数据库村的旺财和小强
本来想单独写个MVCC的,但是后来一想,如果不扯上事务的隔离级别,理解起来不是很方便, 还是在原来的一篇文章《数据库村的旺财和小强》上改写吧。 没看过的同学自然可以从头看起,看过的同学可以复习下,再想想事务隔离级别的本质。
这是一篇超级干的干货,尤其是MVCC部分,很烧脑,挑战一下吧。
1丢失的数据
旺财是数据库村的一个程序, 小强也是。
数据库村有个特点, 很多数据支持共享操作,多个程序可以同时读写,他们俩经常会为了读写同一个数据, 争夺的不可开交。
这一天,当旺财和小强对同一个银行账户A进行写操作时候, 出现了这么一个错误:
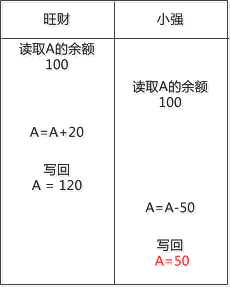
看看, 本来旺财要加上的20元就丢掉了。
同样的事情发生的多了, 他俩给这种情况起了一个名字,叫“丢失修改”, 其实说白了就是俩人都去写一个数据, 一个人的数据把另外一个给覆盖了。
村里的MySQL老头儿说: “你们两个小家伙,写数据的时候连加锁都不做,肯定会出大乱子!"
旺财说:“加什么锁?”
“来来来, 我教你们一个排他锁(Exclusive Lock) , 简称X锁, 旺财你要写数据了, 就把它用X锁锁住, 锁住后,除非你释放, 否则小强无法获得X锁。 这不就解决你们的问题了? ”
小强想了想, 就把上面的操作过程用X锁改了一下:
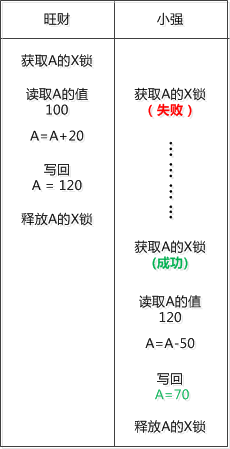
旺财说:“果然不错, 确实可以解决两个人同时修改导致的问题。”
2脏数据
小强说:“旺财, 我们约定,写数据的时候都用X锁吧?”
旺财说: “这没问题, 可是X锁只在写数据的时候用, 我们读数据是不用加锁的, 我想起了一种情况, 你看看怎么办?”

小强在旺财执行的途中读了A的值, 但是旺财把对A的修改给回滚(Rollback)了, 这下小强尴尬了, 他读到了脏数据。
“要不我们在读取数据的时候也加个X锁 ? ” 小强说。
“那样太严格了, 就是读一个数据啊, 值得吗?”
“这样吧, 我们再搞一个新的锁出来, 专门用于共享数据的读取, 就叫共享锁(Share lock) ,简称S锁, 这个锁和之前的排他锁X锁有区别, 主要用于读取数据, 如果一个数据加了X锁, 就没法加S锁, 同样加了S锁, 就没法加X锁” 小强想出了一个点子。
“那如果我加了S锁, 你还能加S锁吗? ” 旺财问。
“应该可以吧, 咱们俩都是读数据, 互不影响啊。 还有为了防止长时间的锁住, 我们可以约定一下,不管我们要做的事情有多少, 读一个数据之前加S锁, 读完之后立刻释放该S锁 ! ”
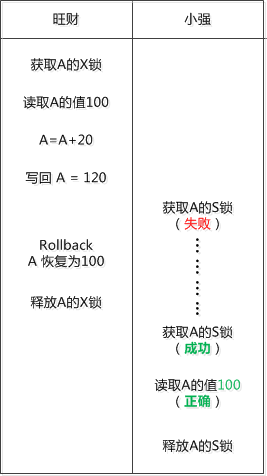
果然,这样一来“脏数据”的问题就解决了 !
3没法重复读?
旺财和小强两个程序相安无事了很久, 但是S锁在读完数据后立刻释放的约定, 导致出了一个新问题。
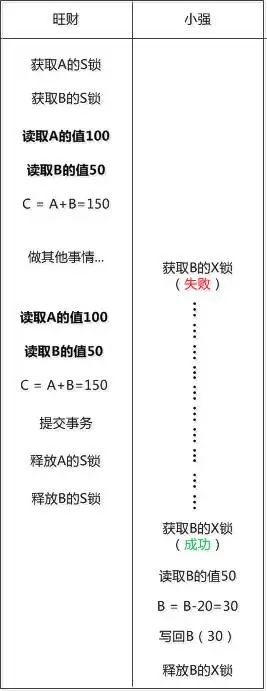
旺财在一次数据处理中, 先读取了A和B的值, 相加得到了150 , 然后小强把B改成了30
旺财再次读取A和B, 发现求和以后是130 , 刚才的不一样了!
