AAAI 2020上的NLP有哪些研究风向?

作者 | Camel
编辑 | 十、年
(一)
(1) Modeling Fluency and Faithfulness for Diverse Neural Machine Translation
(2) Minimizing the Bag-of-Ngrams Difference for Non-Autoregressive Neural Machine Translation
在本届AAAI会议上,冯洋实验组有两篇论文入选。其中一篇工作(汇报人:谢婉莹)是在神经机器翻译模型中引入了一个评估模块,对生成的译文从流利度和忠实度两个方面进行评估,并用得到的评估分数用来指导训练阶段译文的概率分布,而在测试的时候,可以完全抛弃该评估模块,采用传统的Transformer模型进行解码。另一篇文章(汇报人:邵晨泽)提出了一个基于模型与参考译文间n元组袋差异的训练目标,并用该训练目标来训练非自回归模型。实验表明,该训练目标与翻译质量相关性强,对翻译效果有大幅提升。
(3) Neural Machine Translation with Joint Representation
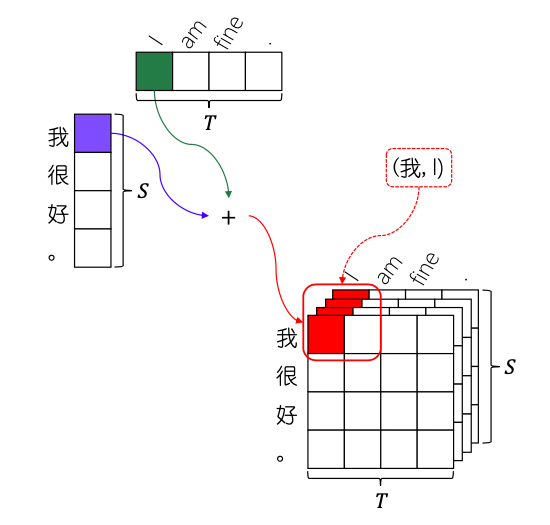
(4) Task-Oriented Dialog Systems that Consider Multiple Appropriate Responses under the Same Context
张亦驰的工作主要研究了任务型对话中的一对多问题,为解决对话数据集中的可行系统动作分布不平衡,他提出了一种基于多动作数据增强的学习框架,可以有效学习到多样化的对话策略。
(5) A pre-training based personalized dialogue generation model with persona-sparse data
黄民烈教授是国内在对话系统方面做得非常优秀的一位学者,其工作曾获得IJCAI-ECAI 2018杰出论文奖、CCL 2018最佳系统展示奖。其博士后郑银河在文章中的主要工作是一个个性化对话生成模型,该模型使用了一种名叫注意力路由的机制,在训练的过程中可以使用个性化稀疏的对话数据,并且可以在生成的时候控制回复中所展现的个性化属性。
(6) Synchronous Speech Recognition and Speech-to-Text Translation with Interactive Decoding
自动化所刘宇宸等人的工作集中在语音识别和语音翻译任务上,他们提出了一种基于交互是学习的方法,能够在一个模型中实现同步语音识别和语音翻译任务,且能够同时提升两个任务的效果。
(7) SPARQA: Skeleton-based Semantic Parsing for Complex Questions over Knowledge Bases
南京大学孙亚伟的工作是聚焦在知识问答任务中的复杂问句上。他提出了一种复杂问句求解的方法,包括提出一种Skeleton表示和解析方法,以及一种多粒度(句子级和单词级)匹配方法。
(8) Knowledge Graph Grounded Goal Planning for Open-Domain Conversation Generation
事实上来自哈工大的徐俊(导师:车万翔)的工作也是关于对话(开放域对话生成),在其工作中,他们将目标管理引入到闲聊当中,其结果就是能够获得更连贯且更具吸引力的多轮对话。
(二)
(11) Towards Building a Multilingual Sememe Knowledge Base: Predicting Sememes for BabelNet Synsets
来自北邮的常亮博士生在刘知远实验组实习期间,做了构建多语言义原知识库的工作,即利用BabelNet Synset进行义原预测从而帮助义原知识库的构建。这项工作也是刘知远老师整个大项目中的一部分。
(9) Multi-Scale Self-Attention for Text Classification
复旦大学的NLP团队也是国内顶尖团队之一,邱锡鹏教授更是为大家所熟知。他们与亚马逊上海AI实验室合作发表的文章主要工作是文本分类(汇报人:郭琦鹏)。他们认为对于语言的理解,无论是大尺度还是小尺度都是重要,为此他们提出了多尺度自注意力的方法,结果优于单一尺度的方法。
(10) Learning Multi-level Dependencies for Robust Word Recognition
这个Session的第三个报告来自“好未来AI LAB”(汇报人:许国伟),这也是所有 34 个报告中唯二来自业界的报告。他们的工作主要是为了提高对错字的识别和纠正。

(12) Cross-Lingual Low-Resource Set-to-Description Retrieval for Global E-Commerce (13) Integrating Relation Constraints with Neural Relation Extractors
