人工智障 2 : 你看到的AI与智能无关
本文转载自微信公众S先生(ID:TheMisterS),作者Mingke。
文章通俗易懂,直击人工智能的核心问题,解决了我的很多疑问,强烈推荐给大家阅读。
“ Artificial-Intelligently Challenged ”
前言
大家好,我又出来怼人了。
两年前,写了一篇文章《为什么现在的人工智能助理都像人工智障》,当时主要是怼“智能助理们”。这次呢则是表达 “我不是针对谁,只是现在所有的深度学习都搞不定对话AI”,以及“你看都这样了,那该怎么做AI产品”。
- 阅读门槛 -
时间:这篇真的太长了(近3万字)根据预览同学们的反馈,通常第一次阅读到Part 3时,会消耗很多精力,但读完Part 3才发现是精华(同时也是最烧脑的部分)。请大家酌情安排阅读时间。
可读性:我会在内容里邀请你一起思考(无需专业知识),所以可能不适合通勤时间阅读。你的阅读收益取决于在过程中思考的参与程度。
适合人群:对话智能行业从业者、AIPM、关注AI的投资人、对AI有强烈兴趣的朋友、关心自己的工作会不会被AI代替的朋友;
关于链接:阅读本文时,无需阅读每个链接里的内容,这并不会影响对本文的理解。
- 关于“人工智障”四个字 -
上一片文章发出后,有朋友跟我说,标题里的“人工智障”这个词貌似有点offensive。作为学语言出身的,我来解释一下这个原因:
最开始呢,我是在跟一位企业咨询顾问聊人工智能这个赛道的现状。因为对话是用英语展开的,当时为了表达我的看法 “现在的智能助理行业正处在一种难以逾越的困境当中”,我就跟她说“Currently all the digital assistants are Artificial-Intelligently challenged”。
她听了之后哈哈一笑。“intelligently challenged”同时也是英文中对智障的委婉表达。 假设不了解这个常识,她就可能忽略掉这个梗,尽管能明白核心意思,只是不会觉得有什么好笑的。那么信息在传递中就有损失。
写文章时,我把这个信息翻译成中文,就成了“人工智障”。但是因为中文语法的特性,有些信息就lost in translation了。比如实际表达的是“一种困境的状态”而不是“一件事”。
(顺便说一下,中文的智障,实际上是政治正确的称呼,详见特殊奥运会的用词方法。)
为什么要写那么多字来解释这个措辞?因为不同的人,看见相同的字,也会得到不同的理解。这也是我们要讨论的重点之一。
那么,我们开始吧。
Part 1
对话智能的表现:智障

Sophia in AI for Good Global Summit 2017. Source: ITU
2017年10月,上图这个叫Sophia的机器人,被沙特阿拉伯授予了正式的公民身份。公民身份,这个评价比图灵测试还要牛。何况还是在沙特,他们才刚刚允许女性开车不久(2017年9月颁布的法令)。
Sophia经常参加各种会、“发表演讲”、“接受采访”,比如去联合国对话,表现出来非常类似人类的言谈;去和Will Smith拍MV;接受Good morning Britain之类的主流媒体的采访;甚至公司创始人参加Jim Fallon的访谈时一本正经的说Sophia是“basically alive”。

Basically alive. 要知道,西方的吃瓜群众都是看着《终结者》长大的,前段时间还看了《西部世界》。在他们的世界模型里,“机器智能会觉醒” 这个设定是迟早都会发生的。
普通大众开始吓得瑟瑟发抖。不仅开始担心自己的工作是不是会被替代,还有很多人开始担心AI会不会统治人类,这样的话题展开。“未来已来”,很多人都以为真正的人工智能已经近在咫尺了。
只是,有些人可能会注意到有些不合理的地方:“等等,人工智能都要威胁人类了,为啥我的Siri还那么蠢?”
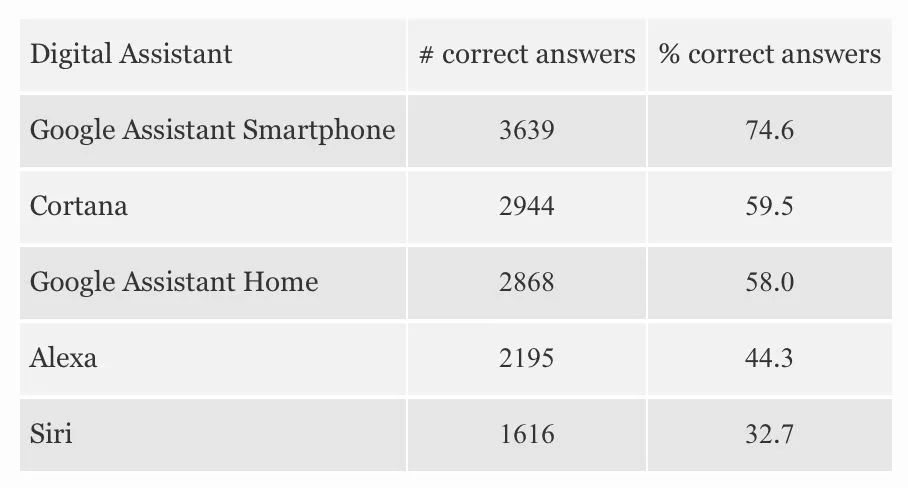
我们来看看到2018年末在对话智能领域,各方面究竟发展的如何了。
“ 不要日本菜 ”
我在2016年底做过一个测试,对几个智能助理提一个看似简单的需求:“推荐餐厅,不要日本菜”。只是各家的AI助理都会给出一堆餐厅推荐,全是日本菜。
2年过去了,在这个问题的处理上有进展么?我们又做了一次测试:
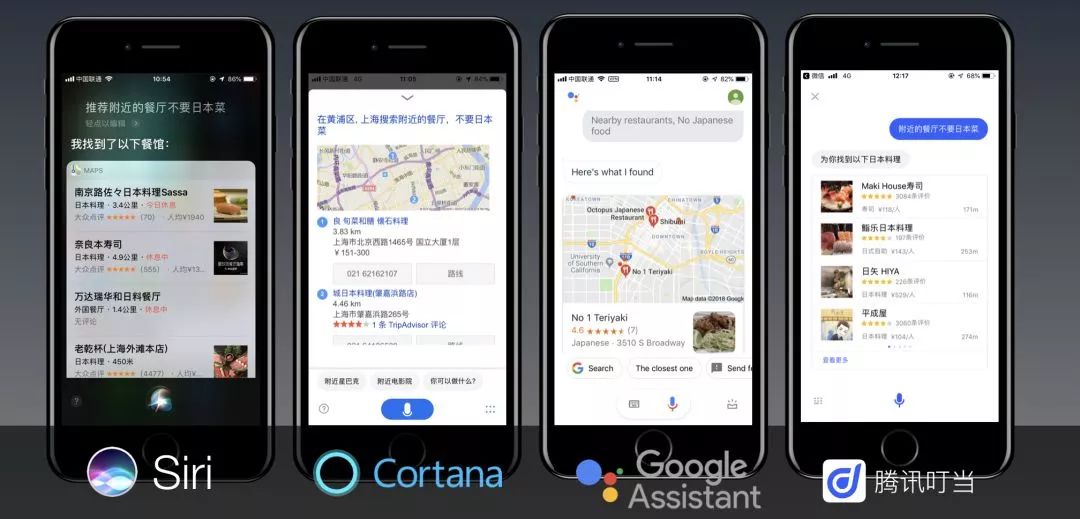
结果是依然没有解决。“不要”两个字被所有助理一致忽略了。
为什么要关注“不要”两个字?之前我去到一家某非常有名的智能语音创业公司,聊到这个问题时,他家的PM显出疑惑:“这个逻辑处理有什么用?我们后台上看到用户很少提出这类表达啊。”
听到这样的评论,基本可以确定:这家公司还没有深入到专业服务对话领域。
场景方面,一旦深入进服务领域里的多轮对话,很容易会遇到类似这样的表达 :“我不要这个,有更便宜的么?”。后台没有遇到,只能说用户还没开始服务就结束了。场景方面与AI公司的domain选择有关。
但是在技术方面,则是非常重要的。因为这正是真正智能的核心特点。我们将在part 2&3详细聊聊这个问题。现在先抛个结论:这个问题解决不了,智能助理会一直智障下去的。
“ To C 团队转 To B ”
自从2015年几个重要的深度学习在开发者当中火了起来,大小公司都想做“Her”这样面对个人消费者的通用型智能助理(To C类产品的终极目标)。一波热钱投给最有希望的种子队伍(拥有Fancy背景)之后,全灭。目前为止,在2C这方面的所有商用产品,无论是巨头还是创业公司,全部达不到用户预期。
在人们的直觉里,会认为“智能助理”,处理的是一些日常任务,不涉及专业的需求,应该比“智能专家”好做。这是延续“人”的思路。推荐餐厅、安排行程是人人都会做的事情;却只有少数受过专业训练的人能够处理金融、医疗问诊这类专业问题。
而对于现在的AI,情况正好相反。现在能造出在围棋上打败柯洁的AI,但是却造不出来能给柯洁管理日常生活的AI。
随着to C助理赛道的崩盘,To B or not to B已经不再是问题,因为已经没得选了,只能To B。这不是商业模式上的选择,而是技术的限制。目前To B,特别是限定领域的产品,相对To C类产品更可行:一个原因是领域比较封闭,用户从思想到语言,不容易发挥跑题;另一方面则是数据充分。
只是To B的公司都很容易被当成是做“外包”的。因为客户是一个个谈下来的,项目是一个个交付的,这意味着增长慢,靠人堆,没有复利带来的指数级增长。大家纷纷表示不开心。
这个“帮人造机器人”的业务有点像“在网页时代帮人建站”。转成To B的团队经常受到资本的质疑: “你这个属于做项目,怎么规模化呢?”
要知道,国内的很多投资机构和里面的投资经理入行的时间,是在国内的移动互联起来的那一波。“Scalability”或者“高速增长”是体系里最重要的指标,没有之一。而做项目这件事,就是Case by case,要增长就要堆人,也就很难出现指数级增长。这就有点尴尬了。
“你放心,我有SaaS!哦不,是AIaaS。我可以打造一个平台,上面有一系列工具,可以让客户们自己组装机器人。”
然而,这些想做技能平台的创业公司,也没有一个成功的。短期也不可能成功。
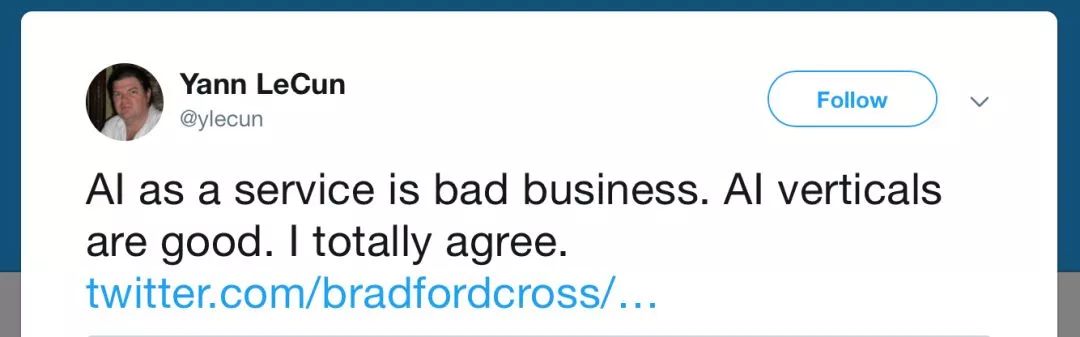
Yann LeCun对AIaas的看法
主要的逻辑是这样的:你给客户提供工具,但他需要的是雕像——这中间还差了一个雕塑家。佐证就是那些各家试图开放“对话框架”给更小的开发者,甚至是服务提供者,帮助他们“3分钟开发出自己的AI机器人”,具体就不点名了。自己都开发不出来一个让人满意的产品,还想抽象一个范式出来让别人沿用你的(不work的)框架?
不过,我认为MLaaS在长期的成功是有可能的,但还需要行业发展更为成熟的时候,现在为时尚早。具体分析我们在后面Part 5会谈到。
“ 音箱的成功和智能的失败 ”
对话这个领域,另一个比较火的赛道是智能音箱。
各大主要科技公司都出了自己的智能音箱,腾讯叮当、阿里的天猫精灵、小米音箱、国外的Alexa、Google的音箱等等。作为一个硬件品类,这其实是个还不错的生意,基本属于制造业。
不仅出货不差,还被寄予期望,能够成为一个生态的生意——核心逻辑看上去也是充满想象力的:
超级终端:在后移动时代,每家都想像iphone一样抢用户的入口。只要用户习惯使用语音来获得咨询或者服务,甚至可以像Xbox/ps一样,硬件赔钱卖,软件来挣钱;
用语音做OS:开发者打造各类语音的技能,然后通过大量“离不开的技能” 反哺这个OS的市场占有;
提供开发者平台:像Xcode一样,给开发者提供应用开发的工具和分发平台、提供使用服务的流量。
可是,这些技能使用的实际情况是这样的:
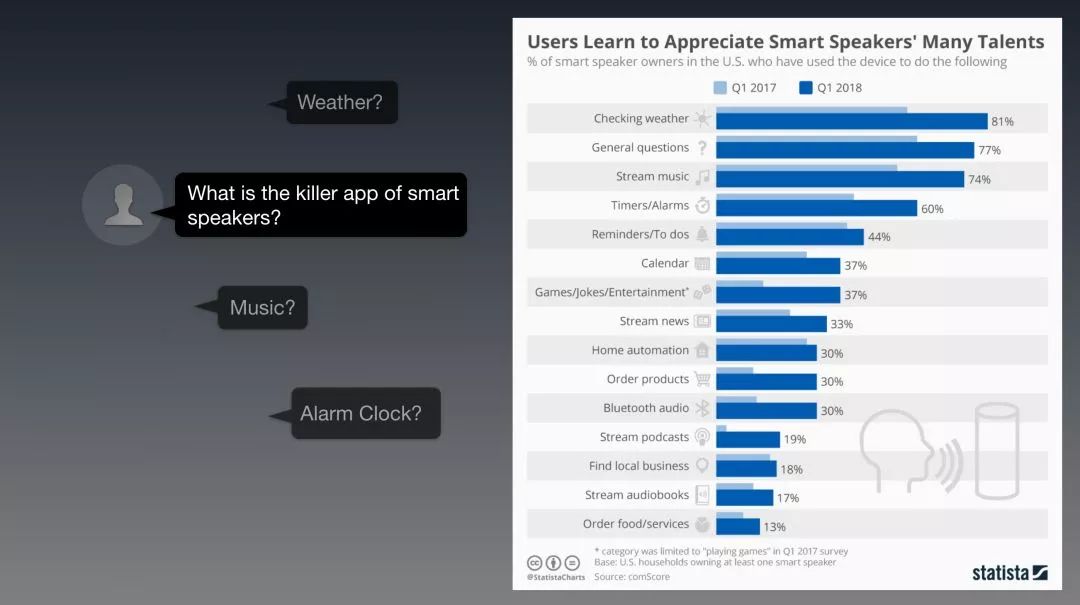
Source: Statista
万众期待的killer app并没有出现;
基本没有商业服务型的应用;
技能开发者都没赚到钱,也不知道怎么赚钱;
大部分高频使用的技能都没有商业价值——用户用的最多的就是“查天气”
没有差异性:智能的差异嘛基本都没有的事儿。
“ 皇帝的新人工智能 ”
回过头来,我们再来看刚刚那位沙特阿拉伯的公民,Sophia。既然刚刚提到的那么多公司投入了那么多钱和科学家,都搞成这样,凭什么这个Sophia能一鸣惊人?
因为Sophia的“智能” 是个骗局。
可以直接引用Yann LeCun对此的评价, “这完全是鬼扯”。
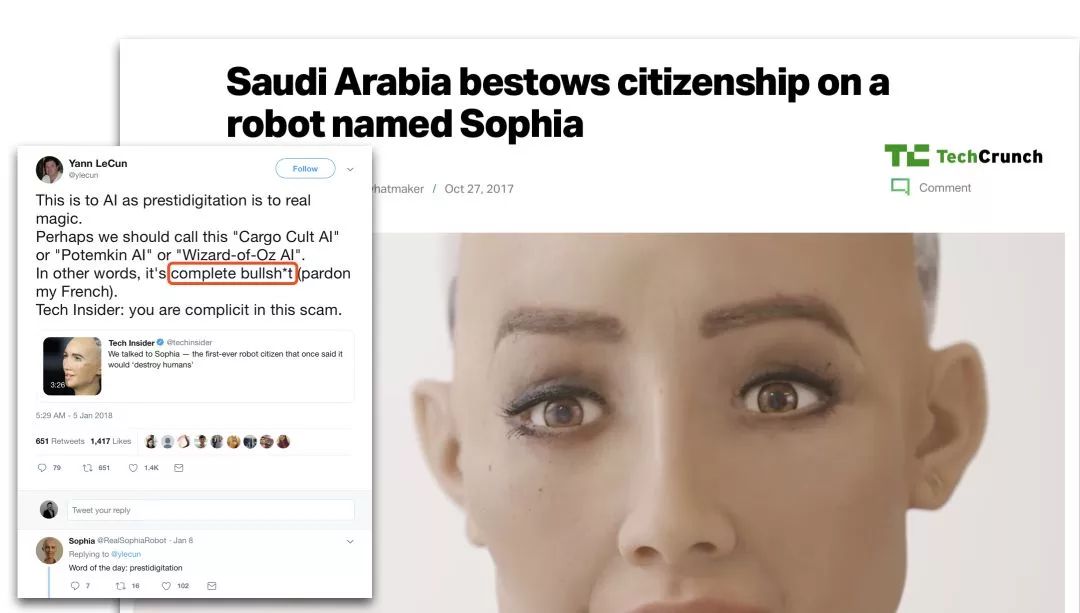
简单来说,Sophia是一个带喇叭的木偶——在各种大会上的发言和采访的内容都是人工撰写,然后用人人都有的语音合成做输出。却被宣传成为是其“人工智能”的自主意识言论。
这还能拿“公民身份”,可能是人类公民被黑的最惨的一次。这感觉,好像是我家的橘猫被一所985大学授予了土木工程学士学位。
其实对话系统里,用人工来撰写内容,或者使用模版回复,这本来就是现在技术的现状(在后面我们会展开)。
但刻意把“非智能”的产物说成是“智能”的表现,这就不对了。
考虑到大部分吃瓜群众是通过媒体渠道来了解当前技术发展的,跟着炒作的媒体(比如被点名的Tech Insider)都是这场骗局的共犯。这些不知道是无知还是无良的文科生,真的没有做好新闻工作者份内的调查工作。
最近这股妖风也吹到了国内的韭菜园里。

