BERT小学生级上手教程,从原理到上手全有图示,还能直接在线运行
作者 Jay Alammar
伊瓢 编译
量子位 出品 | 公众号 QbitAI
BERT,作为自然语言处理领域的C位选手,总是NLPer们逃不过的一环。

但是,如果是经验匮乏、基础薄弱的选手,想玩转BERT还是有点难的。
现在,科技博主Jay Alammar创作了一篇《第一次使用BERT的图形化指南》,用非常简单清晰的方式介绍了如何上手BERT,从BERT的原理到实际操作的过程都有图示,甚至图比代码都多。量子位为大家编译搬运如下~

这篇文章主要以用BERT的变体对句子进行分类为例,介绍了BERT的使用方式。
最后的传送门处还有Colab的地址。
数据集:SST2
首先,我们需要用到SST2数据集,里面的句子来自于一些电影评论。
如果评论者对电影表示肯定赞赏,就会有“1”的标签;
如果评论者不喜欢这个电影,发表了负面评论,就会有“0”的标签。
数据集里的电影评论是用英文写的,大概长这样:
句子情感分类模型
现在,借助SST2影评数据集,我们需要创建一个自动对英文句子进行分类的模型。
如果判断是肯定的、正面的,就标注1;如果判断是否定的、负面的,就标注0。
大致的逻辑是这样的:

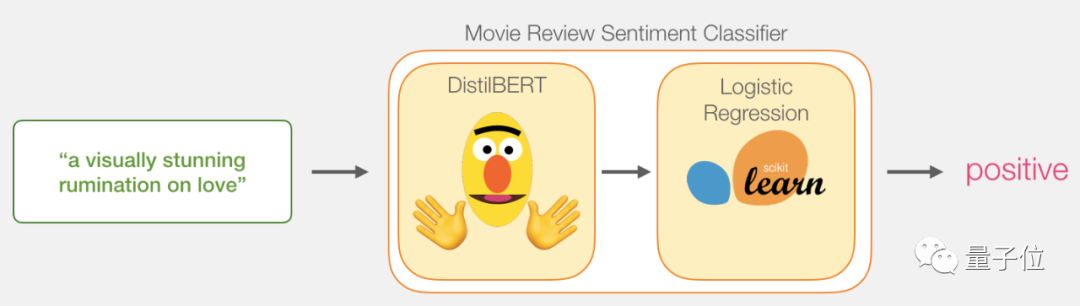
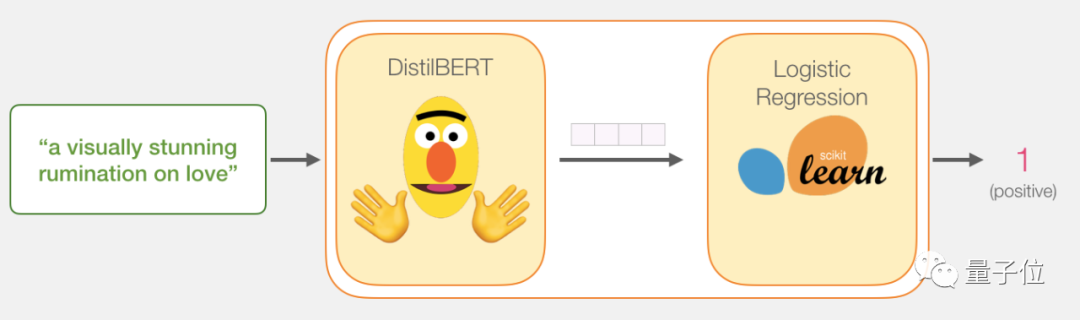
输入一句话,经过电影评论句子分类器,输出积极或消极的结果。
这个模型实际上是两个模型组成的。
