从三大案例,看如何用 CV 模型解决非视觉问题
作者:Max Pechyonkin来源:pechyonkin,机器之心等

近几年,深度学习已经彻底改变了计算机视觉。由于各类学习资源随处可见,任何人都可以在数天(甚至数小时)内掌握最新技术,并将它应用到自己的领域内。随着深度学习变得越来越普遍,一个重要的问题就是如何将它创造性地应用在不同的领域里。
今天,计算机视觉领域的深度学习已经解决了大量关于图像识别、目标检测和图像分割等方面的问题。在这些领域中,深度神经网络表现出了极其优异的性能。
即使你的数据并不是可视化的,同样可以利用这些视觉领域深度学习模型(特别是 CNN 模型)的强大功能——你所需要做的仅仅是:将你的数据从非视觉领域变换成图像,然后就可以将由图像训练出来的模型应用到你的数据上。理论上而言,任何有局部相关性的数据都能使用卷积网络处理,因此你会惊奇地发现,这种方法竟然出奇得好。
在这篇文章中,我将简单介绍 3 个案例,看一下企业如何将视觉深度学习模型创造性地应用到非视觉领域。在这三个案例中,基本方法都是将非视觉问题转换成适合做图像分割的问题,然后利用深度学习模型来解决。
案例一:石油工业
梁泵(beam pumps)通常在石油工业中被用来从地下抽取石油或天然气。它们由连接在步进梁(walking beam)的发动机提供动力。步进梁将发动机的旋转运动传递到抽油杆的垂直往复运动,从而将石油抽取到地面。

一个步进泵,也成为抽油机。
作为一个复杂系统,梁泵很容易出现故障。为了辅助诊断,在洗盘上安装了一个测量梁杆负载的测功机(dynamometer)。测功机会绘制出一个测功机泵卡(dynamometer pump card),如下图所示,显示出引擎旋转周期内的负载。
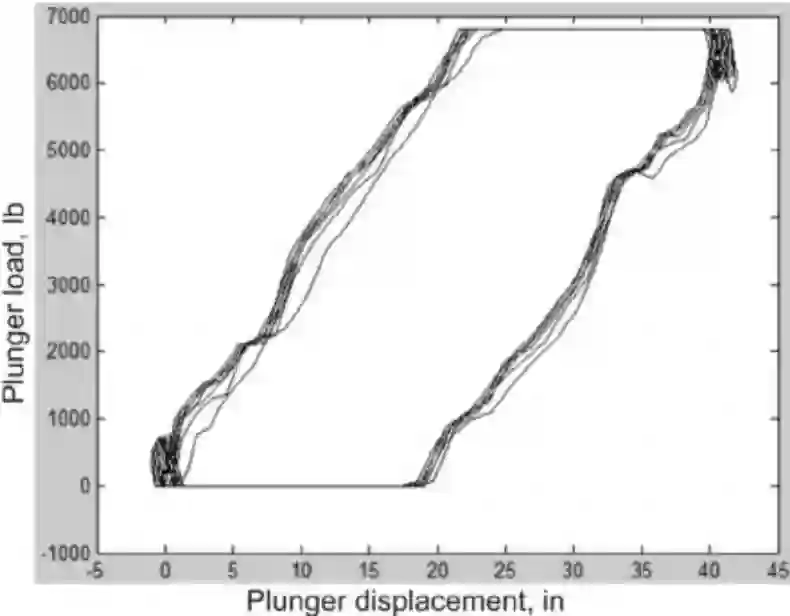
测功机卡
当梁泵出现故障时,测功机卡的形状就会发生变化。通常情况下会邀请专业技术人员来检测测功机卡,并判断哪里出现问题,并提出解决方案。这个过程非常耗时,且只有极为专业的人士才能有效地解决问题。
另一方面,这个过程看起来完全可以自动化。之前也曾尝试用过许多经典的机器学习系统来解决这个问题,但结果并不是很好,正确率只有 60% 左右。
贝克休斯(Baker Hughes)作为众多油田服务公司之一,则采用了一种创新性的方法将深度学习应用到了这个问题上。他们首先将测功机卡转换成图像,并将之作为预训练 ImageNet 模型的输入。结果非常令人振奋,只使用图像分类预训练模型并根据新数据做了些微调,正确率瞬间从 60% 提升到了 93%;对模型进一步的优化后,他们甚至将正确率提高到 97%。
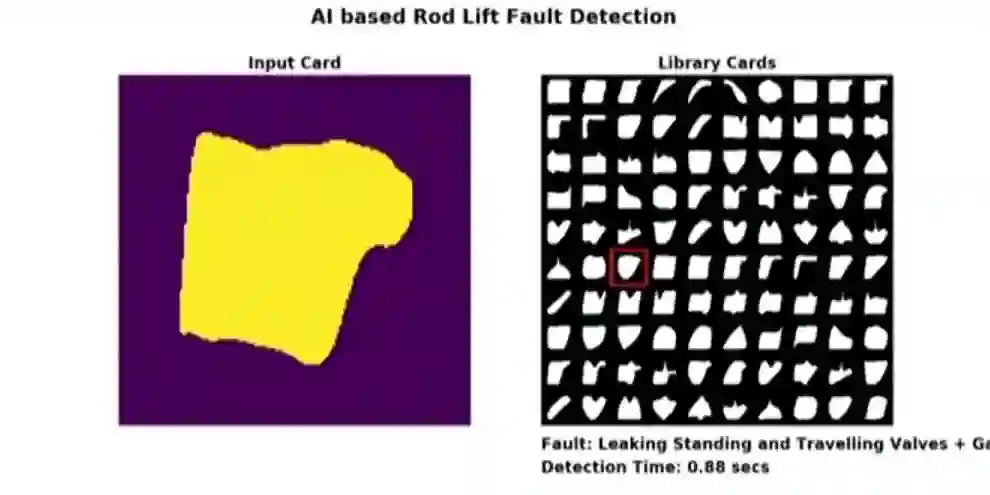
贝克休斯使用系统的一个样例。左图是一张输入图片,右图是缺陷模式的实时分类。整个系统只需要在便携设备上就可以运行,右下角显示了推断时间。
