应用Protocol Buffers替代JSON的五个理由

Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
面向服务的体系架构作为一种从大规模应用中提取需求的可靠手段,缓解了应用规模增长带来的痛苦,因此在Ruby和Rails开发社区中享有很好的声誉。这些新开发的小型服务一般还在使用Rails或者Sinatra,并且用JSON通过HTTP进行交互。虽然JSON作为数据交换格式有很多显著的优点——可读性强,容易理解,应用性好——但它也有自己的弊端。
在那些浏览器和JavaScript并不直接消耗数据的服务——特别在内部服务这块——像Google‘s Protocol Buffers这种结构型编码的数据格式会是比JSON更好的选择。如果你以前从未接触过Protocol Buffers,不用担心——接下来我会简单介绍它们在Ruby中的用法,然后告诉你为什么要应用Protocol Buffers替代JSON的五个原因。

简单介绍Protocol Buffers
首先,什么是Protocol Buffers? 官方文档中是这样定义的:
“Protocol Buffers 是一种高效可扩展的结构型数据编码格式。”
Google开发Protocol Buffers为了用于他们自己的内部服务。它是一种二值编码格式,能让你用某种规范语言给数据指定一个结构对象,像这样:

你可以在命名空间中打包信息或者像上面代码那样在顶层进行声明。这段代码为一个Person类型定义了对象集合,这个类型有三个属性:id, name 和 email 。除了属性,你还可以指定属性的类型来规定数据的编码方式和传输方式——上面例子中我们看到有int32和string类型。用关键字来定义数据结构(像required和optional),同时属性会做上编号,以便反向兼容,这点在后面会详细提到。
Protocol Buffers规范语言支持多种版本:Java,C,Go等等,大部分流行的编程语言都能支持。Ruby当然也在其中,而且多种不同Gems能够支持应用Protocol Buffers。这就意味着实现的编程语言不同也能用同一种规范在系统间传输数据。
举个例子,安装ruby-protocol-buffers 给Ruby Gem安装了一个叫做ruby-protoc的程序,能够结合Protocol Buffers的主库(在OSX系统中为brew install protobuf命令)自动生成底层类文件用来编解码数据。给ruby-protoc程序输入proto文件会生成如下Ruby类:
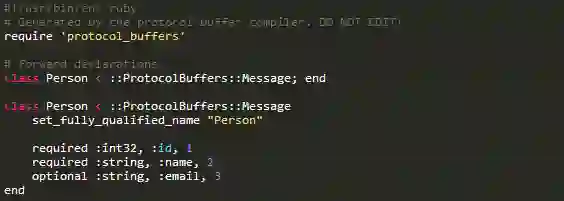
可以看到通过这种对象集合,我们能自动得到一个类用来把数据转换成Protocol Buffer格式(更多细节可以查看Gem中ProtocolBuffers::Message基类的代码文档)。现在我们已经对此有了初步的了解,下面我将更深入地说明应用Protocol Buffers替代JSON的五个原因。
#1. 对象集合很实用
有一个讽刺的事实是,我们仔细地在数据库中建立我们的数据模型,通过维护层层代码来保证这些数据模型不受破坏,却在服务间交换数据的时候置之不顾。而且经常情况下我们在系统间的数据交界处都依赖不统一的代码,这就导致数据的重要结构丢失。如果把你的数据对象按照语义结构打包在proto格式中,那么应用间交换的数据则能保证不被丢失,数据交界处也能保证规则的统一。
#2. 反向兼容很轻松
在proto格式的定义中经过编号的属性可以满足版本检查的需求,这也是设计和应用Protocol Buffers的明显动机之一。就像官方文档所说,这个协议的设计一部分就是为了避免检查协议版本时写出一堆不够简洁的代码,像这样:

有了属性编号,我们不再需要更改代码以反向兼容旧版本。如官方文档所描述的,一旦Protocol Buffers被应用:
“新的域可以被轻松添加,而且那些不需要检查数据的中间级服务也能在不知道所有属性信息的条件下很容易地解析和传递这些数据的属性信息。”
有了部署多个JSON服务的经验以后,我十分清楚更新对象集合和反向兼容过程中遇到的各种弊端,所以我相信属性编号能够解决这些弊端,让升级服务变得更简单。
#3. 更少的样板代码
除了版本检查麻烦和缺少反向兼容这些弊端外,HTTP服务中JSON端点还一般依赖专门手写的样板代码来处理Ruby对象通过JSON编解码的过程。解析器和显示器的类经常包含隐藏的逻辑,暴露出手动解析每个新数据类型时容易出错的弱点,然而当应用Protocol Buffers生成一个底层类(一个我们一般不会去动的类)的时候这些问题都能轻松解决。当对象集合需要更新时,我们也可以用proto生成的类解决相应问题,使我们能集中精力在开发应用和产品本身。
#4. 关键字和可扩展性
在Protocol Buffers定义中像required,optional,repeated这些关键字都十分有用,能让我们在对象集合层面定义数据的结构,而类的工作细节在不同的编程语言下都会自动帮你处理。比如,Ruby的protocol_buffers库会在你尝试建立一个没有required属性的对象实例时报错。我们也可以通过新增属性编号为该属性更改required或者optional属性。有了这种基于数据语义的灵活性,序列化编码格式将变得更加实用。
我们也可以把proto定义嵌套在其他定义中,所以我们也可以用一般的Request和Response结构控制其他数据结构的传输,使服务间的数据传输变得真正的灵活和安全。像Riak数据库系统就已经把Protocol Buffers应用到十分成熟的地步,我推荐大家去了解下它们。
#5. 简单的语言互操作性
因为Protocol Buffes可以用不同语言实现,它能使多语言应用的互操作性在我们的架构下变得非常简单。如果我们用Java或Go建立了一个新服务,或甚至和Node,Clojure或Scala编写的后端进行数据交换,我们都可以简单地把proto文件交给目标语言的代码生成器,而这些架构间的互操作性和安全性都能得到保证。在目标语言的代码实现中,平台专有的数据类型可以直接为你处理好,省去JSON编解码体系中属性匹配和数据类型匹配的时间和精力,让我们能专注于解决自己的问题。
什么时候JSON会是更好的选择呢?
确实有些时候JSON仍比Protocol Buffers更适合需要,包括以下几种情况:
希望代码可读性更强
浏览器直接面向服务数据
服务端应用是基于JavaScript
不准备把数据模型和对象集合绑定
带宽不足以增加更多的开发工具
运行不同类型的网络服务带来的工作负荷已经过大
可能情况还有更多。最终需要永远牢记的是利弊的权衡,盲目选择一项技术很难达到成功。
结论
Protocol Buffers在内部服务的数据传输方面和JSON相比具有多项优势。虽然不能完全取代JSON,尤其对于浏览器需要直接面向服务数据的时候,但是Protocol Buffers在其他方面比如像编解码速度、传输数据所占空间大小等都具有更好的表现。
你会从大规模应用中提取什么服务呢?你会选择JSON还是Protocol Buffers呢?我们期待你的经验分享并在评论区进行留言。
英文原文:https://codeclimate.com/blog/choose-protocol-buffers/
译者:GeeKnight



