Predicting the Future V2更新
Predicting the Future with Multi-scale Successor Representations
https://www.biorxiv.org/content/10.1101/449470v1.full
abs:
A discount or scale parameter determines how many steps into the future SR’s generalizations reach, enabling rapid value computation, subgoal discovery, and flexible decision-making in large trees.
SR can reconstruct both the sequence of expected future states and estimate distance to goal. This derivative can be computed linearly: we show that a multi-scale SR ensemble is the Laplace transform of future states, and the inverse of this Laplace transform is a biologically plausible linear estimation of the derivative. Multi-scale SR and its derivative could lead to a common principle for how the medial temporal lobe supports both map-based and vector-based navigation.
1
It has been shown that the successor representation (SR) offers a candidate principle for generalization in reinforcement learning (Dayan, 1993; Momennejad, Russek, et al., 2017; Russek, Momennejad, Botvinick, Gershman, & Daw, 2017) and computational accounts of episodic memory and temporal context (Gershman, Moore, Todd, Norman, & Sederberg, 2012), with implications for neural representations in the medial temporal lobe (Stachenfeld, Botvinick, & Gershman, 2017) and the midbrain dopamine system (Gardner, Schoenbaum, & Gershman, 2018).
In contrast, SR offers a more computationally efficient solution to the RL problem by storing generalizations (temporal abstractions) of multi-step relationships between states (Dayan, 1993; Gershman, 2018).

SR is as flexible as MB when the rewards change in the environment (reward revaluation) but less flexible when the map of the environment changes (transition revaluation), predicting behaviorally asymmetric flexibility.
Recent experiments have compared these models to human behavior and shown that the asymmetry in human behavior is more consistent with the predictions of SR agents that update their models via replay (SR-Dyna) (Momennejad, Russek, et al., 2017).
It has also been shown that SR offers a computational account of optimal behavior in a variety of RL problems such as policy revaluation and detour (Russek et al., 2017) and explains how context repetition enhances memory-driven predictions in human behavior (Smith, Hasinski, & Sederberg, 2013).
SR has also been proposed as a principle for neural organization for place cells and grid cells in the hippocampus and the entorhinal cortex, playing a crucial role in rodent navigation (Stachenfeld et al., 2017).
Stachenfeld and colleagues reviewed the literature for the hippocampal-entorhinal encoding of spatial maps during navigation, and modeled the evidence using the successor representation.
They concluded that SR is a candidate organizational principles governing the neural firing of place cells and grid cells for learning spatial maps guiding navigation.
Since the eigenvectors for the transition matrix and the SR are the same, they suggested that grid cells in the medial entorhinal cortex may provide an eigendecomposition of the graph of the states.
Furthermore, human neuroimaging implicates SR in neural representations underlying event segmentation in the statistical learning of non-spatial relational structures (Schapiro, Rogers, Cordova, Turk-Browne, & Botvinick, 2013).
Computational models show that SR can partition the state space, enabling sub-goal processing in large decision trees (Botvinick & Weinstein, 2014). Finally, a recent human fMRI study showed that SR govern the implicit encoding and later retrieval of non-spatial relational knowledge (Garvert, Dolan, & Behrens, 2017).
Taken together, these computational, behavioral, neuroimaging, and electrophysiological evidence in humans and rodents suggest the successor representation as a candidate principle underlying the organization of hippocampal and entorhinal firing in spatial navigation and non-spatial relational learning.
The purpose of our paper is to clarify limitations of existing SR models and propose a solution. Briefly, the limitations are that estimating sequential order and distance between states from an SR with a single discount is nontrivial. Intuitively, for every row of the n×n SR matrix, information about the sequential order and distance between states is lost. SR generalizes over successor states and this temporal abstraction relies on a weighted sum of future states. The weights of successor states exponentially decay the further they are in the future, depending on a discount parameter γ.
Our proposed theoretical framework overcomes this limitation by assuming that the brain stores an ensemble of SRs at multiple discounts, and by estimating the derivative of multi-scale SRs.

