体素科技:2018年,算法驱动下的医学影像分析进展
机器之心原创
作者:体素科技、邱陆陆
自 2012 年 AlexNet 挑战 ImageNet 获得巨大成功以来,用于图像领域的深度学习算法以令人目不暇接的速度飞速演化着。通用图像领域中,有明确边界的问题,例如特定类别有标注数据的物体检测、定位、识别,乃至特定场景的图像生成、一定精确度内的图像分割,都出现了令人更新认知的深度学习解答。
目前,站在深度学习研究一线的计算机视觉研究者们,有相当一部分深入到更细分的、与应用场景联系更紧密的任务中,同时扩展算法能够覆盖的数据类型。
2018 年,在医疗影像这个分支中,来自加州的人工智能医疗公司体素科技,结合自身产品线的开发路径,发表了多篇论文,论文探讨了如何利用深度学习算法临床决策支持:例如用端到端算法处理影像中分割问题、 配准问题,以及如何在标注数据有限,且迁移学习困难的情况下,利用代理监督和联合训练获得更好的模型效果。以下为论文介绍:
3D PDV-Net:端到端的器官分割
器官分割是导航(navigation)的核心任务,算法需要找出正常人器官、病情严重的患者器官乃至手术后形态发生显著变化的器官的位置:这是放疗靶区勾画和病灶量化分析几乎唯一可依赖的凭据。
现存的肺叶分割方法非常耗时,并需要依赖气管/血管分割先验作为初始输入,且通常还需要与影像科医生交互才能达到最佳结果。这篇工作提出了一个基于三维渐进密集 V 形深度网络(progressive dense V-network,PDV-NET)的可靠、快速、且完全自动的肺叶分割模型。利用一台 Nvidia Titan XP GPU,PDV-NET 平均 2 秒就可以通过网络的一次前向传播来完成一次肺叶分割,且完全去除了对先验和任何用户介入的依赖。
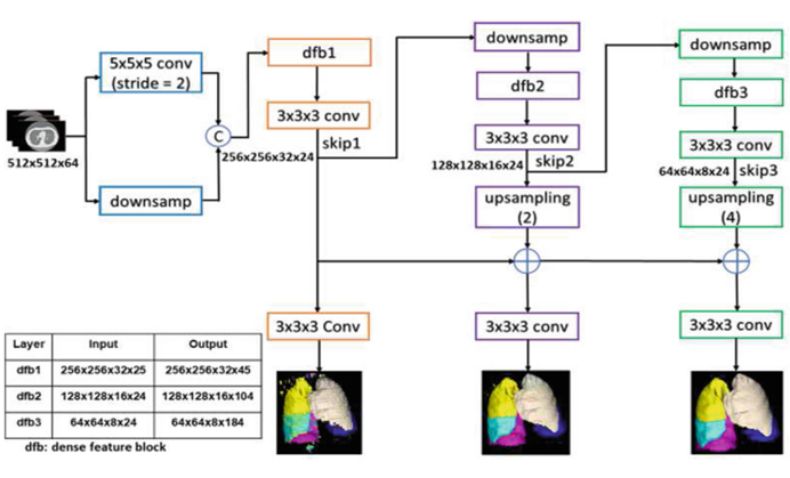
图:用于肺叶分割的 PDV-net 模型,分割结果逐渐提高直到得到最终结果。