贝克休斯采用这种方法不仅获得了比之前经典机器学习方法更高的精度,甚至他们现在都不再需要梁泵技术专家来花费大量时间诊断问题了。一旦出现机器故障,他们能够立刻进行修复。
想了解更多关于这个案例的内容,你可以:
读一些类似工作的文章: https://www.knepublishing.com/index.php/KnE-Engineering/article/download/3083/6587
或观看视频:https://v.qq.com/x/page/h08318aglac.html
案例二:在线欺诈检测
计算机用户在使用计算机时具有独特的模式和习惯,你浏览网页时使用鼠标的方式或你撰写电子邮件时敲击键盘的方式,都是独一无二的。
在这种特殊情况下,Splunk 解决了根据用户使用计算机鼠标的方式对用户进行分类的问题。如果你的系统可以根据鼠标使用模式唯一识别用户,则可以将其用于欺诈检测。想象一下这种情况:欺诈者窃取某人的登录名和密码,然后使用它们登录并在网上商店购物。由于每个人使用计算机鼠标的方式都是独一无二的,系统可以轻松检测到这种异常并防止发生欺诈性交易,并通知真实账户所有者。
使用专门的 JavaScript 代码就可以收集所有鼠标活动,该程序可以每 5 - 10 毫秒记录一次鼠标活动。结果,每个用户的数据将包含每页每个用户大约 5000 - 10000 个数据点。这里有两个挑战:第一,每个用户都有大量的数据;第二,不同用户的数据集所包含的数据点数量不同。这很不方便,如果序列长度不同,通常需要更为复杂的深度学习框架。
解决方案是将每个用户在每个网页上的鼠标活动转换为单个图像。在每个图像中,鼠标移动由一条线表示,其颜色编码鼠标速度,左右点击由绿色和红色圆圈表示。这种处理初始数据的方法解决了这两个问题:首先,所有图像具有相同的大小;其次,现在基于图像的深度学习模型可以与该数据一起使用。

在每张图中,鼠标运动被表示成一条线,线的颜色代表鼠标速度;左击表示为绿色圆,右击表示为红色圆。
Splunk 使用 TensorFlow + Keras 构建了一个深度学习系统来进行用户分类,他们进行了两个实验:
金融服务网站用户群体的分类——访问类似页面时的常客组和非客户组。他们使用了一个相对较小的仅包含 2000 张图像的训练数据集。在基于 VGG16 的修改架构上训练仅 2 分钟后,系统便能够识别这两个类别,准确度超过 80%。
用户的个人分类。任务是针对给定用户进行预测,来判断使用者是该用户还是其他模仿者。同样是一个非常小的训练数据集,只有 360 张图像;同样是基于 VGG16 的框架,但考虑到数据集较小防止过拟合做了些许调整。经过 3 分钟的训练便可以达到约 78% 的准确率,考虑到这种任务本身是挑战性的,因此这样的结果还是蛮令人振奋的。
更多信息,可以阅读关于这个系统和实验的完整文章:https://www.splunk.com/blog/2017/04/18/deep-learning-with-splunk-and-tensorflow-for-security-catching-the-fraudster-in-neural-networks-with-behavioral-biometrics.html