DistilBERT负责处理句子,提取信息,然后传递给下一个模型,这是🤗“抱抱脸公司”(HuggingFace)做的一个开源BERT版本,比较轻量级而且运行快,性能和原版差不多。
下一个模型就是一个基本的逻辑回归模型,它的输入是DistilBERT的处理结果,输出积极或消极的结果。
我们在两个模型之间传递的数据是大小为768的向量,可以把这个向量当成可以用来分类的句子嵌入。
模型的训练过程
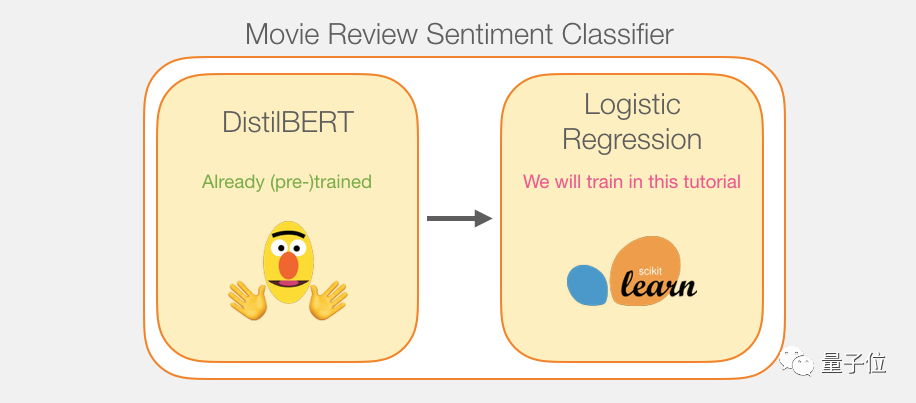
虽然我们会用到两个模型,但是我们只需要训练逻辑回归模型就行了,DistilBERT可以直接用预训练好的版本。
不过,这个模型从来都没有针对句子分类任务被训练或微调过,我们从通用目标BERT获取一些句子分类能力,尤其是对于第一个位置的BERT输出而言(与[CLS]token相关),这是BERT的第二个训练目标,接下来就是句子分类了,这个目标似乎是训练模型将全句意义封装到第一位置的输出位置。
这个Transformer库为我们提供了DistilBERT的实施和模型的预训练版本。
教程概述
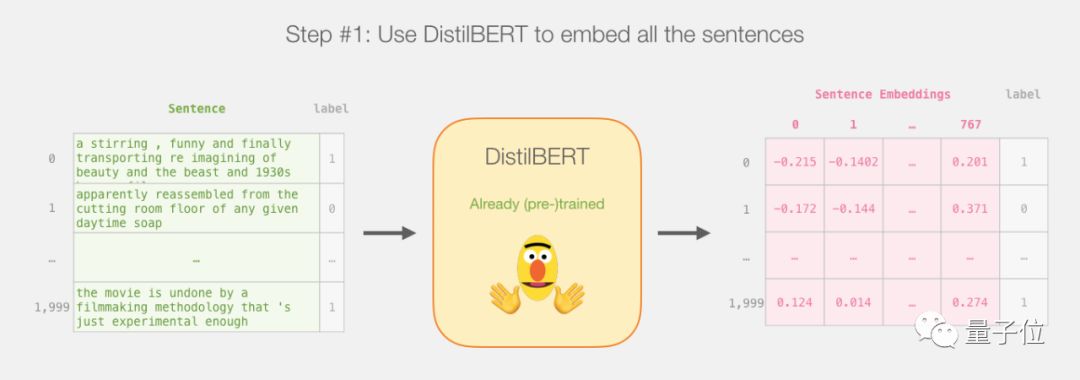
这是本篇教程的整个计划,我们先用训练过的DistilBERT来生成2000个句子的句子嵌入。
之后就不用再碰DistilBERT了,这里都是Scikit Learn,我们在这个数据集上做常规的训练和测试:
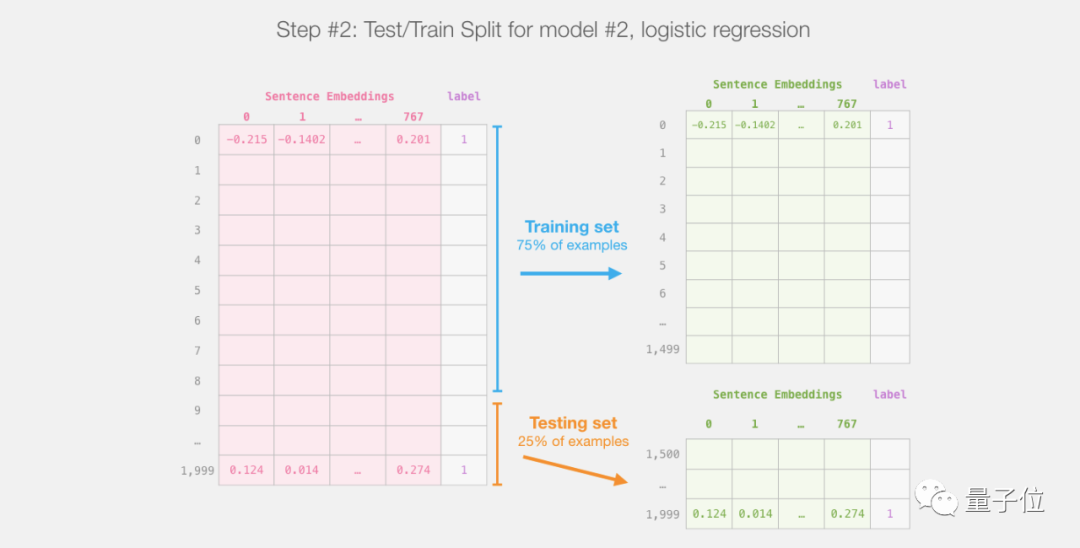
针对第一个模型也就是DistilBERT进行训练测试,创建我们训练用的数据集并评估第二个模型也就是逻辑回归模型。