PDV-net 以 Dense V-net 为基础网络,结合渐进整体嵌套网络(progressive holistically-nested networks)而成。网络主要由 3 条路径组成,每条路径都由密集特征模块(dense feature block,dfb)和卷积层构成,位于前面的 dfb 的输出通过卷积和下采样后,会成为之后的 dfb 的输入。换言之,PDV-net 渐进地提取不同层次的图像特征,最后以串联的方式将这些特征结合在一起,得到最终的分割结果。
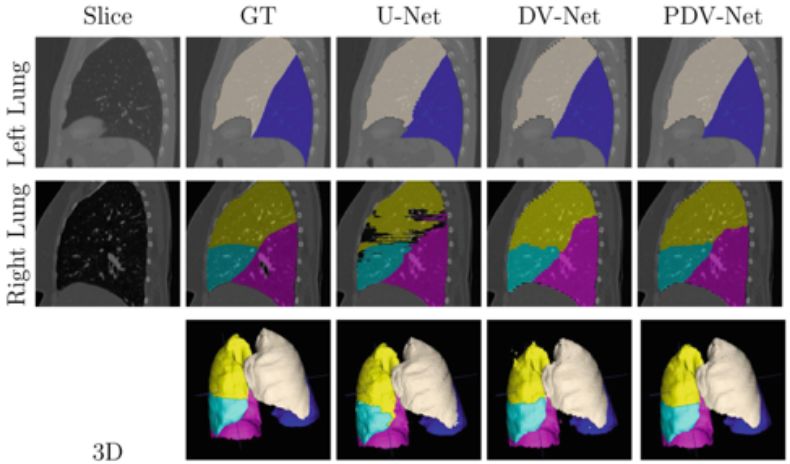
图:真值与 U-net、 dense V-Net (DV-Net)、3D progressive dense V-Net (PDV-Net) 的分割结果的定性比较,可以看出 PDV-Net 的结果没有其他模型会产生的噪声。颜色标记:杏仁白:LUL,蓝:LLL,黄:RUL,青:RML,粉:RLL。
模型在 Lung Image Database Consortium(LIDC)数据集的 84 张胸腔 CT 和 Lung Tissue Research Consortium(LTRC)的 154 张病态胸腔 CT 上进行了测试。模型输出的肺叶分割的 Dice score 在 LIDC 上达到了 0.939 ± 0.02,在 LTRC 上达到了 0.950 ± 0.01,此测试结果显著高于 2D U-net model 和 3D dense V-net 的结果。此外,模型在 LOLA11 challenge 的 55 例上测试并达到了 0.935 的 average Dice score,与最佳参赛队伍的 0.938 相当。
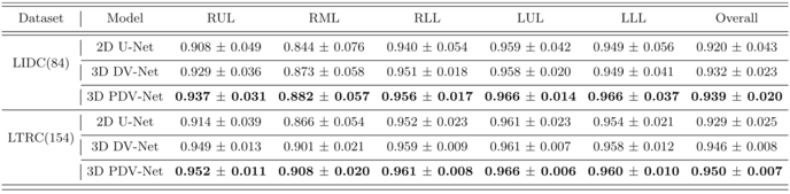
图:PDV-net 与 2D U-net 和 3D dense V-net 在 LIDC 和 LTRC 数据集上的分割结果 Dice score 比较。
研究者也对模型进行了鲁棒性测试,显示出我们的模型对于健康与疾病的 CT 例、不同的厂家的 CT 机的输出、以及同一 CT 机的不同 CT 重构设置产生的不同 CT 例均能够进行可靠的肺叶分割。
