变革尚未成功:深度强化学习研究的短期悲观与长期乐观
选自alexirpan
机器之心编译
参与:Nurhachu Null、刘晓坤
深度强化学习是最接近于通用人工智能(AGI)的范式之一。不幸的是,迄今为止这种方法还不能真正地奏效。在本文中,作者将为我们解释深度强化学习没有成功的原因,介绍成功的典型案例,并指出让深度强化学习奏效的方法和研究方向。
本文所引文献大多数来自于 Berkeley、Google Brain、DeepMind 以及 OpenAI 过去几年的工作,因为它们更容易获得。我难免遗漏了一些比较古老的文献和其他研究机构的工作,我表示很抱歉——毕竟一个人的时间精力有限。
简介
我曾经在 Facebook 说过:
当别人问我强化学习能否解决他们的问题时,至少有 70% 的时候我的回答是:不能。

深度强化学习被成堆的炒作包围着,并且都有足够好的理由!强化学习是一种难以置信的通用范式,原则上,一个鲁棒而高性能的强化学习系统可以处理任何任务,而且将这种范式和深度学习的经验学习能力相结合是很自然的。深度强化学习是最接近于通用人工智能(AGI)的范式之一。
不幸的是,它目前还不能真正地奏效。
但现在,我相信它会取得成功的。如果我不相信强化学习,我是不会从事相关工作的。但是在通往成功的路上存在很多问题,而且很多问题从根本上来说都是很困难的。智能体的漂亮 demo 背后隐藏着创造它们的过程中所付出的所有心血、汗水和泪水。
我多次看到人们被最新的研究所吸引,他们初次尝试使用深度强化学习,而且没有失败,于是低估了深度强化学习所面临的困难。毫无疑问,「玩具问题」并不像看起来那么简单。无一例外,这个领域会数次「摧残」他们,直至他们学会设定更现实的研究期望。
实际上这并不是任何人的错,它更像是一个系统问题。讲述积极结果的故事是很容易的,但承认消极的结果是很困难的。问题在于消极的结果是研究者最常遇到的。某种程度上,消极的结果实际上比积极的结果更加重要。
在这篇文章的其余部分,我会解释一下深度强化学习没有成功的原因,它成功的典型案例,以及将来让深度强化学习更加可靠地工作的方式。我相信如果在这些问题上可以达成一致,并实实在在地讨论相关的问题,而不是独立地重复地去一次又一次地重新发现相同的问题。
我希望看到更多的关于深度强化学习的研究。我希望有新人加入这个研究领域,我也希望知道新人们能够了解他们正在做什么。
在开始文章的剩余部分之前,有几点提示:
我在这篇文章中引用了一些论文。通常,我会因其令人信服的负面例子而引用一篇论文,而不引用正面例子。这并不意味着我不喜欢那些论文。我喜欢这些论文,如果有时间的话,它们是值得一读的。
我在这篇文章中可互换地使用「reinforcement learning,强化学习」和「deep reinforcement learning,深度强化学习」,因为在我的日常工作中,强化学习一直蕴含着深度强化学习的意思。我所批判的是深度强化学习的经验行为,而不是一般的强化学习范式。我所引用的论文中通常使用了深度神经网络的智能体。尽管这种经验批判可能同样适用于线性强化学习或者列表格式强化学习,但是我并不认为这也适用于到更小的问题。强化学习有望被应用于大型、复杂、高维的环境中,在这些环境中良好的函数逼近是必要的。受此驱动,人们才炒作强化学习,这些炒作正是需要重点解决的问题。
这篇文章的基调是由悲观向乐观转换的。我知道文章有些长,但是我更希望你花点时间读完全文再做回复。
下面是深度强化学习的一些失败案例。
深度强化学习可能是非常采样低效的(sample inefficient)
用于深度强化学习的最著名的基准测试就是 Atari 游戏。正如目前最出名的深度 Q 网络论文中所展示的一样,如果你将 Q-Learning 与合理规模的神经网络和一些优化技巧相结合,你可以在几款 Atari 游戏中实现和人类相当甚至超越人类的性能。
Atari 游戏以每秒 60 帧的速度运行,那么目前最先进的 DQN 需要多块的速度才能达到人类的性能呢?
这个问题的答案取决于游戏,那么我们一起来看一下最近 deepmind 发表的一篇论文 Rainbow DQN。这篇论文对原始 DQN 的几个渐变版本的体系结构进行了 ablation study(类似于控制变量法,对模型进行简化测试),结果证明组合所有的改进可以得到最佳的性能。在试验的 57 场 Atari 游戏中,有超过 40 场的表现超越了人类。结果如下图所示:
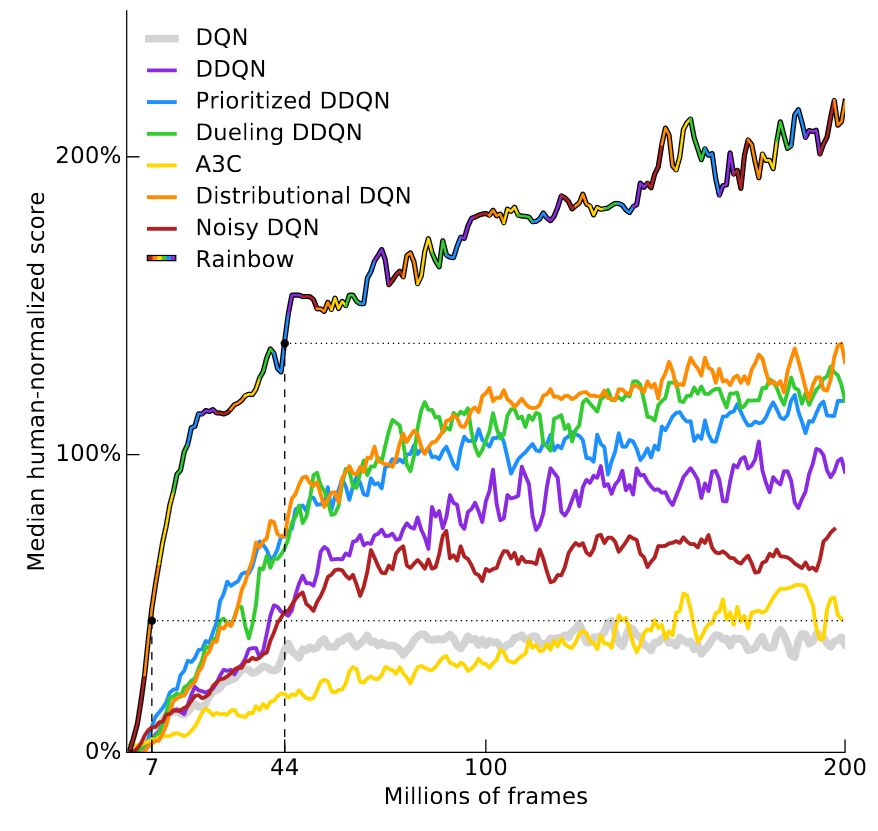
y 轴是「人类性能标准化的中值得分」。通过为 57 个 Atari 游戏中的每一个训练一个 DQN 模型,然后将每个智能体的得分进行标准化,使得人类的性能是 100%,然后将模型在 57 款游戏上的中值得分画出来。RainbowDQN 模型的训练数据达到约 1800 万帧的时候突破了 100% 的阈值。这相当于玩了 83 小时的游戏,再加上训练模型所花的时间。而人类通常能够在几分钟之内学会一款 Atari 游戏。
请注意,1800 万帧实际上已经是相当好的结果了,如果考虑到之前的记录,分布式 DQN(Distributed DQN)需要 7000 万帧才能达到 100% 的中值性能,大约是 4 倍于 RainbowDQN 的训练时间。至于发表在 nature 上的关于 DQN 的论文,即便经历了 2 亿帧的游戏体验,也从未达到 100 的中值性能。
规划谬误理论认为,完成一件事情所花的时间通常要比你想象的更多。强化学习也有其规划谬误,学习一个策略通常需要比想象更多的样本。
这并不是 Atari 游戏特有的问题。另一个非常流行的测试基准是 MuJoCo 基准,这是在 MuJoCo 物理模拟器中设置的一个任务集合。在这些任务中,输入状态通常是模拟机器人各关节的位置和速度。即使不必解决视觉问题,根据任务的不同,这些基准的学习仍然需要 105105 到 107107 的学习时间步。对于控制一个如此简单的环境而言,这是一个惊人的实验量。