根据不同的目的,距离的远近是不一样的,比如不同的目的跑步比赛 5秒 50米就不近,如果是去旅游,5km也不远。
The simple intuition behind our proposed solution is as follows. Consider an ensemble of ng

This is a powerful intuition since absent multiple SRs or the derivative, computing distance and order in the bistro example from a single SR requires computing the one-step transition matrix from a given state to all other states using the entire matrix, which is nontrivial.

In short, the derivative of multiple SR matrices can identify at which scales the relationship between two given states change. If we know at which horizon the relationship between every two states i and j changes, it is possible to identify the distance between two states (see Figure 1). In this paper we show that linear operations on an ensemble of multi-scale SRs can estimate their derivatives. Using the derivative, we can reconstruct the sequence of expected future states following a given starting state, and recover order and distance between states, merely by computing a vector as opposed to entire matrices.
In the remainder of the manuscript we offer a more detailed account of our proposal, and show qualitative fit between model predictions and recent neural findings. We conclude with a discussion of the proposal, its neural plausibility, and its possible implications for a unifying account of map-based and vector-based representations using SR.
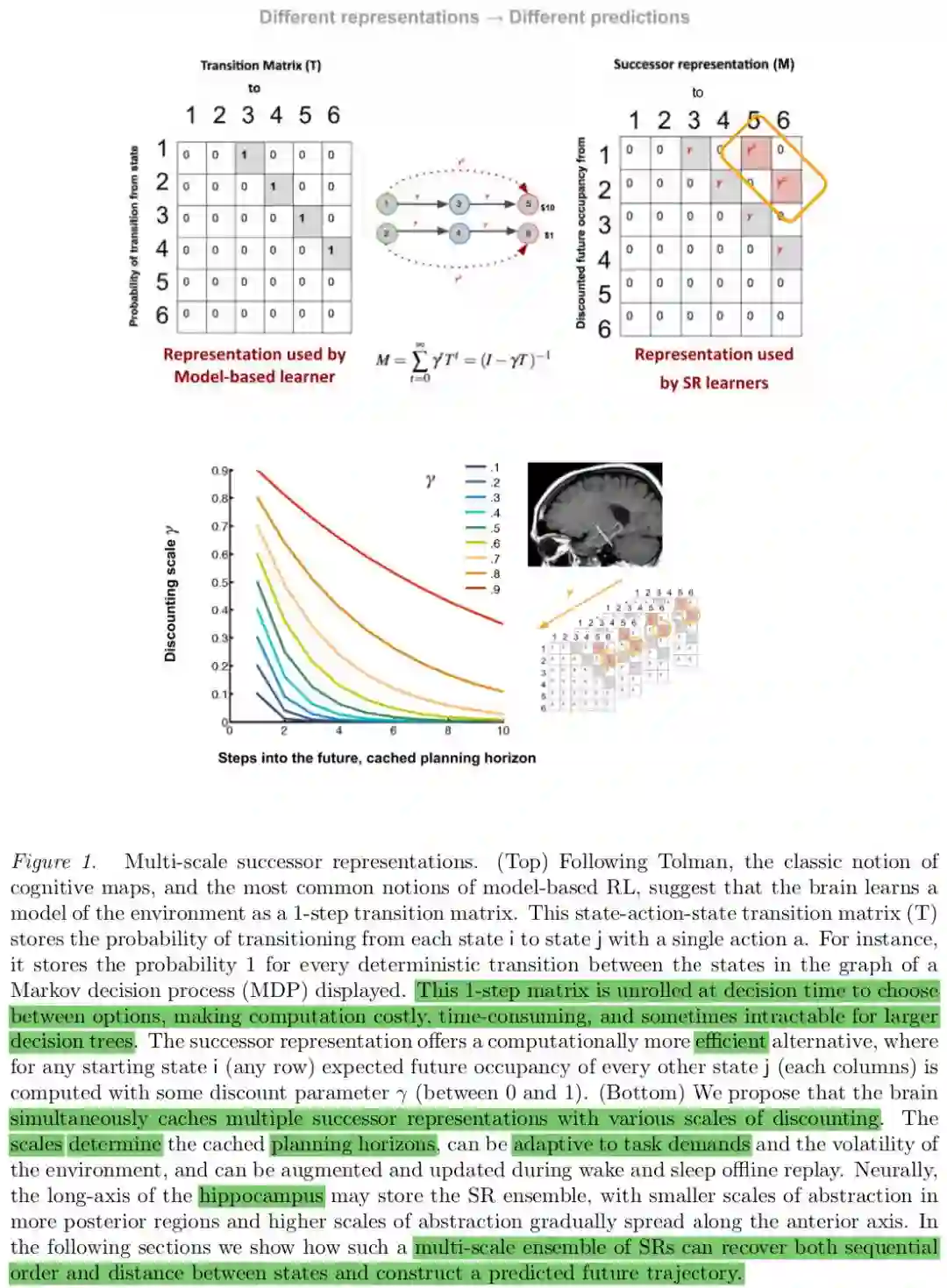

We first demonstrate that an ensemble of successor representations with different discount rates is the Laplace transform of a timeline of future states. We will then show that a simple inverse of the Laplace transform identifies the derivative of multiple SRs, indicating where the relationships between states change. We show that this operation recovers the sequential order of states and predicts cells that fire at specific distance to goal states, as shown in recent animal and human literature (Sarel, Finkelstein, Las, & Ulanovsky, 2017a; Qasim et al., 2018). We will then discuss the significance of this model for learning and navigation, evidenced by the qualitative match between the model’s predictions and recent findings across species.