该工作获得医学影像顶级会议 MICCAI 2018 深度学习影像分析板块最佳论文。
基于无监督神经网络的可变形-仿射混合配准框架
配准(registration)是把不同影像按照生理结构对齐达到重合的目的,用于对比不同检查中的差异。其中,影像的背景部分可以大刀阔斧地调整,通过变形变换(deformation transformation),把病人每次拍照时因为姿势的不同、压到的腔体部位不同而导致的无法重合问题通过形状、大小、角度的变换来进行对准,保证多组照片之间互相可比;而病灶部分只能严谨地微调,通过只有六个空间自由度(dof)的刚体变换(rigid transformation)进行旋转和位移,保证病灶信息不损失。
配准可以被分为可变形配准(deformable registration)和仿射配准(affine registration)两种。目前,深度学习算法已经在可变形配准中获得了应用,相比于比传统的方法,在速度上有多个数量级的提高。然而,基于深度学习的可变形配准模型通常需要传统方法所得的仿射配准进行预配准。这和利用深度学习模型达到快速可变形配准的目的相矛盾。此外,现有的深度学习可变形配准模型的训练必须依赖手动标注的仿射变换真值或者有偏差的仿射变换模拟真值,前者耗费大量时间,后者影响模型的效果。
因此,研究者提出了一个可以利用真实医疗影像进行无监学习的仿射配准模型。在此之上,还提出了一个混合仿射与可变形配准的统一训练框架。
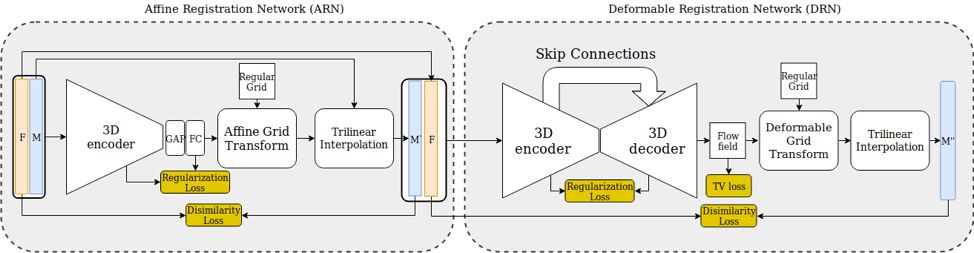
图:混合仿射与可变形配准的统一训练框架。
该方法由仿射配准网络(ARN)与可变形配准网络(DRN)组成。ARN 的输出是描述 3D 仿射变换的 12 个参数,DRN 的输出是描述每个体素位移的形变向量场。通过将网络所输出的仿射和可变形变换作用在有移动的 CT 图像上并进行线性插值,就可以得到配准后的 CT 图像。
在模型训练方面,描述图像全局相似程度的 Dice score 被直接用作优化的目标;此设计使手工标注或者模拟配准真值过程变得不必要。
