干货 | 马蜂窝数据被扒光, 用 Python 爬取网页信息 4 分钟就能搞定

本文为 AI 研习社编译的技术博客,原标题 :
How to Web Scrape with Python in 4 Minutes
翻译 | M.Y. Li 校对 | 就2 整理 | 菠萝妹
原文链接:
https://towardsdatascience.com/how-to-web-scrape-with-python-in-4-minutes-bc49186a8460

图片来自https://www.freestock.com/free-photos/illustration-english-window-blue-sky-clouds-41409346
网页抓取是一种自动访问网站并提取大量信息的技术,这可以节省大量的时间和精力。在本文中我们将通过一个简单的示例来说明如何自动从New York MTA下载数百个文件。对于希望了解如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能会有点复杂,因此本教程将分解步骤进行教学。
New York MTA 数据
我们将从这个网站下载有关纽约公共交通地铁站旋转门的数据:
http://web.mta.info/developers/turnstile.html
从2010年5月至今,这些旋转门的数据被按周汇总,因此网站上存在数百个.txt文件。下面是一些数据片段,每个日期都是可供下载的.txt文件的链接。
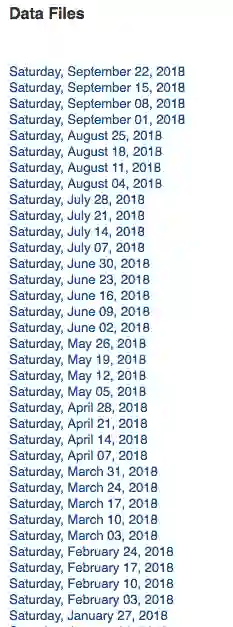
手动右键单击每个链接并保存到本地会很费力,幸运的是我们有网页抓取!
有关网页抓取的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站禁止您将数据用于商业目的。
2. 确保您没有以过快的速度下载数据,因为这可能导致网站崩溃,您也可能被阻止访问该网络。
检查网站
我们需要做的第一件事是弄清楚如何从多级HTML标记中找到我们想要下载的文件的链接。简而言之,网站页面有大量代码,我们希望找到包含我们需要数据的相关代码片段。如果你不熟悉HTML标记,请参阅W3schools教程。为了成功进行网页抓取,了解HTML的基础知识很重要。
在网页上单击右键,并点击”检查”,这允许您查看该站点的原始代码。
点击”检查”后,您应该会看到此控制台弹出。
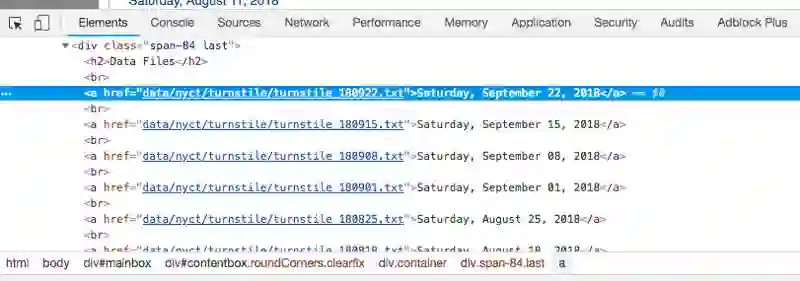
控制台
请注意,在控制台的左上角有一个箭头符号。

如果单击此箭头然后点击网站本身的某个区域,则控制台将高亮显示该特定项目的代码。我点击了第一个数据文件,即2018年9月22日星期六,控制台高亮了该特定文件的链接。
<a href=”data/nyct/turnstile/turnstile_180922.txt”>Saturday, September 22, 2018</a>
请注意,所有的.txt文件都在
上一行的标记之内。当你做了更多的网页抓取后,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
接下来,我们将url设置为目标网站,并使用我们的请求库访问该站点。
url = ‘
response = requests.get(url)
如果访问成功,您应该能看到以下输出:

接下来,我们使用html嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看BeautifulSoup文档。
soup = BeautifulSoup(response.text, “html.parser”)
我们使用方法.findAll来定位我们所有的
<a>
标记。
soup.findAll('a')
这段代码为我们找到了了所有含有
<a>
标记的代码段。我们感兴趣的信息从第36行开始。并非所有的链接都是我们想要的,但大部分是,所以我们可以轻松地从第36行分开。以下是当我们输入上述代码后BeautifulSoup返回给我们的部分信息。

所有<a>标记的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = soup.findAll(‘a’)[36]
link = one_a_tag[‘href’]
此代码将'data/nyct/turnstile/turnstile_le_180922.txt保存到我们的变量链接中。 下载数据的完整网址实际上是 “http://web.mta.info/developers/data/nyct/turnstile/turnstile_180922.txt”,我通过点击网站上的第一个数据文件作为测试发现了这一点。我们可以使用urllib.request库将此文库将此文件路径下载到我们的计算机。 我们给request.urlretrieve提供ve提供两个参数:文件url和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”,“t”,“turnstile_180901”等。
download_url = ‘http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,’./’+link[link.find(‘/turnstile_’)+1:])
最后但同样重要的是,我们应该包含以下一行代码,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向网站发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者。
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用网站抓取旋转栅门数据的全套代码。
# Import libraries
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
# Set the URL you want to webscrape from
url = 'http://web.mta.info/developers/turnstile.html'
# Connect to the URL
response = requests.get(url)
# Parse HTML and save to BeautifulSoup object¶
soup = BeautifulSoup(response.text, "html.parser")
# To download the whole data set, let's do a for loop through all a tags
for i in range(36,len(soup.findAll('a'))+1): #'a' tags are for links
one_a_tag = soup.findAll('a')[i]
link = one_a_tag['href']
download_url = 'http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1) #pause the code for a sec
你可以在我的Github上找到我的Jupyter笔记。感谢阅读,如果您喜欢这篇文章,请尽量多多点击Clap按钮。
祝你网页抓取的开心!
想要继续查看该篇文章相关链接和参考文献?
戳链接:
http://www.gair.link/page/TextTranslation/1120
AI研习社每日更新精彩内容,点击文末【阅读原文】即可观看更多精彩内容:
良心推荐:一份 20 周学习计算机科学的经验贴(附资源)
多目标追踪器:用OpenCV实现多目标追踪(C++/Python)
为计算机视觉生成大的、合成的、带标注的、逼真的数据集
悼念保罗·艾伦,除了他科技圈还有哪些大佬值得信仰?
等你来译:
深度网络揭秘之防止过拟合
有关活动识别的新数据集
用Excel来阐释什么是多层卷积
如何开发多步空气污染时间序列预测的自回归预测模型
号外号外~
想要获取更多AI领域相关学习资源,可以访问AI研习社资源板块下载,
所有资源目前一律限时免费,欢迎大家前往社区资源中心
http://www.gair.link/page/resources 下载喔~
全球AI+智适应教育峰会
免费门票开放申请!
雷锋网联合乂学教育松鼠AI以及IEEE教育工程和自适应教育标准工作组,于11月15日在北京嘉里中心举办全球AI+智适应教育峰会。美国三院院士、机器学习泰斗Michael Jordan、机器学习之父Tom Mitchell已确认出席,带你揭秘AI智适应教育的现在和未来。
扫码免费注册





