程序猿找工作第一步——Scrapy爬招聘信息(完整代码)
作者:jtahstu
http://www.jtahstu.com/blog/scrapy_zhipin_spider.html
开发环境
MacBook Pro (13-inch, 2016, Two Thunderbolt 3 ports)
CPU : 2 GHz Intel Core i5
RAM : 8 GB 1867 MHz LPDDR3
Python : Python 3.6.3 [GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
MongoDB : v3.4.7
MongoDB Tool :MongoBooster v4.1.3
准备工作
安装 Scrapy
pip3 install scrapy参考翻译文档的安装教程:http://scrapy-chs.readthedocs.io/zh_CN/latest/intro/install.html
官方 GitHub 地址:https://github.com/scrapy/scrapy
新建项目
scrapy startproject www_zhipin_com定义要抓取的 Item
在items.py 文件中定义一个类
class WwwZhipinComItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pid = scrapy.Field()
positionName = scrapy.Field()
positionLables = scrapy.Field()
workYear = scrapy.Field()
salary = scrapy.Field()
city = scrapy.Field()
education = scrapy.Field()
companyShortName = scrapy.Field()
industryField = scrapy.Field()
financeStage = scrapy.Field()
companySize = scrapy.Field()
time = scrapy.Field()
updated_at = scrapy.Field()分析页面
一般一条招聘像下面这样
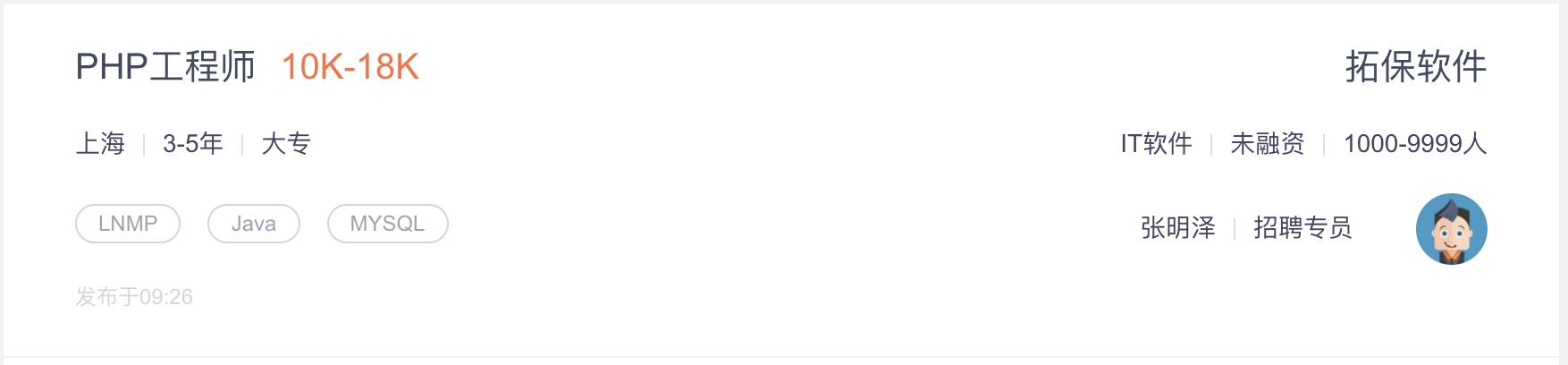
html 结构如下
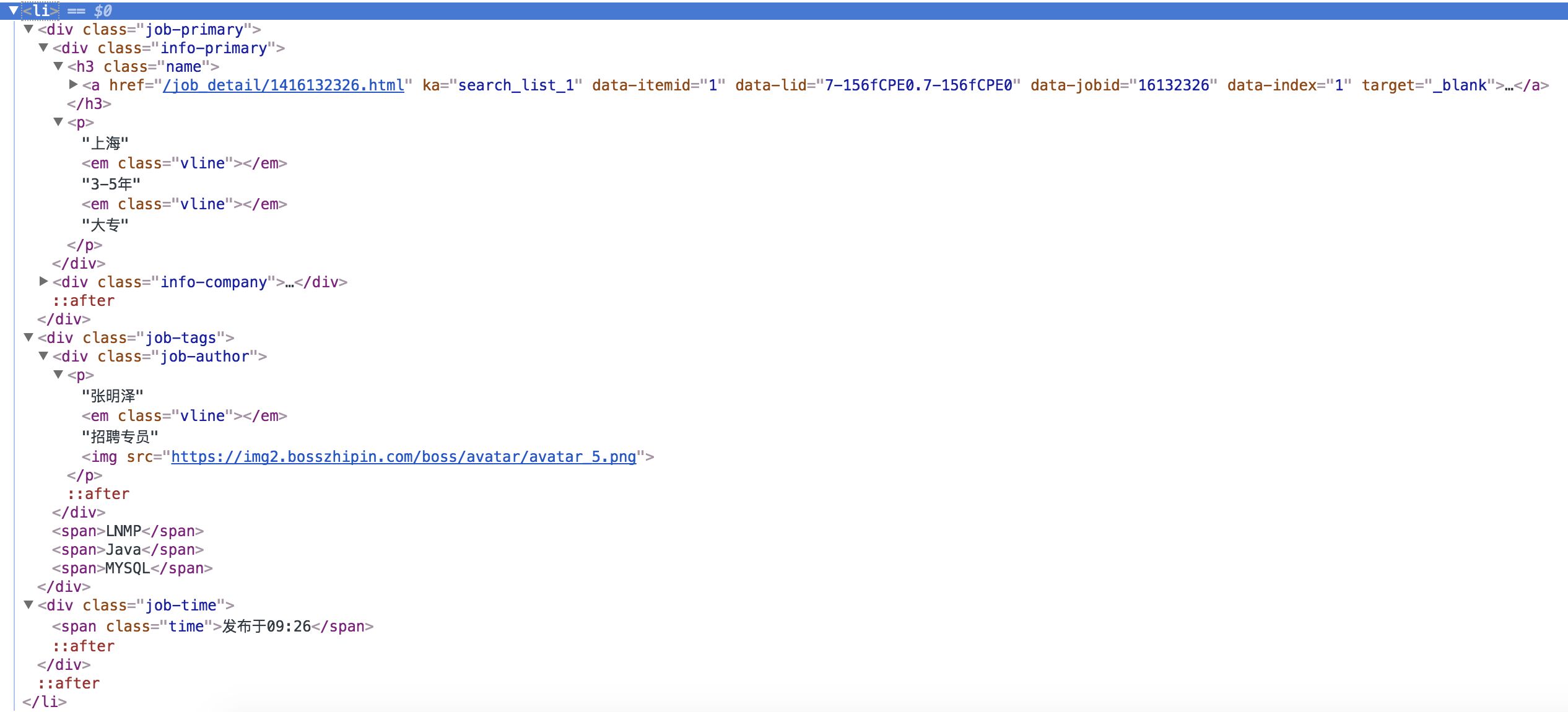
爬虫中就是使用 css 选择器获取标签里的文字或链接等
爬虫代码
在 spiders 目录下新建 zhipin_spider.py
# -*- coding: utf-8 -*-
import scrapy
import timefrom www_zhipin_com.items import WwwZhipinComItem
class ZhipinSpider(scrapy.Spider):
# spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。 不过您可以生成多个相同的spider实例(instance),这没有任何限制。 name是spider最重要的属性,而且是必须的
name = 'zhipin'
# 可选。包含了spider允许爬取的域名(domain)列表(list)。 当 OffsiteMiddleware 启用时, 域名不在列表中的URL不会被跟进。
allowed_domains = ['www.zhipin.com']
# URL列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。
# 这里我们进行了指定,所以不是从这个 URL 列表里爬取
start_urls = ['http://www.zhipin.com/']
# 要爬取的页面,可以改为自己需要搜的条件,这里搜的是 上海-PHP,其他条件都是不限
positionUrl = 'http://www.zhipin.com/c101020100/h_101020100/?query=php'
curPage = 1
# 发送 header,伪装为浏览器
headers = {