The successor representation, described above, provides an exponentially-weighted estimate of future occupancy in going from one state i to state j. That is, when the agent is in its current location in state i, the representation of its successor states are co-activated. The extent of this co-activation depends on the distance: successor states that are nearby are co-activated to a larger extent than those further away, leading to a exponentially-weighted representation of successor states. However,

This makes it in principle possible that different policies lead to the SR matrix at different time-scales, since the agent may be caching SRs while taking different policies at different scales. This feature may enable multi-scale SR to dynamically select different policy based on changing temporal horizons. In other words, caching a multi-scale ensemble of SRs enables selecting policies with a flexible temporal horizon, which would be more adaptive to task demands compared to a condition where a single predictive horizon was used regardless of the planning horizon required by the task. We return to this point in the discussion.
根据时间抽象的粒度进行计划 planning;天 小时?飞机还是步行?

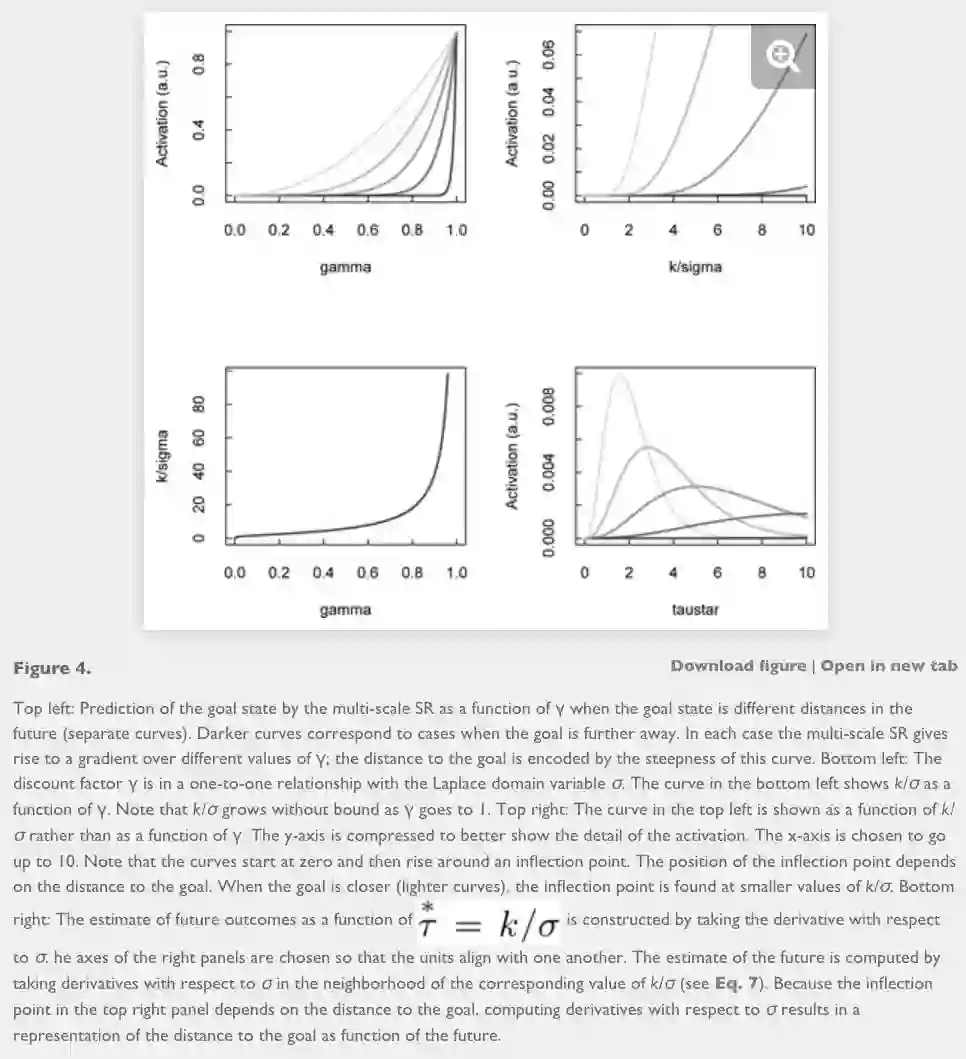
The Laplace transform has powerful properties, enabling extraction of important information using simple linear operations, such as inversion. The Laplace transform can be inverted with a linear operator
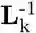
that has been extensively studied in computational cognitive neural models of memory (Shankar & Howard, 2012, 2013; Liu, Tiganj, Hasselmo, & Howard, in press). Importantly, inverting the transform is the equivalent of computing a derivative of the relation between two given states i and j across different SR matrices, i.e., across different time-scales. Intuitively, knowing at which scales the relationship between two states change, indicated by the derivative, enables us to estimate their distance from each other. In short, the multi-scale SR ensemble and its derivative are equivalent, respectively, to the Laplace transform of expected sequential future states and its inversion. Thus, we arrive with cached representation that can also recover the order and distance in estimated future trajectories. To see how this intuition is possible in more detail, we start with a formal description of the successor representation.

