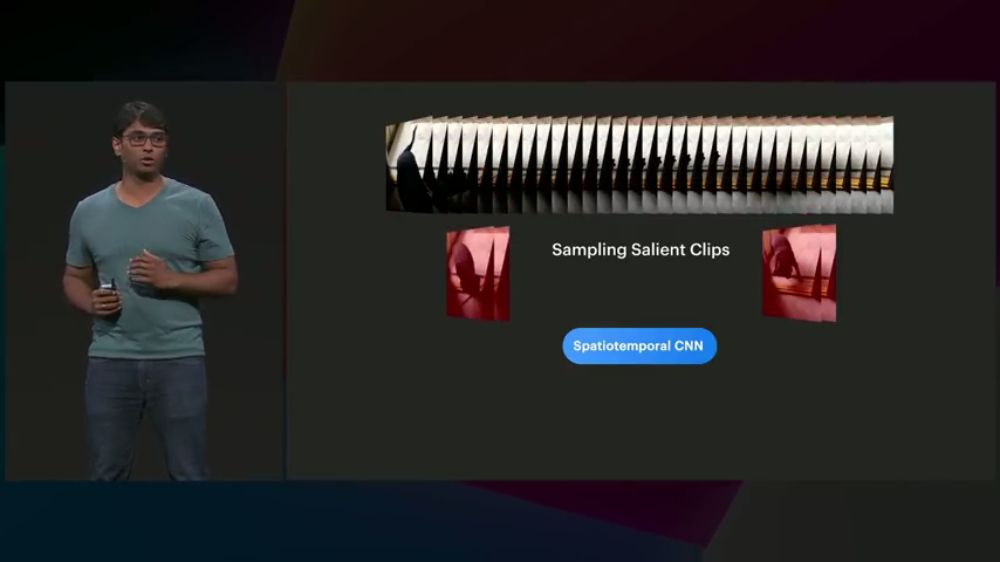
基于显著采样和弱监督学习的视频理解
在视频帧上进行显著采样:
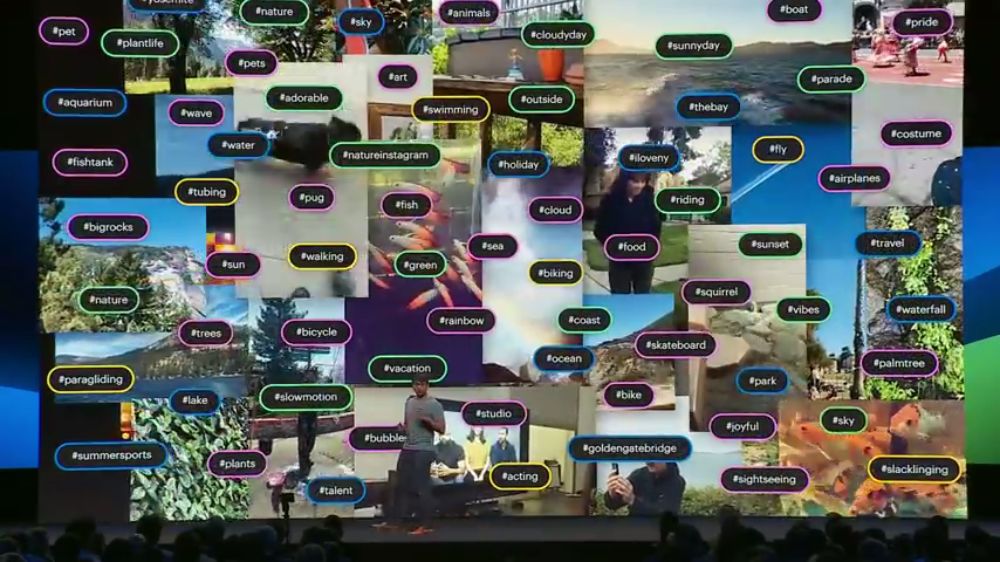
利用视频的标签进行弱监督学习:
性能提升:


请关注专知公众号(点击上方蓝色专知关注)
后台回复“F8D2”就可以获取完整KeyNotes视频下载链接~
参考链接:
https://www.youtube.com/watch?v=j48PqBP-OA0
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!530+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程





