竞赛 | 从全球千余支队伍中脱颖而出,BDC冠军团队是如何做用户预测的

历时近3个月,2018 年中国高校计算机大赛——大数据挑战赛(下称「大数据挑战赛」)落下帷幕。最终,厦门大学的lambda团队夺取冠军获得 30 万元奖金。
根据决赛10支队伍的答辩内容,我们梳理整理了冠军、亚军两支团队的答辩成果及评委点评。
以下,enjoy!
全球千余团队参与,专注活跃用户预测
本次大赛由快手和清华大学联合承办,基于快手提供的脱敏和采样后的数据信息,预测快手平台上未来一段时间的活跃用户。快手同时提供给选手安装了多种机器学习平台的云服务器,供选手研究机器学习算法。
参赛队伍需要设计相应的算法进行数据分析和处理,比赛结果按照指定的评价指标使用在线评测数据进行评测和排名,得分最优者获胜。决赛中10支队伍答辩后,最终成绩综合复赛B榜成绩和现场评委打分两部分生成。
本次大赛面向全球高校在校生开放,并鼓励高校教师参与指导,共有来自全球 10 个国家及地区,439 所高校,1392 支队伍,2751 位选手,15803 次提交参与评审。经过层层筛选激烈竞争,现场 10 支队伍进入决赛环节。
10 支队伍来自清华大学、北京邮电大学、哈尔滨工业大学、厦门大学、武汉大学、同济大学、西北大学、福州大学、东南大学、重庆邮电大学、山东大学、西安电子科大、杭州电子科大。
参赛队伍解题思路及算法亮点干货分享
冠军队伍——lambda思路自述
团队介绍:Lambda团队由厦门大学的一名同学组成,颜晶。值得一提的是,颜晶本专业为金融专业,现读研二,自学机器学习半年时间。
解题思路 :
本题是基于30天内用户使用快手app的相关行为(特别强调:数据为采集和脱敏后),预测未来7天内用户是否活跃的概率,评价指标为AUC。
首先本题没有标签,因此需要自己进行标注标签。首先想到的是根据题目要求,用7天进行自己标注,但是7天噪音大,因此可以尝试使用更少的时间进行标注,比如6天、5天等。最后结果表明用6天进行标注能得到更好的结果。有了训练集和标签就可以选择模型:一种是将时间序列进行面板化,使用传统机器学习(LGB or XGBoost);第二种是使用RNN(many-to-many)。
算法亮点:
此次比赛主要使用了RNN模型。RNN分为三类:many-to-one、one-to-many、many-to-many。我们选择了many-to-many,这相当于对数据一天一天进行滑窗,可以对数据集进行扩充。
首先我对用户按注册进行分类,在通过采样策略,将数据集输入到GRU里面去:
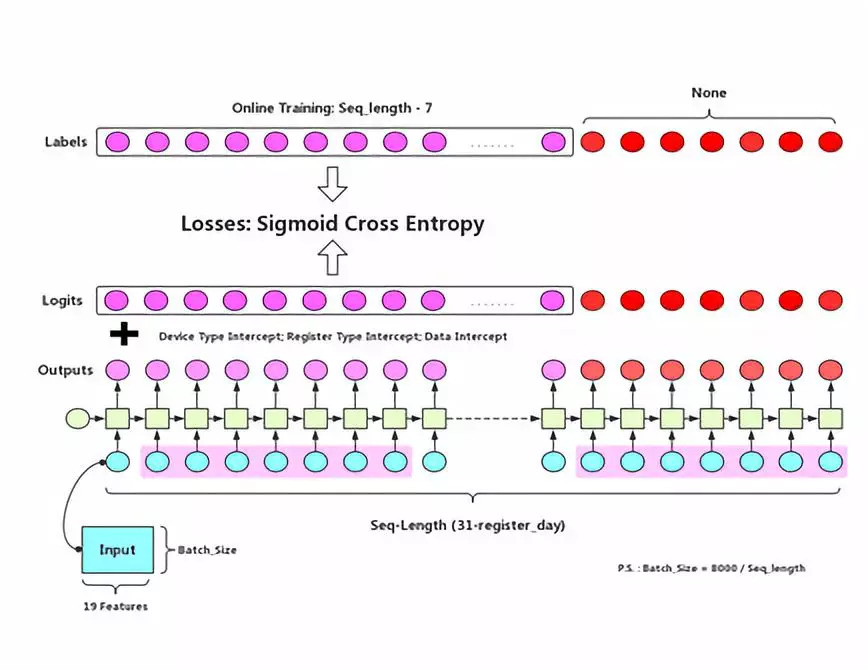