然后在训练集上训练逻辑回归模型:
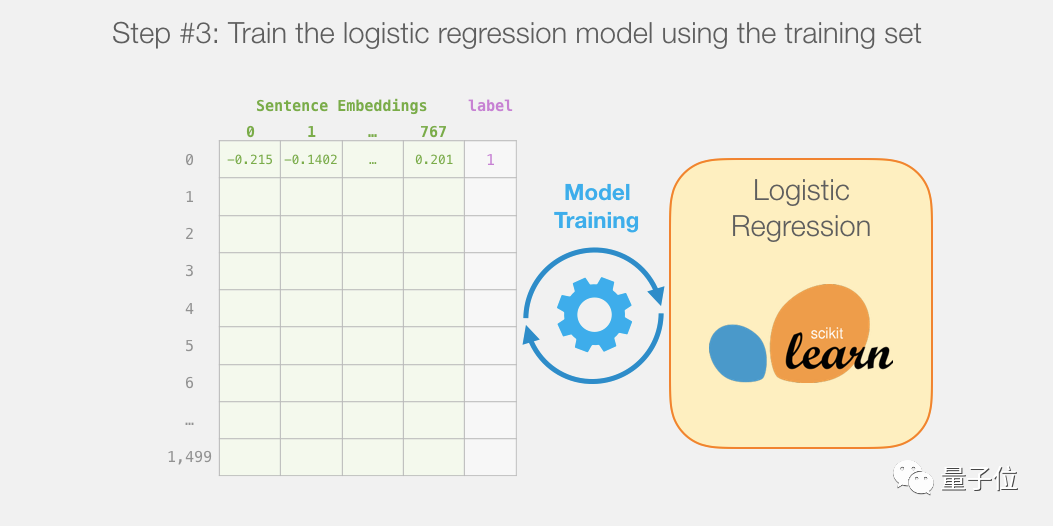
单个预测是如何进行的
在研究代码解释如何训练模型之前,我们先看看一个训练后的模型如何进行预测。
我们试着给这句话进行分类预测:
a visually stunning rumination on love
关于爱情的视觉上令人惊叹的反省
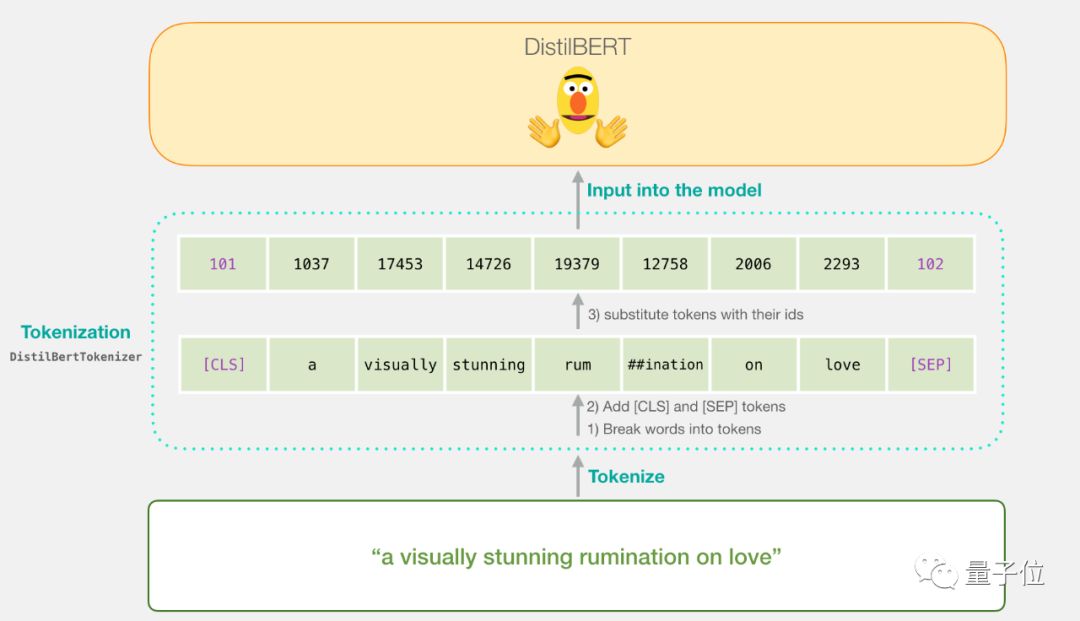
第一步,用BERT tokenizer把句子分为两个token;
第二步,我们加入句子分类用的特殊token(第一个位置的是[CLS],句子结束的位置是[SEP])。

第三步,tokenizer用嵌入表中的ID代替每个token,成为训练模型的组件。

注意,tokenizer是在这一行代码里完成所有步骤的:
1tokenizer.encode("a visually stunning rumination on love", add_special_tokens=True)现在我们的输入句子是可以传递给DistilBERT的适当状态了。
这个步骤可视化起来长这样:
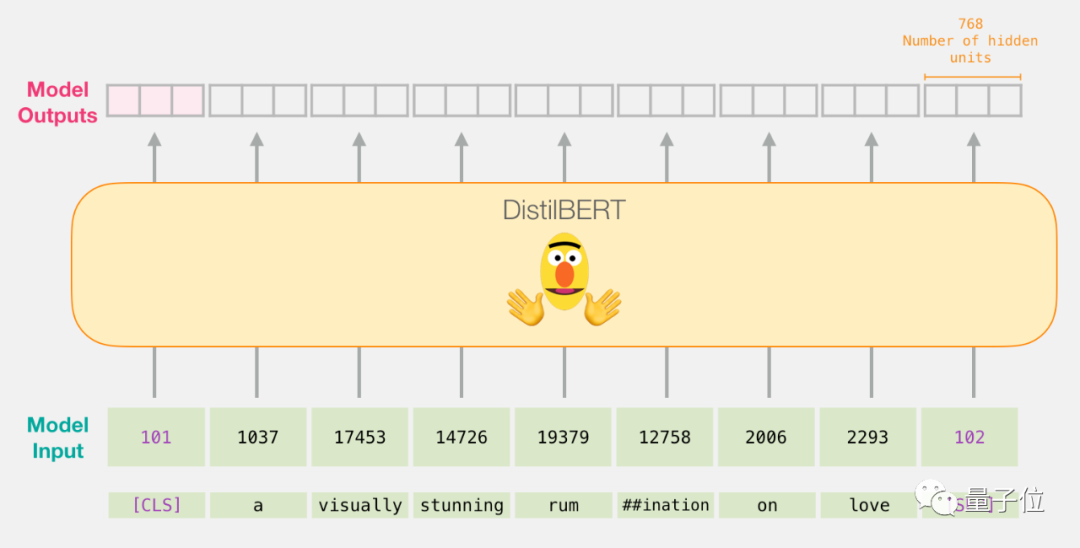
从DistilBERT经过
输入向量从DistilBERT经过,输出每个输入token的向量,每个向量有768个数字组成。
因为这是个句子分类的任务,所以我们忽视掉除第一个向量之外的其他内容(第一个向量和[CLS]token相关),然后把第一个向量作为逻辑回归模型的输入。