在 DeepMind 的跑酷论文(Emergence of Locomotion Behaviours in Rich Environments)的 demo 中,使用了 64 个 worker 在超过一百小时的时间里训练策略。这篇论文并没有阐明 worker 的含义,但是我认为它的意思是一个 worker 意味着 1 个 CPU。
这些结果超级酷。当它刚出现的时候,我很惊讶,强化学习竟然可以学习这些奔跑的步态。
同时,需要 6400 个 CPU 小时训练的事实多少有些令人沮丧。并不是说我期望用更少的时间,更让人沮丧的是深度强化学习仍然比实践水平的采样效率水平要低好几个数量级。
有一个显而易见的对比:倘若我们忽略了采样效率呢?某些环境设置比较易于生成经验,游戏就是一个很好的例子。但是,对于任何不正确的设置,强化学习将面临一场艰苦的战斗,不幸的是,大多数现实世界的设置都属于这一类。
如果你仅仅关心最终的性能,那么很多问题都能够通过其他方法更好地解决
在寻求任何研究问题的解决方案时,通常会在不同的目标之间进行权衡。你可以通过优化以获得针对该研究问题的真正好的解决方案,也可以优化以做出良好的研究贡献。最好的问题就是需要作出很好的研究贡献以得到解决方案的问题,但是满足这种标准是很困难的。
对于单纯地得到良好的性能,深度强化学习方法得到的记录并不是那么好,因为它们总是被其他方法击败。MuJoCo 机器人由在线的路径优化控制。正确的动作几乎是实时、在线计算得到的,而且没有经过任何离线训练。等等,它是运行在 2012 个硬件上面的(Synthesis and Stabilization of Complex Behaviors through Online Trajectory Optimization)。
我觉得这些行为可以和那篇跑酷论文相提并论。那么这两篇论文的差别是什么呢?
差别在于 MuJoCo 机器人中使用的是模型预测控制,这种控制方法可以根据真实世界的模型 (物理模拟器) 执行规划。而无模型的强化学习不做这种规划,因此它的训练过程更困难。另一方面,如果根据一个模型来规划会有如此大的帮助,那么为何还要训练一个强化学习策略来自寻烦恼呢?
类似的情况,在 Atari 游戏中,使用现成的蒙特卡洛树搜索也能够很容易地得到强于 DQN 的性能。这是 Guo 等人在 NIPS 2014 上发表的基准数据(Deep Learning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree Search Planning)。他们比较了训练好的 DQN 和 UCT 智能体的得分。其中 UCT 是目前使用的蒙特卡洛树搜索的一个标准版本。

同样,这是一个不公平的比较,因为 DQN 没有执行任何搜索,蒙特卡洛树搜索会执行基于真实世界模型(Atari 模拟器)的搜索。然而,有时候我们并不需要关心比较是否公平,有时候我们只是想让它起作用。如果你对 UCT 的全面评估感兴趣,你可以参考原始论文「The Arcade Learning Environment: An Evaluation Platform for General Agents」。
理论上强化学习可以解决任何问题,包括在世界模型未知的环境中执行任务。然而,这种泛化是需要代价的:很难利用任何特定问题的信息来帮助学习,这就迫使我们使用大量的样本来学习那些可能已经被硬编码的东西。
然而经验法则是,除了极少数情况,特定领域的算法都会比强化学习表现得更快更好。如果仅仅是为了强化学习而做强化学习,那这不是问题,但是,我个人觉得,将强化学习的性能与其他任何方法进行比较的时候都会令人沮丧。我非常喜欢 AlphaGo 的一个原因是,它是强化学习的明确胜利,而且这不会经常发生。
这使得我更难向外行人士解释为什么我的问题很酷、很难、很有趣,因为他们通常缺乏相应的经验,来理解为什么这些问题很困难。在人们认为强化学习能做什么和强化学习实际上能做什么之间存在一个理解鸿沟。我现在从事于机器人学相关的研究。当提到机器人的时候,很多人都会想到一家公司:波士顿动力。
这个并没有使用强化学习。我经历过几次谈话,人们认为波士顿动力的机器人使用了强化学习,但是实际上并没有。如果你查阅这个研究团队的论文,你会发现有一篇提到时变 LQR、QP 求解器和凸优化的论文(https://dspace.mit.edu/openaccess-disseminate/1721.1/110533)。换言之,他们绝大多数情况使用的是经典的机器人技术。事实证明,当你正确地使用这些经典技术的时候,它们能够工作得相当好。
强化学习通常需要一个奖励函数
强化学习假定存在一个奖励函数。通常,奖励函数要么是给定的,要么是离线手动调整的并在学习过程中保持固定。这里说「通常」,是因为存在例外情况,例如模仿学习或者逆强化学习,但是绝大多数强化学习方法都将奖励函数视为必要的。
重要的是,为了让强化学习做正确的事,你的奖励函数必须精确地捕捉到你希望得到的东西,我的意思是准确无误地捕捉。强化学习有个恼人的倾向,它会把奖励函数过拟合,从而导致不希望出现的结果。这正是 Atari 为什么是出色基准的原因,在 Atari 游戏中,不仅能够轻易地得到大量的样本,而且每款游戏的目标都是将得分最大化,所以根本不必担心奖励函数的定义,每款游戏都有一样的奖励函数。
这同样也是 MuJoCo 如此受欢迎的原因。因为它们运行在模拟环境中,你拥有关于所有对象状态的完美知识,这一切都使得奖励函数的定义变得更加容易。
在 Reacher 任务中,你控制着一个两段机器臂,它被连接在一个中心点上,这个任务的目标就是将机器臂的端点移动到目标位置。
由于所有的位置都是已知的,奖励函数可以定义为机械臂端点到目标点之间的距离,再加上一个小的控制代价。原则上,如果你拥有足够多的传感器来获取环境中足够精确的位置,在现实世界也可以做到这点。但是,根据系统任务的不同定义合理的奖励函数可能会很困难。
就其本身而言,需要一个奖励函数并不是什么大事,除非......