(码农翻身注: 假定旺财的处理是在一个事务当中)

旺财说: “小强, 我在读取数据的时候你不能改啊 , 要不然我这里会出现不一致, 你看刚开始是A+B是 150, 现在变成130了”
小强说: “我们之前的约定是读数据时加S锁, 读完立马释放, 问题就出现在这里了。”
“看来在读数据的时候, 也需要一直锁定了, 直到事务提交。”
4幻觉出现
旺财和小强现在已经能灵活的使用X锁和S锁了。
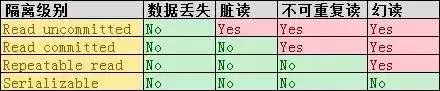
他们俩总结了一下, 分为了这么几种情况:
1. 写数据时加上X锁,直到事务结束, 读的时候不加锁。
虽然能够避免丢失数据, 但是可以读到没有提交或者回滚的内容 (脏数据), 这其实就是数据库最低的事务隔离级别 --- Read uncommitted
2. 写数据的时候加上X锁, 直到事务结束, 读的时候加上S锁, 读完数据立刻释放。
这能避免“丢失数据”和“脏数据”, 但是会出现“不可重复读”的问题 , 这是第二级的事务隔离级别 -- Read committed
3. 写数据的时候加上X锁, 直到事务结束, 读数据的时候加S锁, 也是直到事务结束。
这能避免“丢失数据”和“脏数据”, “不可重复读”三个问题 , 这是数据库常用的隔离级别 --
Repeatable read
整个世界似乎清净了。
有一次旺财对一个“学生表”进行操作,选取了年龄是18岁的所有行, 用X锁锁住, 并且做了修改。
改完以后旺财再次选择所有年龄是18岁的行, 想做一个确认, 没想到有一行竟然没有修改!
这是怎么回事? 出了幻觉吗?
原来就在旺财查询并修改的的时候, 小强也对学生表进行操作, 他插入了一个新的行,其中的年龄也是18岁! 虽然两个人的修改都没有问题, 互不影响, 但从最终效果看, 还是出了事。
(码农翻身注: 正是小强的操作, 让旺财出现了“幻读”)
旺财说: “没辙了, 我们俩非得串行执行不可, 你必须得等我执行完。 ”
这就是数据库事务隔离级别的终极大招:Serializable (串行化)
最后, 为了方便记忆, 他们俩倒腾了半天, 整出了一张表, 用于记录各种情况:
(点击看大图)
两个人看着这张表, 感慨的说:“唉, 这数据库村的事务隔离级别可真是不容易啊!”
5MVCC
旺财和小强使用了一段时间的“串行化”隔离级别,虽然不会出错,但是效率实在太低了。数据库村的人都笑话他俩干活太慢, 于是俩人商量着退到“可重复读”,虽然会出现幻读,但是也能忍受。
“可重复读”用了一段时间,他们又不满意了。
旺财唉声叹气地说:“为了实现可重复读, 我们需要在事务中对读操作加锁,并且得持续到整个事务结束,这实在是不爽啊!”
小强说:“是啊,我修改数据的时候,还得等待你读完成,效率就太低喽。”
许久不见的MySQL听到他俩的抱怨,插嘴道:“看来你们两个已经开始思考了啊,我有一个办法, 可以在读的时候不用加锁,也能实现可重复读。”
“你就吹吧!这怎么可能?” 旺财和小强根本不相信。
MySQL老头儿说: “你们两个太孤陋寡闻了,这个方法叫做MVCC(多版本并发控制)。”
顿了一下, MySQL老头儿故意激他们:“可是有点难啊,你们俩不一定能弄明白。”
旺财和小强很不服气:“说来听听!”
“假设啊,数据库中有一个叫做users的表,里边有这么一行数据:” MySQL老头儿开始画图:

“现在,我要给他加两个隐藏的字段:”

“事务ID? 是不是每次开始事务的时候分配的? ”
“没错,这个事务ID就表明这一行数据是哪个事务操作的,注意啊,事务ID是一个递增的数字,每次开始新事务,这个数字就会增加。”
“这有什么用?”
