学界 | 强化学习+树搜索:一种新型程序合成方法
选自arXiv
作者:Riley Simmons-Edler、Anders Miltner、Sebastian Seung
机器之心编译
参与:Panda
程序合成一直都是计算机科学领域内一大重要研究方向。近日,普林斯顿大学的研究者提出了一种结合强化学习与树搜索实现程序合成的方法,为程序合成开启了一个新研究方向。这项研究目前仍在继续进行,机器之心对该研究的预印本论文进行了摘要编译。
在编程语言和机器学习领域,程序合成方面的研究都已经出现了复兴,该任务要做的是根据用户提供的规格(specification)自动生成计算机代码。由于计算能力的增长和深度神经网络的兴起,这个曾经无力解决的问题现在已经可以攻克了,并且也已经在很多领域得到了使用 [1],其中包括通过自动执行例程任务来提高程序员的效率 [2]、为没有编程知识的非专家人员提供直观的界面 [3]、为性能很关键的代码减少漏洞和提升运行效率 [4]。
在编程语言(PL)领域,程序合成通常使用枚举搜索来解决——通过简单直接地枚举候选项直到找到满足条件的程序来寻找满足给定规格的合适程序 [5,6,7]。通过将演绎组件集成进搜索过程来收窄搜索空间 [8,9,10],或通过将相关语言修改成具有更窄搜索空间的同等语言并在该空间中搜索 [11,12,13],这种方法可以得到解决。另一种常用方法是将合成任务约简成通过 SAT 求解器寻找一个满足条件的布尔公式配置 [14,15],但这只是将枚举搜索放进了求解器进行处理。
机器学习(ML)领域的研究者则在从另一个方向解决这个问题——不是单纯地全面搜索一个有限定的空间,而是使用一个学习了规格到程序的映射方式的模型,通过智能地搜索或采样搜索空间,从而在更大的搜索空间中有效地找到正确的程序。这些方法大都使用了监督学习方法——在一个大型的输入/输出样本和对应满足规格的程序的合成数据集上训练,然后给定一个相应的输入/输出示例集合 [16,17,18,19,20],使用基于循环神经网络(RNN)的模型依次输出目标程序的每一行。从概念上看,这种方法应该能与编程语言技术很好地结合起来——在小型搜索空间中进行智能搜索比在大型搜索空间中进行智能搜索要容易得多。那么,为什么这些技术通常没有一起使用呢?
机器学习领域内的大部分已有工作都严重依赖于被合成的领域特定语言(DSL)的结构来实现优良的表现,而且也不能轻松地泛化到新语言上。这些方法通常需要语言特征,比如语言的全可微分性 [19,20] 或规格和满足规格的程序对构成的大型训练集 [16,17,18]。这些要求使其难以将已有的基于机器学习的方法与编程语言社区开发的技术结合起来,它们在使用一种 DSL 进行有效合成时所需要的性质差异非常大。此外,大多数已有方法都主要注重以「一步式」的方式求解出程序,要么通过单次或少数几次尝试成功输出满足给定规格的程序,要么就无法得到这样的结果;随着程序空间变大,这种方法的扩展能力会变得更糟。相比之下,当基于搜索的方法枚举所有程序时,它们最终能解决任何合成任务,但所需的时间可能会超出可行范围。
强化学习引导的树搜索
我们的方法是强化学习引导的树搜索(RLGTS:reinforcement learning guided tree search),如图 1 所示。该方法旨在将基于搜索的方法和基于机器学习的方法的优势结合起来,并且让来自这两个研究领域的技术结合起来进一步提升效果。我们提出了一种程序合成新方法:将合成程序的过程表示成一个马尔可夫决策过程(MDP)[21] 并使用强化学习(RL)来学习求解程序,仅需给定该程序的一组输入/输出示例、一个语言规格和一个用于衡量给定程序的质量的奖励函数。在我们的基于强化学习的方法中,我们将程序状态和当前的部分程序看作是环境,并将该语言的代码行看作是寻求实现奖励函数最大化的动作。更进一步,我们还将我们的强化学习模型与一种基于树的搜索技术结合到了一起,这能极大提升该方法的表现。这种组合有助于解决很多强化学习应用中都会出现的局部极小值和高效采样的问题。
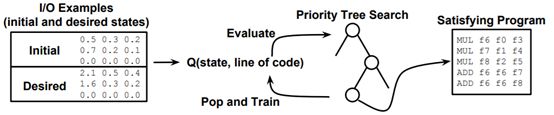