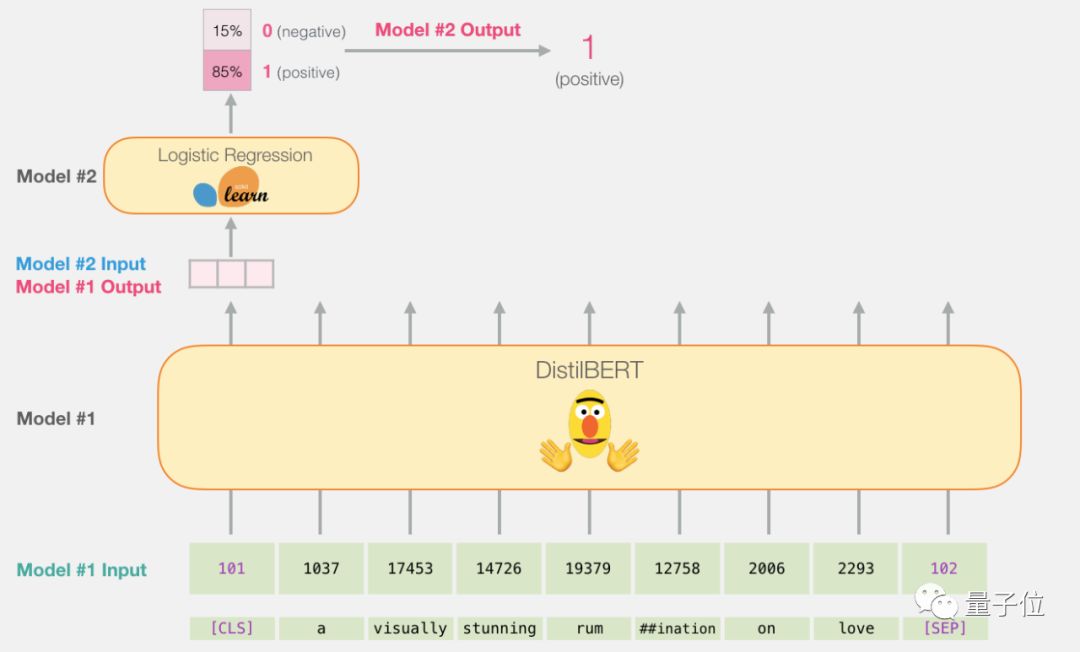
从这里开始,逻辑回归模型的工作就是根据它从训练过程中学到的经验,把这个向量进行分类。
这个预测计算的过程是这样的:
代码
现在,开始看这整个过程的代码,后面你也可以在传送门里看到GitHub代码和Colab上的可运行版本。
首先,导入trade工具。
1import numpy as np
2import pandas as pd
3import torch
4import transformers as ppb # pytorch transformers
5from sklearn.linear_model import LogisticRegression
6from sklearn.model_selection import cross_val_score
7from sklearn.model_selection import train_test_split你可以在GitHub里找到这个数据集,所以我们可以直接把它导入到pandas dataframe里。
1df = pd.read_csv('https://github.com/clairett/pytorch-sentiment-classification/raw/master/data/SST2/train.tsv', delimiter='\t', header=None)可以直接用df.head() 查看dataframe的前五行,看看数据集长啥样。
