是时候怼一波AutoML了

然而,近期的一篇文章却认为:AutoML 似乎有些炒作过度。该文章的作者更是对此进行了一番实验:他的方案在几乎所有测试场景下都获得了高于 AutoML 的分数。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)

我在自己的日常工作中使用过 AutoML,参加过几次 ML 竞赛,外加两次 AutoML 技术比赛。我觉得 AutoML 提出的建模流程自动化概念非常重要,但多少还是有点吹过头的感觉。虽然特征工程以及用于超参数优化的元学习等关键概念值得肯定,而且拥有可观的潜力,但就目前来讲,购买打包出售的 AutoML 工具基本上就是在浪费金钱。
以下所有内容都以数据为基础。
一切数据科学项目都涉及几个基本步骤:从业务角度提出问题(选择任务与成功指标)、收集数据(收集、清洁、探索)、建立模型并评估性能、在生产场景中部署模型并观察模型的实际表现。
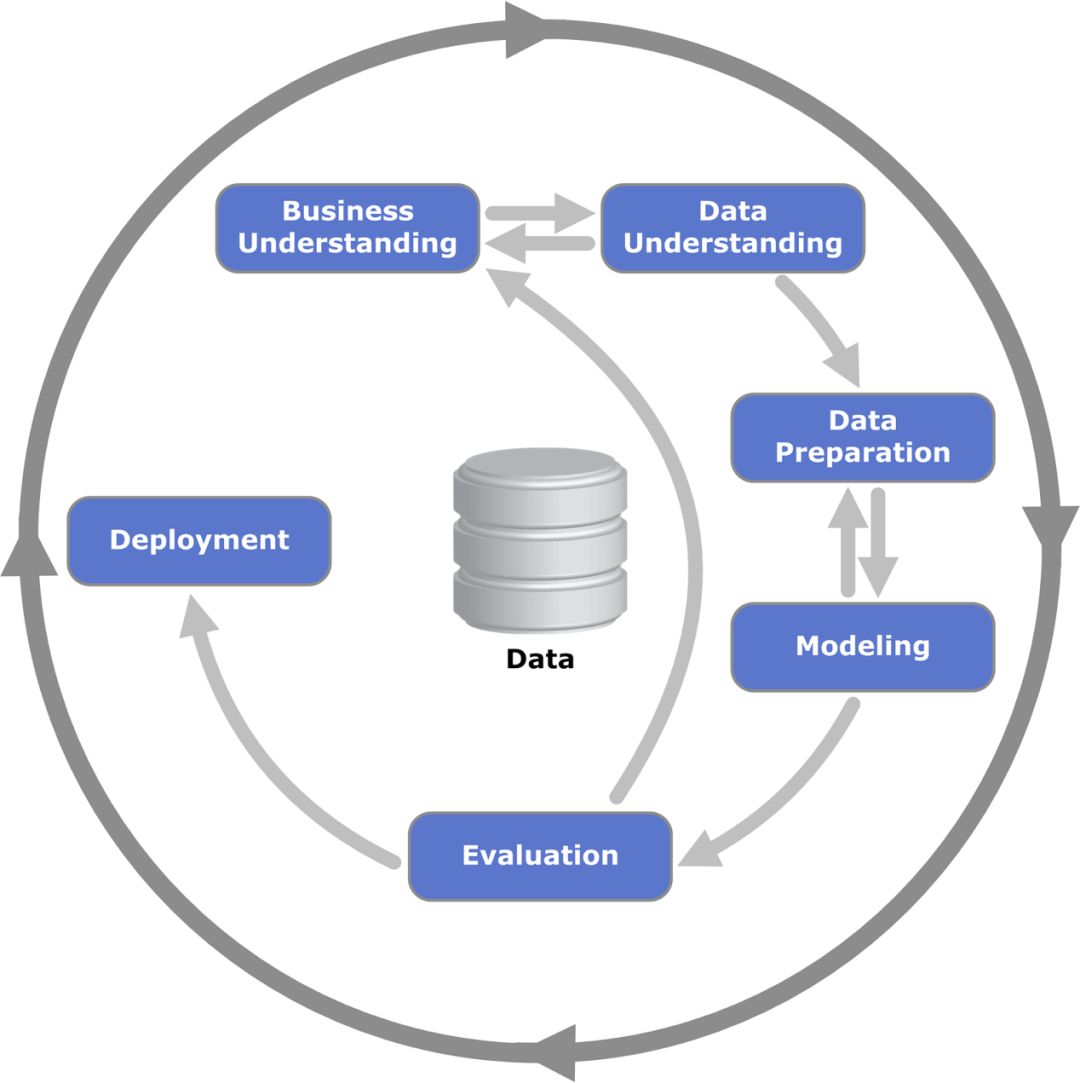
跨行业数据挖掘标准流程
流程中的各个部分对项目的成功都至关重要。但是,从成熟的机器学习角度来看,建模部分无疑最为关键。只有完善的 ML 模型,才能为企业创造更多价值。
在建模阶段,数据科学家们需要解决优化问题:利用一套给定的数据集识别并最大化所选指标。这个过程非常复杂,需要以下几种不同类型的技能:
特征工程,有时更像是种艺术而非科学;
超参数优化,要求我们对算法以及 ML 核心概念拥有深入的理解;
软件工程技能,用于确保输出的代码易于理解及部署。
AutoML 的意义,正在于帮助我们完成以上工作。