The insight that M(σ) is the real Laplace transform of ˆfi is very powerful. The Laplace transform is invertible; if we could invert the Laplace transform we could explicitly estimate the expected sequential trajectory of future states (Figure 2). The real part of the Laplace transform, which is given by Eq. 6 is sufficient to uniquely specify functions defined over the interval from 0 to ∞. Recall that this sequence of future states was formalized in the future-trajectory function above (see Eq. 4). This means that inverting the Laplace transform could recover an estimate of the function over future events itself.
Inverting the Laplace transform in a neurally-plausible way
Put another way, Eq. 6 says that the timeline over the sequence of future states
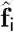
is distributed across different values of σ. Our strategy is to invert the transform, recovering this information about the function, and write the answer onto a set of neurons that estimate the future-trajectory function directly. Different neurons in this representation would then estimate the states that are expected to occur at different points in the future. Therefore, if we find a neurally plausible way to invert the Laplace transform, then we will have a powerful tool for recovering a function of future states from a multi-scale but static stack of cached predictive representations.
Inverting the Laplace transform in a neurally-plausible way
Put another way, Eq. 6 says that the timeline over the sequence of future states ˆfi is distributed across different values of σ. Our strategy is to invert the transform, recovering this information about the function, and write the answer onto a set of neurons that estimate the future-trajectory function directly. Different neurons in this representation would then estimate the states that are expected to occur at different points in the future. Therefore, if we find a neurally plausible way to invert the Laplace transform, then we will have a powerful tool for recovering a function of future states from a multi-scale but static stack of cached predictive representations.