奖励函数的设计是困难的
创建一个奖励函数并不是很困难。困难在于设计可学习的奖励函数去激励智能体得到期望的行动。
在 HalfCheetah 环境中,你拥有一个两条腿的机器人,它被限制在一个竖直平面中,这意味着它只能向前或者向后移动。

这里的目标是学习一个奔跑的步态。奖励函数是 HalfCheetah 的速度。
这是一种定型的奖励,也就是说它越接近最终目标,给出的奖励就越高。与之对应的是稀疏奖励函数,它仅仅在目标状态给出奖励,在其他任何地方都没有奖励。定型奖励函数通常更加容易学习,因为即便所学的策略没有给出问题的完全解决方案,它也能给出积极的反馈。
不幸的是,定型的奖励函数会给学习带来偏差。正如之前所说的,这会导致并不期望得到的行为。一个典型的例子就是 OpenAI 博客中的赛船游戏(https://blog.openai.com/faulty-reward-functions/)。其目标是完成比赛。你可以想象,稀疏奖励函数会在某个时间内完成游戏时给出+1,否则就是 0。
该提供的奖励函数会在你命中关卡的时候给出分数,也会因为收集能更快完成比赛的能量而给出奖励。结果收集能量能够比完成比赛获得更多的分数。
老实说,当我看到 OpenAI 的这篇博客的时候是有些恼火的。很明显,在奖励函数不匹配的情况下,强化学习会得到很诡异的结果!我觉得他们那篇博客在给定的例子上做了大量的不必要的工作。
然后我就开始写这篇博客,而且意识到最引人注目的误匹配奖励函数的视频就是那个赛船游戏的视频。并且从那时开始,这个视频就被用在了好几个阐明这个问题的报告中。所以,好吧,我很不情愿地承认这是一篇很好的博客。
强化学习算法沿着一个连续体发展,在这个连续体中算法需要或多或少地假设一些关于它们所处环境的知识。最广泛应用的是无模型强化学习,它几乎和黑箱优化是一样的。这些方法仅仅被允许假设它们处于一个马尔科夫决策过程(MDP)中。否则,它们将没有任何意义。智能体只是被简单地告知这个会给它+1 的奖励,这个不会给它奖励,它必须自行学会其余的东西。就像黑箱优化一样,问题在于任何一个能够给出+1 奖励的都是好的,即使有时候+1 的奖励并不是源于正确的原因。
一个经典的非强化学习的例子就是使用遗传算法来设计电路,最终得到的电路中,一个未连接的逻辑门竟然是最终设计中所必须的。
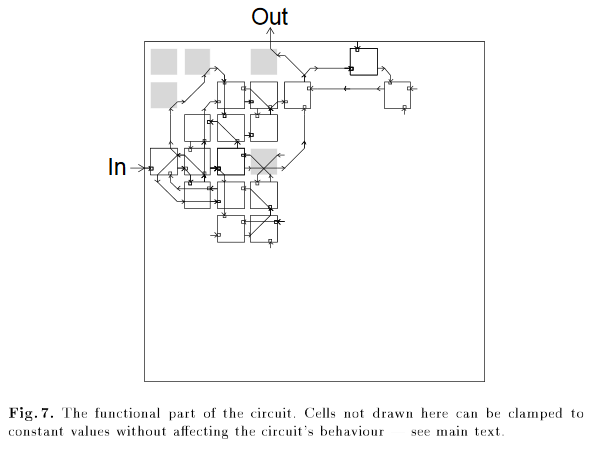
灰色的单元是为了得到正确的行为所必须的,也包括左上角的那个单元,尽管它并没有被连接。
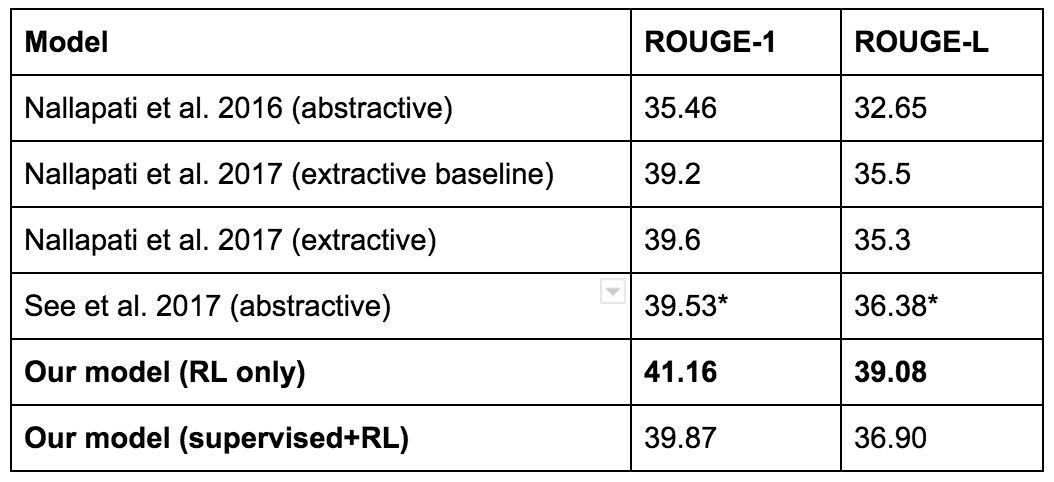
最近的一个例子,可以参考 Salesforce 公司的这篇博客(https://www.salesforce.com/products/einstein/ai-research/tl-dr-reinforced-model-abstractive-summarization/)。他们的目标是文本摘要。他们的基线模型是用监督学习训练得到的,然后使用叫做 ROUGE 的自动指标去评估模型。ROUGE 是不可微的,但是由于强化学习可以处理不可微的奖励函数,所以他们尝试直接使用强化学习的方法来优化 ROUGE。这个方法得到了很高的 ROUGE,但是它却无法给出一个很好的摘要。下面是一个例子:
Button 在迈凯轮车队的第 100 场比赛被拒绝,因为 ERS 阻止了他进入起跑线。这对英国人来说是一个悲惨的周末。Button 已经合格了。在巴林比的尼科罗斯伯格之前完成。Lewis Hamilton,在 11 场比赛中领先 2000 圈……
所以,尽管强化学习模型得到了最高的 ROUGE 得分,他们最终还是选择了另外一个模型。
这里还有另外一个例子,是 Popov 等人的论文(Data-efficient Deep Reinforcement Learning for Dexterous Manipulation),有时候被称为「乐高堆叠」。作者使用了 DDPG 的一个分布式版本来学习抓取策略。它的目标就是抓到红色的方块,并将其堆叠在蓝色的方块上面。
他们使系统跑通了,但是遇到了非常严重的失败案例。在原始的举起动作中,奖励函数是基于红色方块被举的高度,通过底平面的 Z 坐标来定义。其中一种失败的模式就是学到的策略将红色的方块翻了过来,并没有将它捡起来。
显然这并不是期望的解决方案。但是强化学习并不关心这个。从强化学习的角度来看,翻转红色的方块会得到奖励,从而它会继续翻转。
解决这个问题的一种方式是,仅仅在机器人完成方块堆叠之后才给出正奖励使奖励函数稀疏化。有时候这种方式会奏效,因为稀疏奖励函数是可学习的,然而通常都不会起作用,因为缺乏正增强会使得整个过程都变得很困难。
解决这个问题的另一个方式就是仔细地进行奖励函数调整,添加新的奖励项并调整已有的系数,直至得到期望学到的行为。在这条战线上「打赢强化学习之战」是可能的,但是这是一场不怎么令人称心的战斗。有时候这样做是必要的,但是我并不觉得我从中学到了什么。
作为参考,以下列出了「乐高堆叠」那篇论文中的奖励函数之一。
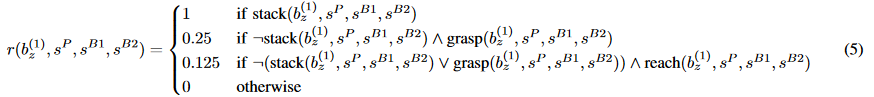
我不清楚设计这么一个奖励函数花费了多少时间,但是由于这里存在这么多的项和不同的系数,我猜应该是花费了「大量的」时间。
在与其他强化学习研究者交谈的过程中,我听到了一些因为没有设计合适的奖励函数,而导致奇怪结果的轶事。
我的一位合作者在教智能体进行室内导航。如果智能体走出了边界,事件就会终止。然而当事件以这种方式终止的时候,他并没有增加任何惩罚项。最终智能体学到的策略表现出了自杀的行为,因为负奖励太多了,而正奖励很难实现。
一个朋友训练机械臂来到达桌子上的一个点。而事实是这个目标点是相对于桌子定义的,而桌子并没有固定到任何东西上。结果策略学会了猛烈地撞击桌子,最终将桌子掀翻,目标点也被移动了。目标点凑巧落在了机械臂末端的旁边。
一位研究者谈论了使用强化学习来训练模拟机器手,使它拿起锤子钉钉子。最开始,奖励是由钉子插入孔中的距离决定的。机器人并没有拿起锤子,而是使用自己的肢体将钉子砸入了孔中。因此,他们增加了一个奖励项来鼓励机器人拿起锤子,并重新训练策略。最后他们得到了拿起锤子的策略....... 但是后来它将锤子扔在了钉子上,而不是使用锤子去砸钉子。
诚然,这些都是我道听途说的,我并没有见过任何一个相关的视频。然而,没有一个听起来是难以置信的。我已经被强化学习雷了好多次了,所以我选择相信。
