一文读懂 Netflix 的推荐探索策略 Contextual Bandits

作者 | 张相於
为了文章的简洁性,本文省略了大量原文的文字和图片,只保留了笔者认为比较核心的内容,对原文有兴趣的同学欢迎点击「阅读原文」。
这篇文章讲述了Netflix对用户看到的视频封面进行个性化筛选的方法,但更具有普适性意义的是以此案例为载体的contextual bandit exploration方法,以及基于replay的离线效果无偏评估方法。
What & Why
本文要解决的核心问题是在Netflix的推荐系统中,为给用户推荐的每部剧集选择不同的封面图片,以提高用户的点击和观看时长。为什么需要将展示图片做个性化呢?因为剧集的题目很多时候并不足以给出足够的信息,以吸引用户的观看,而如果图片能够投其所好的话,则可以提高用户感兴趣的概率。有的用户喜欢某个演员,那么在剧集图片里展示该演员的剧照会更有效;有的演员喜欢喜剧,那么通过图片来告诉用户这是一部喜剧,则更有可能吸引用户;此外,不同用户可能有着不同的审美,那么对其展示更符合其审美的图片也会有更好的效果。
Challenges
第一个挑战,在于每个剧集只能展示一张图片,如果用户点击并观看了这部剧集,我们并不能确认是因为图片选得好起了作用,还是用户无论如何都会观看这部剧集。用户没有点击的情况也是类似。所以第一个要解决的问题时如何正确地对结果进行归因,对于确定算法的好坏至关重要。
第二个挑战,在于正确理解session之间切换展示图片的影响。所谓切换,指的是用户第一次看到这个剧集时使用的是图片A,后面经过算法学习,在第二次看到时使用了图片B。这种做法是好还是坏呢?坏的一面在于,图片切换不利于用户定位剧集,下次看到时会以为是不同的剧集。而好的一面在于,优化后的图片展示可能会导致对用户产生更大的吸引力。显然我们如果能找到更好的图片的话是会起到正面作用的,但是频繁地切换也会让用户困惑,还会导致无法正确地将用户的点击和观看进行归因。
第三个挑战,在于理解一副封面图和同一页面或同一session中其他封面图和展示元素之间的关系。一张包含主角大幅特写的图片可能会非常吸引人,因为这可以使得该图片脱颖而出。但如果整个页面中都是这样的图片,这个页面作为一个整体就不那么吸引人了。此外,封面图的效果可能和故事梗概和预告片的效果也紧密相关。所以候选图片需要能够涵盖该剧集吸引用户的多个方面。
第四个挑战,是每个剧集都需要一组优秀的候选图片。这些图片要有信息量和吸引力,同时还要避免成为“clickbait[1]”。同时这组图片还要有足够的差异化,能够覆盖不同喜好和审美的人。设计师不仅要考虑以上因素,同时还要考虑图片推荐的个性化算法,毕竟他们创作出来的图片是通过这些算法推送到用户面前的。
最后一个挑战,就是大规模工程化的挑战。Netflix面临的是千万级每秒级别的请求,这个量级上图片的实时渲染非常有挑战,也对算法的实时性提出了挑战。同时算法还需要适应用户和剧集的不断演化。
Contextual bandits approach
经典的策略升级采用的是基于ABTest的方法,简单来说,就是离线训练新算法,上线ABTest和老算法进行比较,如果效果优于老算法,则将新算法全量切换。这种方法有个问题,就是会导致regret[2]:长时间内很多用户都无法享受到新算法的更好体验。这个过程如下图所示:
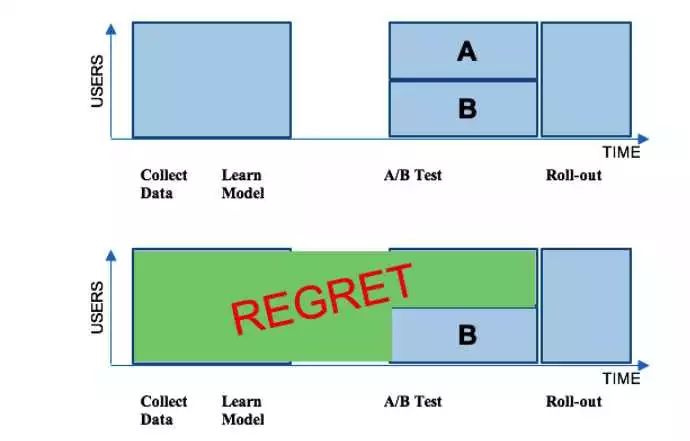
上图中绿色标了REGRET的用户和流量,都无法享技术,这种技术的核心优势在于可以无偏地对算法效果进行离d线衡量,使得算法在上线abtest之前就可以对其效果有了解。具体做法如下图所示:,使用的是Contextual bandits框架。Contextual bandits不是一个具体的算法,而是一类算法框架。在这种框架下,模型会快速学习到每个用户的图片偏好。Contextual bandits的做法简单来讲就是用线上一部分流量来实时收集样本 ,然后实时训练,然后将实时训练更新的模型应用到该用户身上。简单来讲,Contextual bandits牺牲了收集足够数据以及训练出的无偏模型,换来了可以对每个用户生效的实时更新模型。
Contextual bandits的核心目标是要最小化regret。其本质就是通过可控随机注入来获取训练数据。具体的随机策略可以根据数据的数据规模来确定。这个过程也就是数据探索(data exploration)的过程,也就是传说中ee中的一个e。在这种探索策略下,我们需要尽可能详细地记录日志,这些日志不仅可以用来训练实时模型,还可以用来在离线做无偏的效果评估。
数据探索是有代价的,那就是用户的一部分展示没有使用我们预测的最优结果,而是使用了随机结果,也就是regret,这样做的影响是什么呢?如果整体用户量达到千万级以上的话,这种regret平均到每个用户其实是很小的,同时这些用户还为整体提供了训练数据,所以这种代价是完全可以接受的。但如果数据探索的代价比较大的话,这种随机和探索策略可能就不太合适了。
此外,在这个过程中还需要控制用户在同一剧集中看到图片的变化频率,以及仔细控制标注数据的质量,以免引起clickbait。
模型训练
模型训练中值得一提的是,作者将“为每个用户的不同剧集的候选图片分别排序”问题简化为“为每个用户的所有候选图片整体排序”。这样学习起来更简单,同时也能够学习到足够的信息。具体学习方法可适用有监督学习、汤普森采样或者LinUCB等等。我们的公众号上也介绍过相关算法,点击“阅读原文”了解。
潜在信号
所谓信号也就是特征,值得一提的是除了图片本身的特征,例如风格和用户历史记录等,作者还将剧集推荐算法中与图片无关的特征加了进去一起训练。
效果评测
在衡量效果方面使用了基于日志的replay[3]技术,这种技术的核心优势在于可以无偏地对算法效果进行离线衡量,使得算法在上线abtest之前就可以对其效果有了解。具体做法如下图所示:

这种做法的流程如下:
在线上留出部分随机流量,对这些流量展现随机结果,而不是算法计算出来的结果,在这个场景下,就是展现一个剧集的随机封面。这是整个环节中最重要的一环,也是保证评测无偏的基础。(这里的偏指的是什么?留给读者想一想)。
离线评测时,计算出新算法的推荐结果,并在1中的日志里寻找推荐结果与新算法结果一致的数据,也就是上图中的用户1、2和4,然后计算这个集合中用户的点击率,上图中也就是2/3。
这种做法可以让我们得知如果线上展现的是新算法的结果的话,用户会如何反馈,是点击还是不点击。下图展示了不同bandit算法的效果:
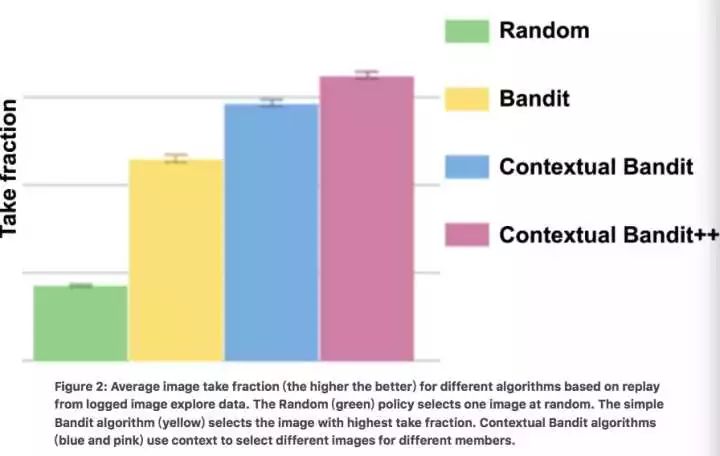
下图是一个具体的例子:

线上表现
与离线评估一致,算法上线后确实表现出了明显的提升,同时作者也观察到了在replay技术下离线指标的提升和线上指标提升之间是存在相关性的。同时也观察到了一些有趣的事实,例如对于那些用户之前没展示过的剧集提升要更大,这是因为该算法对于用户不了解剧集的情况更有效。
总结
这个工作是Netflix对于“如何推荐”而不仅是“推荐什么”的第一次尝试,在此之后还有很多可做的工作,例如对于冷启动图片和剧集的处理,对于其他UI层面元素的个性化,甚至帮助设计是设计出更加有吸引力和个性化的图片。
clickbait从字面上可理解为钓鱼图片,指的是用和内容关系不大但吸引人的图片吸引用户点击,但用户点击后常常会很快跳出。典型的如一些新闻客户端上的标题党。
这个场景下的regret是bandit问题中一个概念,指的是由于没有利用到最好的结果而造成的损失,例如为了探索中奖率更高的老虎机而没有选择当前已知中奖概率最大的老虎机,这种行为造成的可能的损失,叫做regret。
L. Li, W. Chu, J. Langford, and X. Wang, “Unbiased Offline Evaluation of Contextual-bandit-based News Article Recommendation Algorithms,” in Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, New York, NY, USA, 2011, pp. 297–306.
本文作者:张相於(zhangxy@live.com),现任转转推荐系统负责人,负责转转的推荐系统。他正在招推荐算法和推荐架构工程师,负责转转推荐系统和机器学习系统的构建和持续优化。转转目前业务发展飞快,技术挑战巨大,有志青年请邮件发送简历联系。
原文链接:https://medium.com/netflix-techblog/

CSDN AI热衷分享 欢迎扫码关注



