全网第一SoTA成绩却朴实无华的PyTorch版EfficientDet
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文作者:Zylo117
https://zhuanlan.zhihu.com/p/129016081
本文已由原作者授权,不得擅自二次转载
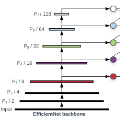
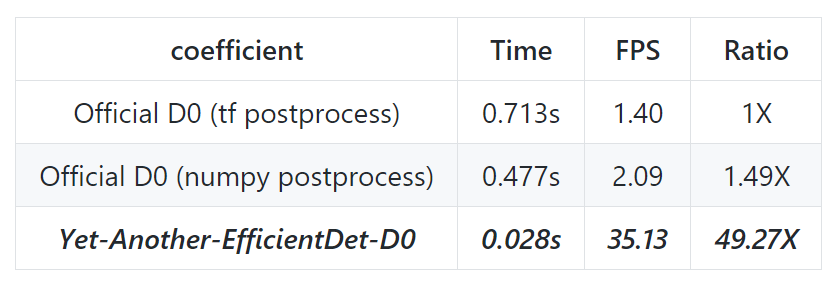
太长不看版:我,在清明假期,三天,实现了pytorch版的efficientdet D0到D7,迁移weights,稍微finetune了一下,是全网第一个跑出了接近论文的成绩的pytorch版,处理速度还比原版快。现在免费提供pretrained的weights。感兴趣的小伙伴可以去watch、star、fork三连我的repo。
https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch
先附上我的测试成绩:
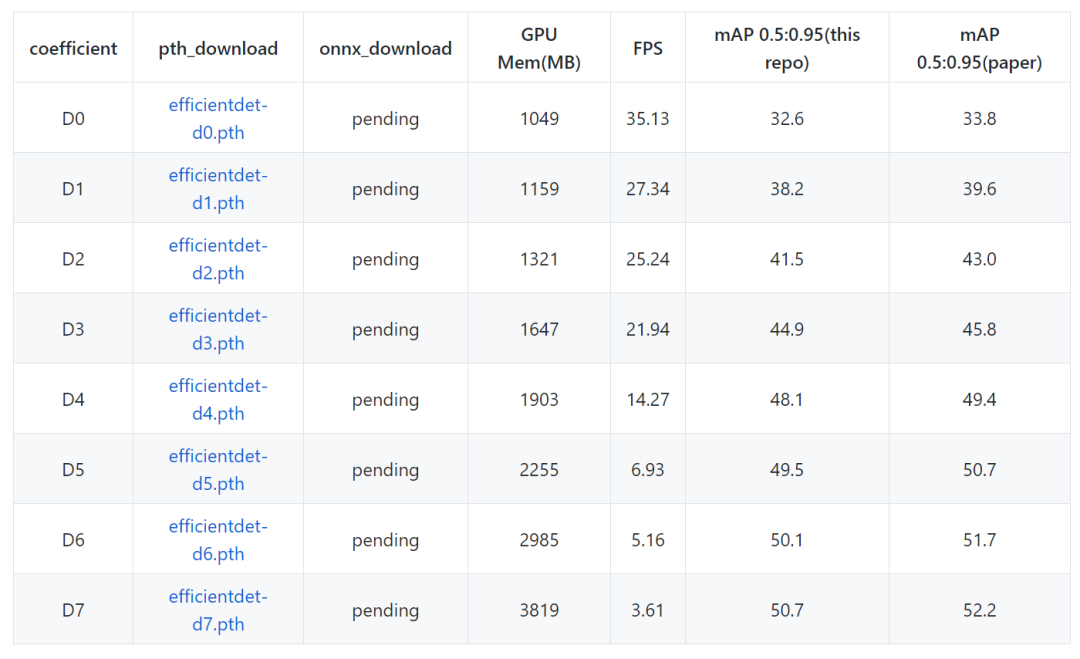
再附上速度测试:
看本文前,建议阅读EfficientDet原文,并理解其网络结构,链接在参考处。
看完本文,你会知道:
为什么之前都没有人复现efficientdet的成绩?