北大王选计算所这次也入选多篇论文。来自赵东岩/严睿实验组的博士生刘畅的研究工作是针对全球电子商务的跨语言、低资源、集合到描述的检索任务;而博士生叶元则提出了一个可以集成关系约束信息和神经关系抽取器的框架,该框架通过一个额外的损失函数使得神经关系抽取器能够学习到关系约束中蕴含的知识,从而提升关系抽取的性能。
(14) Capturing Sentence Relations for Answer Sentence Selection with Multi-Perspective Graph Encoding
来自中科院自动化所的田志兴,针对答案句选择任务中候选句间存在信息依赖的问题,提出了一种基于多视角图编码的方法,从而来捕获候选句之间的关系。
(15) Replicate, Walk, and Stop on Syntax: an Effective Neural Network Model for Aspect-Level Sentiment Classification
来自北航的郑耀威的研究也是与义原有关。他在依存树中引入了随机游走的方法,通过激活树的边给关键词更大的权重,用语法信息增强了多方面情感分类的效果。
(16) Cross-Lingual Natural Language Generation via Pre-Training
迟泽闻来自北理工黄河燕教授的团队,他的工作主要是通过预训练来进行跨语言的自然语言生成。
(17) Hyperbolic Interaction Model For Hierarchical Multi-Label Classification
对于知识理解,来自北京交通大学的陈博理提出了一个分级多标签分类的双曲交互模型。他在双曲线空间中对具有层级结构的标签进行文本分类,将标签映射到双曲线空间,对比欧式空间,可以更好地保留标签之间的关系。方法非常新颖。
(18) Multi-channel Reverse Dictionary Model
来自清华刘知远团队的岂凡超提出了一种多通道反向词典模型。所谓反向词典,即给定对某个词语的描述,希望得到符合给定描述的词语。岂凡超提出了一种受到人的描述→词的推断过程启发的多通道模型,这个模型在中英两种语言的数据集上都实现了当前最佳性能(state-of-the-art),甚至超过了最流行的商业反向词典系统。此外,基于该文提出的模型,论文作者还开发了在线反向词典系统,包含首次实现的中文、中英跨语言反向查词功能。
(19) Discovering New Intents via Constrained Deep Adaptive Clustering with Cluster Refinement
同样来自清华的林廷恩提出基于深度约束聚类的对话新意图发现。这项工作主要做端到端的约束聚类,融入少量带label的标注数据来提升性能,并透过消除低置信度分配来提升鲁棒性。
(20) Logo-2K+: A Large-Scale Logo Dataset for Scalable Logo Classification
来自山东师范大学的王静在计算所实习期间,构建了一个大型的且完备的logo数据集Logo-2K+,基于这个数据集,她提出了一个判别性的区域引导和增强网络,来二次定位关键区域,并将区域特征和全局特征进行融合,来做最终的类别预测。
(21) DMRM: A Dual-channel Multi-hop Reasoning Model for Visual Dialog
自动化所的陈飞龙针对视觉对话任务提出了一种双通道多跳推理模型。这个模型解决了视觉对话的多模态交互过程中往往会忽略信息的隐含关系以及原始表示的问题。
(22) DualVD: An Adaptive Dual Encoding Model for Deep Visual Understanding in Visual Dialogue
北航的蒋萧泽所做的工作也是视觉对话。他针对视觉对话中设计的图像内容范围广、多视角理解困难的问题,提出一种用于刻画图像视觉和语义信息的自适应双向编码模型——DualVD,从视觉目标、视觉关系、高层语义等多层面信息中自适应捕获回答问题的依据,同时通过可视化结果揭示不同信息源对于回答问题的贡献,具有较强的可解释性。
(23) Storytelling from an Image Stream Using Scene Graphs
复旦大学的王瑞泽是黄萱菁教授的博士生,他的工作是关于多模态文本生成,即利用场景图针对图像序列进行故事生成。王瑞泽在报告中认为将图像转为图结构的表示方法(如场景图),然后通过图网络在图像内和跨图像两个层面上进行关系推理,将有助于表示图像,并最终有利于描述图像。实验结果证明了这种方法可以显著提高故事生成的质量。
(24) Draft and Edit: Automatic Storytelling Through Multi-Pass Hierarchical Conditional Variational Autoencoder