此外我们对数据集进行padding,这样可以在训练集中随机选择用户输入到的GRU中,其中也对注册早的用户赋予更高的概率,这样保证模型能够得到更多的信息。
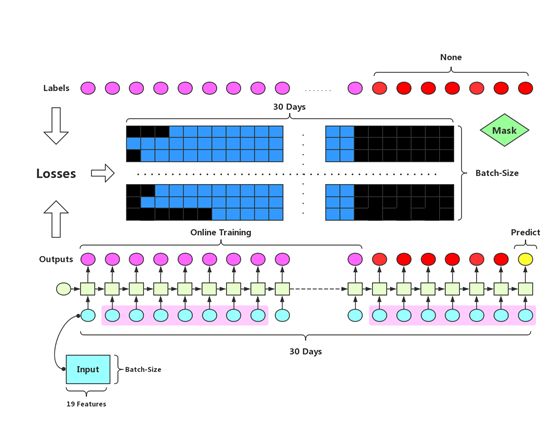
在优化时,使用了快速集合集成fast geometric ensembling(FGE),这样可以无成本的获得到多个差异性模型,能得到更好的结果。
评委点评:
与其他参赛队伍使用复杂的特征工程+多模型融合方案不同,lambda 队仅用十几个原始特征+RNN单模型就拿到了最好的成绩。RNN模型的难点在于调参和学习方法的调整,选手调研了多种优化方法,如余弦退火、warmrestarts、快照集成和快速几何集成,最终使得模型稳定收敛。选手的方案再一次证明了神经网络可以从原始数据中自动发现规律,可以节省大量的特征工程工作。同时模型复杂度较低,可以部署到线上生产环境。
比赛感想:
将近3个月的比赛从中,我收获很多。首先是可以多尝试些方案,虽然各大比赛中冠军基本是LGB or XGBoost,NN一直作为融合补充所用,这可能只是那么数据集更适合LGB模型。其实在比赛开始时,我们并不是一开始就选择了RNN模型,也走了很多弯路。在初赛中,由于数据量较小,RNN模型的成绩在B榜排在200名以后。复赛数据集扩大后,RNN有了很好的效果,才一直不断的优化RNN,算是踩对了坑。
此外,在比赛中找到一致的线上与线下是非常重要的,这样不仅能保证得到的模型是稳定的,且能更有效利用提交次数。
最后,在国内大数据比赛中,夺冠的有以下几种情形:对数据理解透彻、很多模型融合、模型创新等。虽然模型创新很难,但是当你将模型构建起来时,也预示着,别人是很难追上你了。
亚军队伍——小小蚂蚁队思路自述
团队介绍:小小蚂蚁队由两位同学组成,分别来自西北大学的曾凯,计算机应用技术专业,研一在读,和福州大学的冉宪东,大三在读,电子信息工程专业。
解题思路 :
1、滑动窗口
题目是给定1-30天时间内的四个日志数据(特别强调,数据为采集和脱敏后),通过这些数据来预测未来一段时间(即31-37天)活跃(即出现在以上四个日志中任意一个)的用户。经过分析,判定该问题是一个典型的二分类问题,也就是说给定一个用户id,让我们来预测这个用户是活跃或者不活跃。那么首先考虑如何构造出线上线下的训练集以及它的标签,还有线上线下测试集以及它的标签。

图(一)
如图一所示,我们采用滑动窗口的算法思想,给定a到b,也就是1-30天区间,我们定义n和m,其中n是构造训练集或验证集的区间,紧接着的后7天是构造标签的区间。其中,n小于等于23,m大于等于0。这样满足这种条件的我们可以滑动出很多个窗口,理论上讲这样我们训练集的样本可以构造出很多个,但是经过仔细分析与思考,我们总结了窗口必须满足以下两个条件:
保持线上与线下窗口间隔一致。
满足数据分布的周期性。
我们看第一点,假如我们以构造训练集越多越好的原则去构造,那么变长窗口当然是1-2,1-3,1-4,一直到1-23,但是这样会出现一个问题,也就是线上和线下的窗口间隔不一致,这样会导致线上和线下构造的特征数据分布不一致,很容易出现过拟合现象。因此我们从后往前推,使得线上线下得窗口间隔一致,还是以构造训练集最多原则构造窗口,那么这样构造就是1-30,1-23,1-16,1-9,1-2(为什么间隔是7呢,因为这7天是用来构造label的,也就是线上和线下最小的间隔)。

图(二)
第二个原则,我们是根据图二得出的规律,也就是窗口还需要满足数据分布的周期性,可以看出,每个窗口每天的行为次数都是周期性的增长,除了1-2这个窗口之外。因此1-2这个窗口就被去掉了,并且1-2这个数据窗口太小,信息量太小,显然也就舍去了。
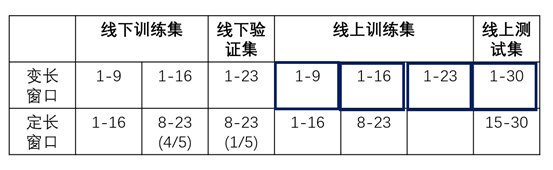
同样的道理,所以最终我们构造出了两个可行的窗口,如表一所示,第一个是变长窗口,线下训练集是1-9,1-16,线下验证集是1-23。线上训练集是1-9,1-16,1-23,线上测试集就是1-30。另一个是定长窗口,线下训练集是1-16,8-23(4/5),验证集是8-23(1/5),线上训练集是1-16,8-23,线上测试集是15-30。
后来我们最终确定的窗口为变长窗口,主要有三个原因:
第一,这样我们可以预测全范围的用户,也就是注册表里所有的用户,而定长窗口不能。
第二,这样有利于线下验证集的构造,因为数据分布基本一致,保持线上线下一致,而相比定长窗口的切分窗口数据好。
第三,变长窗口构造的训练集相比较定长窗口多
2、用户分类
构造好了数据集的划分,我们再进一步对数据进行探索,因为是对用户进行是否活跃预测,那么我们研究的对象主体是用户,于是,我们就通过日志数据对用户类型进行分析。
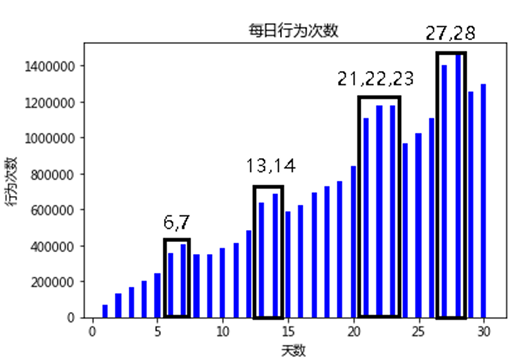
图(三)
如图三所示,我们发现每天的行为次数从第一天开始每隔五天就会有两天突增,我们猜测这两天应该是周末,说明有个用户群在周末这两天比较活跃,而在周内相对活跃次数较少。这部分用户也许是上班族等,他们得生活规律有周期性。21,22,23这三天也比较多我们猜测是节假日三天。
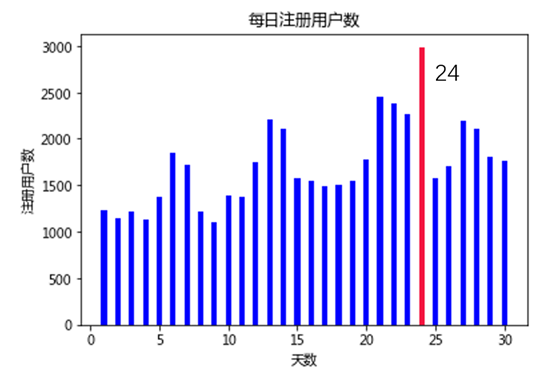
从图四我们可以看出,每天的注册人数也是符合图一的规律,但是到了第24天,注册量出奇的高。于是我们单独拿出这一天注册日志的数据,分析发现,这些注册用户的设备类型和注册类型一模一样,于是我们就画出了如图五这样的图。