1df.head()然后就输出:

导入预训练DistilBERT模型和tokenizer
1model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer, 'distilbert-base-uncased')
2
3## Want BERT instead of distilBERT? Uncomment the following line:
4#model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
5
6# Load pretrained model/tokenizer
7tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
8model = model_class.from_pretrained(pretrained_weights)现在可以对这个数据集tokenize了。
注意,这一步和上面的例子不同,例子只处理了一个句子,但是我们要批处理所有的句子。
Tokenization
1tokenized = df[0].apply((lambda x: tokenizer.encode(x, add_special_tokens=True)))这一步让每个句子都变成ID列表。
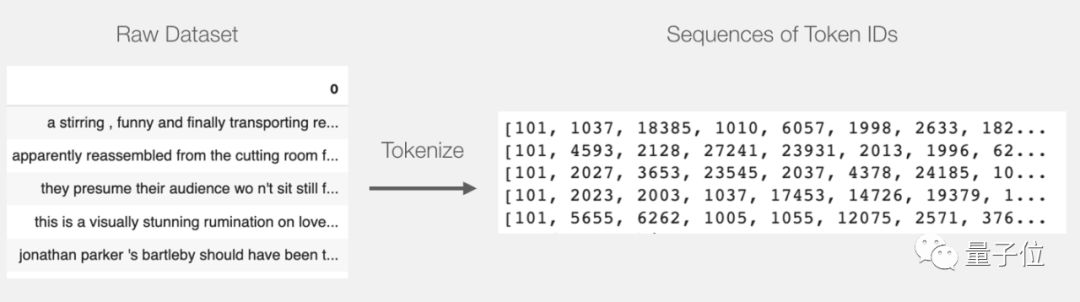
数据集是当前的列表(或者pandas Series/DataFrame),在DistilBERT处理它之前,我们需要给所有向量统一规格,给短句子加上token 0。