另外一篇关于故事生成的文章来自北大严睿团队,一作为于孟萱。她在论文中提出了结合Hierarchical CVAE 模型以及Multi-pass generation mechanism的方法,用这种方法来做故事生成,可以提升生成故事内容的一致性及多样性。
(四)
(25) Learning Sparse Sharing Architectures for Multiple Tasks
在这个部分,首个报告来自复旦大学孙天祥(导师也是黄萱菁教授)。这篇文章提出了一种新的参数共享机制:稀疏共享。这种共享机制能够同时解决目前主流的三种共享机制(硬共享、软共享、分层共享)的限制问题。目前这篇文章已经开源。
(26) Reinforcement Learning from Imperfect Demonstrations under Soft Expert Guidance
个人认为在所有报告中,清华大学荆明轩的presentation是做的最好的,无论是slide,还是讲解都干净利落,当然工作也很好。他这项工作通过引入示教样本作为约束,从而来提高强化学习和模仿学习在稀疏回报函数下的训练效率,并保持了在低质量示教下策略的最优性。
(27) Shapley Q-value: A Local Reward Approach to Solve Global Reward Games
北京来也公司的张原通过考虑游戏中的状态和动作,将Shapley值(即凸游戏中的信用分配方法)扩展为Shapley Q-值,并利用Shapley Q-值将信用分配给全局奖励游戏中的每个代理商,同时还根据Shapley Q-值提出了一种称为SQDDPG的算法。
(28) Measuring and relieving the over-smoothing problem in graph neural networks from the topological view
博士生陈德里来自北大计算语言所孙栩教授门下,他们从拓扑学的视角,针对图神经网络中的over-smoothing问题进行系统且定量的研究。报告中陈德里表示,影响over-smoothing的关键在于结点的信噪比,而图的拓扑结构恰恰会影响信噪比。于是他们从图的拓扑关系出发,设计了两个不依赖于gold lable的指标MAD和MADGap,分别用来衡量图网络学习到的节点表示的smoothing以及over-smoothing程度。
(29) Neighborhood Cognition Consistent Multi-Agent Reinforcement Learning
随后来自北大的毛航宇介绍了一项由北大、华为(诺亚方舟实验室)等单位合作的一项关于多智能体强化学习的工作。这项工作受启于社会心理学中的“认知一致性”对维持人类社会秩序的作用,即如果人们对环境的认知更加一致,他们就更有可能实现更好的合作。由此他们提出“邻域认知一致性”,并将其引入多智能体强化学习当中。
(30) Neural Snowball for Few-Shot Relation Learning
来自清华的高天宇是刘知远副教授的学生,他的工作聚焦在关系抽取。目前的关系抽取,面临着开放式的关系增长问题,目前已有有监督、半监督、少次学习和自启动关系抽取,这些方法涉及到了三种类型的数据:在已有关系类型上的大规模监督数据,对于新关系的少量标注数据,以及大规模的无监督数据。高天宇等人提出Neural Snowball,充分利用了这三种数据,进行关系抽取。
(31) Multi-Task Self-Supervised Learning for Disfluency Detection
哈工大王少磊也是车万翔教授的学生,在他的工作中主要利用多任务、自监督学习来检测文本中的套话。他们提出了两种模型,实验结果验证他们只需要1%的训练数据就可以达到与之前工作相同的性能。
(32) Constructing Multiple Tasks for Augmentation: Improving Neural Image Classification With K-means Features
复旦大学卿立之来自黄萱菁教授团队。他的工作围绕图像分类,通过无监督聚类的方式,在图像分类上为单任务构造了辅助任务,并利用新设计的一套元学习算法进行多任务训练,从而提高了图像分类的效果。
(33) Graph-propagation based correlation learning for fine-grained image classification
大连理工大学的王世杰工作的内容是关于细粒度图像识别。在该任务中,他们提出了使用图的方式(据他表示,这也是第一个提出)来挖掘区域间的关系并引入局部空间上下文,从而来进一步强化判别性特征。
(34) End-to-End Bootstrapping Neural Network for Entity Set Expansion
同样是第一个提出,中科院软件所颜令勇(来自孙乐、韩先培团队)在实体集合拓展中,第一个提出了端到端的bootstrapping网络,并利用多视角学习进行有效学习。
最后的话……
附 34 篇文章列表