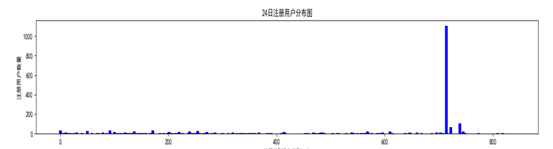
图(五)
横轴是注册类型和设备类型组合,纵轴是注册用户数量,发现确实有几种组合类型的注册数量很高,我们把这类用户定义为异常用户,这类用户有以下两个个特点:
注册类型和设备类型一样,并且是一天之内注册数量相对正常注册量出奇的高(设定阈值γ,只要这种异常用户注册量大于γ就符合)。
这些用户在随后的天数之内都没有活跃,只在当天活跃
我们推测这类用户是因为快手的某种活动引流进来的用户,并且这类用户是那种类似于黄牛的机器用户,最终我们根据这种规则找出了每天的异常用户。掌握了这些用户群的特点之后,这样更有利于我们进一步的特征构造与模型构建。
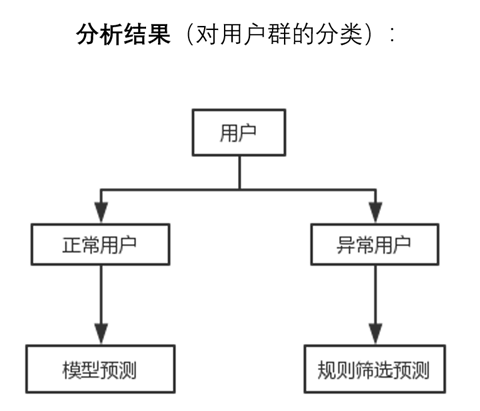
图(六)
于是根据上面数据的进一步探索,我们把用户分为两大类,如图六所示,第一类是正常用户,我们可以用模型去预测活跃的概率。第二类是异常用户,我们可以通过规则去筛选预测,也就是符合异常规则的用户我们把预测概率置为0。
总结起来,这样对用户划分主要有两大好处,第一就是使得预测异常用户更加准确。第二就是剔除之后,减少训练集噪声,增加正常用户模型预测准确率。
3、特征构造
现在我们数据集划分确定了,用户也基本分析清楚了,就开始根据变长窗口的特点以及用户群的特性构造特征。特征构造方面我们主要从‘时间’ 和‘空间’维度的层面构造。
时间维度基本侧重的是单个日志来提取的有关的时序特征,概括性的分类如图七所示。
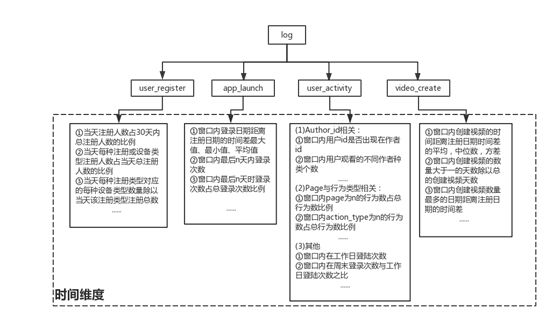
图(七)
空间维度就是题目中给的四类日志,它们从不同方面也就是不同的维度反映着用户的不同特征,比如用户的活动日志,从这方面提取的大部分特征是有关用户活动方面的特征,因此我们利用空间维度与维度之间的差异主要来构造出交叉特征。如图八所示
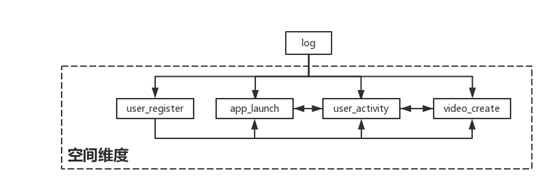
图(八)

4、模型构建

图(九)
模型方面,主要对两个单模型进行单独训练,然后对其预测结果进行加权融合。由于Lightgbm模型和神经网络模型差异性大,一个是boosting的集成思想,一个是采用神经元激活的思想的,因此我们对其两个模型预测的结果进行加权融合,提升的效果会好。
算法亮点:
TF-IDF特征的构造:
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
这样我们把一个authorid比作一个字词,根据authorid在日志中出现的次数从大到小排列,取前n个作为语料库。这样与userid交互的有多个authorid,就能计算出对应的tf-idf值,我们取前m个,不够的补0,多的省去,这样就构成了m维特征。
这个特征就相当于对每一个用户在窗口内进行了编码,表征着这个用户与authorid的亲密程度,用于区分特定的用户群体。例如,一个人气高的作者一般是经常活跃的,用户与该作者交互次数越多,此用户对应该作者的tf-idf的值也越大,那么该用户活跃的概率也越大。
比赛感想:
此次比赛提供的数据为快手app真实数据的脱敏采集后的数据,更结合实际业务,使得我们更应该结合用户使用快手app的实际场景,从而对用户的特性有更深的了解以及用户群有更深更细的划分,使得特征的构造更加合理与有效。同时,在比赛过程中,竞争比较激烈,但是一定要坚持下去,不到最后一刻决不放弃,一定不能只停留在想象方面,有想法一定要及时去实现,也许那个点子就是提分的关键。
评委点评:
小小蚂蚁队在充分理解业务场景、对数据进行细致的分析后,用丰富的特征来表达业务场景。在构建训练集的过程中,对比了多种滑动窗口方案。针对业务场景中出现的异常噪音,能够细致分析并妥当处理。选手使用的模型为 gbdt 模型, 在实际业务场景中,易于增加特征做扩展,可以持续迭代优化。
大赛点评
评委对此次大赛点评:
参赛选手在历时 100 多天的比赛中,遵守比赛相关规定,公平竞赛。本届赛题提供给选手的是经过采样和脱敏后的真实行为数据,在赛题设计上并不限制选手使用分类模型求解。选手在问题转化的过程中,方法各有不同,在训练集构造、标签构建、特征抽取等环节均有创新。冠军队 lambda 使用 RNN 模型,从原始数据中学习规律,该方法具有通用性和实用性。
第三届BDC评委介绍:
此次大赛共有七位评审,其中四位是高校老师,三位是快手的技术专家。分别是,教育部高等学校教学指导委员会委员,大赛专家委员会副主任臧斌宇教授。北京大学教授、大数据挑战赛专家委员会委员王腾蛟教授。哈工大教授、大数据挑战赛专家委员会委员王宏志老师。代表清华主办方的清华软件学院党委副书记王朝坤老师。快手的技术专家李森栋、王哲、林涛。
快手科技技术专家李森栋,曾先后工作于社区科学部、海外事业部,参与推荐系统的迭代开发以及推荐模型的研究和实现工作。在本次大赛中,担任竞赛专家委员会委员,负责大赛的赛题、数据和评测等工作。
王哲快手科技技术专家,在快手社区科学部负责推送和新产品的推荐系统和算法策略。
林涛快手科技技术专家,在快手社区科学部负责推荐系统架构,主要包括搭建机器学习平台、开发线上高性能的一些模型触发、预估模块等工作。
【今日机器学习概念】
Have a Great Definition