ML 建模类似于艺术、科学加上软件工程的综合体
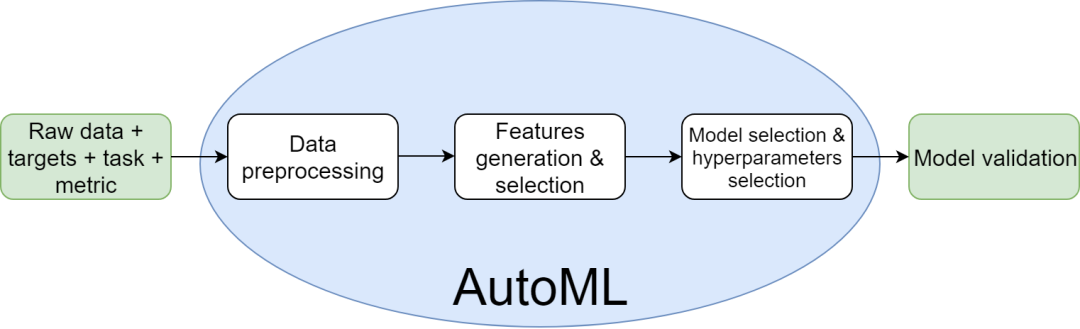
AutoML 的输入内容包括数据与任务(分类、回归、建议等),输出结果则为生产就绪模型。这类模型能够预测到原本并不存在的数据。数据驱动流水线中的每个决策环节都是一项超参数。AutoML 的基本思路,就是找到这样的超参数,确保其取值能够在合理的时间内给出得分良好的决策结果。
AutoML 选择一种数据预处理策略,包括:如何处理不平衡数据;如何填补缺失值;删除、替换或保留异常值;如何编码类别与多类别列;如何避免目标泄漏;如何防止内存错误等等;
AutoML 生成新的特征并从中选择有意义的条目;
AutoML 负责选择模型(线性模型、K 最近邻、梯度增强以及神经网络等);
AutoML 对所选模型的超参数进行调优(例如基于树状结构的模型或架构的树数与子分支采样、神经网络的学习率与轮数等);
AutoML 实现模型的稳定集成,并尽可能提高得分。
如今,越来越多的企业开始收集数据,或者希望利用已经收集到的数据实现业务潜能:即从中获取实际价值。但在另一方面,市场上拥有良好技术背景的数据科学家非常有限,因此供求之间就出现了缺口。AutoML 希望填补这部分缺口。
然而,打包出售的解决方案真能给企业带来任何价值吗?我个人答案是否定的。
这些企业需要的是完整流程,但 AutoML 只是一款工具。工具再先进,也无法弥补战略层面的不足。 在开始使用 AutoML 之前,请首先与咨询企业开展项目合作,从而帮助我们预先建立起数据科学策略。大多数 AutoML 解决方案供应商都在提供咨询服务,这绝不是巧合,而是切实存在的市场需求。
这个主意好像不怎么样,对吧?(来自《南方公园》第 2 季第 17 集)
根据《2018 年 Kaggle 机器学习与数据科技调查》报告,典型的数据科学项目会将 15% 到 26% 的时间投入到模型的选择或者构建当中。无论是“人工工时”还是计算时间,这都代表着一种巨大的消耗。如果目标或数据发生变更(例如需要添加新特征),则整个流程还得再来一遍。AutoML 能够帮助公司内的数据科学家们节约时间,并把宝贵的精力投入到更重要的工作当中(比如坐着发呆……)。