Sophia出现在了王力宏的一首讲AI的MV里;然后又2018年11月跑去给大企业站台。
真的,行业内认真做事儿的小伙伴,都应该站出来,让大家更清晰的知道现在AI——或者说机器学习的边界在哪儿。不然甲方爸爸们信以为真了,突然指着sophia跟你说,“ 别人都能这么自然,你也给我整一个。”
你怕不得装个真人进去?
对了,说到这儿,确实现在也有:用人——来伪装成人工智能——来模拟人,为用户服务。
Source: The Guardian
国内的案例典型的就是银行用的大堂机器人,其实是真人在远程语音(所谓Tele presence)。美国有X.ai,做基于Email的日程管理的。只是这个AI到了下午5点就要下班。
当然,假如我是这些骗局背后开发者,被质疑的时候,我还可以强行拉回人工智能上:“这么做是为了积累真正的对话数据,以后用来做真的AI对话系统识别的训练。”
这么说对外行可能是毫无破绽的。但是真正行业内干正经事的人,都应该像傅盛那样站出来,指明这些做法是骗人:“全世界没有一家能做出来......做不到,一定做不到”。
人家沙特是把AI当成人,这些套路是把人当成AI。然后大众就开始分不清楚究竟什么是AI了。
“ 人工智能究竟(tmd)指的是什么?”
另一方面,既然AI现在的那么蠢,为什么马一龙 (Elon Musk) 却说“AI很有可能毁灭人类”;霍金甚至直接说 “AI可能是人类文明里最糟糕的事件”。
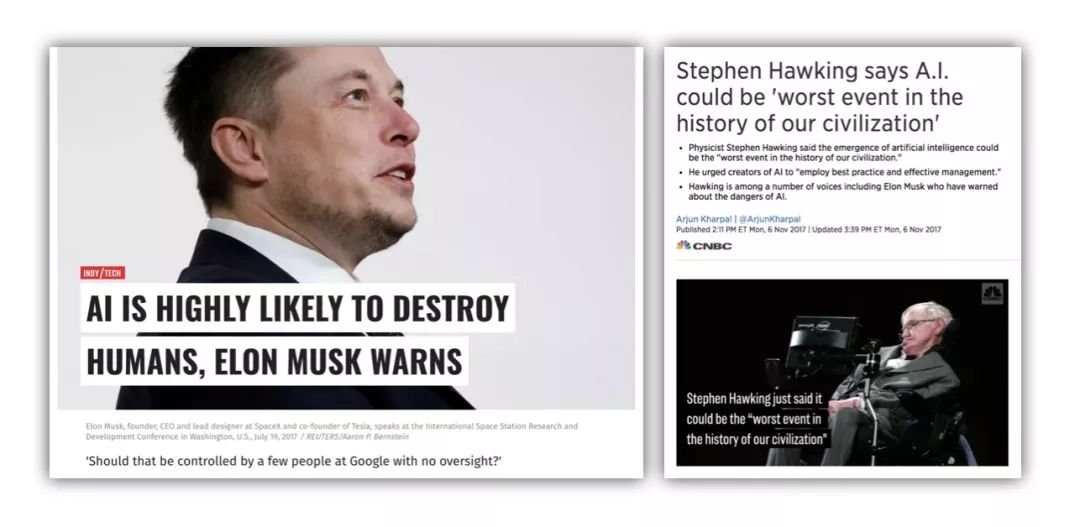
而在另一边,Facebook和Google的首席科学家却在说,现在的AI都是渣渣,根本不需要担心,甚至应该推翻重做。

大家该相信谁的?一边是要去火星的男人,和说不定已经去了火星的男人;另一边是当前两家科技巨头的领军人物。
其实他们说的都对,因为这里说到的“人工智能”是两码事。
马一龙和霍金担心的人工智能,是由人造出来的真正的智能,即通用人工智能(AGI, Artificial General Intelligence)甚至是超级智能(Super Intelligence)。
而Yann LeCun 和Hinton指的人工智能则是指的当前用来实现“人工智能效果”的技术(基于统计的机器学习)。这两位的观点是“用这种方式来实现人工智能是行不通的”。
两者本质是完全不同的,一个指的是结果,一个指的是(现在的)过程。
那么当我们在讨论人工智能的时候,究竟在说什么?

John McCathy
John McCathy在1956年和Marvin Minsky,Nathaniel Rochester 以及Claude Shannon在达特貌似研讨会上打造了AI这个词,但是到目前为止,学界工业界并没有一个统一的理解。
最根本的问题是目前人类对“智能”的定义还不够清楚。何况人类本身是否是智能的最佳体现,还不一定呢。想想每天打交道的一些人:)
一方面,在大众眼中,人工智能是 “人造出来的,像人的智能”,比如Siri。同时,一个AI的水平高低,则取决于它有多像人。所以当Sophia出现在公众眼中的时候,普通人会很容易被蒙蔽(甚至能通过图灵测试)。
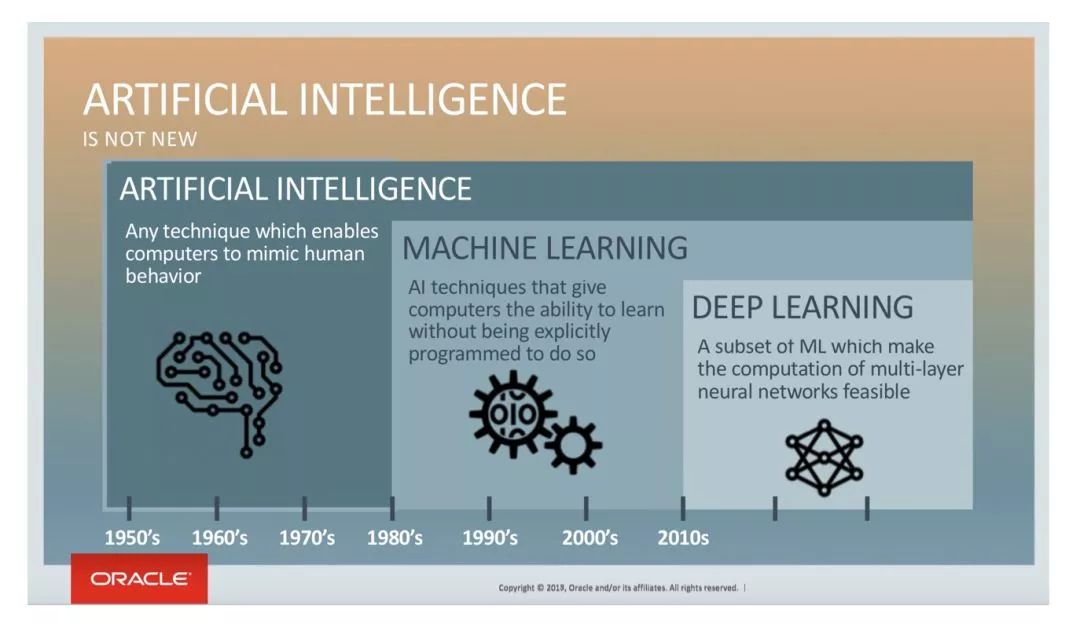
Oracle对AI的定义也是 “只要是能让计算机可以模拟人类行为的技术,都算!”
而另一方面,从字面上来看“Artificial Intelligence”,只要是人造的智能产品,理论上都算作人工智能。
也就是说,一个手持计算器,尽管不像人,也应算是人工智能产品。但我相信大多数人都不会把计算器当成是他们所理解的人工智能。
这些在认识上不同的解读,导致当前大家对AI应用的期望和评估都有很多差异。
再加上还有“深度学习、神经网络、机器学习” 这些概念纷纷跟着人工智能一起出现。但是各自意味着什么,之间是什么关系,普通大众都不甚了解。
“ 没关系,韭菜不用懂。” 但是想要割韭菜的人,最好能搞清楚吧。连有些投资人自己也分不清,你说怎么做判断,如何投项目?当然是投胸大的。
以上,就是到2018年末,在对话领域的人工智能的现状:智能助理依然智障;大部分To B的给人造机器人的都无法规模化;对话方面没有像AlphaZero在围棋领域那样的让人震惊的产品;没有商业上大规模崛起的迹象;有的是一团浑水,和浑水摸鱼的人。
为什么会这样?为什么人工智能在图像识别,人脸识别,下围棋这些方面都那么快的进展,而在对话智能这个领域却是如此混乱?
既然你都看到这里了,我相信你是一个愿意探究本质的好同志。那么我们来了解,对话的本质是什么;以及现在的对话系统的本质又是什么。
Part 2
当前对话系统的本质:填表
“ AI thinks, man laughs ”