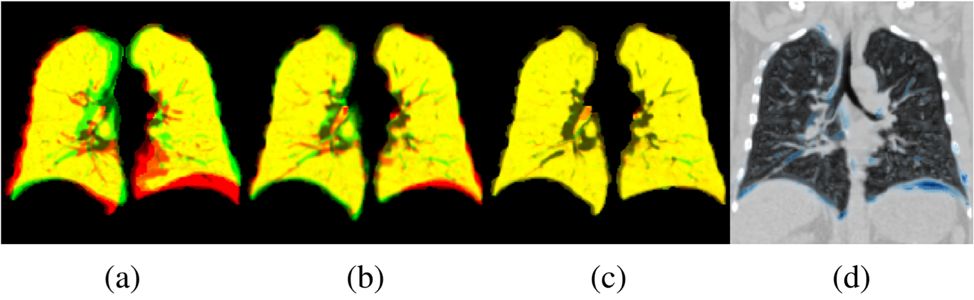
图:(a)固定的与移动后的 CT 对冠状面(b)ARN 仿射配准结果(c)DRN 可变形配准结果(d)模型输出的形变场的强度与移动 CT 冠状面的重合图。
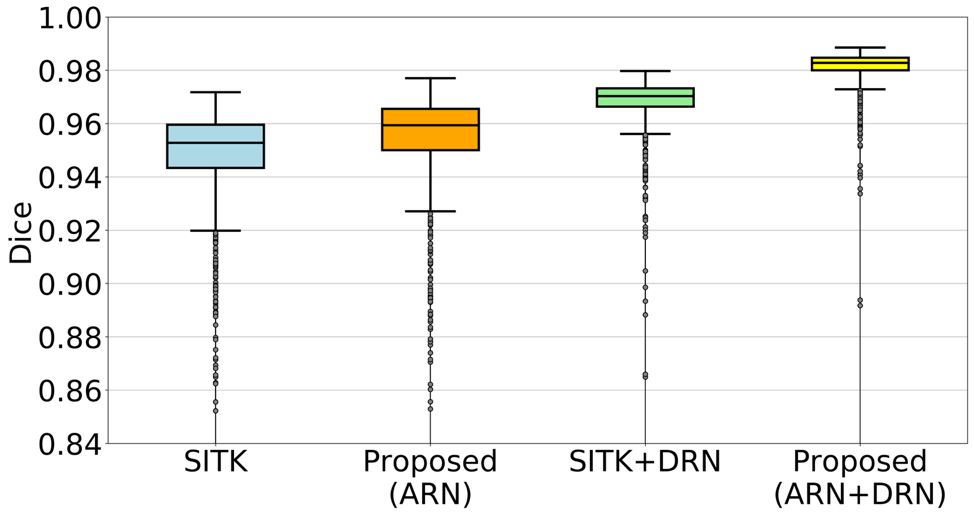
图:用肺部重合度表达的配准准确率。ARN+DRN 配准模型较其对应的基准模型在准确率上有显著提高。
利用代理监督进行预训练解决标注有限问题
医疗影像和自然影像之间的明显差异决定了研究者很难利用迁移学习弥补标注数据不足问题:大量用于 CT、MRI 影像的模型是三维的,无法使用 ImageNet 等数据库进行预训练,即使是用于病理切片,眼底,皮肤等影像的二维模型,也只是与自然图像在空间与色彩维度上保持了一致,由于图像内容相差甚远,迁移学习的作用也十分有限。而另一方面,医疗影像数据的标注难度远胜于普通图像,大规模数据集的建立几乎是无法完成的任务。
给定这样的现实情况一些研究者选择以「代理监督」的方法,利用未标注的医疗图像辅助深度学习模型。
本文中,作者在胸部 CT、眼底图像和皮肤图像上,用旋转、重建和上色这三种代理监督方法,对 4 个不同任务进行了预训练。
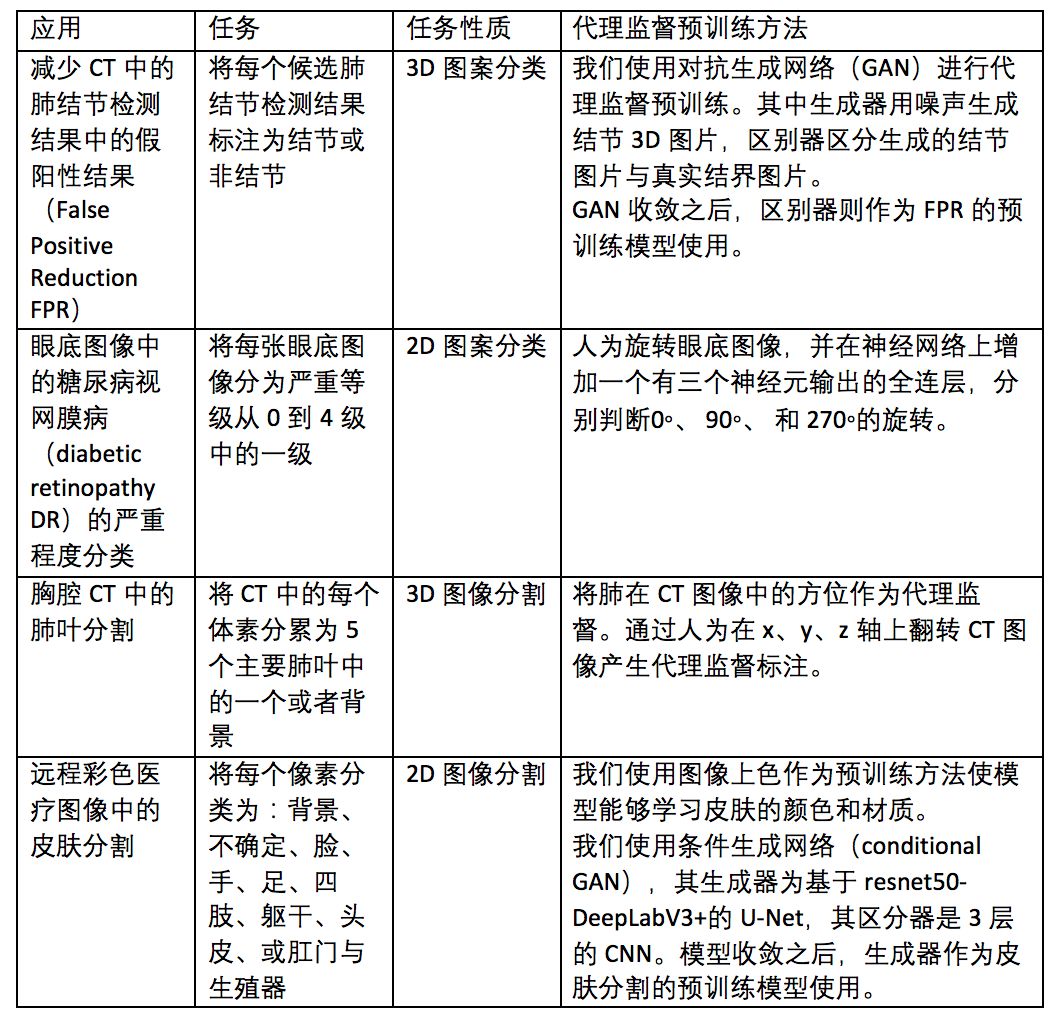
图:任务及代理监督方法。
研究显示:
当有标注训练数据较少时,代理监督模型预训练效果显著,当有标注训练数据增多时,代理监督效果减弱。
通过代理监督预训练的深度模型,比在同一训练集上参数随机初始化的深度模型性能更优。
在医疗图像上进行预训练的模型,比在自然图像上进行预训练的模型进行迁移学习后效果更优。这显示出大量存在的未标注的医疗图像在模型训练时还有很多未被开发的价值。
这些研究结论为训练性能更强的用于医学图像分析的深度模型提供了一些可以广泛应用的准则。
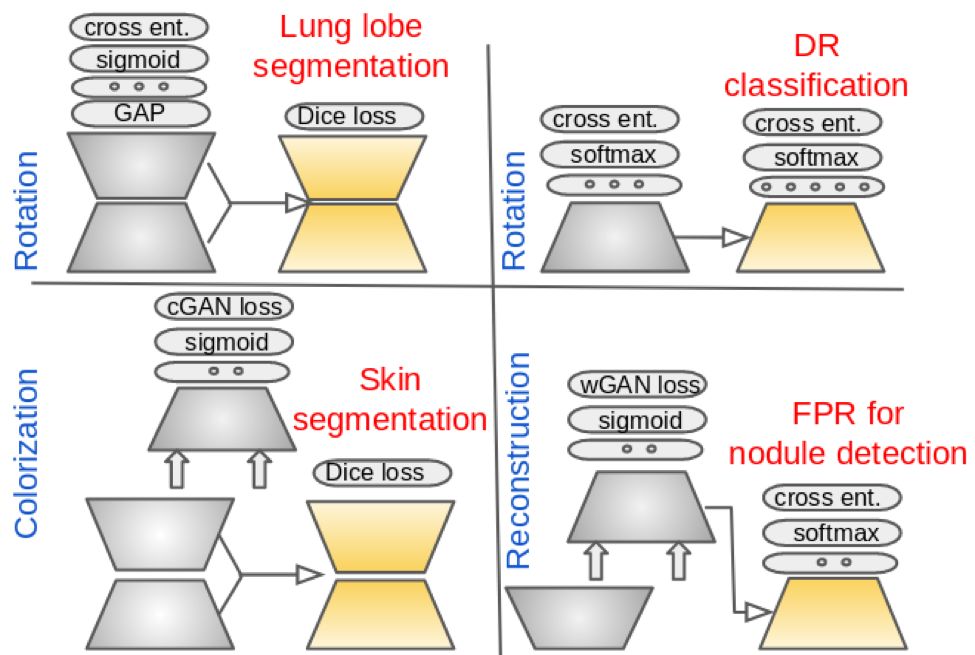
图:代理监督方法以及目标任务模型示意图。每格左侧的网络为代理任务,右侧的网络为目标任务。灰色梯形指代未训练的参数,黄色梯形指代预训练后的参数。
据了解,该论文已被 ISBI 2019接收。
多任务联合检测网络
传统的医疗影像识别模型通常采用端对端的分类方式:输入图片,输出判别结果。但是以皮肤病为例,此类方法在具体场景的应用中有很大的局限性。首先,皮肤病的种类繁多,仅书本记载的皮肤病种就多达数千种,因此用一个单一模型来涵盖所有的皮肤病及其变种是不现实的。其次,皮肤病的表现复杂。不同的疾病可能出现相似的表现;同样的疾病在不同人身上、不同部位、不同发病时期,都会有不同的表现。第三,皮肤病的诊断判别通常需要对患者病史、体格检查、实验室和其他相关检查的检查结果等进行综合分析,仅从图片很难进行准确的皮肤病判别。
针对这一现象,研究者选择在病种判别之外,引入皮肤损害作为联合目标,同时关注病灶级别目标和整体图像的识别,提高模型的能力。
皮肤损害(简称皮损)是皮肤病最重要的体征,是对各种皮肤病进行诊断和鉴别的重要依据。相对于皮肤病来说,皮损类型具有种类相对较少(原发性皮损和继发性皮损共数十种)、皮损分类明确、泛化程度高等优点。根据皮肤病判别的特殊性,体素科技提出了多任务联合检测网络(Multi-task Joint Detection Network)来进行皮肤病的学习。
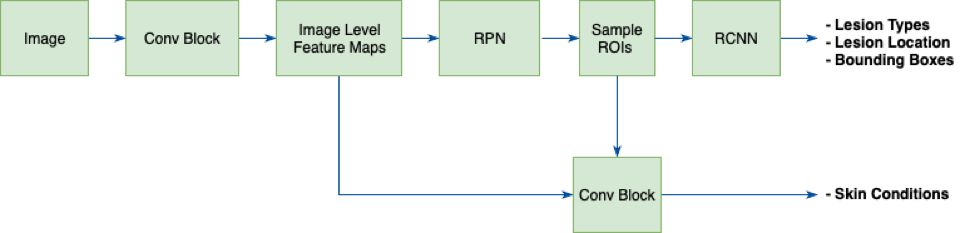
图:皮肤病多任务联合检测网络结构示意图。
该网络同样以图片作为输入,但输出结果包含了皮损类型(Lesion Types)、皮损部位(Lesion Location)、皮损边框(Lesion Bounding Box)以及综合以上结果得出的最终皮肤病判别(Skin Conditions)。采用上述网络,研究者将 100 种常见皮肤病的判别分类模型提高了 10%,并且模型预测的结果更加合理。

References:
[1] Terzopoulos, D., Ding, X., & Tajbakhsh, N. Automatic, Fast, Reliable Lung Lobe Segmentation Using a 3D Progressive Dense V-Network.