你没见过的《老友记》镜头,AI给补出来了|ECCV 2022
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
诶?这是《老友记》流出未公开镜头了?
还是“子弹时间”特效那种?

只见人物定格的一瞬,机位丝滑运动,一个多角度全方位的厨房出现在了眼前,仿佛我人就站在现场啊。
要知道,在正片里其实只有这两幅画面:


没错,又是AI在搞“魔法”。
在看了《老友记》之后,AI能直接还原出宛如真实现场的3D场景,补足两个切换画面之间人物在不同角度时的姿态。
没拍过的角度画面,它都能重建出来。

还能把一个近景镜头,变成大远景。

乍一眼看去,真的很难分辨出生成效果其实是完全捏造的。
“以后电视剧补拍镜头都省了?”
这就是由UC伯克利大学研究人员提出的重建3D人物和环境的新方法。
网友看后脑洞大开:
可能不出10年,你就能把自己的VR形象放到自己喜欢的节目里了。
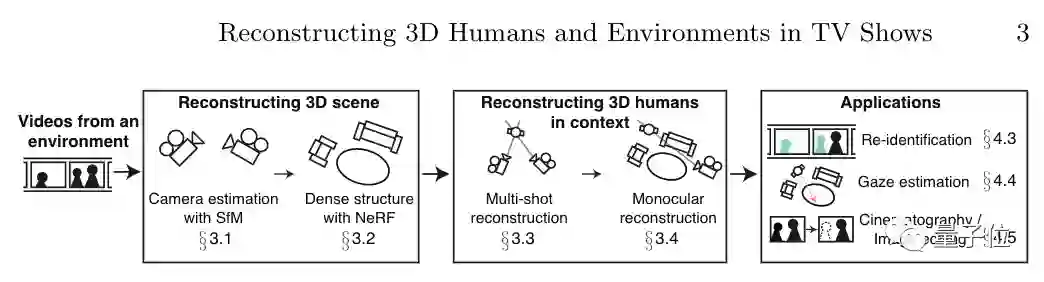
目前,该方法已被ECCV 2022接收。
专门针对电视剧场景重建
研究人员表示,这次提出的新方法就是专门针对电视剧场景的。
除了《老友记》外,他们还3D重建了《生活大爆炸》等7个电视剧的场景。

要知道,使用单个视频来重建3D场景的难度其实还很高,但是电视剧中往往是同一场景拍下了多个画面,这为AI学习提供了非常丰富的图像资料。
本文方法能够在整季剧集中自动运行,计算出各个镜头的摄像机位置信息、静态三维场景结构和人物身体信息,然后将他们整合计算成一个3D场景来。
具体来看,该方法主要分为处理场景信息人物信息两方面。
场景上,基于不同画面,该方法通过SfM(Structure-from-Motion)来估计出拍摄时摄像机的位置。
这种方法是指在只有单个摄像机的情况下,通过分析摄像机移动时拍到的场景来确定3D场景信息。
然后通过分析摄像机与人物之间的位置关系,以此确定出人物所在的区域,然后将两个不同角度的画面整合分析,进行三角定位,以此确定人物的真正位置。

之后,利用NeRF来重建出细致的3D场景信息。
神经渲染辐射场可以将场景的体积表示优化为向量函数,该函数由位置和视图方向组成的连续5D坐标定义。
也就是沿着相机射线采样5D坐标,以此合成图像。
接下来,就是处理场景中人物信息方面。
针对多镜头情况下,在确定好人物所在位置后,使用NeRF就能直接重建出人体3D信息。

而如果是单镜头情况,就需要利用上下帧画面中人体姿势的变化、摄像机位置和环境结构信息来进行重建。
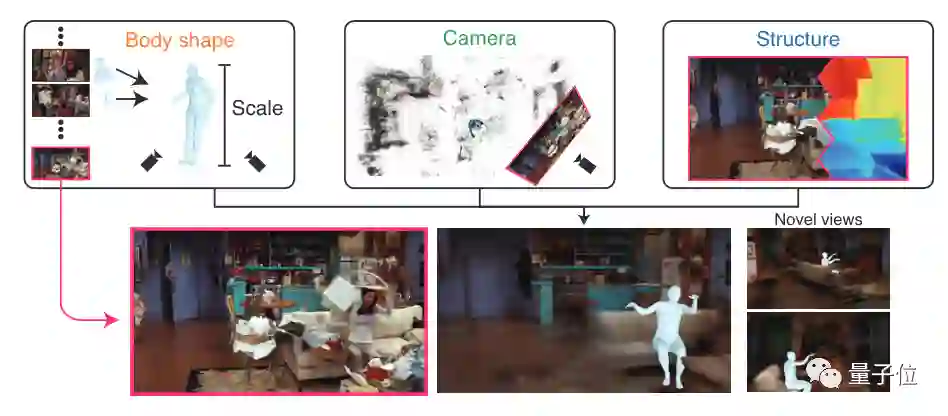
从实验结果中可以看到,该方法最终可以综合得到的3D信息,重新渲染出一个新的画面。

在消融实验中,如果没有确定摄像机、人物的特征信息,最终得到的结果也都不尽如人意。
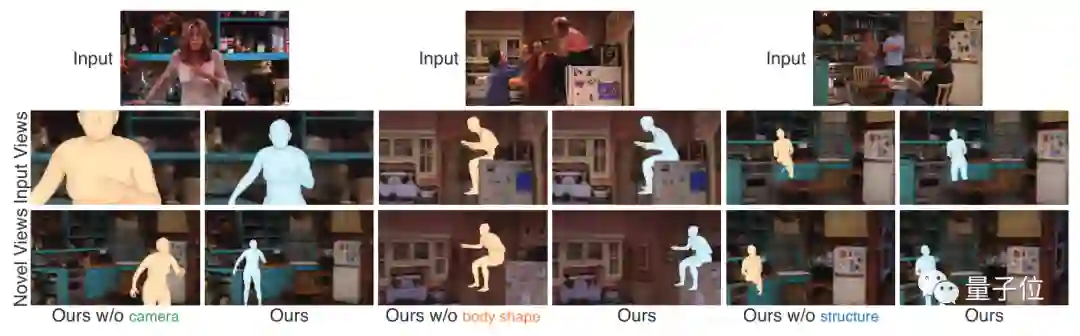
并且,研究人员还对得到的场景进行了数据分析,包括相机距离、人物位置分布。
还提供了编辑选项,可以删除或插入选定对象。

目前,该团队已将代码和论文数据开源。
研究团队来自UC伯克利大学人工智能研究实验室。
作者表示,本文方法在电影、体育节目等领域同样适用。
论文地址:
https://arxiv.org/abs/2207.14279
GitHub地址:
https://github.com/ethanweber/sitcoms3D
项目主页:
https://ethanweber.me/sitcoms3D/
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~