图 1:我们提出的系统的示意图。我们的程序合成方法将该问题看作是一个可用强化学习解决的马尔可夫决策过程,并且将其与一种优先搜索树组合起来通过避免局部极小值来加速求解过程,这能提升在固定数量的尝试次数内求解的程序的数量。给定一个输入记忆状态和对应的输出记忆状态集合,这种方法能使用一个为部分正确的解定义的奖励函数来引导学习过程,从而学习到一个策略——该策略能输出可将每个输入样本映射到对应的输出样本的代码行序列。
RLGTS 不依赖给定语言的训练数据的可用性,并且不对语言的结构做任何假设——只要求该语言允许执行和评估不完整的部分程序。此外,我们的基于强化学习的方法可以轻松且自然地与其它程序合成方法结合起来,这让用户可以受益于某些领域在基于搜索的合成上的大量研究成果。
总体而言,我们有以下贡献:
我们引入了强化学习引导的树搜索(RLGTS),这是一种将程序生成作为强化学习任务处理的程序合成方法。
我们描述了 RLGTS 在 RISC-V 汇编语言的一个子集上的实现,并且通过结合一个基于 Q 网络的策略与简单的树搜索方法为该任务创建了一个强化学习智能体。
研究表明,在随机程序构成的一个合成数据集上,相比于仅使用强化学习和仅使用枚举搜索的基准方法,我们的方法可求解的程序的比例分别提升了 100% 和 800%。此外,我们还比较了 RLGTS 与基于马尔可夫链蒙特卡洛(MCMC)的方法(该方法已经在 x86 代码的超优化上取得了很大的成功,并且也是合成汇编语言代码的当前最佳方法 [4]),结果表明我们的方法在更有难度的基准程序上有更优越的表现,在固定的程序评估限制内可求解的程序多出 400%;即使当该限制在 MCMC 看来增大了 50 倍时,我们的方法依然能在总体表现上保持竞争力。
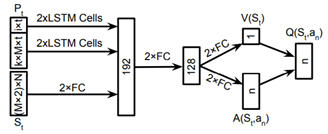
图 2:我们的 Q 函数神经网络的示意图
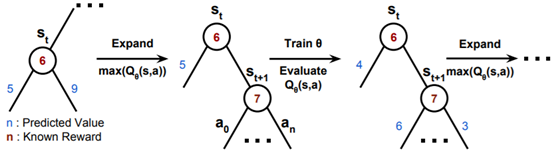
图 3:我们的 Q 函数与优先搜索树组合方法的示意图
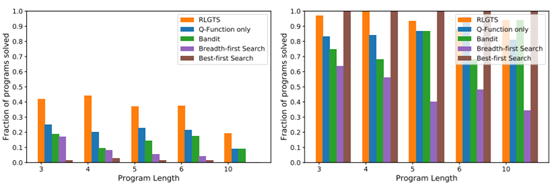
图 5:RLGTS 与基准方法的表现比较,左图展示了求解出的非凸程序的比例,右图展示了求解出的凸程序的比例。尽管 RLGTS 能有效求解凸程序,但它们也可以通过最佳优先搜索(Best-First Search)轻松解决,因此我们将它们从我们的其它实验中移除了,因为它们不能很好地代表该方法的表现。对于长度最多到 6 的程序,最大程序长度为 6;对于长度为 10 的程序,最大程序长度为 10。
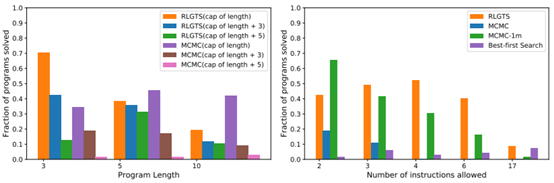
图 6:RLGTS 和 MCMC 作为程序长度函数(左图)和允许的指令数(右图)的表现比较。随着程序长度和搜索上限之间的差异的增大,RLGTS 一直都有更好的表现。让人惊讶的是,随着程序长度的增大,MCMC 的表现仅略有甚至没有下降。随着搜索的指令数的增大,MCMC 样本效率下降得快得多。MCMC-1m 给出了当 MCMC 的超时时间增加到 100 万次尝试时的表现,其它情况都使用了 20000 次尝试的限制。
论文:Program Synthesis Through Reinforcement Learning Guided Tree Search

论文地址:https://arxiv.org/abs/1806.02932
摘要:程序合成是根据提供的规格生成程序的任务。传统上该任务被编程语言(PL)社区看作是一个搜索问题,近期则被机器学习(ML)社区视为一个监督学习问题。我们在这里提出另一种方法,将合成给定程序的任务当作是可通过强化学习(RL)解决的马尔可夫决策过程。根据对部分程序的状态的观察,我们试图找到一个程序,且该程序在程序和状态对上依据所提供的一个奖励度量是最优的。我们在操作浮点数的 RISC-V 汇编语言的一个子集上实例化了该方法;并且受编程语言社区使用基于搜索的技术来进行优化的启发,我们将强化学习与一种优先搜索树组合到了一起。我们评估了这个实例,并且表明了我们的组合方法相比于各种基准方法的有效性,其中包括仅保留强化学习的方法和一种在该任务上当前最佳的马尔可夫链蒙特卡罗搜索方法。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com