高star的efficientdet之间的差异?
那么多个民间efficientdet,我应该用哪个?
众所周知,图像分类任务最强的CNN是efficientnet[1],而屠榜目标检测的网络则是基于efficientdet[2]的。
大家不妨去paperwithcode看看排行榜,看看efficientdet是怎么屠榜的。
https://paperswithcode.com/sota/object-detection-on-coco-minival
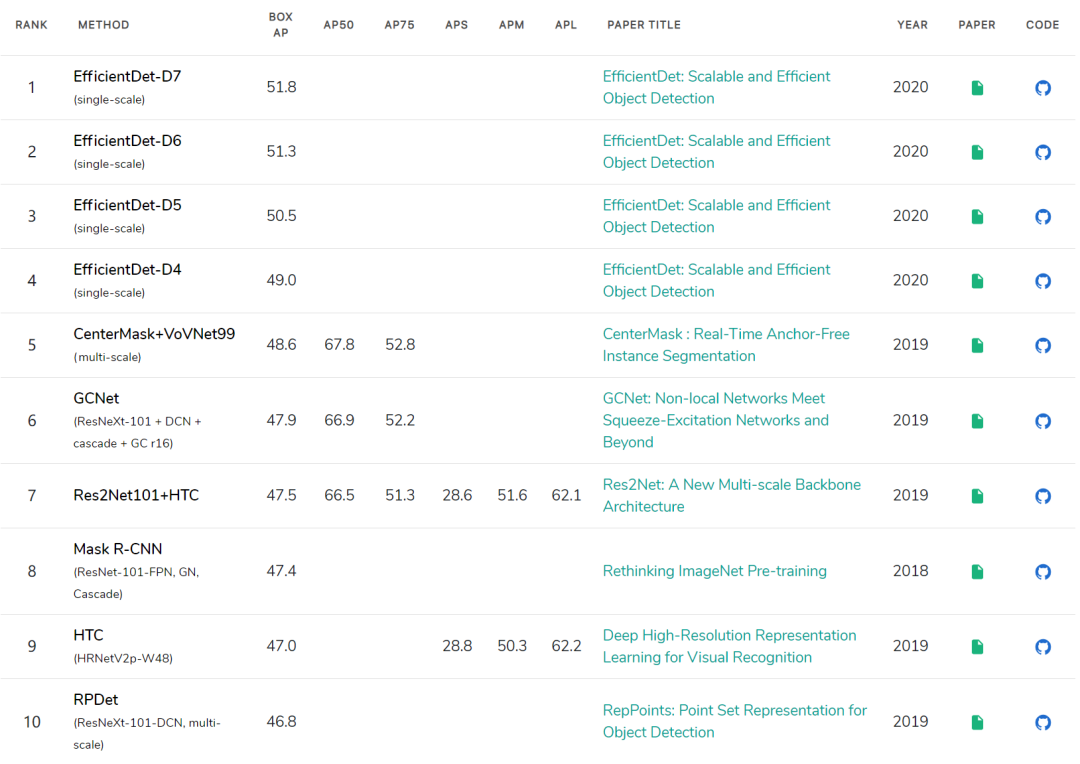
前五名里面包揽了四名,可以说是“垄断”了。
那大家就好奇了,那么SoTA的网络,哪里可以抄作业啊?哦不好意思说错了,哪里可以学习一下啊?