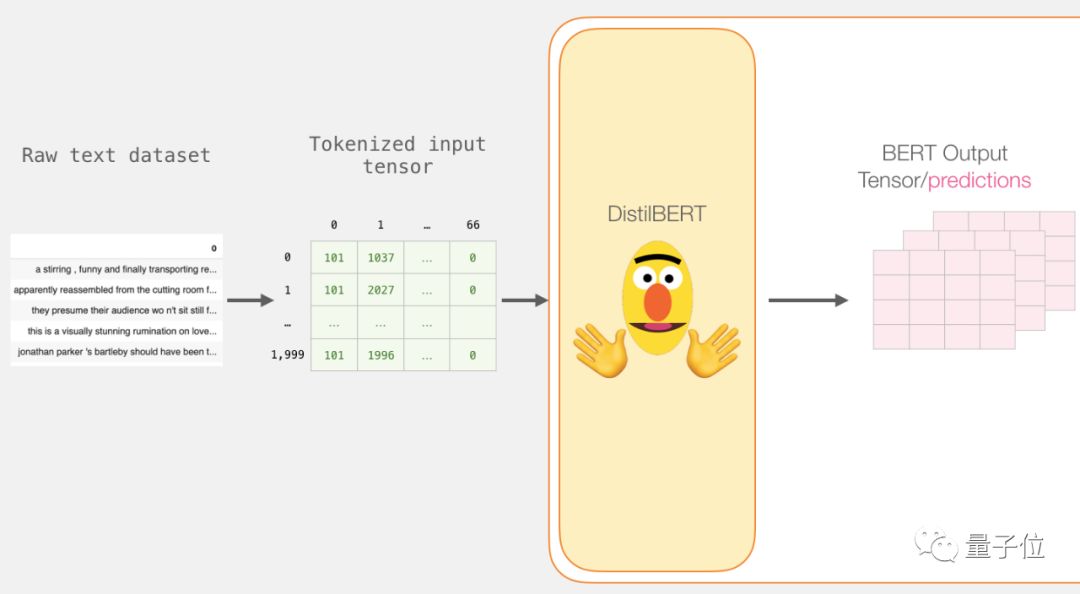
填上0之后,现在就有了一个成形的矩阵/张量可以投喂给BERT了:

用DistilBERT处理
现在,为填充的token矩阵创造一个输入张量,发送给DistilBERT。
1input_ids = torch.tensor(np.array(padded))
2
3with torch.no_grad():
4 last_hidden_states = model(input_ids)运行这一步之后,last_hidden_states保留DistilBERT的输出。
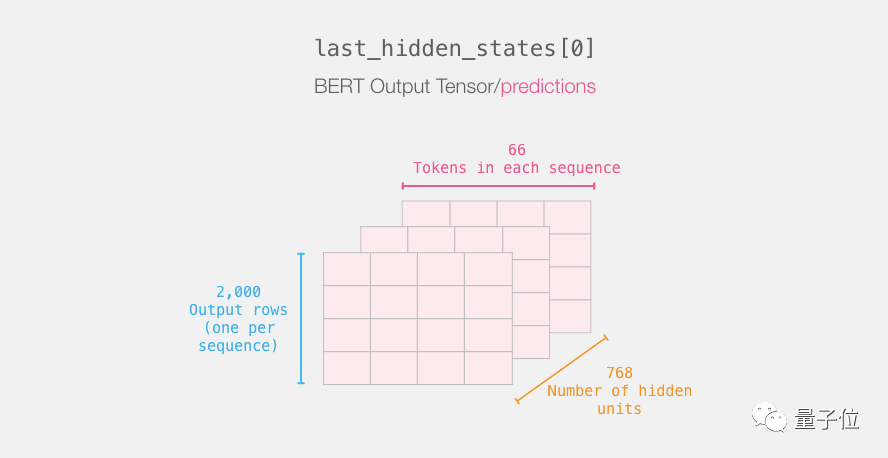
打开BERT的输出张量
解压缩这个3-d输出张量,先检查它的尺寸:
回顾处理句子的过程
每行都和我们数据集里的一个句子关联,回顾一下,整个处理过程是这样的:
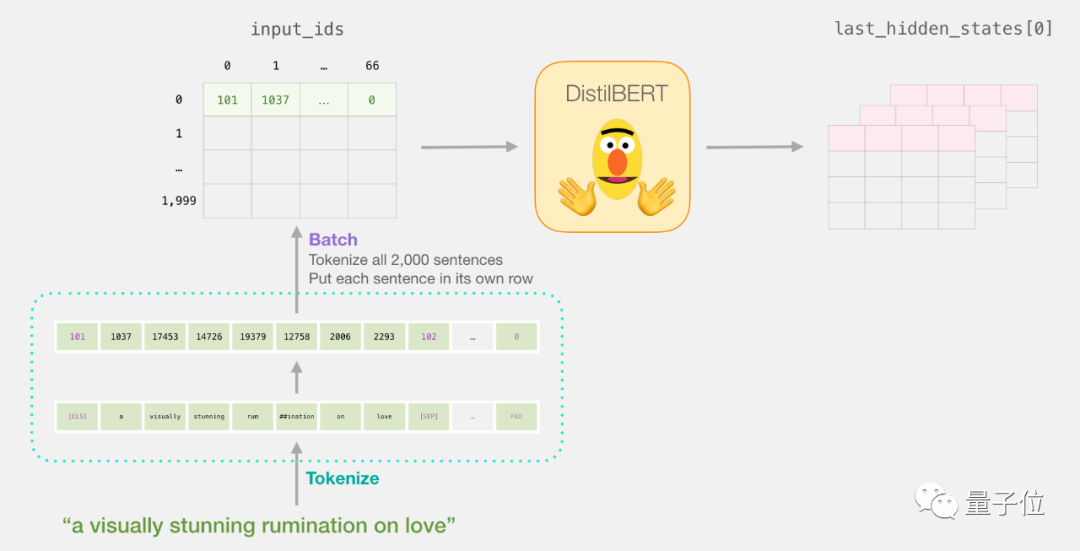
挑出重要部分
关于句子分类,我们只对BERT的[CLS] token输出感兴趣,所以我们只挑出重要部分就行了。
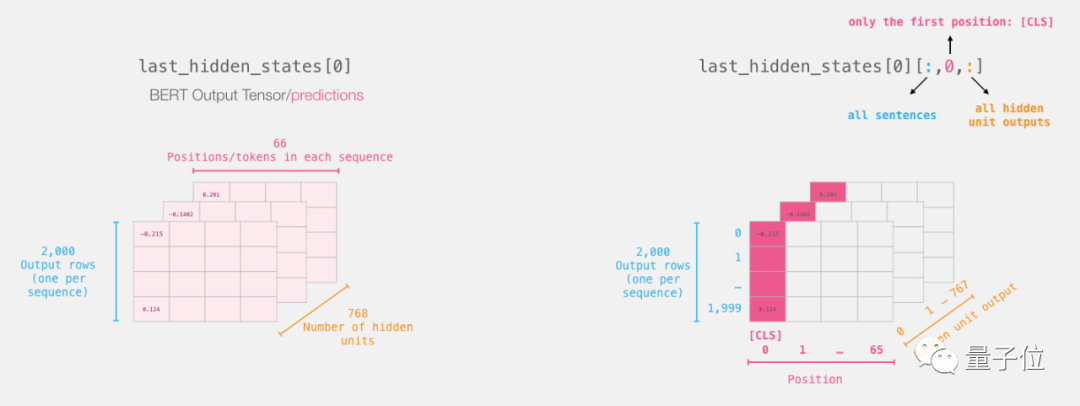
下面是从3D张量里挑出我们需要的2D张量的办法:
1# Slice the output for the first position for all the sequences, take all hidden unit outputs