即使给定了较好的奖励函数,也很难跳出局部最优
之前关于强化学习的例子有时候被称作「reward hacking」。对我而言,这意味着存在一个更加聪明的现成的解决方案,它能够给出比奖励函数的设计者预期更多的奖励。
Reward hacking 是一个例外。更普遍的情况则是比较糟糕的局部最优解,这个局部最优解源于「探索—利用」权衡过程中的错误。
这里有一段我喜欢的视频。它是对「Normalized Advantage Function」的实现(Continuous Deep Q-Learning with Model-based Acceleration),是在 HalfCheetah 环境中学习得到的。
从外部角度来看,这实在是很愚蠢。但是只有当我们以第三人的角度来看,并且大量的预置知识告诉我们靠双足奔跑才是更加好的,才会觉得它很蠢。然而强化学习并不知道这个!它只看到了一个状态向量,并且输出动作向量,并且它知道自己能够获得某些正奖励。这是它知道的所有。
我猜,在它学习的过程中发生了以下这些现象:
在随机探索中,策略发现向前扑倒比原地不动要更好一些。
它做了大量努力来「铭记」那种行为,所以它现在会连续地向前扑倒。
在向前扑倒之后,策略学习到,如果它一次使很大的劲,它会做一次后翻,这个后翻能够得到稍微多一点的奖励。
它做了足够多的探索之后,相信后翻是一个不错的注意,然后就将后翻铭刻在了策略之中。
一旦后翻策略持续进行,这对已学到的策略而言更加容易:是纠正自己按照「标准姿势」奔跑,还是学会如何躺着仰面前行?我想应该是后者。
这是很有趣的,但是这绝对不是我们想让机器人所做的。
下面另一次失败的运行,这次是发生在 Reacher 环境中的。
在这次运行中,初始随机权重倾向于输出特别大的正值或特别小的负值的动作输出。这使得绝大多数的动作输出可能是最大加速度或者最小加速度。这实际上很容易发生超快的旋转:在每个关节处输出高强度的力。一旦机器人开始运行,它很难以一种有意义的方式偏离这种策略—如果要偏离,必须采取一些探索步骤来阻止这种疯狂的旋转。这当然是可能的,但是在这次运行中,并没有发生。
这些都是一直以来困扰着强化学习的经典「探索—利用」问题的两种情况。你的数据来自于目前的策略。如果你当前的策略探索太多,那将会得到大量的垃圾数据,从而学习不到任何东西。利用太多,则记忆的行为经常是非最优的。
这里有几个解决这个问题的直观想法—内在动机、好奇心驱动的探索、基于重要性的探索,等等。其中很多方法都是在上世纪 80 年代或者更早的时候提出来的,而且一些方法已经使用深度学习的模型进行了重新研究。然而,据我所知,这些方法都不能在所有的环境中一致奏效。有时候它们会有帮助,有时候则不会。如果已经存在一种探索技巧能够在所有环境中起作用的话,那将会是很好的,但是我很怀疑这种万精油会不会在近期被发现。不是因为人们没有尝试解决这个问题,而是因为探索—利用问题实在是太难了。可以参考维基百科中的多臂老虎机问题:
这一问题最初由二战中的盟军科学家考虑到的,但事实证明非常棘手,据 Peter Whittle 说,这个问题被提议搁置在德国,以便德国科学家也能在这个问题上浪费时间。(参考: Q-Learning for Bandit Problems, Duff 1995)
我开始想象深度强化学习是一个恶魔,故意曲解你的奖励,并积极寻找最懒的局部最优解。这有点荒谬,但我发现这实际上是一种富有成效的思维方式。
即使当深度强化学习成功的时候,它也有可能仅仅是过拟合了环境中的某些奇怪的模式
深度强化学习之所以流行是因为它是唯一一个被认可在测试集上做训练的机器学习方法。
强化学习的好处在于如果你想在一个环境中做得很好,你可以肆意地进行过拟合。但是不好的地方在于如果你想把模型泛化到另一个环境中,你可能会做得很糟糕。
DQN 可以解决很多 Atari 游戏,但是它是通过将所有的学习聚焦在一个单独的目标上实现的—仅在一款游戏中表现得极其好。最终的模型不会泛化到其他的游戏中,因为它没有以其他游戏中的方式训练过。你也可以将一个学到的 DQN 模型精调到一款新的 Atari 游戏中(Progressive Neural Networks (Rusu et al, 2016)),但是不能保证它能够完成迁移,而且人们通常不期望它能够完成这种迁移。这并不是我们已经在 ImageNet 中所见证的巨大成功。
原则上,在一个广泛的环境分布中训练应该会使这些问题消失。在某些情况下,你可以免费地使用这种分布。导航就是其中的一个例子,你可以随机地采样目标位置,然后使用统一的价值函数去泛化(Universal Value Function Approximators, Schaul et al, ICML 2015)。我发现这项工作是很有希望的,我后续会给出关于这项工作更多的一些例子。然而,我认为深度强化学习的泛化能力还不足以处理很多样的任务集合。认知传感已经变得更好了,但是深度强化学习还没有达到 ImageNet 的成就。OpenAI 尝试挑战这个问题,但是据我所知,这个问题太难解决了,所以也没有多少进展。
在拥有这种泛化能力之前,我们还是会受到策略被局限在极小范围内的困扰。有这么一个例子(这也是 daq 我打趣自己所做工作的机会),考虑一下这个问题:Can Deep Reinforcement Learning Solve Erdos-Selfridge-Spencer Games?(Raghu et al, 2017) 我们研究了一个轻量级的两玩家组合游戏,存在一个寻求最优玩法的闭环形式分析解决方案。在我们初次进行的一个实验中,我们固定了玩家 1 的行为,然后用强化学习的方法去训练玩家 2。这样,你可以将玩家 1 的动作视为环境的一部分。通过用玩家 1 的最优解来训练玩家 2,最终证明强化学习可以达到很高的性能。但是当我们将策略部署到一个非最优的玩家 1 上时,它的性能下降了。
Lanctot 等人在 NIPS 2017 的论文中展示了类似的结果(A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning)。其中有两个智能体在玩激光标记。它们都是以多智能体强化学习的方式训练得到的。为了测试其泛化能力,他们用 5 个随机种子来运行训练过程。下图的两个智能体都是在对方的基础上训练得到的。

它们学会了朝着彼此射击。然后他们从一个实验中选择玩家 1,与另一个实验中的玩家 2 进行对战。如果学习到的策略可以泛化,那么我们应该能够看到类似的行为。
剧透:它们并没有!

这是多智能体强化学习中的一个常见问题。当智能体进行对抗训练时,就发生了某种协同进化。智能体非常擅长和对手对抗,但是当它们被部署在一个没有见过的智能体上时,性能就会下降。我还想指出的是,这些视频中唯一不同的地方就是随机种子。完全相同的学习算法,完全相同的超级参数。它们的不同表现完全来自于初始条件的随机性。
话虽如此,但是竞争性自我对抗博弈中的一些简单例子貌似是与此矛盾的。OpenAI 的博客介绍了他们在这个领域中的一些工作(学界 | openai 竞争性自我对抗训练:简单环境下获得复杂的智能体)。自我对抗也是 AlphaGo 和 AlphaZero 的重要部分。我的直觉是:智能体在相同的环境中学习,它们可以不断地挑战彼此,并加速彼此的学习,但是如果其中的一个学习得比较快,它就会过度地利用较弱的那个智能体,并导致过拟合。当从对称自我博弈松弛化到多智能体环境中时,保证以同样的速度学习就会变得更加困难。
即使忽略了泛化问题,最终的结果也可能是不稳定的和难以复现的
几乎每个机器学习算法都有能够影响模型行为和学习系统的超参数。通常,这些参数都是通过手动挑选得到的,或者是通过随机搜索得到的。
监督学习是稳定的。固定的数据集,固定的真实目标。如果对超参数做了很小的改动,最终的性能并不会改变很多。并不是所有的超参数都具有很好的性能,但是,基于多年来发现的经验技巧,很多参数都会在学习得过程中表现出一种生命迹象。这种生命迹象是很重要的,因为它们会告诉你,你走上了正确的道路,值得投入更多的时间。
目前,深度强化学习一点都不稳定,这对于研究来说是非常恼人的。
当我开始在 Google Brain 工作的时候,我所做的第一批工作之一就是实现那篇「Normalized Advantage Function」的论文。我本以为花费大约两到三个星期就可以完成了。对我而言需要做以下几件事情:对 Theano 要有一定的熟悉(当然现在转移到了 TensorFlow),一些深度强化学习的经验,由于 NAF 论文的一作也在 Google Brain 实习,所以我可以向他请教。
由于几个软件 bug,最终我花了 6 个星期复现了结果。而问题在于,为什么花了这么久才找到 bug?
为了回答这个问题,我们先考虑一下 OpenAI Gym 中最简单的连续控制问题:摆任务。在这个任务中,有一个摆,它被固定在一个点上,受到重力作用。输入状态是 3 维的。动作空间是 1 维的,也就是施加的力矩。目标是使这个摆完全直立。
这是一个比较简单的问题,通过一个较好的定型奖励函数可以很容易做到。奖励函数被定义为摆的角度。将摆靠近垂直方向的动作会给出奖励,而且会给出递增的奖励。奖励函数基本上是凸的。
下面展示了一个基本成功的策略(视频见原文链接)。尽管它并没有使摆保持直立平衡,但是它输出了能够抵消重力的准确力矩。

下面是修复了所有 bug 之后的性能图。每一条曲线都是 10 次独立运行中的奖励函数。它们拥有相同的超参数,唯一的区别是随机种子。
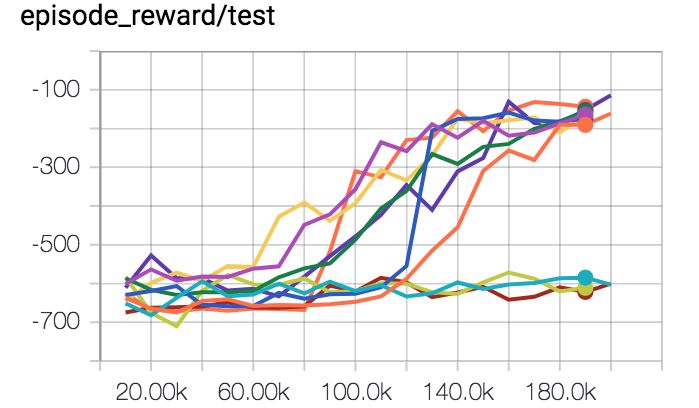
其中有 7 次运行是成功的,3 次没有成功,成功率是 70%。这里还有一些已经发表过的研究中的图,「Variational Maximizing Exploration, Houthooft et al,NIPS 2016」。所用环境是 HalfCheetah 环境。虽然奖励函数被修改得更加稀疏,但是这些细节并不是十分重要。Y 轴是事件奖励,X 轴是时间步数,所用算法是信赖域策略优化(TRPO)。
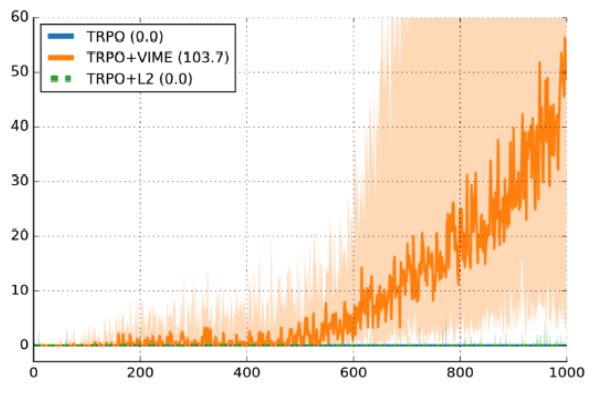
深色曲线是 10 个随机种子的中值性能,浅色区域是第 25 至第 75 百分位数。别误会,这幅图是支持 VIME 的很好的证明。但是另一方面,第 25 个百分位确实很接近 0 奖励。这意味着 25% 的运行失败了,仅由于随机种子的不同而导致。
注意,这种方差在监督学习中也是存在的,但是它很少会这么糟糕。如果我的监督学习代码在 30% 的时间不能成功运行,那么我会高度质疑数据加载或者训练过程的可信度。但是,如果我的强化学习代码没有随机性能好,那我并不清楚到底是代码有 bug,还是超参数不太好,或者我只是运气不好。
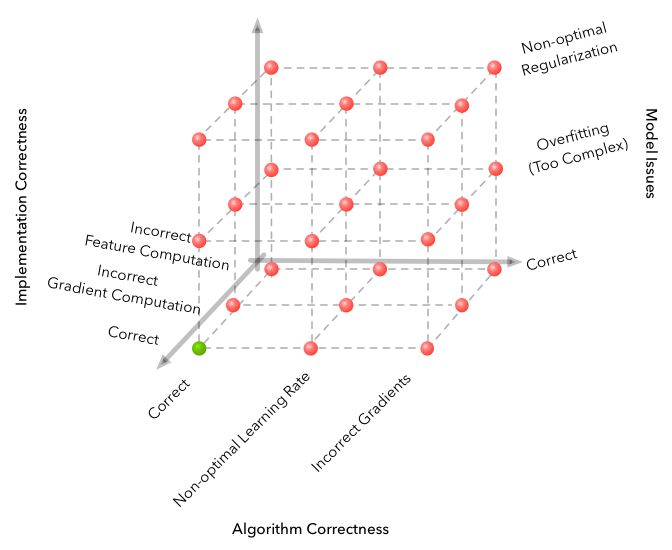
这幅图来自于这篇博客:「Why is Machine Learning 『Hard』?」。它的核心主题就是机器学习给失败的案例空间中增加了维度,这些维度导致出错形式的指数增加。深度强化学习增加了一个新的维度:随机几率(random chance)。解决随机几率的唯一方法就是在问题上投入足够多的实验来降低噪声。
当你训练一个样本低效并且不稳定的算法时,它会严重降低生产性研究的速度。或许它只需要一百万步。但是如果你使用了 5 个随机数种子,那就是将调节的超参数变成了原来的 5 倍,为了有效地测试你的假设,你需要极其多的计算量。
如果这样能让你感觉好一些的话,我愿意分享一下我的一些经历,我做这项工作已经有一段时间了,从零开始实现到能在很多强化学习问题上的 50% 时间中取得成功的策略梯度,花费了我大约六个星期的时间。我还有一个便于使用的计算机集群,以及一群自我来到这个地区之后就可以每天共进午餐的朋友。
此外,我们从监督学习中了解到的良好的 CNN 设计似乎并不适用于强化学习,因为经常受到信任分配/监督比特率的限制,而并不是因为缺乏强大的表征。ResNets、batchnorms 或者非常深的网络在这里没有任何作用。
[监督学习] 希望它起作用。即使把有些东西搞砸了,你也会得到一个非随机的结果。但是强化学习是被强迫起作用的。如果你把某些事情搞砸了或者你没有将一些东西调节到足够好,你很有可能得到一个比随机结果更糟糕的情况。即使一切都正常,你也有可能在 30% 的时间里得到一些糟糕的策略。长话短说,仅仅是因为深度强化学习的难度,更少是因为「设计神经网络」的难度。
以上引用内容摘自 Andrej Karpathy 还在 OpenAI 工作时发表在 Hacker News 上的评论(https://news.ycombinator.com/item?id=13519044)。
随机种子的不稳定性就像飞翔在矿井中的金丝雀。如果单纯的随机就足以在运行中导致如此大的差异,那么想象一下代码中实际的差异会有多大。
幸运的是,我们不必进行这样的想象。因为这已经被这篇论文检验过了——「Deep Reinforcement Learning That Matters」(Henderson et al, AAAI 2018)。论文结论如下:
给奖励函数乘以一个常量会导致显著的性能差别
5 个随机种子(常用值)不足以证明这种显著的结果,因为通过仔细挑选可以得到一些不重叠的置信区间。
同一算法的在同一个任务上的不同实现会有不同的性能,甚至是当使用相同的超参数的时候。
我在这里持有的观点是:强化学习对初始化和训练过程的动态变化都很敏感,因为数据总是在线采集到的,你可以执行的唯一监督只有关于奖励的单个标量。在较好的训练样例上随机碰到的策略会比其他策略更快地引导学习。没有及时地遇到好的训练样本的策略会崩溃而学不到任何东西,因为它越来越坚信:它所尝试的任何偏离都会导致失败。
但是,我们又该如何看待深度强化学习的成功案例呢?
深度强化学习确实做了许多很酷的事情。虽然 DQN 现在已经是老生常谈了,但是在那个时候确实是比较疯狂的。单个模型就可以直接从原始像素开始学习,而不需要为每个游戏进行单独地调节。后来 AlphaGo 和 AlphaZero 又继续获得了引人注目的成就。
然而,除了这些成功之外,很难在现实世界中发现深度强化学习产生实际价值的案例。
我曾经费尽心力去思考深度强化学习在现实世界中的生产应用,发现这是惊人的困难。我曾经期望在推荐系统中寻找有用的案例,但是我认为这些系统仍旧被协同过滤(collaborative filtering)和上下文老虎机 (contextual bandits) 主导着。
最终,我能找到的最好案例是 Google 的两个项目:降低数据中心能耗(https://deepmind.com/blog/deepmind-ai-reduces-google-data-centre-cooling-bill-40/)和最近发布的 Auto ML Vision。OpenAI 的 Jack Clark 在推特上的发问也得到了类似的结论。
我知道奥迪也在使用深度强化学习研发技术,因为他们在 NIPS 上展示了一辆自动驾驶汽车的 RC 版本,据说这款汽车使用了深度强化学习。我知道有一些优化大规模 TensorFlow 图中设备部署的优秀工作(Device Placement Optimization with Reinforcement Learning)。Salesforce 公司有自己的文本摘要模型,基本也可以工作。金融公司肯定正在尝试使用强化学习,但是目前还没有确凿的证据。Facebook 一直在用深度强化学习做一些聊天机器人和广告方面的优秀工作。每家互联网公司可能都考虑过将深度强化学习添加到它们的广告服务模型中,但是即使这么做了,他们也会对此守口如瓶。
我认为,要么深度强化学习仍然是一个研究课题,它不够鲁棒,所以没有广泛的应用,要么,深度强化学习已经可用了,并且使用深度强化学习的人没有公之于众。我认为前者更有可能。
如果是图像分类的问题,我会推荐预训练的 ImageNet 模型,它们很可能表现得更好。我们现在处于这么一个世界,硅谷的人们可以开发出一款 Not Hotdog 应用来开玩笑。然而我很难看到深度强化学习也有如此的盛况。
在目前的局限下,深度强化学习何时才能真正地工作呢?