利用 AutoML,我们只需要几行代码就能让整个体系运转起来
然而,既然数据科学团队的核心工作内容就不是建模,那么企业的流程显然已经存在问题。一般来讲,即使是模型性能的小幅提升,也足以为企业带来可观的经济回报。在这种情况下,投入建模的时间越长,那么回报应该就越高:
规则过度简化:如果从模型获取的收益>数据科学团队的时间成本,则不需要节约时间。
如果从模型获取的收益<= 数据科学团队的时间成本,那么是不是当初选择的就不是正确的业务问题?🤔
在这方面,最好的办法是为数据科学团队的日常任务编写脚本以节约时间,而不是使用现成的打包解决方案。我就曾为日常任务编写过几套脚本,包括自动特征生成、特征选择、模型训练以及超参数调优等等,而且直到现在仍在经常使用。
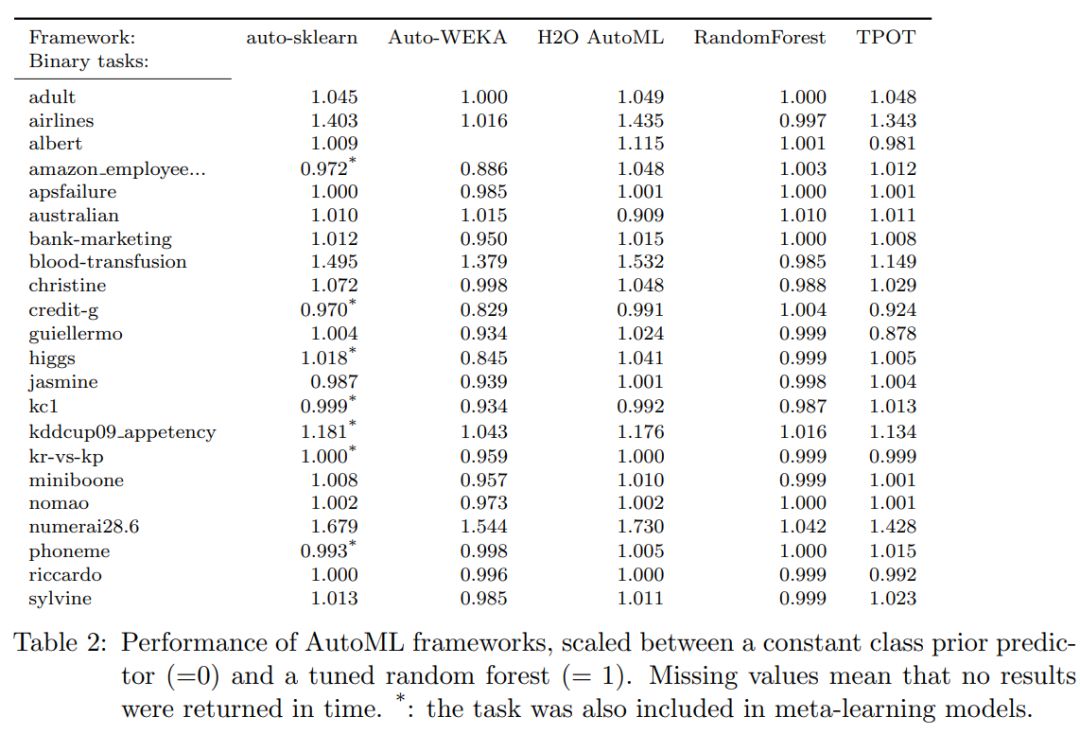
遗憾的是,除了“开源 AutoML 基准”之外,我们并没有“Tabular AutoML 对人类基准”可供参考。论文作者将多套 AutoML 库的性能与调整后的随机森林性能进行了比较,结果发布于 2019 年 7 月 1 日。
我很好奇,并决定亲自做做基准测试。我利用二进制分类的三套数据集对自己的性能与 AutoML 解决方案进行了比较,具体包括 credit、KDD Upselling 以及 mortgages 数据集。我将原始数据集拆分为训练数据集(按目标分层随机分配了 60% 的数据量)以及测试数据集(剩余 40% 数据)。
我的基准解决方案相对简单,在这里没有对数据进行任何深入研究,也没有建立任何高级特征:
5-StratifiedKFold;
用于分类的 Catboost Encoder;
用于数字列对的数学运算符(+-*/)。新特征数量被限定为 500;
模型:LightGBM,使用默认参数;
混合 OOF 排名预测。
我为 AutoML 使用了两套标准库,分别为 H2O 与 TPOT。我以多种时间间隔对其进行训练:最低 15 分钟,最高 6 个小时。通过以下指标,我得出了令人惊讶的结果:
得分 =(曲线下面积 / 基准曲线下面积)*100%
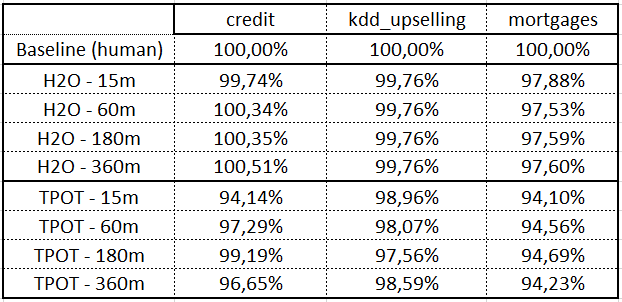