'x-devtools-emulate-network-conditions-client-id': "5f2fc4da-c727-43c0-aad4-37fce8e3ff39",
'upgrade-insecure-requests': "1",
'user-agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36",
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
'dnt': "1",
'accept-encoding': "gzip, deflate",
'accept-language': "zh-CN,zh;q=0.8,en;q=0.6",
'cookie': "__c=1501326829; lastCity=101020100; __g=-; __l=r=https%3A%2F%2Fwww.google.com.hk%2F&l=%2F; __a=38940428.1501326829..1501326829.20.1.20.20; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1501326839; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1502948718; __c=1501326829; lastCity=101020100; __g=-; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1501326839; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1502954829; __l=r=https%3A%2F%2Fwww.google.com.hk%2F&l=%2F; __a=38940428.1501326829..1501326829.21.1.21.21",
'cache-control': "no-cache",
'postman-token': "76554687-c4df-0c17-7cc0-5bf3845c9831"
}
//该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取的第一个Request。
//该方法仅仅会被Scrapy调用一次,因此您可以将其实现为生成器。
def start_requests(self):
return [self.next_request()]
//负责处理response并返回处理的数据以及(/或)跟进的URL。
def parse(self, response):
print("request -> " + response.url)
job_list = response.css('div.job-list > ul > li')
for job in job_list:
item = WwwZhipinComItem()
job_primary = job.css('div.job-primary')
item['pid'] = job.css('div.info-primary > h3 > a::attr(data-jobid)').extract_first().strip()
item["positionName"] = job_primary.css('div.info-primary > h3 > a::text').extract_first().strip()
item["salary"] = job_primary.css('div.info-primary > h3 > a > span::text').extract_first().strip()
info_primary = job_primary.css('div.info-primary > p::text').extract()
item['city'] = info_primary[0].strip()
item['workYear'] = info_primary[1].strip()
item['education'] = info_primary[2].strip()