由于官方(谷歌)一直不发官方repository,所以民间就开始发力了,真的靠paper的内容实现了出来,真的佩服,很强。
今年1月,宅家为国出力,本着学习强国的想法,我也去学习了一个。根据本能,按照star的数量排序,找到了这个。
https://github.com/toandaominh1997/EfficientDet.Pytorch
拿下来第一时间跑demo,因为它没有提供coco下的pretrained,所以我只能from scratch train了鸭。结果几天过去了,怎么一点进度都没有,mAP卡在了15左右。我以为是我的知识水平不行,结果发现issue里面的都是这样的。
这是什么玩意?这也能有1k star?我当时还没有搞清楚efficientdet,我承认,不过后来自己实现了之后,发现这个repo有这样的问题。
因为efficientdet的特性之一是BiFPN,它会融合backbone输出的任意相邻两层的feature,但是由于有两层尺寸的宽高是不同的,所以会进行upsample或者pooling来保证它们宽高一致。而这个作者,他没有意识到,他不知道从backbone抽哪些feature出来,他觉得是backbone有问题,改了人家的stride,随便挑了几层,去强迫backbone输出他想要的尺寸。。。可以参考下面两个链接,一个是官方参数,一个是他魔改的参数,stride被错误地改了,s11改成了s22。
https://github.com/google/automl/blob/master/efficientdet/backbone/efficientnet_builder.py#L172
https://github.com/toandaominh1997/EfficientDet.Pytorch/blob/master/models/utils.py
问题来了,我们炼金术师都知道,改了网络结构,pretrained权值基本就废了,所以他也发现了,发现训练不下去了,怕丢人,就训练了个上古数据集VOC2007敷衍一下,拿个62的mAP,知道VOC2007才 62意味着什么吗?连YOLO v1都不如!要知道efficientdet-D0就是为了干掉YOLO v3去的啊!
https://paperswithcode.com/sota/object-detection-on-pascal-voc-2007
最搞笑的是,这个作者回答了几个问题后发现搞不定,现在已经你给路达哟了。
但是他的repo真的一无是处吗?也不是,他奠定了efficientdet的基础要素,后来的人每一个人的代码里面都能看到他的影子。
只不过说明了,不仅是他,社区中都没有人训练出论文的成绩。说明论文中的确有很多没有提及到的细节,所以大家容易误解。
好,我找了另一个efficientdet,这个。这个赞才不到前者一半。
怎么?现在的炼丹师都那么没有眼光的吗?
https://github.com/signatrix/efficientdet
剧透警告:这个repo也无法在其他骨架上复现论文成绩,但是起码人家在D0上面有论文的成绩啊!
没错,这个repo提供了coco的pretrained权值,31.4的mAP,已经很不错了。让我看到了可以白嫖的希望!
所以我冲了,马上clone下来跑,成绩果然不错,训练个D2出来看看!
1周过去了。。。
2周过去了。。。
3周过去了。。。
。。。
6周过去了。。。
7周过去了。。。
泷泽萝拉哒!!!!
没用没用没用没用没用没用没用没用没用
弃了弃了,不行,我努力了很久,只有24mAP,社区反馈好像也是差不多,20到22这样的。你要说为什么不行,那时候我也不知道。
但是现在可以告诉大家。高能预警。
1. 这个作者的BN实现有问题,BatchNorm是有一个参数,叫做momentum,用来调整新旧均值的比例,从而调整移动平均值的计算方式的。而问题来了,人家官方efficientdet用的tensorflow。。。tensorflow的momentum定义和pytorch不一样。。。没想到吧!!!这就是我的坑人方法啊!这个套路熟悉吗?而这个作者沿用了论文写到的0.997,所以在pytorch里面,就是等于说新的输入的mean、std的系数是0.997。。。整个移动参数,都被新输入给主导了,被破坏了,所以BN的表现非常糟糕。
momentumpytorch = 1 - momentum_tensorflowhttps://github.com/signatrix/efficientdet/blob/master/src/model.py#L20
2. Depthwise-Separatable Conv2D的错误实现。DSConv2D,解开来是DepthwiseConv2D+SeparatableConv2D+BiasAdd,而这个作者在Depthwise后面来了一个BiasAdd。
https://github.com/signatrix/efficientdet/blob/master/src/model.py#L18
3. 误解了maxpool2d的参数,kernel_size和stride,他应该是想缩小尺寸,所以设置的缩小为原来的两倍,本来应该设置stride的,他却是设置kernel为2,感受野会变得很奇怪。
https://github.com/signatrix/efficientdet/blob/master/src/model.py#L46
4. 在backbone输入feature的时候,上面也说了,BiFPN会融合多feature,所以feature之间要保证尺寸一致,不仅是宽高一致,通道数也有一致。而减少通道的卷积后面,他没有进行BN
5. 这个是最严重的问题了,和上一个人一样,他的backbone feature抽头抽错了,他抽的是stride为2的那一层,但是错了,应该抽stride为2的上一层的结果,以及backbone的最后一层。什么影响呢?原版是想把stride2卷积降维后的feature进行特征提取,然后作为输出。而这个版本的作者,则是把stride2卷积降维的当成结果直接输出了,还没有提取特征呢!所以特征提取能力上也会大打折扣。