Source:The Globe and Mail
有一群小鸡出生在一个农场,无忧无虑安心地生活。
鸡群中出现了一位科学家,它注意到了一个现象:每天早上,食槽里会自动出现粮食。
作为一名优秀的归纳法信徒(Inductivist),这只科学鸡并不急于给出结论。它开始全面观察并做好记录,试图发现这个现象是否在不同的条件下都成立。
“星期一是这样,星期二是这样;树叶变绿时是这样,树叶变黄也是这样;天气冷是这样,天气热也是这样;下雨是这样,出太阳也是这样!”
每天的观察,让它越来越兴奋,在心中,它离真相越来越接近。直到有一天,这只科学鸡再也没有观察到新的环境变化,而到了当天早上,鸡舍的门一打开,它跑到食槽那里一看,依然有吃的!
科学鸡,对他的小伙伴,志在必得地宣布:“我预测,每天早上,槽里会自动出现食物。明天早上也会有!以后都会有!我们不用担心饿死了!”
经过好几天,小伙伴们都验证了这个预言,科学鸡骄傲的并兴奋的把它归纳成“早起的小鸡有食吃定理”。
正好,农场的农夫路过,看到一只兴奋的鸡不停的咯咯叫,他笑了:“这只鸡很可爱哦,不如把它做成叫花鸡好了” 。
科学鸡,卒于午饭时间。
在这个例子里,这只罗素鸡(Bertrand Russell’s chicken)只对现象进行统计和归纳,不对原因进行推理。
而主流的基于统计的机器学习特别是深度学习,也是通过大量的案例,靠对文本的特征进行归类,来实现对识别语义的效果。这个做法,就是罗素鸡。
目前,这是对话式人工智能的主流技术基础。其主要应用方向,就是对话系统,或称为Agent。之前提到的智能助理Siri,Cortana,Google Assistant以及行业里面的智能客服这些都算是对话智能的应用。
“ 对话智能的黑箱 ”
这些产品的交互方式,是人类的自然语言,而不是图像化界面。
图形化界面(GUI)的产品,比如网页或者APP的产品设计,是所见即所得、界面即功能。
对话智能的交互(CUI, Conversational UI)是个黑箱:终端用户能感知到自己说出的话(输入)和机器人的回答(输出)——但是这个处理的过程是感觉不到的。就好像跟人说话,你并不知道他是怎么想的。
每一个对话系统的黑箱里,都是开发者自由发挥的天地。
虽说每家的黑箱里面都不同,但是最底层的思路,都万变不离其宗,核心就是两点:听人话(识别)+ 讲人话(对话管理)。
如果你是从业人员,那么请回答一个问题:你们家的对话管理是不是填槽?若是,你可以跳过这一节(主要科普填槽是怎么回事),请直接到本章的第五节“当前对话系统的局限” 。
“ AI如何听懂人话 ?”
对话系统这个事情在2015年开始突然火起来了,主要是因为一个技术的普及:机器学习特别是深度学习带来的语音识别和NLU(自然语言理解)——主要解决的是识别人讲的话。
这个技术的普及让很多团队都掌握了一组关键技能:意图识别和实体提取。这意味着什么?我们来看一个例子。
在生活中,如果想要订机票,人们会有很多种自然的表达:
“订机票”;
“有去上海的航班么?”;
“看看航班,下周二出发去纽约的”;
“要出差,帮我查下机票”;
等等等等
可以说“自然的表达” 有无穷多的组合(自然语言)都是在代表 “订机票” 这个意图的。而听到这些表达的人,可以准确理解这些表达指的是“订机票”这件事。
而要理解这么多种不同的表达,对机器是个挑战。在过去,机器只能处理“结构化的数据”(比如关键词),也就是说如果要听懂人在讲什么,必须要用户输入精确的指令。
所以,无论你说“我要出差”还是“帮我看看去北京的航班”,只要这些字里面没有包含提前设定好的关键词“订机票”,系统都无法处理。而且,只要出现了关键词,比如“我要退订机票”里也有这三个字,也会被处理成用户想要订机票。
自然语言理解这个技能出现后,可以让机器从各种自然语言的表达中,区分出来,哪些话归属于这个意图;而那些表达不是归于这一类的,而不再依赖那么死板的关键词。比如经过训练后,机器能够识别“帮我推荐一家附近的餐厅”,就不属于“订机票”这个意图的表达。
并且,通过训练,机器还能够在句子当中自动提取出来“上海”,这两个字指的是目的地这个概念(即实体);“下周二”指的是出发时间。
这样一来,看上去“机器就能听懂人话啦!”。
这个技术为啥会普及?主要是因为机器学习领域的学术氛围,导致重要的论文基本都是公开的。不同团队要做的是考虑具体工程实施的成本。
最后的效果,就是在识别自然语言这个领域里,每家的基础工具都差不多。在意图识别和实体提取的准确率,都是百分点的差异。既然这个工具本身不是核心竞争力,甚至你可以用别家的,大把可以选,但是关键是你能用它来干什么?
“Due to the academic culture that ML comes from, pretty much all of the primary science is published as soon as it’s created - almost everything new is a paper that you can read and build with. But what do you build? ”
——Benedict Evans (A16Z合伙人)
在这方面,最显而易见的价值,就是解放双手。语音控制类的产品,只需要听懂用户的自然语言,就去执行这个操作:在家里要开灯,可以直接说 “开灯”,而不用去按开关;在车上,说要“开天窗”,天窗就打开了,而不用去找对应的按钮在哪里。
这类系统的重点在于,清楚听清哪个用户在讲是什么。所以麦克风阵列、近场远场的抗噪、声纹识别讲话的人的身份、ASR(语音转文字),等等硬件软件的技术就相应出现,向着前面这个目标不断优化。
“讲人话”在这类应用当中,并不那么重要。通常任务的执行,以结果进行反馈,比如灯应声就亮了。而语言上的反馈,只是一个辅助作用,可有可无。
但是任务类的对话智能,往往不止是语音控制这样一轮交互。如果一个用户说,“看看明天的机票”——这表达正常,但无法直接去执行。因为缺少执行的必要信息:1)从哪里出发?和 2)去哪里?
如果我们希望AI Agent来执行这个任务,一定要获得这两个信息。对于人来完成这个业务的话,要获得信息,就得靠问这个用户问题,来获得信息。很多时候,这样的问题,还不止一个,也就意味着,要发起多轮对话。
对于AI而言,也是一样的。
要知道 “去哪里” = Agent 问用户“你要去哪里?”
要知道 “从哪里出发” = Agent 问用户“你要从哪里出发呢?”
这就涉及到了对话语言的生成。
“ AI 如何讲人话?”
决定“该说什么话”,才是对话系统的核心——无论是硅基的还是碳基的智能。但是深度学习在这个版块,并没有起到什么作用。
在当前,处理“该说什么”这个问题,主流的做法是由所谓“对话管理”系统决定的。
尽管每一个对话系统背后的“对话管理”机制都不同,每家都有各种理解、各种设计,但是万变不离其宗——目前所有任务类对话系统,无论是前段时间的Google duplex,还是智能客服,或者智能助理,最核心的对话管理方法,有且仅有一个:“填槽”,即Slot filling。
如果你并不懂技术,但是又要迅速知道一家做对话AI的水平如何,到底有没有黑科技(比如刚刚开始看AI领域的做投资的朋友 ),你只需要问他一个问题:“是不是填槽?”
如果他们(诚实地)回答“是”,那你就可以放下心来,黑科技尚未出现。接下来,能讨论的范围,无非都是产品设计、工程实现、如何解决体验和规模化的困境,这类的问题。基本上该智障的,还是会智障。
要是他们回答“不是填槽”,而且产品的效果还很好,那么就有意思了,值得研究,或者请速速联系我:)
那么这个“填槽”究竟是个什么鬼?嗯,不搞开发的大家可以简单的把它理解为“填表”:好比你要去银行办个业务,先要填一张表。
如果这张表上的空没有填完,柜台小姐姐就不给你办。她会红笔给你圈出来:“必须要填的空是这些,别的你都可以不管。” 你全部填好了,再递给小姐姐,她就去给你办理业务了。
还记得刚刚那个机票的例子么?用户说“看看明天的机票”,要想执行“查机票”,就得做以下的步奏,还要按顺序来:
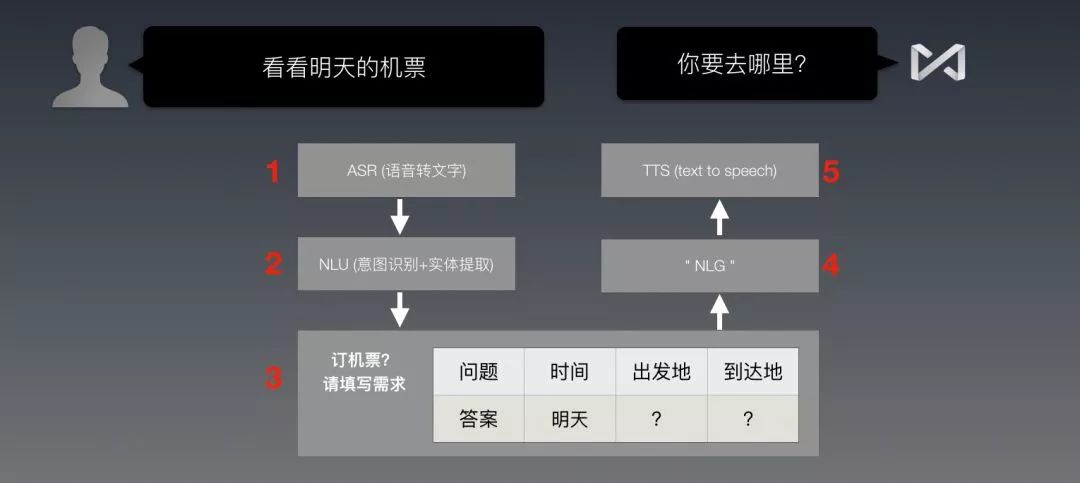
1. ASR:把用户的语音,转化成文字。
2. NLU语义识别:识别上面的文字,属于(之前设定好的)哪一个意图,在这里就是“订机票”;然后,提取文字里面的实体,“明天”作为订票日期,被提取出来啦。
3. 填表:这个意图是订机票,那么就选“订机票”这张表来填;这表里有三个空,时间那个空里,就放进“明天”。
(这个时候,表里的3个必填项,还差两个:“出发地”和“到达地”)
4. 开始跑之前编好的程序:如果差“出发地”,就回“从哪里走啊?”;如果差“目的地”,就回“你要去哪里?”(NLG上打引号,是因为并不是真正意义上的自然语言生成,而是套用的对话模版)
5. TTS:把回复文本,合成为语音,播放出去
在上面这个过程当中,1和2步奏都是用深度学习来做识别。如果这个环节出现问题,后面就会连续出错。
循环1-5这个过程,只要表里还有空要填,就不断问用户,直到所有的必填项都被填完。于是,表就可以提交小姐姐(后端处理)了。
后端看了要查的条件,返回满足这些条件的机票情况。Agent再把查询结果用之前设计好的回复模板发回给用户。
顺便说一下,我们经常听到有些人说“我们的多轮对话可以支持xx轮,最多的时候有用户能说xx轮”。现在大家知道,在任务类对话系统里,“轮数的产生”是由填表的次数决定的,那么这种用“轮数多少”来衡量产品水平的方法,在这个任务类对话里里完全无意义。
一定要有意义,也应该是:在达到目的、且不影响体验的前提下,轮数越少越好。
在当前,只要做任务类的多轮对话,基本跑不掉填表。
5月的时候,Google I/O发布了Duplex的录音Demo,场景是Google Assistant代替用户打电话去订餐厅,和店员沟通,帮助用户预定位子。值得注意,这并不是Live demo。
Google's Assistant. CREDIT:GOOGLE
那Google的智能助理(后称IPA)又怎么知道用户的具体需求呢?跑不掉的是,用户还得给Google Assistant填一张表,用对话来交代自己的具体需求,比如下面这样:
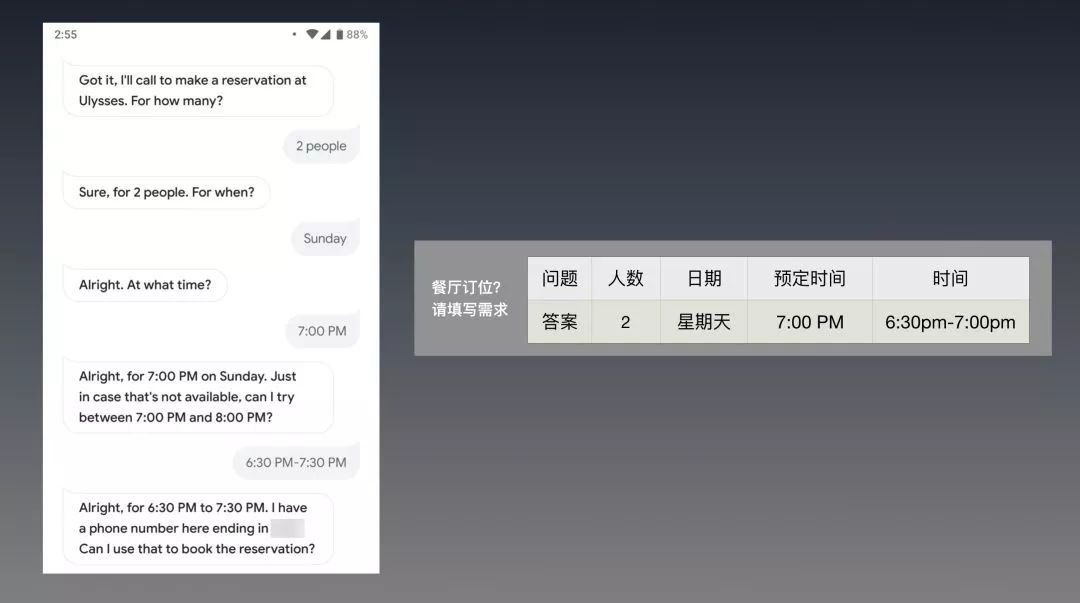
图中左边是一个使用Google Assistant订餐厅的真实案例,来自The Verge。
“ 当前对话系统的局限 ”
我刚刚花了两千来个字来说明对话系统的通用思路。接下来,要指出这个做法的问题
还记得之前提到的 “不要日本菜”测试么?我们把这个测试套用在“订机票”这个场景上,试试看:“看看明天去北京的航班,东航以外的都可以”,还是按步奏来:
1. ASR语音转文字,没啥问题;
2. 语义识别,貌似有点问题
- 意图:是订机票,没错;
- 实体提取:跟着之前的训练来;
- 时间:明天
- 目的地:北京
- 出发地:这个用户没说,一会得问问他...
等等,他说的这个“东航以外的都可以”,指的是啥?之前没有训练过与航空公司相关的表达啊。
没关系,咱们可以把这个表达的训练加上去:东航 = 航司。多找些表达,只要用户说了各个航空公司的名字的,都训练成航司这个实体好啦。
另外,咱们还可以在填表的框里,添加一个航司选择,就像这样(黄色部分):