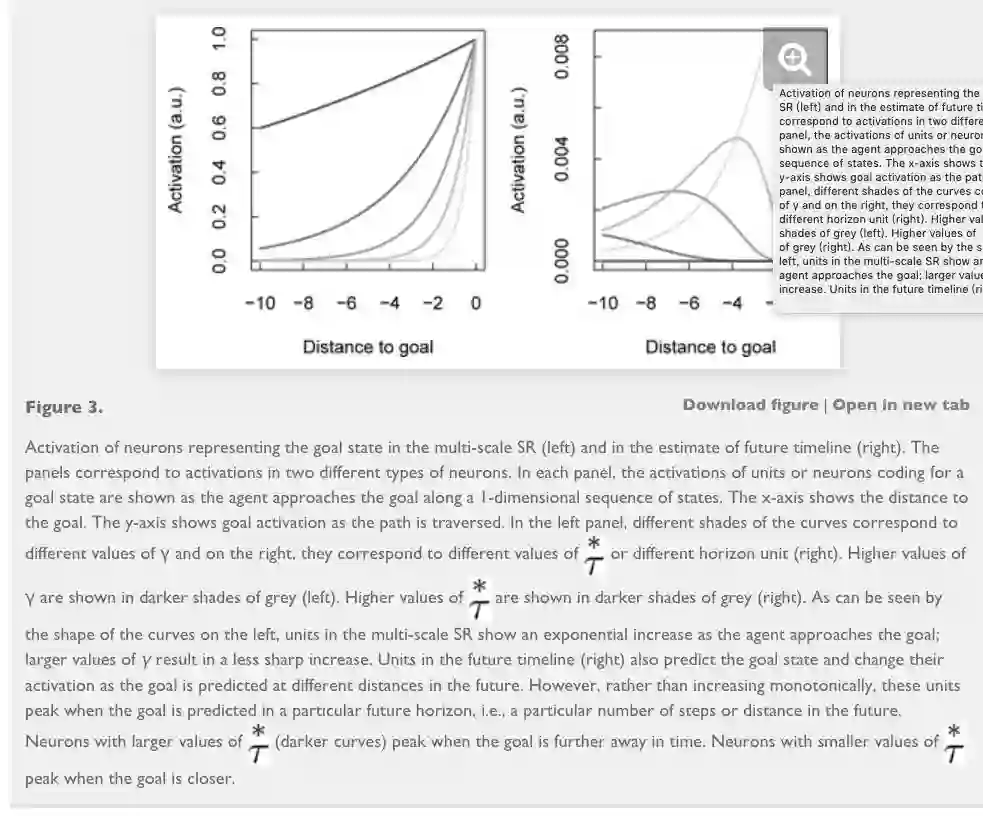
The curvature of this functio over values of γ encodes information about when the outcome is expected to occur.
The inflection point where this happens depends on how far in the future the goal state is predicted.
these units are maximally activated when the goal state is expected
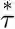
units in the future. With many values of
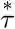
, the pattern of
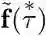
over different values provides a veridical but coarse-grained estimate of when the goal state will be observed in the future subject to the policy that generated the multi-scale SR.
Predictive maps and distance to goal firing patterns
Multi-scale successor representations can be thought of as a set of predictive maps, each with a different scale or predictive horizon.
computing the inverse (or the derivative) of the multi-scale SR ensemble resembles firing patterns at specific distances to any given destination state. This predicts sequential activations of different units/cells as a function of distance to the goal
(this ‘goal’ could be a goal object, a reward state, a frequently visited location or destination, a specific boundary, a subgoal, a remembered location, etc.).
Whereas the successor representation itself gives monotonically decreasing gradients into the future (like border cells), the inverse of a multi-scale SR ensemble predicts cells that are sequentially activated as a function of distance to goal (these can be thought of as distance-to-goal cells).