6. Conv和pooling,没有用到same padding。你的下一句话就是!这个也有影响?对!当然有影响!
先不说前后尺寸差异的问题,只讨论两种paddin值上的差异。
我们来算一下,这些op的padding只会影响四边和角落,假设是128x128的feature map,用vaild padding,舍弃边缘和角落,那么影响的数据点为128*4-4,508个,对原map的信息丢失率为508/(128*128)≈ 3.1%。同样的方法,当你feature map只有6x6的时候,信息丢失率则是55.6%了。
所以我们可以看出来,same padding在小feature map上是必要的,否则将会丢失将近过半的信息!
7. 没有能正确理解BiFPN的流程
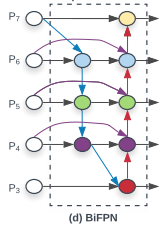
illustration of a minimal bifpn unit
P7_0 -------------------------> P7_2 -------->
|-------------| ↑
↓ |
P6_0 ---------> P6_1 ---------> P6_2 -------->
|-------------|--------------↑ ↑
↓ |
P5_0 ---------> P5_1 ---------> P5_2 -------->
|-------------|--------------↑ ↑
↓ |
P4_0 ---------> P4_1 ---------> P4_2 -------->
|-------------|--------------↑ ↑
|--------------↓ |
P3_0 -------------------------> P3_2 -------->如图,这个是BiFPN的最小单元,下图是我加上名称后的BiFPN。
要是我不说,大家都理所当然地认为P4_0,同时去了P4_1,又去了P4_2。
然而,鸡贼的官方,没有告诉大家,这个其实两个独立的P4_0。什么意思呢?应该是这样的。
P4_0_A,去了P4_1; P4_0_B去了P4_2。P4_0_A和 P4_0_B是独立的tensor。混在一起是错误的。
上述问题,在我的repo里面,我全部解决了,不然哪里敢这里和你们吹水。
好了,总结完了,这些就是他们主要存在的问题,你会问,就这?真的差那么一点也会有那么大的影响?当然!要知道,efficientnet也好,efficientdet也好,都是参数驱动型的网络,参数是贯穿每一层的。也就是说,你改了一个参数,整个网络都会完全变化。人家谷歌大佬没说参数是怎么来的,但我们都猜到是通过大量TPU搜索试错出来的,我们这种没钱没资源的,没有做过实验,不应该随便乱改的。
文章你也看完了,看在我浪费几个月生命的份上,麻烦各位炼丹同行多多点赞,去我repo三连一波,蟹蟹大家!
参考
^EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
https://arxiv.org/abs/1905.11946
^EfficientDet: Scalable and Efficient Object Detection
https://arxiv.org/abs/1911.09070
推荐阅读
这三篇论文开源了!何恺明等人的PointRend和谷歌大脑的EfficientDet
一骑绝尘的EfficientNet和EfficientDet
重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集3800人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!