从俄罗斯方块到星际2,全都用得上:DeepMind无监督分割大法,为游戏而生
方栗子 发自 凹非寺
量子位 报道 | 公众号 QbitAI

只给AI喂一张图片。
画里的各种物件,瞬间变成了独立的个体。可以移动起来,可以变形变色,毫无PS痕迹。
就连绿色的地板和黄色的墙,都不用安然站在那里不动:
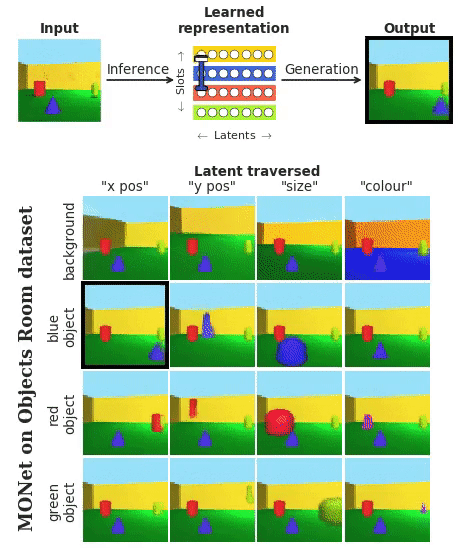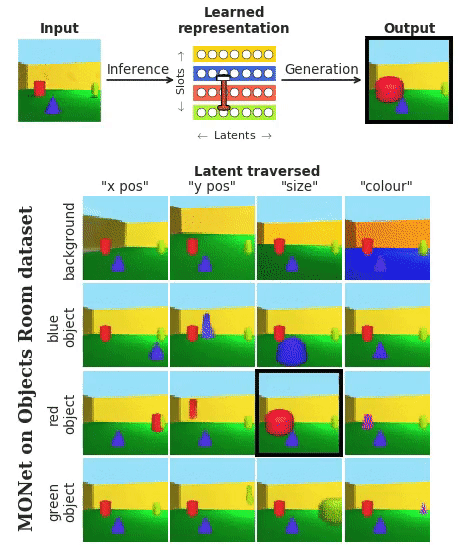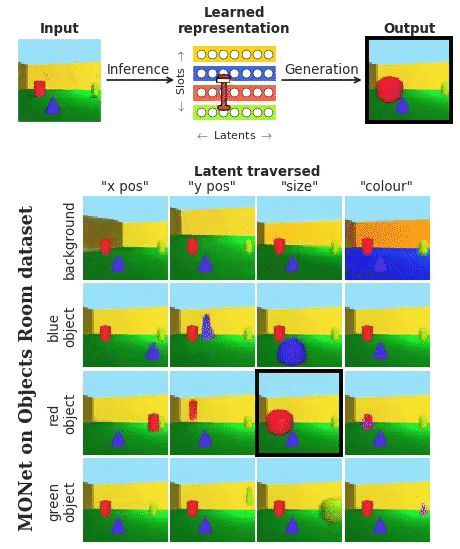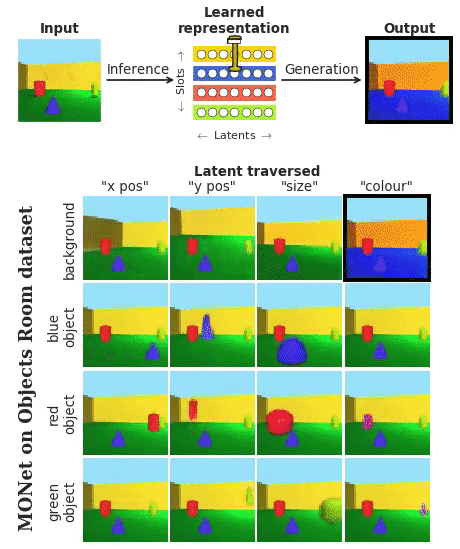
这段表演,来自DeepMind最新发布的神经网络MONet (简称“莫奈”) 。
它把每个物体,圆满地从背景里分离出来。这样的技能,完全是在无监督的学习过程中解锁的。
与莫奈一同发布的,还有一只叫做IODINE (简称“碘”) 的网络。
它也是无监督网络,也可以让画面里的每一个角色,都成为独立的自我,随意奔跑,野蛮生长。