(嗯,好多做TO B的团队,都是掉在这个“在后面可以加上去”的坑里。)
但是,这么理所当然的训练之后,实体提取出来的航司却是“东航”——而用户说的是 “东航以外的”,这又指的哪个(些)航司呢?
“要不,咱们做点Trick把‘以外’这样的逻辑单独拿出来手工处理掉?”——如果这个问题可以这么容易处理掉,你觉得Siri等一干货色还会是现在这个样子?难度不在于“以外”提取不出来,而是在处理“这个以外,是指哪个实体以外?
当前基于深度学习的NLU在“实体提取”这个技术上,就只能提取“实体”。
而人能够理解,在这个情况下,用户是指的“排除掉东航以外的其他选择”,这是因为人除了做“实体提取”以外,还根据所处语境,做了一个对逻辑的识别:“xx以外”。然后,自动执行了这个逻辑的处理,即推理,去进一步理解,对方真正指的是什么(即指代)。
而这个逻辑推理的过程,并不存在于之前设计好的步奏(从1到5)里。
更麻烦的是,逻辑的出现,不仅仅影响“实体”,还影响“意图”:
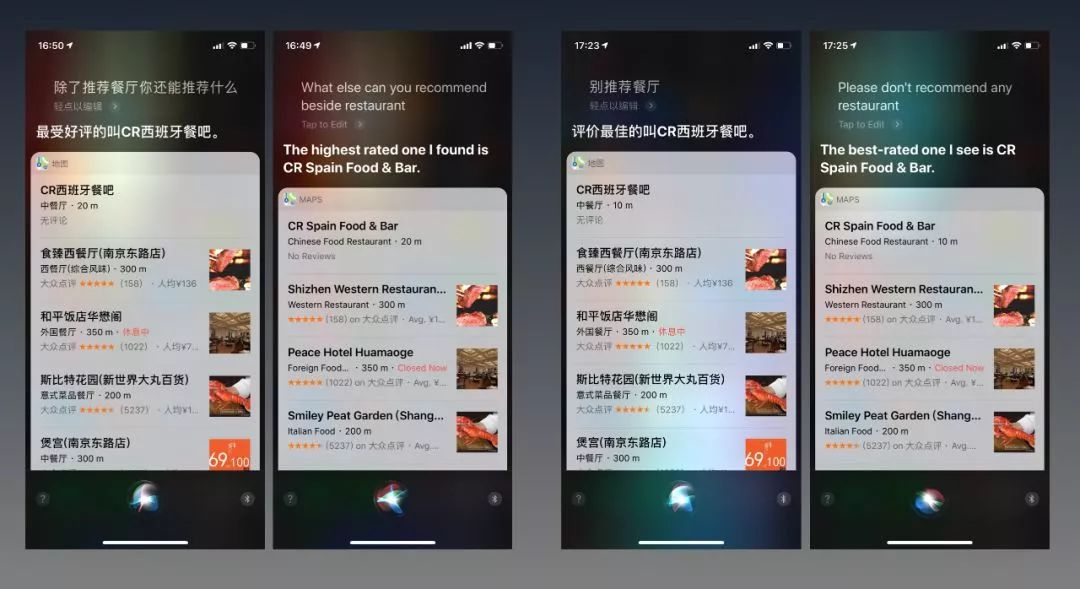
“hi Siri,别推荐餐厅”——它还是会给你推荐餐厅;
“hi Siri,除了推荐餐厅,你还能推荐什么?”——它还是会给你推荐餐厅。
中文英文都是一样的;Google assistant也是一样的。
想要处理这个问题,不仅仅是要识别出“逻辑”;还要正确判断出,这个逻辑是套用在哪个实体,或者是不是直接套用在某一个意图上。这个判断如何做?用什么做?都不在当前SLU的范围内。
对这些问题的处理,如果是集中在一些比较封闭的场景下,还可以解决个七七八八。但是,如果想要从根本上、泛化的处理,希望一次处理就解决所有场景的问题,到目前都无解。在这方面,Siri是这样,Google Assistant也是这样,任意一家,都是这样。
为啥说无解?我们来看看测试。
“ 用图灵测试来测对话系统没用 ”
一说到对人工智能进行测试,大部分人的第一反应是图灵测试。
5月Google I/O大会的那段时间,我们团队正在服务一家全球100强企业,为他们规划基于AI Agent的服务。
在发布会的第二天,我收到这家客户的Tech Office的好心提醒:Google这个像真人一样的黑科技,会不会颠覆现有的技术方案?我的回答是并不会。
话说Google Duplex在发布会上的demo确实让人印象深刻,而且大部分看了Demo的人,都分辨不出打电话去做预定的是不是真人。
“这个效果在某种意义上,算是通过了图灵测试。”
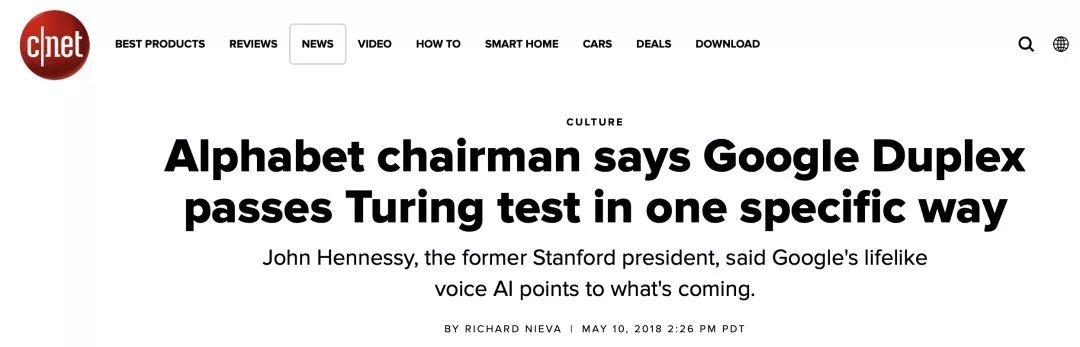
Google母公司的Chairman说google duplex可以算过了图灵测试了
由于图灵测试的本质是“欺骗” (A game of deception,详见Toby Walsh的论文),所以很多人批评它,这只能用来测试人有多好骗,而不是用来测智能的。在这一点上,我们在后文Part 4对话的本质中会有更多解释。
人们被这个Demo骗到的主要原因,是因为合成的语音非常像真人。
这确实是Duplex最牛的地方:语音合成。不得不承认,包括语气、音调等等模拟人声的效果,确实是让人叹为观止。只是,单就在语音合成方面,就算是做到极致,在本质上就是一只鹦鹉——最多可以骗骗Alexa(所以你看活体识别有多么重要)。
只是,Google演示的这个对话系统,一样处理不了逻辑推理、指代这类的问题。这意味着,就它算能过图灵测试,也过不了Winograd Schema Challenge测试。
相比图灵测试,这个测试是直击深度学习的要害。当人类对句子进行语法分析时,会用真实世界的知识来理解指代的对象。这个测试的目标,就是测试目前深度学习欠缺的常识推理能力。
如果我们用Winograd Schema Challenge的方法,来测试AI在“餐厅推荐”这个场景里的水平,题目会是类似这样的:
A. “四川火锅比日料更好,因为它很辣”
B. “四川火锅比日料更好,因为它不辣”
AI需要能准确指出:在A句里,“它”指的是四川火锅;而在B句里,“它”指的则是日料。
还记得在本文Part 1里提到的那个“不要日本菜测试”么?我真的不是在强调“回字有四种写法”——这个测试的本质,是测试对话系统能不能使用简单逻辑来做推理(指代的是什么)。
而在Winograd Schema Challenge中,则是用世界知识(包括常识)来做推理:
如果系统不知道相应的常识(四川火锅是辣的;日料是不辣的),就没有推理的基础。更不用说推理还需要被准确地执行。
有人说,我们可以通过上下文处理来解决这个问题。不好意思,上面这个常识根本就没有出现在整个对话当中。不在“上文”里面,又如何处理?
对于这个部分的详细解释,请看下一章 (Part 3 对话的本质)。
尽管指代问题和逻辑问题,看上去,在应用方面已经足够致命了;但这些也只是深度学习表现出来的诸多局限性中的一部分。
哪怕更进一步,再过一段时间,有一家AI在Winograd Schema Challenge拿了100%的正确率,我们也不能期望它在自然语言处理中的表现如同人一样,因为还有更严重和更本质的问题在后面等着。
“ 对话系统更大的挑战不是NLU ”
我们来看问题表现在什么地方。
现在我们知道了,当人跟现在的AI对话的时候,AI能识别你说的话,是靠深度学习对你说出的自然语言进行分类,归于设定好的意图,并找出来文本中有哪些实体。
而AI什么时候回答你,什么时候反问你,基本都取决于背后的“对话管理”系统里面的各种表上还有啥必填项没有填完。而问你的话,则是由产品经理和代码小哥一起手动完成的。
那么,这张表是谁做的?
或者说,是谁决定,对于“订机票”这件事,要考虑哪些方面?要获得哪些信息?需要问哪些问题?机器又是怎么知道的?
是人。是产品经理,准确点说。
就像刚才的“订机票”的案例,当用户问到“航司”的时候,之前的表里并没有设计这个概念,AI就无法处理了。
要让AI能处理这样的新条件,得在“订机票”这张表上,新增加“航空公司”一栏(黄色部分)。而这个过程,都得人为手动完成:产品经理设计好后,工程师编程完成这张表的编程。
所以AI并不是真的,通过案例学习就自动理解了“订机票”这件事情,包含了哪些因素。只要这个表还是由人来设计和编程实现的,在产品层面,一旦用户稍微谈及到表以外的内容,智障的情况就自然出现了。
因此,当Google duplex出现的时候,我并不那么关心 Google duplex发音和停顿有多像一个人——实际上,当我观察任意一个对话系统的时候,我都只关心1个问题:
“是谁设计的那张表:人,还是AI?”
只是,深度学习在对话系统里面,能做的只是识别用户讲出的那句话那部分——严格依照被人为训练的那样(监督学习)。至于其他方面,比如该讲什么话?该在什么时候讲话?它都无能为力。
但是真正人们在对话时的过程,却不是上面提到的对话系统这么设计的,而且相差十万八千里。人的对话,又是怎么开展的?这个差异究竟在哪里?为什么差异那么大?所谓深度学习很难搞定的地方,是人怎么搞定的呢?毕竟在这个星球上,我们自身就是70亿个完美的自然语言处理系统呢。
我们需要了解要解决的问题,才可能开展解决问题的工作。在对话领域,我们需要知道人们对话的本质是什么。下一章比较烧脑,我们将讨论“思维”这件事情,是如何主导人们的对话的。
Part 3
人类对话的本质:思维
“ 对话的最终目的是为了同步思维 ”
你是一位30出头的职场人士,每天上午9点半,都要过办公楼的旋转门,进大堂的,然后刷工牌进电梯,去到28楼,你的办公室。今天是1月6日,平淡无奇的一天。你刚进电梯,电梯里只有你一个人,正要关门的时候,有一个人匆忙挤进来。
进来的快递小哥,他进电梯时看到只有你们两人,就说了一声“你好”,然后又低头找楼层按钮了。
你很自然的回复:“你好”,然后目光转向一边。
两边都没什么话好讲——实际上,是对话双方认为彼此没有什么情况需要同步的。
人们用语言来对话,其最终的目的是为了让双方对当前场景模型(Situation model)保持同步。(大家先了解到这个概念就够了。更感兴趣的,详情请见 Toward a neural basis of interactive alignment in conversation)。
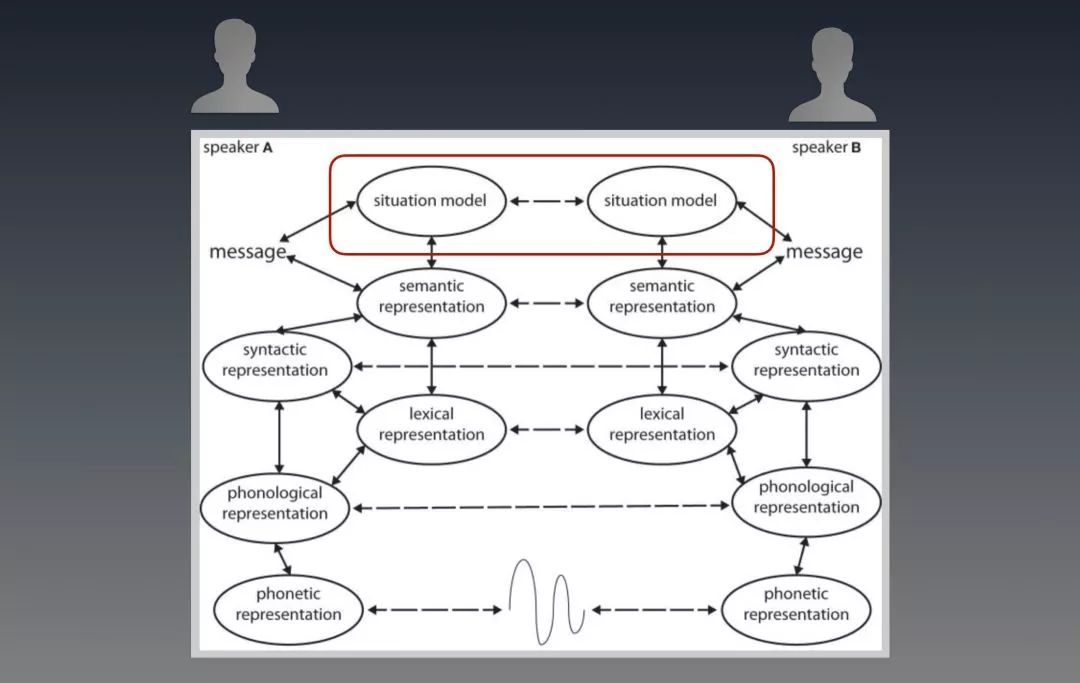
上图中,A和B两人之间发展出来所有对话,都是为了让红框中的两个“Situation model” 保持同步。Situation model 在这里可以简单理解为对事件的各方面的理解,包括Context。
不少做对话系统的朋友会认为Context是仅指“对话中的上下文”,我想要指出的是,除此以外,Context还应该包含了对话发生时人们所处的场景。这个场景模型涵盖了对话那一刻,除了明文以外的所有已被感知的信息。 比如对话发生时的天气情况,只要被人感知到了,也会被放入Context中,并影响对话内容的发展。
A: “你对这个事情怎么看?”
B: “这天看着要下雨了,咱们进去说吧”——尽管本来对话内容并没有涉及到天气。
对同一件事情,不同的人在脑海里构建的场景模型是不一样的。 (想要了解更多,可以看 Situation models in language comprehension and memory. Zwaan, R. A., & Radvansky, G. A. (1998). )
所以,如果匆忙进电梯来的是你的项目老板,而且假设他和你(多半都是他啦)都很关注最近的新项目进展,那么你们要开展的对话就很多了。
在电梯里,你跟他打招呼:“张总,早!”, 他会回你 “早啊,对了昨天那个…”
不待他问完,优秀如你就能猜到“张总” 大概后面要聊的内容是关于新项目的,这是因为你认为张总对这个“新项目”的理解和你不同,有同步的必要。甚至,你可以通过昨天他不在办公室,大概漏掉了这个项目的哪些部分,来推理你这个时候应该回复他关于这个项目的具体什么方面的问题。
“昨天你不在,别担心,客户那边都处理好了。打款的事情也沟通好了,30天之内搞定。” ——你看,不待张总问完,你都能很棒的回答上。这多亏了你对他的模型的判断是正确的。
一旦你对对方的情景模型判断失误,那么可能完全“没打中点上”。
“我知道,昨天晚上我回了趟公司,小李跟我说过了。我是要说昨天晚上我回来办公室的时候,你怎么没有在加班呀?小王,你这样下去可不行啊…”
所以,人们在进行对话的过程中,并不是仅靠对方上一句话说了什么(对话中明文所包含的信息)就来决定回复什么。而这和当前的对话系统的回复机制非常不同。
“ 对话是思想从高维度向低维的投影 ”
我们假设,在另一个平行宇宙里,还是你到了办公楼。
今天还是1月6日,但2年前的今天,你与交往了5年的女友分手了,之后一直对她念念不忘,也没有交往新人。
你和往日一样,进电梯的,刚要关门的时候,匆忙进来的一个人,要关的门又打开了。就是你2年前分手的那位前女友。她进门时看到只有你们两,她抬头看了一下你,然后又低头找楼层电梯了,这时她说:“你好”。
请问你这时脑袋里是不是有很多信息汹涌而过?这时该回答什么?是不是类似“一时不知道该如何开口”的感觉?
这个感觉来自(你认为)你和她之间的情景模型有太多的不同(分手2年了),甚至你都无法判断缺少哪些信息。有太多的信息想要同步了,却被贫瘠的语言困住了。
在信息丰富的程度上,语言是贫瘠的,而思想则要丰富很多 “Language is sketchy, thought is rich” (New perspectives on language and thought,Lila Gleitman, The Oxford Handbook of Thinking and Reasoning;更多相关讨论请看, Fisher & Gleitman, 2002; Papafragou, 2007)
有人做了一个比喻:语言和思维的丰富程度相比,是冰山的一角。我认为远远不止如此:对话是思想在低维的投影。
如果是冰山,你还可以从水面上露出来的部分反推水下大概还有多大。属于维度相同,但是量不同。但是语言的问题在,只用听到文字信息,来反推讲话的人的思想,失真的情况会非常严重。