“别急,马上就会讲到,” MySQL老头儿地说:“ 旺财,小强,假设你们俩的事务中SQL的执行次序如下: ”
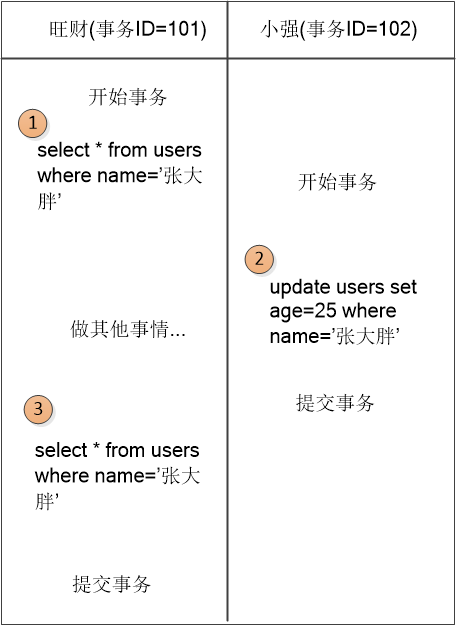
在标号为 (1) 的地方,数据是这样的:
与此同时,需要建立一个叫做Read View的数据结构,它有三个部分:
(1) 当前活跃的事务列表 ,即[101,102]
(2) Tmin ,就是活跃事务的最小值, 在这里 Tmin = 101
(3) Tmax, 是系统中最大事务ID(不管事务是否提交)加上1。 在这里例子中,Tmax = 103
(注: 在可重复读的隔离级别下,当第一个Read操作发生的时候,Read view就会建立。 在Read Committed隔离级别下,每次发出Read操作,都会建立新的Read view。)
旺财和小强还不知道有什么用处,只是死记硬背,生怕跟不上老头儿的思路。
MySQL老头儿接着说道: “在标号为(2)的地方,小强做了修改,数据是这样的:”
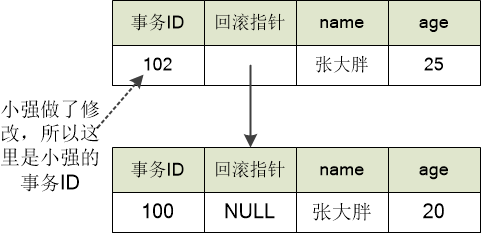
“看到回滚指针没有? 它指向了上一条记录。”
“怪不得叫做多版本并发控制,你这里维护了数据的多个版本啊。” 小强感慨道。
“按照可重复读的要求,我开始了一个事务,无论我读多少次,我总是能读到age=20的那行记录,即使小强修改了age,我也不受影响。你这个结构该怎么实现啊? ” 旺财问道。
“关键部分要到了,我这里有个算法,用来判断这些数据版本记录中哪些对你来说是可见的(可读的)。 ”
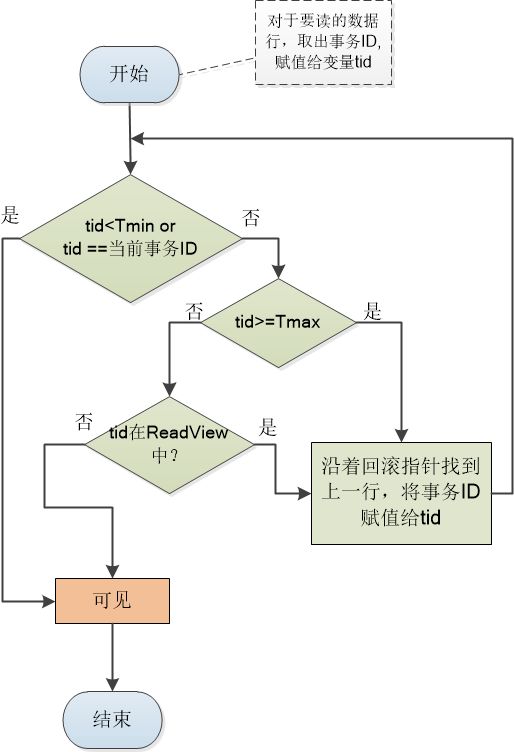
旺财只觉得觉得自己的头嗡地一下就大了:“这....怎么这么麻烦!”
MySQL老头说:“这还麻烦? 已经很简单的算法了,就是几个if else ,加上几个循环而已! 连这个都整不明白,别在我们数据库村混了! 对于上面的例子,ReadView 中事务列表是[101,102], Tmin= 101, Tmax = 103,你们想想,第一次读和第二次读是什么样子。”
只听到小强嘴里嘟囔着:“ 当旺财第一次读的时候,只有一条记录, tid = 100 ,小于Tmin,所以是可以读的。 然后我做了修改, 当旺财第二次读的时候,tid=102,程序走到了‘tid是否在Read View中这一分支,由于102确实在Read View的活动事务列表中,那就顺着回滚指针找到下一行记录,即tid为100那一行,再次判断,这就和第一次读一样了。”
MySQL老头儿得意地说:“对喽,这不就实现了可保证可重复读嘛! 旺财你想想,你在读数据的时候,需不需要加锁操作?”
旺财摇头:“不用加锁, 我只要找到正确的版本就可以了。 ”
(注: 但是在写数据的时候,MySQL还是要加锁的,防止写-写冲突)
“这就是MVCC的好处啊,读写不互相等待,能极大地提高数据库的并发能力啊。”
旺财还是有点不放心,觉得这种方式太复杂了,但是转念一想,读的时候不用加锁,这个诱惑实在太大, 他说:“这样吧,我和小强再合计合计。”
MySQL老头儿自信地说:“没问题,你们来再想想,有问题再找我吧。”
(注:本文讲解了可重复读的情况,对于Read Committed 这个可以适用同样的算法,只是每次读操作的时候,都要建立新的Read view,朋友们可自行分析下。)
(完)
码农翻身
用故事讲述技术