很难说。尝试用强化学习解决一切的问题其实就是用同一个方法解几个特别不同的环境中的问题。不会总是成功的,这很自然。
尽管如此,我们还是可以从目前深度强化学习的成功案例得出一些结论。在这些项目中,深度强化学习要么学会了十分令人印象深刻的东西,要么它学会了相比以前的工作更好的东西。(诚然,这是非常主观的判断标准)
下面是我列出的清单:
之前所提及的:DQN、AlphaGo、AlphaZero、跑酷机器人、降低数据中心能耗的应用,以及使用神经架构搜索的 Auto ML。
OpenAI 的 Dota2 1v1 暗影恶魔机器人,它在简化版本的决斗环境中击败了顶级人类职业玩家(https://blog.openai.com/dota-2/)。
超级粉碎机器混战机器人(https://arxiv.org/abs/1702.06230),它在 1v1 的猎鹰 dittos 游戏中可以击败职业玩家。
顺便说一下:机器学习最近在无限注德州扑克中击败了专业玩家。Libratus(Brown et al, IJCAI 2017,https://www.ijcai.org/proceedings/2017/0772.pdf) 和 Deepstack(Moravčík,https://arxiv.org/abs/1701.01724)都完成了这样的壮举。我和一部分人交谈过,它们认为这项工作使用了深度强化学习技术。它们都很酷,但是它们并没有使用深度强化学习。而是使用了反事实后悔值最小化(CFR minimization)和巧妙的子游戏迭代求解。
我们可以从上面这个列表中发现一些让学习变得更加容易的共同属性。以下列出的属性都不是学习所必需的,但是更多地满足这些属性学习效果会更好。
生成近乎无限多的经验是很容易的。我们应该清楚为什么这是有帮助的。拥有的数据越多,学习问题就会变得越容易。这适用于 Atari 游戏、围棋游戏、象棋游戏、日本将棋游戏以及跑酷机器人的迷你环境。它也可能适用于电力中心的项目,因为之前 Gao 的工作已经显示:神经网络能以很高的准确率预测能源效率。这正是你想要为一个强化学习系统训练的模拟模型。它也可能适用于 Dota2 和 SSBN 的工作,但是它取决于游戏运行速度的吞吐量,以及有多少机器可以用来运行游戏。
问题被简化成了一个更简单的形式。我在深度强化学习中看到的一个常见的错误就是梦想过于庞大。总以为强化学习无所不能!但是这并不意味着可以立即达成一切。OpenAI 的 Dota2 机器人只玩早期的游戏,只在使用硬编码组件构建的 1v1 laning 环境中玩暗影恶魔和暗影恶魔的对抗,想必是为了避免感知问题而称其为 Dota2 API。虽然 SSBM 机器人实现了超越人类的性能,但是那仅仅是 1v1 的游戏,在无限时间的比赛中只有猎鹰队长在战场上。这不是在嘲讽任何一个机器人。你为何要在连一个简单问题都无法解决的时候就去解决一个艰难的问题呢?所有研究的广泛趋势都是先去证明最小的问题上的概念,然后再去泛化。OpenAI 在扩展他们在 Dota2 上的工作,当然也存在将 SSBN 上的工作扩展到其他角色上的工作。
也有可以将自我对抗引入到学习中的方式。这是 AlphaGo、AlphaZero、DOTA2 暗影狂魔机器人以及 SSBN 猎鹰机器人的组成部分。应当注意的是,我在这里所说的自我对抗指的是这样的游戏环境:游戏是竞争性的,两个玩家都可以被同一个智能体控制。目前,这样的环境似乎拥有最好的稳定性和最好的性能。
有一个简洁的方式来定义一个可学习的、不冒险的奖励函数。两个玩家的游戏有这样的特点:赢了得到+1 的奖励,输了得到-1 的奖励。Zoph 等人最早的文章有这样的奖励函数:验证已训练模型的准确率(neutral architecture search for reinforcement learning,ICLR,2017)。当你引入奖励函数重塑时,就可能学习了一个优化错误目标的非最优策略。如果你对如何拥有一个更好的奖励函数比较感兴趣,「proper scoring rule」是一个不错的检索词。至于可学习性,除了做实际尝试之外,我没有更好的建议。
如果必须对奖励函数进行重塑,那么它至少是结构较丰富的。在 Dota2 中,奖励可以来自于上次的命中(每个玩家杀死一只怪兽之后就会触发)和生命值(在每一次攻击或者技能命中目标之后就会触发)。这些奖励信号出现的很快而且很频繁。对 SSBN 机器人而言,可以对所造成的伤害给予奖励,这将为每次的攻击提供信号。行动和结果之间的延迟越短,反馈回路能够越快地闭合,强化学习就越容易找到回报更好的路径。
案例研究:神经架构搜索
我们可以结合一些原则来分析神经架构搜索的成功。从 ICLR 2017 中的原始版本论文中可以得知,在 12800 个样本之后,深度强化学习能够设计出最先进的神经网络架构。诚然,每个例子都需要训练一个神经网络以得到收敛,但是这仍然是非常有效的。
正如上面所提到的,其奖励函数是验证准确率。这是结构非常丰富的奖励信号——如果一个神经网络的设计决策将准确率仅仅从 70% 提高到了 71%,强化学习仍然可以从这一点上获得进展,此外,深度学习中的超参数接近线性无关。Hazan 等人在「Hyperparameter Optimization: A Spectral Approach」中进行了经验证明。神经架构搜索(NAS)并不是在调参数,但是我认为,神经网络设计决策是以类似的方式工作。这对学习来说是一个好消息,因为决策和性能之间的关联是很强的。
与其他环境中需要数百万个样本相比,以上这些要点的结合可以帮助我们理解为什么「仅仅」需要 12800 个训练好的神经网络就可以学习到一个更加好的网络架构。这个问题中的几个部分都在朝着强化学习倾斜。
总之,如此强大的成功案例仍然是一种例外,而不是必然的规则。深度强化学习现在还是不是拿来即用的技术。
展望未来
有这么一句话—每个研究人员都知道如何厌恶自己的研究领域。然而关键在于,尽管如此,大家还是会坚持下去,因为他们实在是太喜欢这些问题了。
这也是我对深度强化学习的大致感受。尽管我有所保留,但是我认为人们绝对应该将强化学习投入到不同的问题中去,包括那些可能不会成功的地方。那么我们还能怎样使强化学习变得更好呢?
给再多的时间,我也找不到深度强化学习无法工作的理由。当强化学习变得足够鲁棒和得到广泛应用的时候,一些十分有趣的事情就会发生。问题在于如何到达那一步。
我在下面列举出了一些比较合理的未来情况。对于基于进一步研究的未来,我已经引用了这些领域的相关研究论文。
局部最优已经足够好了:如果说人类在任何事情上都是最棒的,那可能有些傲慢。与其他物种相比,我想我们只是足够好的到达了文明阶段。同样的,强化学习解决方案也不必获得全局最优解,只要它的局部最优解能够比人类的基线好就行了。
硬件解决一切:我知道一些人觉得可以为人工智能做的最重要的事情就是简单地扩展硬件。我自己则对硬件解决一切持怀疑态度,但是硬件确实是很重要的。你的运行速度越快,就可以越少地关心采样低效,就可以更容易地暴力解决探索问题。
增加更多的学习信号:稀疏奖励函难以学习,因为你获得的帮助信息很少。我们要么误以为获得了正奖励(Hindsight Experience Replay),要么通过自我监督学习建立更好的世界模型(Reinforcement Learning with Unsupervised Auxiliary Tasks)。可以说是在蛋糕上增加了更多的樱桃。
基于模型的学习可以提高采样效率:这是我对基于模型的强化学习的描述,「大家都想做,但是没几个人知道如何做」。原则上,一个好的模型可以解决一系列的问题。就像我们在 AlphaGo 中看到的一样,拥有一个比较全面的模型使得学习解决方案变得更加容易。好的世界模型可以很好地迁移到新的任务上面,而世界模型的展开可以让你想象新的体验。据我所见,基于模型的方法使用的样本也比较少。
问题在于学习一个好模型是很困难的。在我的印象中,低维度的状态模型有时候会起作用,而图像模型则通常是比较困难的。但是,如果这个也变得很容易的话,一些有趣的事情就会发生。
Dyna 和 Dyna2 是这个领域中的经典论文。对于使用深度网络结合基于模型学习的论文而言,我想推荐一下最近伯克利机器人学实验室的一些论文:
Neutral Network Dynamics for Model-Based Deep RL with Model-Free Fine-Tuning
Supervised Visual Planning with Temporal Skip Connections
Combining Model-Based and Model-Free Updates for Trajectory-Centric Reinforcement Learning
Deep Spatial Autoencoders for Visuomotor Learning
End-to-End Training of Deep Visuomotor Policies
仅将强化学习用作微调步骤:第一篇 AlphaGo 论文从监督学习开始,然后在此基础上进行强化学习的微调。这是一个很好的方法,因为它可以让你使用一个更快但功能不太强大的方法来加速初始学习。还存在其他环境下的工作——参考《Sequence Tutor: Conservative Fine-Tuning of Sequence Generation Models with KL-control》。可以将此视为以合理的先验(而不是随机先验)开始强化学习过程,在这种情况下,学习先验的问题可以用其他方法求解。
奖励函数是可以学习的:机器学习的承诺是我们可以使用数据去学习到比人类设计更好的东西。如果奖励函数设计这般难,为什么不用它来学习到更好的奖励函数呢?模仿学习和逆强化学习都是成果很丰富的领域,它们已经展示了奖励函数可以通过人类的演绎或者评估来隐式地定义。
逆强化学习和模仿学习方面的著名论文有:
Algorithms for Inverse Reinforcement Learning
Apprenticeship Learning via Inverse Reinforcement Learning
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
关于最近将这些思想扩展到深度学习领域的工作,可以参考以下论文:
Guided Cost Learning: Deep Inverse Optimal Control via Policy Optimization
Time-Contrastive Networks: Self-Supervised Learning from Video
Learning from Human Preferences
其中,《Learning from Human Preferences》这篇论文表明,从人类评级中获得的奖励实际上比原来的硬编码奖励更适合于学习。
对于无需深度学习的长期研究,我更喜欢:
Inverse Reward Design
Learning Robot Objectives from Physical Human Interaction
迁移学习可以节省时间:迁移学习承诺可以利用之前任务中学习到的知识来加快新任务的学习。我认为这绝对是未来的希望,那时候任务学习已经足够鲁棒来解决多个不同的任务。如果根本学习不到任何东西,就很难进行迁移学习,给定了任务 A 和任务 B,就很难预测 A 是否迁移到了 B。根据我的经验,这要么是超级明显的,要么是很不清楚的,即便是超级明显的情况,也不会是很普通的工作。
这个方向上有三篇最近的论文:
Universal Value Function Approximators
Distral: Robust Multitask Reinforcement Learning
Enabling Continual Learning in Neural Networks
而比较早期的工作可以考虑一下 Horde:
Horde: A Scalable Real-time Architecture for Learning Knowledge from Unsupervised Sensorimotor Interaction
机器人学特别是在从仿真向真实的转移方面的进展(仿真版本的任务和真实版本任务之间的迁移),参见:
Spam Detection in the Physical World
Sim-to-Real Robot Learning from Pixels with Progressive Nets
Closing the Simulation-to-Reality Gap for Deep Robotic Learning
好的先验知识会大大缩短学习时间:这与前面的几点息息相关。有一种观点:迁移学习是使用过去的经验来构建较好的学习其他任务所需的先验知识。强化学习算法被设计适用于任何马尔科夫决策过程,这才是泛化性的痛点来源。如果承认我们的解决方案只能在一小部分环境中运行良好,我们就能够以一种有效的方式利用共享结构来解决这些问题。
Pieter Abbeel 在他的演讲中喜欢提到的一点是:深度强化学习只需要解决我们在现实生活中需要解决的任务。我赞同这个观点。应该有一个现实世界的先验知识,让我们能够快速学习新的现实世界的任务,代价是在非现实的任务上学习更慢,但这是一个完全可以接受的权衡。
困难在于设计这样的一个现实世界先验知识是很难的。然而,我认为不是不可能的。就我个人而言,我对最近在元学习方面的工作感到兴奋,因为它提供了一种数据驱动的方法来生成合理的先验知识。例如,如果我想使用强化学习进行仓库导航,我会非常好奇如何使用元学习事先学习一个好的导航,然后针对机器人将要部署到的特定仓库对这个先验知识进行微调。这看起来很有希望,问题是元学习能否实现。
BAIR 在这篇文章中总结了最近的「学习到学习」方面的工作:http://bair.berkeley.edu/blog/2017/07/18/learning-to-learn/(参阅:学界 | 与模型无关的元学习,UC Berkeley提出一种可推广到各类任务的元学习方法)。
更困难的环境可能会使问题变得更容易:DeepMind 的跑酷论文给我们的最大的教训就是:如果可以通过增加一些任务变体使得任务变得非常困难,实际上你可以使学习变得更加容易,因为策略不能在不损失所有其他环境中的性能的情况下过拟合任何一个环境。在域随机化的论文中,甚至在 ImageNet 中,我们也看到了类似的情况:在 ImageNet 上训练的模型比在 CIFAR - 100 上训练的模型更具泛化性。正如我前面提到的,也许我们只是一个「受控的 ImageNet」,而远没有使强化学习更通用。
环境方面倒是有很多选择。OpenAI Gym 非常具有吸引力,当然也有街机学习环境(Arcade Learning Environment)、机器人学习环境(Roboschool)、DeepMind Lab、DeepMind 控制组件(DeepMind Control Suite),以及 ELF。
最后,尽管从研究的角度来看还是不尽如人意,但是深度强化学习的经验问题或许对实际目的来说不是很重要的。作为一个假设的例子,假设一家金融公司正在使用深度强化学习。基于美国股市过去的数据,他们使用三个随机数种子训练了一个智能体。在实时的 A/B 测试中,一个给出了 2% 的收益减少,第二个和第一个表现相同,第三个带来了 2% 的收入增益。在这种假设下,再现性并不重要,你大可以部署那个带来 2% 收入增益的模型,并准备庆祝。同样地,交易智能体可能只在美国表现良好,这也没关系——如果它在全球市场泛化得不好,就不要在那里部署它。在做一些非凡的事情和让非凡的成功重现之间有很大的差距,也许值得把注意力集中在前者。
我们现在的处境
从很多方面来说,我发现自己对深度强化学习的现状感到恼火。然而,它吸引了一些我所见过的最强烈的研究兴趣。我的感受最能概括为吴恩达在他的演讲《Nuts and Bolts of Applying Deep Learning》中所说的:短期悲观,长期乐观。深度强化学习目前还有些混乱,但是我仍然相信它可以成功。
话虽如此,下次有人问我强化学习能否解决他们的问题,我还是要告诉他们,不行,不行。但我也会告诉他们几年后再问我。到那时,也许可以。

(原文视频较多,微信文章无法一一展现,全部视频请参见原文链接)
原文链接:https://www.alexirpan.com/2018/02/14/rl-hard.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