为了方便理解这个维度差异,在这儿用3D和2D来举例:思维是高维度(立体3D的形状),对话是低维度(2D的平面上的阴影)。如果咱们要从平面上的阴影的形状,来反推,上面悬着的是什么物体,就很困难了。两个阴影的形状一模一样,但是上面的3D物体,可能完全不同。
对于语言而言,阴影就像是两个 “你好”在字面上是一模一样的,但是思想里的内容却完全不同。在见面的那一瞬间,这个差异是非常大的:
你在想(圆柱):一年多不见了,她还好么?
前女友在想(球):这个人好眼熟,好像认识…
“ 挑战:用低维表达高维 ”
要用语言来描述思维有多困难?这就好比,当你试图给另一位不在现场的朋友,解释一件刚刚发生过的事情的时候,你可以做到哪种程度的还原呢?
试试用语言来描述你今天的早晨是怎么过的。
当你用文字完整描述后,我一定能找到一个事物或者某个具体的细节,它在你文字描述以外,但是却确实存在在你今天早晨那个时空里。

Source:The Challenger
比如,你可能会跟朋友提到,早饭吃了一碗面;但你一定不会具体去描述面里一共有哪些调料。传递信息时,缺少了这些细节(信息),会让听众听到那碗面时,在脑海里呈现的一定不是你早上吃的“那碗面”的样子。
这就好比让你用平面上(2D)阴影的样子,来反推3D的形状。你能做的,只是尽可能的增加描述的视角,尽可能给听众提供不同的2D的素材,来尽量还原3D的效果。
为了解释脑中“语言”和“思想”之间的关系(与读者的情景模型进行同步),我画了上面那张对比图,来帮助传递信息。如果要直接用文字来精确描述,还要尽量保全信息不丢失,那么我不得不用多得多的文字来描述细节。(比如上面的描述中,尚未提及阴影的面积的具体大小、颜色等等细节)。
这还只是对客观事物的描述。当人在试图描述更情绪化的主观感受时,则更难用具体的文字来表达。

比如,当你看到Angelina Jordan这样的小女生,却能唱出I put a spell on you这样的歌的时候,请尝试用语言精确描述你的主观感受。是不是很难?能讲出来话,都是类似“鹅妹子嘤”这类的?这些文字能代表你脑中的感受的多少部分?1%?
希望此时,你能更理解所谓 “语言是贫瘠的,而思维则要丰富很多”。
那么,既然语言在传递信息时丢失了那么多信息,人们为什么理解起来,好像没有遇到太大的问题?
“ 为什么人们的对话是轻松的?”
假设有一种方式,可以把此刻你脑中的感受,以完全不失真的效果传递给另一个人。这种信息的传递和上面用文字进行描述相比,丰富程度会有多大差异?
可惜,我们没有这种工具。我们最主要的交流工具,就是语言,靠着对话,来试图让对方了解自己的处境。
那么,既然语言这么不精准,又充满逻辑上的漏洞,信息量又不够,那么人怎么能理解,还以此为基础,建立起来了整个文明?
比如,在一个餐厅里,当服务员说 “火腿三明治要买单了”,我们都能知道这和“20号桌要买单了”指代的是同样的事情 (Nuberg,1978)。是什么让字面上那么大差异的表达,也能有效传递信息?
人能通过对话,有效理解语言,靠的是解读能力——更具体的点,靠的是对话双方的共识和基于共识的推理能力。
当人接收到低维的语言之后,会结合引用常识、自身的世界模型(后详),来重新构建一个思维中的模型,对应这个语言所代表的含义。这并不是什么新观点,大家熟悉的开复老师,在1991年在苹果搞语音识别的时候,就在采访里科普,“人类利用常识来帮助理解语音”。
当对话的双方认为对一件事情的理解是一样的,或者非常接近的时候,他们就不用再讲。需要沟通的,是那些(彼此认为)不一样的部分。
当你听到“苹果”两个字的时候,你过去建立过的苹果这个模型的各个维度,就被引用出来,包括可能是绿或红色的、味道的甜、大概拳头大小等等。如果你听到对方说“蓝色的苹果”时,这和你过去建立的关于苹果的模型不同(颜色)。思维就会产生一个提醒,促使你想要去同步或者更新这个模型,“苹果为什么是蓝色的?”
还记得,在Part 2 里我们提到的那个测试指代关系的Winograd Schema Challenge么?这个测试的名字是根据Terry Winograd的一个例子而来的。
“议员们拒绝给抗议者颁发许可证,因为他们 [害怕/提倡] 暴力。”
当 [害怕] 出现在句子当中的时候,“他们”指的应该是议员们;当[提倡]出现在句子当中的时候,“他们”则指的是“抗议者”。
1. 人们能够根据具体情况,作出判断,是因为根据常识做出了推理,“议员害怕暴力;抗议者提倡暴力。”
2. 说这句话的人,认为这个常识对于听众应该是共识,就直接把它省略掉了。
同理,之前(Part 2)我们举例时提到的那个常识 (“四川火锅是辣的;日料不是辣的”),也在表达中被省略掉了。常识(往往也是大多数人的共识)的总量是不计其数,而且总体上还会随着人类社会发展的演进而不断新增。
例子1,如果你的世界模型里已经包含了“华农兄弟” (你看过并了解他们的故事),你会发现我在Part 2最开始的例子,藏了一个梗(做成叫花鸡)。但因为“华农兄弟”并不是大多数人都知道的常识,而是我与特定人群的共识,所以你看到这句话时,获得的信息就比其人多。而不了解这个梗的人,看到那里时就不会接收到这个额外的信息,反而会觉得这个表达好像有点点奇怪。
例子2,创投圈的朋友应该都有听说过 Elevator pitch,就是30秒,把你要做什么事情讲清楚。通常的案例诸如:“我们是餐饮界的Uber”,或者说“我们是办公室版的Airbnb”。这个典型结构是“XX版的YY”,要让这句话起到效果,前提条件是XX和YY两个概念在发生对话之前,已经纳入到听众的模型里面去了。如果我给别人说,我是“对话智能行业的麦肯锡”,要能让对方理解,对方就得既了解对话智能是什么,又了解麦肯锡是什么。
“ 基于世界模型的推理 ”
场景模型是基于某一次对话的,对话不同,场景模型也不同;而世界模型则是基于一个人的,相对而言长期不变。
对世界的感知,包括声音、视觉、嗅觉、触觉等感官反馈,有助于人们对世界建立起一个物理上的认识。对常识的理解,包括各种现象和规律的感知,在帮助人们生成一个更完整的模型:世界模型。
无论精准、或者对错,每一个人的世界模型都不完全一样,有可能是观察到的信息不同,也有可能是推理能力不一样。世界模型影响的是人的思维本身,继而影响思维在低维的投影:对话。
让我们从一个例子开始:假设现在咱们一起来做一个不那么智障的助理。我们希望这个助理能够推荐餐厅酒吧什么的,来应付下面这样的需求:

当用户说:“我想喝点东西”的时候,系统该怎么回答这句话?经过Part 2,我相信大家都了解,我们可以把它训练成为一个意图“找喝东西的店”,然后把周围的店检索出来,然后回复这句话给他:“在你附近找到这些选择”。
恭喜,咱们已经达到Siri的水平啦!
但是,刚刚我们开头就说了,要做不那么智障的助理。这个“喝东西的店”是奶茶点还是咖啡店?还是全部都给他?
嗯,这就涉及到了推理。我们来手动模拟一个。假设我们有用户的Profile数据,把这个用上:如果他的偏好中最爱的饮品是咖啡,就给他推荐咖啡店。
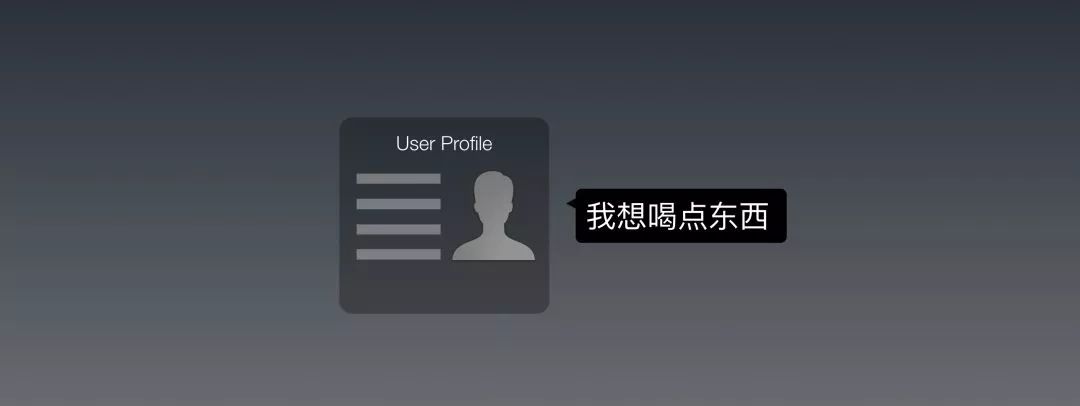
这样一来,我们就可以更“个性化”的给他回复了:“在你附近找到这些咖啡店”。
这个时候,咱们的AI已经达到了不少“智能系统”最喜欢鼓吹的个性化概念——“千人千面”啦!
然后我们来看这个概念有多蠢。
一个人喜欢喝咖啡,那么他一辈子的任意时候就都要喝咖啡么?人是怎么处理这个问题的呢?如果用户是在下午1点这么问,这么回他还好;如果是在晚上11点呢?我们还要给他推荐咖啡店么?还是应该给他推荐一个酒吧?
或者,除此之外,如果今天是他的生日,那么我们是不是该给他点不同的东西?或者,今天是圣诞节,该不该给他推荐热巧克力?
你看,时间是一个维度,在这个维度上的不同值都在影响给用户回复什么不同的话。
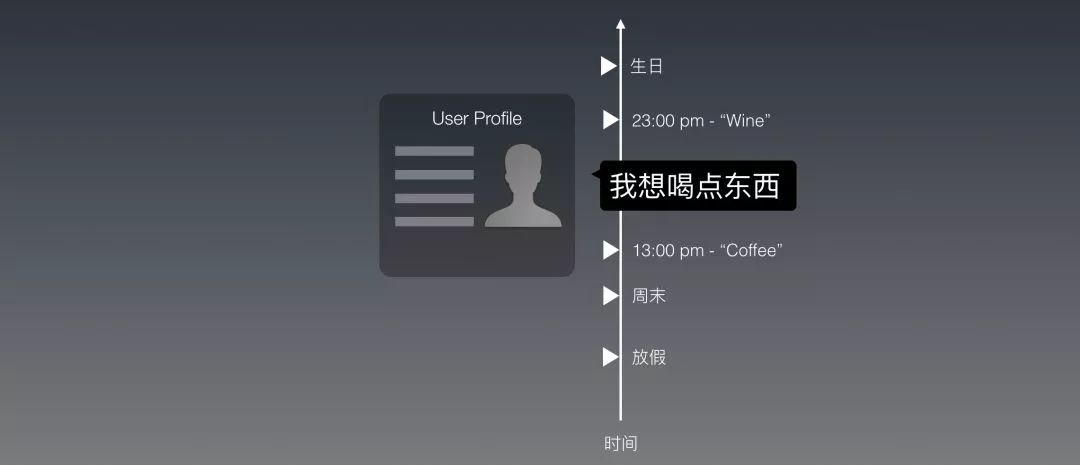
时间和用户的Profile不同的是:
1. 时间这个维度上的值有无限多;
2. 每个刻度还都不一样。比如虽然生日是同一个日期,但是过生日的次数却不重复;
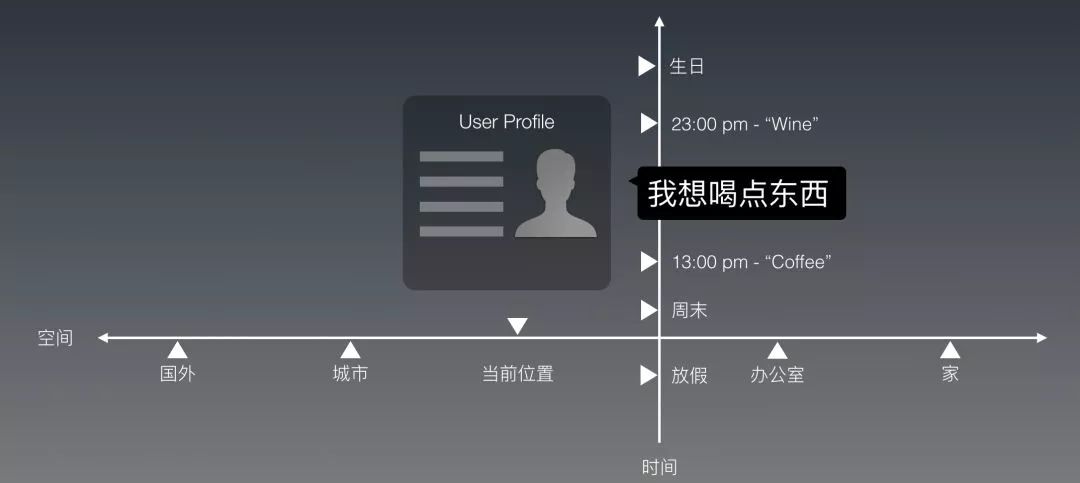
除了时间这个维度以外,还有空间。
于是我们把空间这个维度叠加(到时间)上去。你会发现,如果用户在周末的家里问这个问题(可能想叫奶茶外卖到家?),和他在上班时间的办公室里问这个问题(可能想出去走走换换思路),咱们给他的回复也应该不同。
光是时空这两个维度,就有无穷多的组合,用"if then"的逻辑也没法全部手动写完。我们造机器人的工具,到这个需求,就开始捉襟见肘了。
何况时间和空间,只是世界模型当中最显而易见的两个维度。还有更多的,更抽象的维度存在,并且直接影响与用户的对话。比如,人物之间的关系;人物的经历;天气的变化;人和地理位置的关系(是经常来出差、是当地土著、是第一次来旅游)等等等等。咱们聊到这里,感觉还在聊对话系统么?是不是感觉有点像在聊推荐系统?
要想效果更好,这些维度的因素都要叠加在一起进行因果推理,然后把结果给用户。
至此,影响人们对话的,光是信息(还不含推理)至少就有这三部分:明文(含上下文)+ 场景模型(Context)+ 世界模型。
普通人都能毫不费力地完成这个工作。但是深度学习只能处理基于明文的信息。对于场景模型和世界模型的感知、生成、基于模型的推理,深度学习统统无能为力。
这就是为什么现在炙手可热的深度学习无法实现真正的智能(AGI)的本质原因:不能进行因果推理。
根据世界模型进行推理的效果,不仅仅体现上在对话上,还能应用在所有现在成为AI的项目上,比如自动驾驶。
经过大量训练的自动驾驶汽车,在遇到偶发状况时,就没有足够的训练素材了。比如,突然出现在路上的婴儿车和突然滚到路上的垃圾桶,都会被视为障碍物,但是刹不住车的情况下,一定要撞一个的时候,撞哪一个?
又比如,对侯世达(Douglas Hofstardler )而言,“驾驶”意味着当要赶着去一个地方的时候,要选择超速还是不超速;要从堵车的高速下来,还是在高速上慢慢跟着车流走...这些决策都是驾驶的一部分。他说:“ 世界上各方面的事情都在影响着“驾驶”这件事的本质 ”。
“ 人脑有两套系统:系统1 和系统2 ”
关于 “系统1和系统2”的详情,请阅读 Thinking, Fast and Slow, by Daniel Kahneman,一本非常好的书,对人的认知工作是如何展开的进行了深入的分析。在这儿,我给还不了解的朋友介绍一下,以辅助本文前后的观点。
心理学家认为,人思考和认知工作分成了两个系统来处理:
系统1是快思考:无意识、快速、不怎么费脑力、无需推理
系统2是慢思考:需要调动注意力、过程更慢、费脑力、需要推理
系统1先上,遇到搞不定的事情,系统2会出面解决。
系统1做的事情包括: 判断两个物体的远近、追溯声音的来源、完形填空 ( "我爱北京天安 " )等等。
顺带一提,下象棋的时候,一眼看出这是一步好棋,这个行为也是系统1实现的——前提是你是一位优秀的玩家。
对于中国学生而言,你突然问他:“7乘以7”,他会不假思索的说:“49!”这是系统1在工作,因为我们在小学都会背99乘法表。这个49并非来自计算结果,而是背下来的(反复重复)。
相应的,如果你问:“3287 x 2234等于多少?”,这个时候人就需要调用世界模型中的乘法规则,加以应用(计算)。这就是系统2的工作。
另外,在系统1所设定的世界里,猫不会像狗一样汪汪叫。若事物违反了系统1所设定的世界模型,系统2也会被激活。

在语言方面,Yoshua Bengio 认为系统1不做与语言有关的工作;系统2才负责语言工作。对于深度学习而言,它更适合去完成系统1的工作,实际上它根本没有系统2的功能。
关于这两个系统,值得一提的是,人是可以通过训练,把部分系统2才能做的事情,变成系统1来完成的。比如中国学生得经过“痛苦的记忆过程”才能熟练掌握99乘法表,而不是随着出生到长大的自然经验,慢慢学会的。
但是这里有2个有意思的特征:
1. 变成系统1来处理问题的时候,可以节约能量。人们偏向相信自己的经验,是因为脑力对能量的消耗很大,这是一个节能的做法。
2. 变成系统1的时候,会牺牲辩证能力,因为系统1对于逻辑相关的问题一无所知。“我做这个事情已经几十年了”这种经验主义思维就是典型案例。
想想自己长期积累的案例是如何在影响自己做判断的?
“ 单靠深度学习搞不定语言,现在不行,将来也不行 ”
在人工智能行业里,你经常会听到有人这么说 “尽管当前技术还实现不了理想中的人工智能,但是技术是会不断演进的,随着数据积累的越来越多,终将会实现让人满意的人工智能。”
如果这个说法,是指寄希望于仅靠深度学习,不断积累数据量,就能翻盘——那就大错特错了。
无论你怎么优化“马车”的核心技术(比如更壮、更多的马),都无法以此造出汽车(下图右)。

对于大众而言,技术的可演进性,是以宏观的视角看人类和技术的关系。但是发动机的演化和马车的关键技术没有半点关系。
深度学习领域的3大牛,都认为单靠深度学习这条路(不能最终通向AGI)。感兴趣的朋友可以沿着这个方向去研究:
Geoffrey Hinton的怀疑:“我的观点是都扔掉重来吧”
Yoshua Bengio的观点:“如果你对于这个每天都在接触的世界,有一个好的因果模型,你甚至可以对不熟悉的情况进行抽象。这很关键......机器不能,因为机器没有这些因果模型。我们可以手工制作这些模型,但是这远不足够。我们需要能发现因果模型的机器。”
Yann LeCun的观点:“A learning predictive world model is what we’re missing today, and in my opinion is the biggest obstacle to significant progress in AI.”
至于深度学习在将来真正的智能上扮演的角色,在这儿我引用Gary Marcus的说法:“I don’t think that deep learning won’t play a role in natural understanding, only that deep learning can’t succeed on its own.”
“ 解释人工智障产品 ”
现在,我们了解了人们对话的本质是思维的交换,而远不只是明文上的识别和基于识别的回复。而当前的人工智能产品则完全无法实现这个效果。那么当用户带着人类的世界模型和推理能力来跟机器,用自然语言交互时,就很容易看到破绽。
Sophia是一个技术上的骗局(凡是鼓吹Sophia是真AI的,要么是不懂,要么是忽悠);
现在的AI,都不会有真正的智能(推理能力什么的不存在的,包括Alpha go在内);
只要是深度学习还是主流,就不用担心AI统治人类;
对话产品感觉用起来智障,都是因为想跳过思维,直接模拟对话(而现在也只能这样);
“用的越多,数据越多,智能会越强,产品就会越好,使用就会越多”——对于任务类对话产品,这是一个看上去很酷,实际上不靠谱的观点;
一个AI agent,能对话多少轮,毫无意义;
to C的助理产品做不好,是因为解决不了“如何获得用户的世界模型数据,并加以利用”这个问题;
to B的对话智能公司为何很难规模化?(因为场景模型是手动生成的)
先有智能,后有语言:要做到真正意义上的自然语言对话,至少要实现基于常识和世界模型的推理能力。而这一点如果能实现,那么我们作为人类,就可能真的需要开始担心前文提到的智能了。
不要用NLP评价一个对话智能产品:年底了,有些媒体开始出各种AI公司榜单,其中有不少把做对话的公司分在NLP下面。这就好比,不要用触摸屏来衡量一款智能手机。在这儿我不是说触摸屏或者NLP不重要(Essential),反而因为太重要了,这个环节成为了每一家的标配,以至于在这方面基本已经做到头了,差异不过1%。
对于一个对话类产品而言,NLU尽管重要,但只应占个整体配件的5-10%左右。更进一步来说,甚至意图识别和实体提取的部分用大厂的,产品间差异也远小于对话管理部分的差距。真正决定产品的是剩下的90%的系统。
到此,是不是有一种绝望的感觉?这些学界和行业的大牛都没有解决方案,或者说连有把握的思路都没有。是不是做对话智能这类的产品就没戏了?上限就是这样了么?
不是。对于一项技术而言,可能确实触底了;但是对于应用和产品设计而言,并不是由一个技术决定的,而是很多技术的结合,这里还有很大的空间。
作为产品经理,让我来换一个角度。我们来研究一下,既然手中的工具是这些,我们能用他们来做点什么?
Part 4
AI产品的潜力在于设计
“ AI的归AI,产品的归产品 ”

《The Prestige》2006,剧照
有一部我很喜欢的电影,The Prestige,里面讲了一个关于“瞬间移动”的魔术。对于观众而言,就是从一个地方消失,然后瞬间又从另一个地方出现。
第一个魔术师,成功的在舞台上实现了这个效果。他打开舞台上的右边的门,刚一进去的一瞬间,就从舞台左边的门出来了。对观众而言,这完全符合他们的期望。
第二个魔术师在观众席里,看到效果后惊呆了,他感觉这根本毫无破绽。但是他是魔术师——作为一个产品经理——他就想研究这个产品是怎么实现的。但是魔术行业里,最不受人待见的,就是魔术揭秘。
影片最后,他得到了答案(剧透预警):所有的工程机关、升降机、等等,都如他所料的藏在了舞台下面。但真正的核心是,第一个魔术师一直隐藏着自己的另一个双胞胎兄弟。当他打开一个门,从洞口跳下舞台的那一刻,双胞胎的另一位就马上从另一边升上舞台。
看到这里,大家可能就恍然大悟:“ 原来是这样,双胞胎啊!”
这感觉是不是有点似曾相识?在本文Part 2,我们聊到把对话系统的黑箱打开,里面就是填一张表的时候,是不是有类似的感觉?对话式人工智能的产品(对话系统)就像魔术,是一个黑箱,用户是以感知来判断价值的。
“ 我还以为有什么黑科技呢,我是双胞胎我也可以啊。”
其实这并不容易。我们先不说魔术的舞台里面的工程设计,这个魔术最难的地方是如何能在魔术师的生活中,让另一个双胞胎在大众视野里完全消失掉。如果观众们都知道魔术师是双胞胎,就很可能猜到舞台上的魔术是两个人一起表演的。所以这个双胞胎,一定不能出现在大众的“世界模型”里。
为了让双胞胎的另一个消失在大众视野里,这两兄弟付出了很多代价,身心磨,绝非一般人能接受的,比如共享同一个老婆。
这也是我的建议:技术不够的时候,设计来补。做AI产品的同学,不要期待给你智能。要是真的有智能了,还需要你干什么?人工智能产品经理需要设计一套庞大的系统,其中包括了填表、也当然包括深度学习带来的意图识别和实体提取等等标准做法、也包括了各种可能的对话管理、上下文的处理、逻辑指代等等。
这些部分,都是产品设计和工程力量发挥的空间。
“ 设计思路的基础 ”
我需要强调一下,在这里,咱们讲的是AI产品思路,不是AI的实现思路。
对于对话类产品的设计,以现在深度学习的基础,语义理解应该只占整个产品的5%-10%;而其他的,都是想尽一切办法来模拟“传送”这个效果——毕竟我们都知道,这是个魔术。如果只是识别就占了你家产品的大量心血,其他的不去拉开差异,基本出来就是智障无疑。
在产品研发方面上,如果研发团队能提供多种技术混用的工具,肯定会增加开发团队和设计的发挥空间。这个做法也就是DL(Deep Learning) + GOFAI (Good Old Fashioned AI) 的结合。GOFAI是John Haugeland首先提出的,也就是深度学习火起来之前的symbolic AI,也就是专家系统,也就是大多数在AI领域的人都看不起的 “if then…”
DL+GOFAI 这个前提,是当前一切后续产品设计思路的基础。
“ Design Principle:存在即为被感知 ”
“存在即为被感知” 是18世纪的哲学家George Berkeley的名言。加州大学伯克利分校的命名来源也是为了纪念这位唯心主义大师。这个意思呢,就是如果你不能被感知到,你就是不存在的!
我认为“存在即为被感知” 是对话类AI产品的Design principle。对话产品背后的智能,是被用户感知到而存在的。直到有一天AI可以代替产品经理,在那之前,所有的设计都应该围绕着,如何可以让用户感觉和自己对话的AI是有价值的,然后才是聪明的。

要非常明确自己的目的,设计的是AI的产品,而不是AGI本身。就像魔术的设计者,给你有限的基础技术条件,你能组装出一个产品,体验是人们难以想到。
同时,也要深刻的认识到产品的局限性。魔术就是魔术,并不是现实。
这意味着,在舞台上的魔术,如果改变一些重要的条件,它就不成立了。比如,如果让观众跑到舞台的顶上,从上往下看这个魔术,就会发现舞台上有洞。或者“瞬间移动”的不是这对双胞胎中的一个,而是一个观众跑上去说,“让我来瞬间移动试试”,就穿帮了。
Narrow AI的产品,也是一样的。如果你设计好了一个Domain,无论其中体验如何,只要用户跑到Domain的边界以外了,就崩溃了。先设定好产品边界,设计好“越界时给用户的反馈”,然后在领域里面,尽可能的模拟这个魔术的效果。
假设Domain的边界已经设定清晰了,哪些方面可以通过设计和工程的力量,来大幅增加效果呢?
其实,在“Part 3 对话的本质” 里谈到的与思维相关的部分,在限定Domain的前提下,都可以作为设计的出发点:你可以用GOFAI来模拟世界模型、也可以模拟场景模型、你可以Fake逻辑推理、可以Fake上下文指代——只要他们都限定在Domain里。
“ 选择合适的Domain ”
成本(工程和设计的量)和给用户的价值并不是永远成正比,也根据不同的Domain的不同。
比如,我认为现在所有的闲聊机器人都没有什么价值。开放Domain,没有目标、没有限定和边界,对用户而言,会认为什么都可以聊。但是其自身“场景模型”一片空白,对用户所知的常识也一无所知。导致用户稍微试一下,就碰壁了。我把这种用户体验称为 “每次尝试都容易遇到挫折”。
可能,有些Domain对回复的内容并不那么看重。也就并不需要那么强壮的场景模型和推理机制来生成回复内容。
我们假设做一个“树洞机器人”,可以把产品定义是为,扮演一个好的听众,让用户把心中的压力烦恼倾诉出来。

