前沿 | DeepMind提出SPIRAL:使用强化对抗学习,实现会用画笔的智能体
选自DeepMind
作者:Ali Eslami等
机器之心编译
参与:路雪
近日,DeepMind 发布博客,提出一种结合了对抗训练和强化学习的智能体 SPIRAL。该智能体可与绘图程序互动,在数位画布上画画、改变笔触的大小、用力和颜色,并像街头艺人一样画画。也就是说,通过向 SPIRAL 提供人类用于描绘周围世界的工具,它们也可以生成类似的表征。
人类眼中的世界不只是角膜映射出的图像。比如,当我们看一幢建筑,赞美其设计精巧复杂时,我们能够欣赏到它的精巧工艺。通过创造事物的工具来解读事物是帮助我们理解世界的一项重要能力,也是人类智能的重要组成部分。
DeepMind 希望其系统能够按类似的方式构建对世界的丰富表征。例如,当系统观察一幅画的图像时,它们能够理解画家使用的笔触,而不只是看到屏幕上呈现的像素。
在《Synthesizing Programs for Images using Reinforced Adversarial Learning》研究中,DeepMind 给人工智能体配备了用于生成图像的工具,并展示了智能体可以推断出数字、字符和画像被创造出来的过程。关键是,它们学会这么做完全是出于自觉,没有使用人类标注的数据集。这与最近的研究《A Neural Representation of Sketch Drawings》恰恰相反,后者目前仍依赖于从人类演示中学习,是一个时间密集型的过程。

DeepMind 设计了一种深度强化学习智能体,该智能体可与计算机绘图程序(http://mypaint.org/)互动,在数位画布上画画、改变笔触的大小、用力和颜色。最初,这一未经训练的智能体下笔随意,其涂鸦没有明显的内容或结构。为了解决这个问题,DeepMind 不得不提出一种方式来奖励智能体,鼓励它生成有意义的涂鸦。
为此,DeepMind 训练出第二个神经网络,叫作判别器(discriminator),旨在预测特定画作是智能体生成的,还是来自现实照片数据集。绘画智能体所接受的奖励决定于它多大程度上能够「欺骗」判别器,使之认为其画作是真的。换言之,智能体的奖励信号是由自己学习而来。这和生成对抗网络使用的方法类似,但也有不同,因为 GAN 中的生成器通常是一个可以直接输出像素的神经网络。而 DeepMind 的智能体通过写图形程序与绘画环境互动,来生成图像。

在第一组实验中,智能体被训练来生成类似 MNIST 数字的图像,只对智能体显示数字,而没有数字生成的过程。通过尝试生成欺骗判别器的图像,智能体学会控制笔触,并绘制适合不同数字的风格,这种技术叫作视觉程序合成(visual program syhthesis)。
DeepMind 还训练它来重现特定图像。这里,判别器要确定重现出的图像是目标图像的复制,还是由智能体生成的。判别器判断二者的难度越大,智能体得到的奖励就越多。
关键是,该框架具备可解释性,因为它能生成一系列控制模拟画刷的动作。这意味着该模型可以将其学得的东西应用到模拟绘图程序上,以在其他类似环境中重新创建字符,如在模拟或真实的机械臂上。
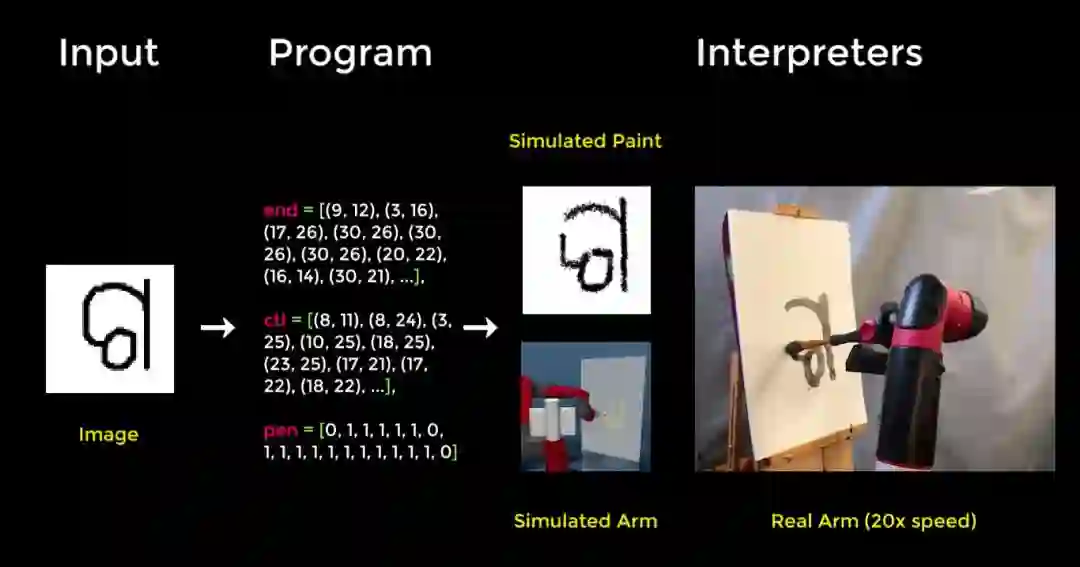
也可以将该框架扩展到真实数据集上。在训练智能体绘制名人人脸时,它能够捕捉人脸、色调、发型的主要特征,就像一个寥寥几笔绘制人像的街头画家一样。

从原始感知中找到结构化表征是人类拥有且经常使用的能力。该研究显示通过向智能体提供人类用于描绘周围世界的工具,它们也可以生成类似的表征。这样,它们学会生成可简练表达因果关系的视觉程序。
尽管该研究只能代表朝灵活程序合成迈进的一小步,但 DeepMind 期望类似的技术可以赋予人工智能体类人感知、生成和交流的能力。
来看SPIRAL如何画出手写数字和名人肖像:
论文:Synthesizing Programs for Images using Reinforced Adversarial Learning

论文链接:https://deepmind.com/documents/183/SPIRAL.pdf
摘要:近年来,深度生成网络的进展带来了令人瞩目的成绩。但是,此类模型通常把精力浪费在数据集细节上,可能是因为其解码器的归纳偏置较弱。这样图形引擎就有了用武之地,因为图形引擎将低级别细节抽象化,并将图像表示为高级别程序。当前结合了深度学习和渲染器的方法受限于手动制作的相似度或距离函数、对大量监督信息的需求,或者将推断算法扩展至更丰富数据集的难度。为了缓解这些问题,我们提出了 SPIRAL,一种对抗训练的智能体,可以生成由图形引擎来执行的程序,以解释和采样图像。该智能体的目标是欺骗判别器网络(分辨真实数据和渲染数据),该智能体在分布式强化学习环境中进行训练,且训练过程无需任何监督。令人惊讶的是,使用判别器的输出作为奖励信号是使智能体获得期望输出渲染的关键。目前,这是在难度较高的现实世界数据集(MNIST、OMNIGLOT、CELEBA)和合成 3D 数据集上的第一次端到端、无监督和对抗逆图形(adversarial inverse graphics)智能体演示。

原文链接:https://deepmind.com/blog/learning-to-generate-images/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