案例三:鲸鱼的声学检测
在这个例子中,谷歌使用卷积神经网络分析了声音记录并从中检测出了座头鲸。这对于座头鲸的研究是有非常有用的,例如跟踪个体鲸鱼的运动、歌曲的属性、鲸鱼的数量等。在这里,有意思的并不是他们研究的目的,而是如何预处理数据以方便使用卷积神经网络。
将音频数据转换为图像的方法是使用频谱图。频谱图是音频数据基于频率特征的视觉表示。
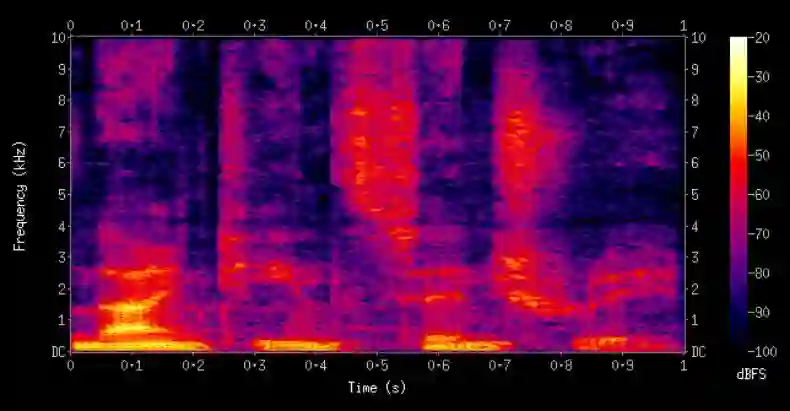
一个例子:一个男性说」nineteenth century」的频谱图。
将声学数据转换为频谱图后,谷歌研究人员使用 ResNet-50 框架来训练模型。他们训练出的模型性能达到:
90% 精度:分类为鲸鱼声音的音频片段中的 90% 是正确的;
90% 召回率:给定鲸鱼声音的录音,有 90%的可能性被标记为鲸鱼。
这个结果令人印象深刻,将很大程度上有助于鲸鱼的研究。
让我们将焦点从鲸鱼切换到你处理音频数据时可以做的事情。创建频谱图时,你可以选择要使用的频率,这取决于你的音频数据类型。对于人类语音、座头鲸歌曲、工业设备录音等,你可能需要不同的频率,因为不同的情况下重要信息往往包含在不同的频段中,这时候就必须依靠你的领域知识来选择参数了。例如如果你正在处理的是人类语音数据,那么你首选的就应该是梅尔频率倒谱系数了。
目前有一些很好的软件来处理音频。Librosa(https://librosa.github.io/librosa/)是一个免费的音频分析 Python 库,可以使用 CPU 来生成频谱图。如果你正在使用 TensorFlow 进行开发并希望在 GPU 上进行频谱图计算,那么这也是可以的(https://www.tensorflow.org/api_guides/python/contrib.signal#Computing_spectrograms)。
想了解 Google 如何使用座头鲸数据的详细内容,可以参考 Google AI 的博客文章: https://ai.googleblog.com/2018/10/acoustic-detection-of-humpback-whales.html。
总而言之,本文中概述的一般方法遵循两个步骤。首先找到一种将数据转换为图像的方法,然后使用一个预训练的卷积网络或自己从头开始训练一个卷积网络。第一步比第二步更难,这需要你去创造性思考如何将你的数据转换成图像,希望我提供的示例对解决你的问题有所帮助。
原文地址:https://towardsdatascience.com/deep-learning-vision-non-vision-tasks-a809df74d6f
广告 & 商务合作请加微信:kellyhyw
投稿请发送至:mary.hu@aisdk.com