Human Counseling. Source: Bradley University Online
这个产品的边界,需要非常明确的,在用户刚刚接触到的时候,强化到用户的场景模型中。主要是系统通过一些语言的反馈,鼓励用户继续说。而不要鼓励用户来期望对话系统能输出很多正确且有价值的话。当用户做出一些陈述之后,可以跟上一些对“场景模型”依赖较小,泛泛的话。
“我从来没有这么考虑过这个问题,你为什么会这么想呢?”
“关于这个人,你还有哪些了解?”
“你觉得他为什么会这样?”
……
这样一来,产品在需求上,就大幅减轻了对“自然语言生成”的依赖。因为这个产品的价值,不在回复的具体内容是否精准,是否有价值上。这就同时降低了对话背后的“场景模型”、“世界模型”、以及“常识推理”这些高维度模块的需求。训练的素材嘛,也就是某个特定分支领域(比如职场、家庭等)的心理咨询师的对话案例。产品定义上,这得是一个Companion型的产品,不能真正起到理疗的作用。
当然,以上并不是真正的产品设计,仅仅是用一个例子来说明,不同的Domain对背后的语言交互的能力要求不同,进而对更后面的“思维能力”要求不同。选择产品的Domain时,尽量远离那些严重依赖世界模型和常识推理,才能进行对话的场景。
有人可能说,你这不就是Sophia的做法么?不是。这里需要强调的是Sophia的核心问题是欺骗。产品开发者是想忽悠大众,他们真的做出了智能。
在这里,我提倡的是明确告诉用户,这就是对话系统,而不是真的造出了智能。这也是为什么,在我自己的产品设计中,如果遇到真人和AI同时为用户服务的时候(产品上称为Hybrid Model),我们总是会偏向明确让用户知道,什么时候是真人在服务,什么时候是机器人在服务。这么做的好处是,控制用户的预期,以避免用户跑到设计的Domain以外去了;不好的地方是,你可能“听上去”没有那么酷。
所以,当我说“存在即为被感知”的时候,强调的是对价值的感知;而不是对“像人一样”的感知。
“ 对话智能的核心价值:在内容,不在交互 ”
多年前,还在英国读书的时候,我曾经在一个非常有名历史悠久的秘密结社里工作。我对当时的那位照顾会员需求的大管家印象深刻。你可以想象她好像是“美国运通黑卡服务”的超级礼宾,她有两个超能力:
1. Resourceful,会员的奇葩需求都能想尽办法的实现:一个身在法兰克福的会员半夜里遇到急事,临时想尽快回伦敦,半夜没有航班了,打电话找到大管家求助。最后大管家找到另一个会员的朋友借了私人飞机,送他一程,凌晨回到了伦敦。
2. Mind-reading,会员想要什么,无需多言:
“Oliver,我想喝点东西…”
“当然没问题,我待会给你送过来。” 她也不需要问喝什么,或者送到哪里。
人人都想要一个这样的管家。蝙蝠侠需要Alfred;钢铁侠需要Javis;西奥多需要Her(尽管这哥们后来走偏了);iPhone 需要Siri;这又回到了我们在Part1里提到的,AI的to C 终极产品是智能助理。
但是,人们需要这个助理的根本原因,是因为人们需要它的对话能力么?这个世界上已经有70亿个自然语言对话系统了(就是人),为什么我们还需要制造更多的对话系统?
我们需要的是对话系统后面的思考能力,解决问题的能力。而对话,只是这个思考能力的交互方式(Conversational User Interface)。如果真能足够聪明的把问题提前解决了,用户甚至连话都不想说。
我们来看个例子。

我知道很多产品经理已经把这个iPhone初代发布的东西讲烂了。但是,在这儿确实是一个非常好的例子:我们来探讨一下iPhone用虚拟键盘代替实体键盘的原因。
普通用户,从最直观的视角,能得出结论:这样屏幕更大!需要键盘的时候就出现,不需要的时候就消失。而且还把看上去挺复杂的产品设计给简化了,更好看了。甚至很多产品经理也是这么想的。实际上,这根本不是硬件设计的问题。原因见下图。

其实乔布斯在当时也讲的很清楚:物理键盘的核心问题是,(作为交互UI)你不能改变它。物理交互方式(键盘)不会根据不同的软件发生改变。
如果要在手机上加载各种各样的内容,如果要创造各种各样的软件生态,这些不同的软件都会有自己不同的UI,但是交互方式都得依赖同一种(物理键盘无法改变),这就行不通了。
所以,实际代替这些物理键盘的,不是虚拟键盘,而是整个触摸屏。因为iPhone(当时的)将来会搭载丰富的生态软件内容,就必须要有能与这些还没出现的想法兼容的交互方式。
在我看来,上述一切都是为了丰富的内容服务。再一次的,交互本身不是核心,它背后搭载的内容才是。
但是在当初看这个发布会的时候,我是真的没有get到这个点。那个时候真的难以想象,整个移动互联时代会诞生的那么多APP,都有各自不同的UI,来搭载各式各样的服务。
你想想,如果以上面这些实体键盘,让你来操作大众点评、打开地图、Instagram或者其他你熟悉的APP,是一种怎样的体验?更有可能的是,只要是这样的交互方式,根本设计不出刚才提到的那些APP。
与之同时,这也引申出一个问题:如果设备上,并没有多样的软件和内容生态,那还应该把实体键设计成触摸和虚拟的方式么?比如,一个挖掘机的交互方式,应该使用触屏么?甚至对话界面?
“ 对话智能解决重复思考 ”
同样的,对话智能的产品的核心价值,应该在解决问题的能力上,而不是停留在交互这个表面。这个“内容” 或者 “解决问题的能力” 是怎么体现的呢?

工业革命给人类带来的巨大价值在于解决“重复体力劳动”这件事。
经济学家Tyler Cowen 认为,“ 什么行业的就业人越多,颠覆这个工种就会创造更大的商业价值。” 他在Average Is Over这本书里描述到:
“ 20世纪初,美国就业人口最多的是农民;二战后的工业化、第三产业的发展,再加上妇女解放运动,就业人工最多的工种变成辅助商业的文字工作者比如秘书助理呼叫中心(文员,信息输入)。1980/90年代的个人计算机,以及Office 的普及,大量秘书,助理类工作消失。”
这里提及的工作,都是需要大量重复的工作。而且不停的演变,从重复的体力,逐步到重复的脑力。
从这个角度出发,对一个场景背后的“思考能力”没有把控的AI产品,会很快被代替掉。首当其冲的,就是典型意义上的智能客服。
在市场上,有很多这样的智能客服的团队,他们能够做对话系统(详见Part 2),但是对这各领域的专业思考,却不甚了解。
我把“智能客服” 称为“前台小姐姐”——无意冒犯,但是前台小姐姐的主要工作和专业技能并没有关系。他们最重要的技能就是对话,准确点说是用对话来“路由”——了解用户什么需求,把不合适的需求过滤掉,再把需求转给专家去解决。
但是对于一个企业而言,客服是只嘴和耳,而专家才是脑,才是内容,才是价值。客服有多不核心?想想大量被外包出去的呼叫中心,就知道了。
与这类客服机器人产品对应的,就是专家机器人。一个专家,必定有识别用户需求的能力,反之不亦然。你可以想象一个企业支付给一个客服多少薪资,又支付给一个专家多少薪资?一个专家需要多少时间培训和准备才能上岗,客服小姐姐呢?于此同时,专业能力是这个机构的核心,而客服不是。
正因为如此,很多人认为,人工的呼叫中心,以后会被AI呼叫中心代替掉;而我认为,用AI做呼叫中心的工作,是一个非常短暂的过渡型方案。很快代替人工呼叫中心的,甚至代替AI呼叫中心,是具备交互能力的专家AI中心。在这儿,“专家”的意义大于“呼叫”。
在经历过工具化带来的产能爬坡和规模效应之后,他们成本差不多,但是却专业很多。比如他直接链接后端的供给系统的同时,还具备专业领域的推理能力,也能与用户直接交互。
NLP在对话系统里解决的是交互的问题。
在人工智能产品领域里,给与一定时间,掌握专业技能的团队一定能对话系统;而掌握对话系统的团队则很难掌握专业技能。试想一下在几年前,移动互联刚刚出现的时候,会做app的开发者,去帮银行做app;而几年之后银行都会自己开发app,而开发者干不了银行的事。
在这个例子里,做AI产品定义的朋友,你的产品最好是要代替(或者辅助)某个领域专家;而不要瞄准那些过渡性岗位,比如客服。
从这个角度出发,对话智能类的产品最核心的价值,是进一步的代替用户的重复思考。Work on the mind not the mouth. 哪怕已经是在解决脑袋的问题,也尽量去代替用户系统2的工作,而不只是系统1的工作。
在你的产品中,加入专业级的推理;帮助用户进行抽象概念与具象细节之间的转化;帮助用户去判断那些出现在他的模型中,但是他口头还没有提及的问题;考虑他当前的环境模型、发起对话时所处的物理时空、过去的经历;推测他的心态,他的世界模型。
先解决思考的问题,再尽可能的转化成语言。
Part 5
AIPM
“ 缺了什么?”
2018年10月底,我在慕尼黑为企业客户做on site support。期间与客户的各个BU、市场老板们以及自身的研发团队交流对话AI的应用。作为全球最顶尖的汽车品牌之一,他们也在积极寻求AI在自身产品和服务上的应用。
不缺技术人才。尽管作为传统行业的大象,可能会被外界视为不擅长AI,其实他们自身并不缺少NLP的研发。当我跟他们的NLP团队交流时,发现基本都有世界名校的PHD。而且,在闭门的供应商大会上,基本全球所有的科技大厂和咨询公司都在场了。就算实在搞不了,也大有人排着队的想帮他们搞。
创新的意愿强烈。在我接触过的大企业当中,特别是传统世界100强当中中,这个巨头企业是非常重视创新的。经过移动互联时代,丢掉的阵地,他们是真心想一点点抢回来,并试图领导所在的行业,而不是follow别人的做法。不仅仅是像“传统的大企业创新”那样做一些不痛不痒的POC,来完成创新部门的KPI。他们则真的很积极地推进AI的商业化,而且勇于尝试改变过去和Tech provider之间的关系。这点让我印象深刻,限于保密条款,在此略过细节。(关于国际巨型企业借新技术的初创团队之手来做颠覆式创新,也是一个很有意思的话题,以后新开一个Topic。)
数据更多。那么传统巨头的优势就在于,真正拥有业务场景和实际的数据。卖出去的每一台产品都是他们的终端,而且开始全面联网和智能化。再加上,各种线下的渠道、海量的客服,其实他们有能力和空间来搜集更完整的用户生命周期数据。
当然,作为硬币的另一面,百年品牌也自然会有严重的历史牵绊。机构内部的合规、采购流程、数据的管控、BU之间的数据和行政壁垒也是跑不掉的。这些环节的Trade off确实大大的影响了对上述优势的利用。
但是最缺少的还是产品定义能力。
如果对话智能的产品定义失败,后面的执行就算是完美的,出来的效果也是智障。有些银行的AI机器人就是例子:立项用半年,竞标用半年,开发用一年,然后上线跑一个月就因为太蠢下线了。
但这其实并不是传统行业的特点,而是目前所有玩家的问题——互联网或科技公司的对话AI产品也逃不掉。可能互联网企业还自我感觉良好,在这产品设计部分,人才最不缺了——毕竟“人人都是产品经理” 嘛。但在目前,咱们看到的互联网公司出来的产品也都是差不多的效果,具体情况咱们在Part 2里已经介绍足够多了。
我们来看看难点在哪里。
AI产品该怎么做定义呢?也就是,需要怎样的产品才能实现商业需求。技术部门往往主要关注技术实现,而不背商业结果KPI;而业务部门的同事对AI的理解又很有限,也就容易提出不合适的需求。
关键是,在做产品定义时,你想要描述 “我想要一个这样的AI,它可以说…” 的时候你会发现,因为是对话界面,你根本无法穷尽这个产品的可能性。其中一个具体细节就是,产品文档该怎么写,这就足够挑战了。
“ 对话AI产品的管理方法 ”
先给结论:如果还想沿用管理GUI产品的方法论来管理对话智能产品,这是不可能的。
从行业角度来看,没有大量成功案例,就不会有流水线;没有流水线,就没有基于流水线的项目管理。

也就是说,从1886年开始第一辆现代汽车出现,到1913年才出现第一条流水线——中间有27年的跨度。再到后来丰田提出The Toyota Way,以精益管理(Lean Management)来快速迭代(类似敏捷开发)以尽量避免浪费,即Kaizen(改善),这已经是2001年的事情了。
这两天和其他也在给大企业做对话的同行交流的时候,听到很多不太成功的产品案例,归结起来几乎都是因为 “产品Scope定义不明”,导致项目开展到后面根本收不了尾。而且因为功能之间的耦合紧密,连线都上不了(遇到上下文对话依赖的任务时,中间环节一但有缺失,根本走不通流程)。这些都是行业早期不成熟的标志。
“ 对话AI产品的Design Principle 尚未出现 ”
对话智能领域相对视觉类的产品,有几个特性上的差异:
1)是产品化远不如视觉类AI成熟;
2)深度学习在整个系统里扮演的角色虽然重要,但是还是很少,远不够撑起来有价值的对话系统;
3)产品都是黑箱,目前在行业中尚无比较共同认可的设计标准。
APP发展到后面,随着用户的使用习惯的形成,和业界内成功案例的“互相交流”,逐步形成了一些设计上的共识,比如下面这一排,最右边红圈里的 “我”:
但是,从2007年iPhone发布,到这些移动产品的设计规范逐步形成, 也花了近6、7年时间,且不提这是图形化界面。
到如今,这类移动设备上的产品设计标准已经成熟到,如果在设计师不遵循一些设计思路,反而会引起用户的不习惯。只是对话系统的设计规范,现在谈还为时尚早。
到这里,结合上述两个点(对话AI产品的管理方法、设计规范都不成熟),也就可以解释为什么智能音箱都不智能。因为智能音箱的背后都是一套“技能打造框架”,给开发者,希望开发者能用这套框架来制作各种“技能”。
而“对话技能类平台” 在目前根本走不通。任何场景一旦涉及到明文识别以外的,需要对特定的任务和功能进行建模,然后再融合进多轮对话管理里的场景,以现在的产品成熟程度,都无法抽象成有效的设计规范。现在能抽象出来的,都是非常简单的上下文管理(还记得Part 2里的“填表”么?)。
我就举一个例子,绝大部分的技能平台,根本就没有“用户生命周期管理”的概念。这和服务流程是两码事,也是很多机器人智障的诸多原因之一。因为涉及到太细节和专业的部分,咱们暂且不展开。
也有例外的情况:技能全部是语音控制型,比如“关灯开灯” “开空调25度”。这类主要依赖明文识别的技能,也确实能用框架实现比较好的效果。但这样的问题在于,开放给开发者没有意义:这类技能既不需要多样的产品化;开发者从这类开发中也根本赚不到钱——几乎没有商业价值。
另一个例外是大厂做MLaaS类平台,这还是很有价值的。能解决开发者对深度学习的需求,比如意图识别、分词、实体提取等最底层的需求。但整个识别部分,就如我在Part 3&4里提到的,只应占到任务对话系统的10%,也仅此而已。剩下的90%的工作,也是真正决定产品价值的工作,都得开发者自己搞。
他们会经历些什么?我随便举几个最简单的例子(行业外的朋友可以忽略):
如果你需要训练一个意图,要生成1000句话来做素材,那么“找100个人,每人写10句” 的训练效果要远好于 “找10个人,每人写100句”;
是用场景来分意图、用语义来分意图和用谓语来拆分意图,怎么选?这不仅影响机器人是否能高效支持“任务”之间的跳转,还影响训练效率、开发成本;
有时候意图的训练出错,是训练者把自己脑补的内容放进去了;
话术的重要性,不仅影响用户看着舒不舒服,更决定了他的回复的可能性——以及回复的回复的可能性——毕竟他说的每一句后面的话,都需要被识别后,再回复;
如果你要给一个电影院做产品,最好用图形化界面,而不要用语言来选座位:“现在空着的座位有,第一排的1,2,3,4….”
这些方面的经验和技巧数都数不完,而且还是最浅显、最皮毛的部分。你可以想象,对话智能的设计规范还有多少路要走——记得,每个产品还是黑箱,就算出了好效果,也看不到里面是怎么设计的。
“ 一个合适的AIPM ”
当真正的人工智能实现之后,所有产品经理所需要做的思考,都会被AI代替。所以,真正的人工智能也许是人类最后的一个发明。在那一天之前,对话智能产品经理的工作,是使用各种力量来创造智能给人的感觉。
AIPM一定要在心中非常明确 “AI的归AI,产品的归产品”。做工具的和用工具的,出发点是完全不同。应该是带着做产品的目的,来使用AI;千万不要出现“AIPM是来实现AI的”这样的幻觉。