2features = last_hidden_states[0][:,0,:].numpy()现在的特征是个2D numpy数组,里面有我们数据集里所有句子的句子嵌入。
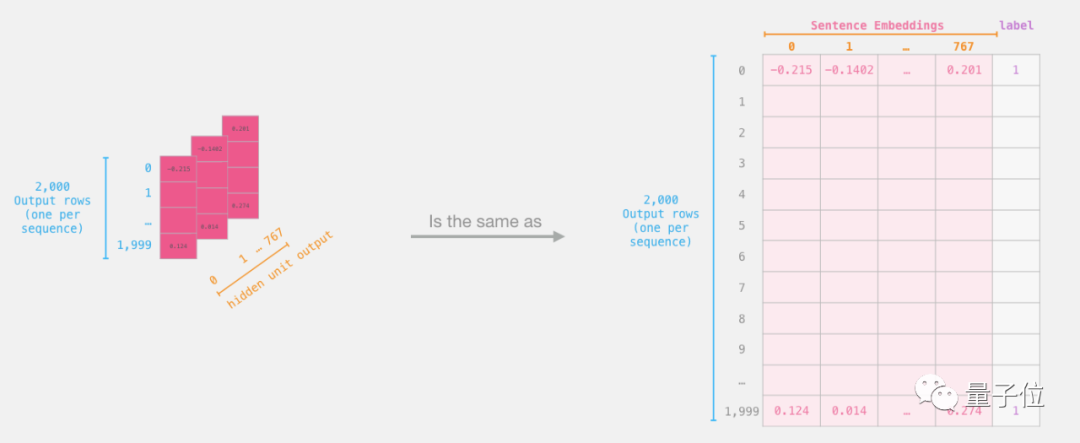
逻辑回归数据集
现在我们有BERT的输出了,前面逻辑回归模型已经已经训练好了。下图的798列是特征,标签是初始数据集里面的。
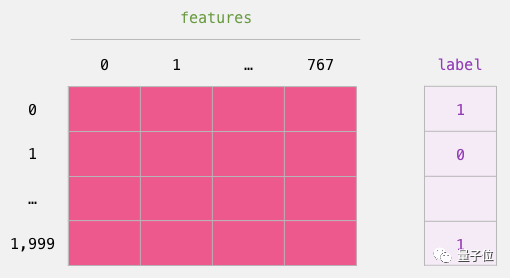
在完成传统的机器学习训练测试后,我们可以拿逻辑回归模型再进行训练。
1labels = df[1]
2train_features, test_features, train_labels, test_labels = train_test_split(features, labels)将数据分为训练集/测试集:
接下来,在训练集上训练逻辑回归模型:
1lr_clf = LogisticRegression()
2lr_clf.fit(train_features, train_labels)现在模型训练完了,用测试集给它打分:
1lr_clf.score(test_features, test_labels)得出的模型准确度为81%。
Score Benchmarks
作为参考,这个数据集目前的最高准确率得分为96.8.
在这个任务里,DistilBERT可以训练来提升分数,这个过程叫做微调(fine-tuning),可以更新BERT的权重,来实现更好的分类句子。
微调后的DistilBERT可以实现90.7的准确率,完整的BERT模型能达到94.9的准确率。
传送门
A Visual Guide to Using BERT for the First Time
https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/
代码
https://github.com/jalammar/jalammar.github.io/blob/master/notebooks/bert/A_Visual_Notebook_to_Using_BERT_for_the_First_Time.ipynb
Colab
https://colab.research.google.com/github/jalammar/jalammar.github.io/blob/master/notebooks/bert/A_Visual_Notebook_to_Using_BERT_for_the_First_Time.ipynb
DistilBERT
https://medium.com/huggingface/distilbert-8cf3380435b5
— 完 —
大咖齐聚!量子位MEET大会正在直播
量子位 MEET 2020 智能未来大会正在直播!李开复、倪光南、景鲲、周伯文、吴明辉、曹旭东、叶杰平、唐文斌、王砚峰、黄刚、马原等AI大咖与你一起读懂人工智能。扫码观看直播吧~ ~


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !