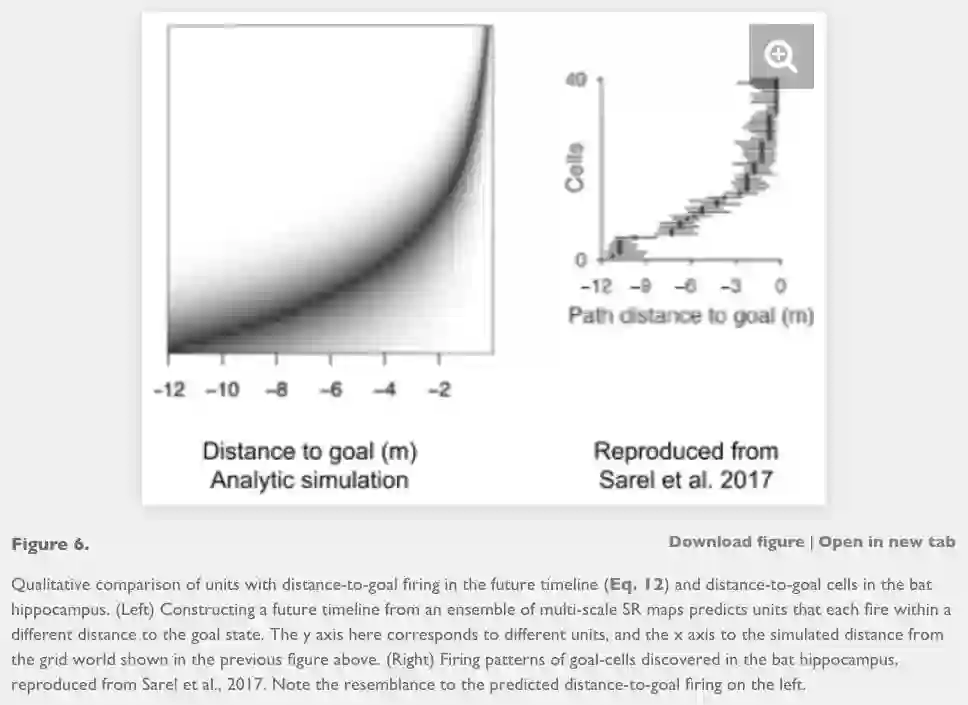
Our multi-scale successor representation framework could potentially offer a unified principle that supports both the map-like representations elicited by place cells, asymmetric firing skewed towards the goal location (Stachenfeld et al., 2017), and the vectorial representation of direction and distance to goal (Kubie & Fenton, 2009; Bush, Barry, Manson, & Burgess, 2015). The predictions of this proposal are in line with the observation of distance to goal cells (Fig. 6).
Discussion
The successor representation (SR) offers a principle for abstract organization in reinforcement learning (Dayan, 1993; Momennejad, Russek, et al., 2017; Russek et al., 2017), computational accounts of episodic memory and temporal context (Gershman et al., 2012), and predictive representations in place cells and grid cells in the hippocampus and medial entorhinal cortex (Stachenfeld et al., 2017). The successor representation (SR) offers a solution to planning at large temporal horizons and optimal sub-goal discovery (Botvinick & Weinstein, 2014). Combined with offline replay, a model known as SR-Dyna is superior to classic model-free and model-based reinforcement learning mechanisms in explaining human behavior (Momennejad, Russek, et al., 2017), outperforming hybrid MF-MB models and varieties of earlier Dyna models across other problems as well (Russek et al., 2017). Neurally, it can also explain asymmetric firing toward the goal state in hippocampal place cells (Stachenfeld et al., 2017). However, on its own, a single row of SR discards fine grained information about order and distance of a starting state to expected future states. This information is important to animals in many real-world decision making problems, and call for an adequate account in any computational proposal.
Here we have shown that a multi-scale ensemble of successor representations can overcome these limitations: the derivative of the SR ensemble can estimate the expected sequence of future states following a starting state, recovering both sequential order and distance between states. Importantly, this derivative marks changes in the relationship between two given states across the timescales of abstraction.
Neural plausibility: Evidence from place cells, grid cells, and time cells

原文:
https://www.biorxiv.org/content/10.1101/449470v1.full
欢迎加入打卡群自律学习强化学习,更欢迎支持或加入我们!请参考公众号createAmind菜单说明。