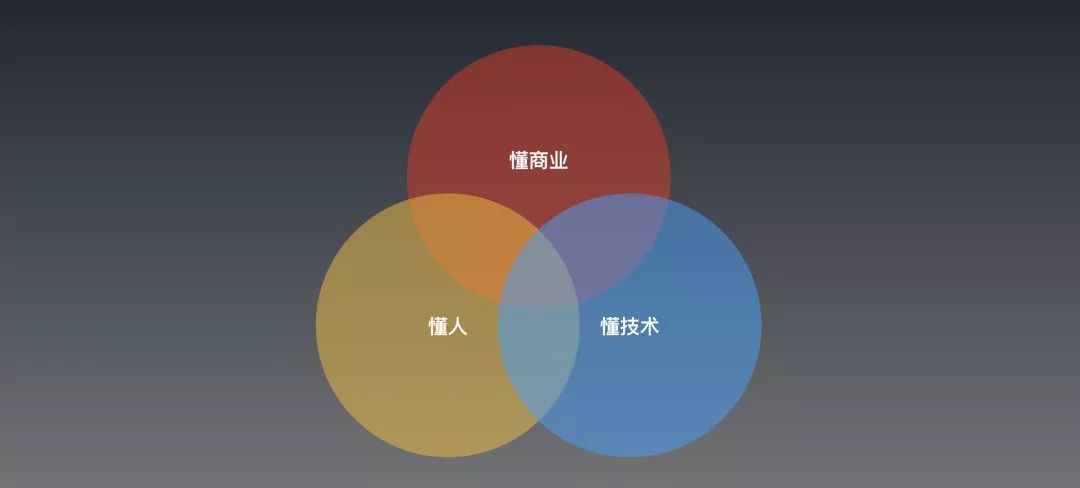
我们都熟悉,PM需要站在“人文和技术的十字路口”来设计产品。那么对话智能的AIPM可能在这方面可能人格分裂的情况更极端,以至于甚至需要2个人来做配合成紧密的产品小组——我认为一个优秀的对话智能产品经理,需要在这三个表现优秀:
1. 懂商业:就是理解价值。
对话产品的价值一定不在对话上,而是通过对话这种交互方式(CUI)来完成背后的任务或者解决具体问题。一个本来就很强的APP,就不要想着去用对话重新做一遍。反而是一些APP/WEB还没有能很好解决的问题,可以多花点时间研究看看。
这方面在Part 4 里的对话智能的核心价值部分,当中有详细阐述,在这里就不重复了。
2. 懂技术:理解手中的工具(深度学习 + GOFAI)
一个大厨,应该熟悉食材的特性;一个音乐家,应该熟悉乐器的特征;一个雕塑家,应该熟悉手中的凿子。大家工具都差不多,成果如何,完全取决于艺术家。
现在,AIPM手中有深度学习,那么就应该了解它擅长什么和不擅长什么。以避免提出太过于荒谬的需求,导致开发的同学向你发起攻击。了解深度学习的特性,会直接帮助我们判断哪些产品方向更容易出效果。比如,做一个推荐餐厅的AI,就比做一个下围棋的AI难太多了。
下围棋的产品成功,并不需要人类理解这个过程,接受这个结果就行。而推荐一个餐厅给用户,则必须要去模拟人的思维后,再投其所好。
人们在想要推荐餐厅的时候,通过对话,了解他的需求(绝对不能问太多,特别是显而易见的问题,比如他在5点的时候,你问他要定几点的餐厅)
对于围棋而言,每次(单次)输入的可能性只有不超过棋盘上19x19=361种可能性;一局棋的过程尽管千变万化,我们可以交给深度学习的黑箱;最后决定输赢所需要的信息,全部呈现在棋盘上的落子上,尽管量大,但与落子以外的信息毫无关系,全在黑箱里,只是这个黑箱很大。最后,输出的结果的可能性只有两种:输或者赢。
对于推荐餐厅。每次输入的信息,实际并不包含决策所需要的全部信息(无法用语言表达所有相关的影响因素,参考Part 3 里世界模型部分);而且输出的结果是开放的,因为推荐的餐厅,既不可被量化,更不存在绝对的对错。
了解CUI的特性后,不该用对话的就不要强上对话交互;有些使用对话成本非常高,又很不Robust的环节,同时用户价值和使用频次又很低的,就要考虑规避——咱们是做产品的,不是实现真正的AI的,要分清楚。
3. 懂人:心理和语言
这可能是当前对话类产品最重要的地方,也是拉开和其他产品设计的核心部分。也可能是中年人做产品的第二春。
对心理的理解,指的是当用户在说话的时候,对他脑中的模型的理解。英文中“Read the room”就是指讲话之前,先观察一下了解周围听众的情况,揣摩一下他们的心理,再恰当的说话。
比如,讲话的时候,是否听众开始反复的看表?这会让直接影响对话的进程。你有遇到过和某人对话起来感觉很舒服的么?这个人,不仅仅是语言组织能力强,更重要的则是他对你脑中的对话进程的把握,以及场景模型,甚至对你的世界模型有把握。他还知道怎么措辞,会更容易让你接受,甚至引导(Manipulate)你对一些话题的放弃,或者是加强。
对话系统的设计也是一样的。哪些要点在上文中说过?哪些类型的指代可以去模拟?如果是文字界面,用户会不会拉回去看之前的内容?如果是语音界面,用户脑中还记不记得住?如果记得住,还强调,会感觉重复;如果记不住,又不重复,会感觉困惑。
对语言的理解,则是指对口语特性的理解。我知道Frederick Jelinek说的“每当我开除一个语言学家,Speech识别的准确率就会增高”。只是,现在根本没有真正意义上的自然语言生成(NLG),因为没有真正的思维生成。
所以,任务类的对话的内容,系统不会自然产生,也无法用深度学习生成。对于AIPM而言,要考虑的还是有很多语言上的具体问题。一个回复里,内容会不会太长?要点该有几个?谓语是否明确,用户是否清晰被告知要做什么?条件又是什么?这样的回复,能引发多少种可能的问询?内容措辞是否容易引起误解(比如因为听众的背景不同,可能会有不同的解读)?
从这个角度而言,一个好的对话系统,必定出自一个很能沟通的人或者团队之手。能为他人考虑,心思细腻,使用语言的能力高效,深谙人们的心理变化。对业务熟悉,能洞察到用户的Context的变化,而其格调又帮助用户控制对话的节奏,以最终解决具体问题。
Part 6
可见的未来是现状的延续
“ 过渡技术”
在几周前,我与行业里另一家做对话的CEO讨论行业的将来。当我聊到“深度学习做对话还远达不到效果”的态度时,他问我:“如果是悲观的,那么怎么给团队希望继续往前进呢?”
其实我并不是悲观的,可能只是更客观一点。
既然深度学习在本质上搞不定对话,那么现在做对话AI的实现方式,是不是个过渡技术?这是一个好问题。
我认为,用现在的技术用来制作AI的产品,还会持续很长时间,直到真正智能的到来。
如果是个即将被替代或者颠覆的技术,那就不应该加码投入。如果可以预见未来,没人想在数码相机崛起的前期,加入柯达;或者在LED电视普及之前,重金投入在背投电视的研发上。而且难以预测的不仅仅是技术,还有市场的发展趋势。比如在中国,作为无现金支付方式,信用卡还没来得及覆盖足够多的支付场景,就被移动支付断了后路。
而现在的对话智能所使用的技术,还远没到这个阶段。
Clayton M. Christensen在《创新者的窘境》里描述了每个技术的三个阶段:
第一个阶段,缓步爬坡;
第二个阶段开始迅猛发展,但是到接近发展的高地(进步减速)的时候,另一个颠覆式技术可能已经悄悄萌芽,并重复着第一个技术的发展历程;
第三个阶段,则进入发展瓶颈,并最终被新技术颠覆
下图黑色部分,为书中原图:
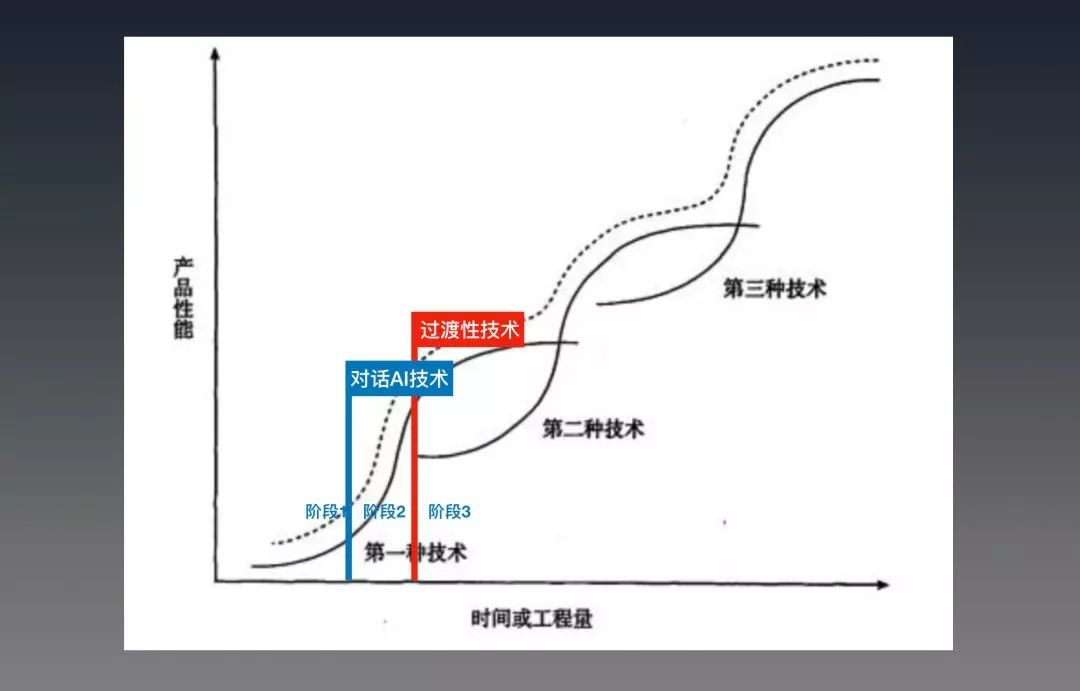
而当前对话AI的技术,还在第一阶段(蓝色旗帜位置)称不上是高速发展,还处于探索的早期。黑箱的情况,会使得这个周期(第一阶段)可能比移动时代更长。
以当前的技术发展方向,结合学术界与工业界的进展来看,第二个技术还没有出现的影子。
但是同样因为深度学习在对话系统中,只扮演的一小部分角色,所以大部分的空间,也是留给大家探索和成长的空间。换句话来讲,还有很多发展的潜力。
前提是,我们在讨论对话类的产品,而不是实现AI本身。只是,这个阶段的对话AI,还不会达到人们在电影里看到的那样,能自如的用人类语言沟通。
2) 服务提供者崛起的机会
因为上述的技术发展特点,在短期的将来,数据和设计是对话智能类产品的壁垒,技术不是。
只是这里说的数据,不是指的用来训练的数据。而是供给端能完成服务的数据;能够照顾用户整个生命周期的数据;是当对话发生的时候,用户的明文以外的数据这些数据;影响用户脑中的环境模型、影响对任务执行相关的常识推理数据,等等。
而随着IOT的发展,服务提供者,作为与用户在线下直接打交道的一方,是最有可能掌握这些数据。他们能在各个Touch point去部署这些IOT设备,来搜集环境数据。并且,由他们决定要不要提供这些数据给平台方。
但是,往往这些行业里的玩家都是历史悠久、行动缓慢。其组织机构庞大,而且是组织结构并不是为了创新而设计,而是围绕着如何能让庞大的躯干不用思考,高速执行。而这也正是互联网企业和创业企业的机会。
3)超级终端与入口之争
对话智能类的产品必须搭载在硬件终端上。很多相关的硬件尝试,都是在赌哪个设备能够成为继手机之后的下一个超级终端。就好像智能手机作为计算设备,代替了PC的地位一样。
毕竟,在移动时代,抢到了超级终端,就抢到了用户获取服务的入口。在入口的基础之上,才是各个应用。
如果对话智能发展到足够好的体验,并能覆盖更多的服务领域时,哪一个终端更有可能成为下一个超级终端呢?智能音箱、带屏幕的音箱、车载设备甚至车机、穿戴设备等等都可以搭载对话智能。在5G的时代,更多的计算交给云端,在本地设备上留下能耗较低的OS和基础设施,I/O交给麦克风和音频播放就完成了。

credit:Pixabay
因此任意一个联网设备,都可能具备交互和传递服务的能力,进一步削弱超级终端的存在。也就是说,作为个人用户,在任意一个联网设备上,只要具备语音交互和联网能力,都可能获得服务。特别是一些场景依赖的商业服务,如酒店、医院、办公室等等。
随着这些入口的出现,在移动时代的以流量为中心的商业模式,可能将不再成立。而新的模式可能诞生,想象一下,每一个企业,每一个品牌都会有自己的AI。一个或是多个,根据不同的业务而产生;对内部员工服务或者协助其工作,同时也接待外部的客服,管理整个生命周期从注册成这家企业的用户开始,到最后(不幸地)中断服务为止。
只是这个发展顺序是,先有服务,再有对话系统——就好像人,是有脑袋里的想法,再用对话来表达。
结语
在本文中,所有与技术和产品相关的讨论,都是在强调一个观点:一个产品是由很多技术组合而成。我不希望传达错误的想法,类似“深度学习不重要”之类的;相反,我是希望每一类技术都得到正确的认识,毕竟我们离真正的人工智能还有距离,能用上的都有价值。
作为AI从业者,心中也会留有非理性的希望,能早日见证到人造的智能的到来。毕竟,如果真正的智能出现了,可能产品经理(以及其他很多岗位)就彻底解放了(或者被摧毁了)。
这或许就是人类的最后一个发明。
本文开始于慕尼黑,最终成稿于北京,断断续续耗时接近3个月。期间与很多大企业,行业内的创业者,还有一些资本的同学沟通交流。在此表示感谢,就不一一点名啦。
关于作者
作者Mingke,正在从事对话智能方面的创业,为世界一百强企业提供对话智能应用的咨询和解决方案。上次《为什么现在的人工智能助理都像人工智障》一文发出来之后,认识结交了不少行业内的朋友。希望这次,把过去一段时间的思考与大家分享,能给行业内的新老朋友们一些启发,有兴趣沟通和碰撞的也欢迎与我联系。
欢迎行业里的新老朋友勾搭吐槽,微信:mingke27 (请注明称呼+所在机构)