首先,我的方案在几乎所有场景下都获得了高于 AutoML 的分数。我有点难过,因为我原本打算在工作里用 AutoML 偷偷懒的,没想到它这么不中用。😒
其次,AutoML 的得分并没有随着时间的推移而提高,这意味着我们无论等待多久都没有意义:它在 15 分钟与 6 小时场景下的得分一样,都很低。
AutoML 压根就得不到高分。
如果你的企业第一次使用数据科学,请考虑雇用一名顾问。
你应该尽可能提升工作的自动化水平……
.……但现成解决方案得分相对较低,似乎不是什么理想的选择。
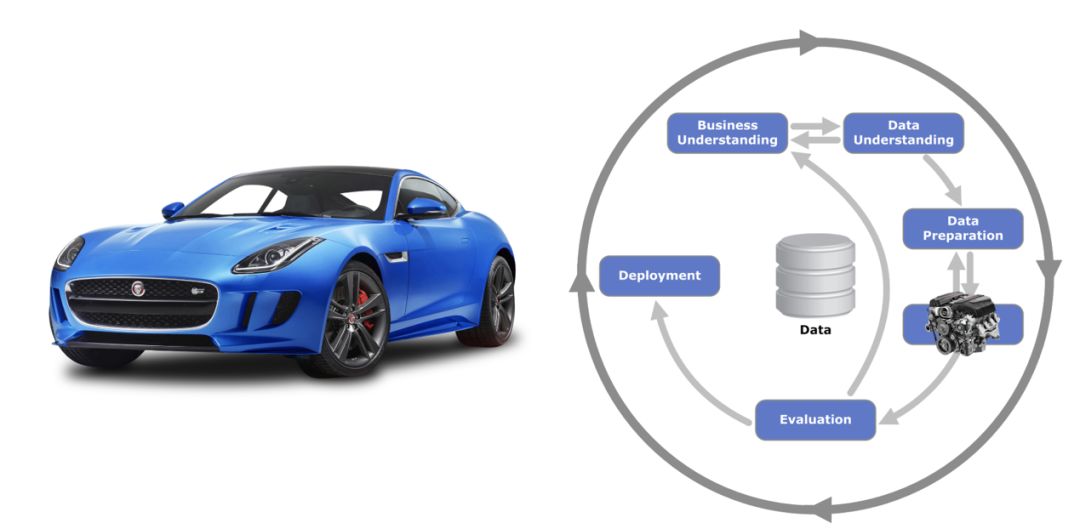
在本文中,我讨论的是工具,但请记住,建模部分只是整个数据科学流水线中的一小部分。我经常把项目比喻成一辆汽车,建模部分(机器学习模型)的输出就像是一台引擎。
引擎确实非常重要,但仍然跟汽车是两个概念。我们需要投入大量时间来设计出精妙、完善且复杂的特征,选择神经网络的架构或调整随机森林参数,从而构建起强大的引擎。但是,如果没有兼顾到汽车的其他部分,那么这一切可能只是在浪费时间。
了要解决的问题(对业务理解不深)或者模型过于复杂,就必须进行重新训练(数据探索)或者发现模型无法应用于实际生产(部署阶段)。
最后,大家可能会发现自己面临着进退两难的境地:经过数天甚至数周的艰苦建模之后,拿出的只是一辆拥有强大引擎的自行车。
工具非常重要,但策略至关重要。

原文链接:
https://towardsdatascience.com/automl-is-overhyped-1b5511ded65f
有意思的趋势是 ,AI的崛起正改变着公司间竞争的基础。传统的互联网公司加上一些机器学习或神经网络,这是不等同于AI公司。如何及时踏入人工智能这艘大船?ArchSummit全球架构师峰会(北京站)2019大会中,独家设置“提升效率的AIOps”、“机器学习与业务提升”等专题,帮你预定船票~
8折购票倒计时,限时立减1760元,团购更便宜哦~了解详情请联系票务经理灰灰:15600537884 ,微信同号。

今日荐文
点击下方图片即可阅读

Uber正式开源Go语言编程规范,内部已使用多年

你也「在看」吗?👇