item['companyShortName'] = job_primary.css('div.info-company > div.company-text > h3 > a::text').extract_first().strip()
company_infos = job_primary.css('div.info-company > div.company-text > p::text').extract()
if len(company_infos) == 3: # 有一条招聘这里只有两项,所以加个判断
item['industryField'] = company_infos[0].strip()
item['financeStage'] = company_infos[1].strip()
item['companySize'] = company_infos[2].strip()
item['positionLables'] = job.css('li > div.job-tags > span::text').extract()
item['time'] = job.css('span.time::text').extract_first().strip()
item['updated_at'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
yield item
self.curPage += 1
time.sleep(5) # 停停停!听听听!都给我停下来听着!睡一会(~﹃~)~zZ
yield self.next_request() # 发送请求
def next_request(self):
return scrapy.http.FormRequest(self.positionUrl + ("&page=%d&ka=page-%d" %(self.curPage, self.curPage)), headers=self.headers,callback=self.parse)
运行脚本
scrapy crawl zhipin -o item.json这里会在项目目录下生成 item.json 的一个 json 文件
运行情况如下 http://cdn.jtup.cc/blog/video/scrapy_zhipin_demo.mp4
注意
Point 1 设置 UTF-8 编码
但是不巧,往往这是一个 Unicode 编码的文件,所以需要加个设置
在 settings.py中添加(PS:也可以在运行的时候带上这个参数)
FEED_EXPORT_ENCODING = 'utf-8'亲测以下方法是不能解决问题的

Point 2 慢一点
注意不要爬的太快,因为一页只会显示20页的招聘信息,所以理论上这个脚本只要执行20次即可,那么间隔时间尽量设置长一点,本人爬的时候设置的是5秒,但是后面稍微快了一点就403了,还好我已经把数据爬到了。
慢一点,才能快一点!
Point 3 修改为自定义的条件
可以修改 zhipin_spider.py 第18行 positionUrl 的链接,把 PHP 修改为 Java 或 Python,把城市编码(’c101020100’ == 上海)换成你需要查询的城市,即可爬取自定的岗位,这就很灵性了!
保存到数据库
一条json数据如下
{ "pid": "16115932",
"positionName": "PHP后台开发工程师",
"salary": "13K-20K",
"city": "上海",
"workYear": "1-3年",
"education": "本科",
"companyShortName": "蜻蜓FM",
"industryField": "互联网",
"financeStage": "D轮及以上",
"companySize": "100-499人",
"positionLables": [ "PHP"],
"time": "发布于昨天",
"updated_at": "2017-12-10 17:36:21" },使用软件将json文件导入到 MongoDB 中,以备后面的使用(数据清洗)
推荐阅读
版权声明:转载文章和图片均来自公开网络,版权归作者本人所有,推送文章除非无法确认,我们都会注明作者和来源。如果出处有误或侵犯到原作者权益,请与我们联系删除或授权事宜。