不过,这两个网络用的分割方法,还是非常不同的:
莫奈与碘
莫奈 (MONet) ,是从背景开始,每次只分割出一个物体。
一步一步叠加上去。如下图,橘黄色→黄色→绿色→蓝色:

那么,来仔细认识一下莫奈的网络结构。
它是一只VAE (变分自编码器) 和一只注意力网络的结合:
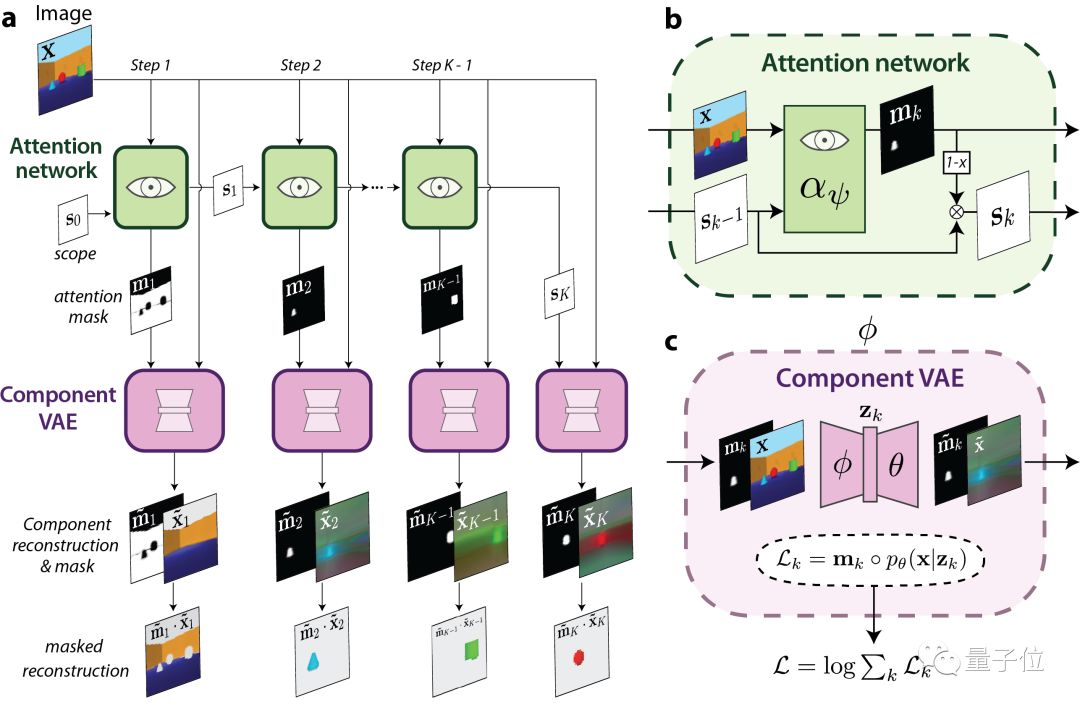
注意力网络是循环 (Recurrent) 出现的,它会不断地产生掩膜 (Mask) ,不断地对VAE做出调整。
每一步里,注意力网络都是不同的,是随着上一步分割出的场景而变化的。这样,每一步输出的重构图也是不同的。
最终,会集齐画面里的所有物体。这时候,每个存在都是独立的了。
你看,学打星际2的强化学习AI,要先了解敌人的行动规律。这时候,MONet就可以帮忙:

而与莫奈不同,碘 (IODINE) 不会一次只分一个物体。它会直接生成全场的分割图:

一开始是全然靠猜,然后会在一次一次迭代里面,不断细化 (Refine) 这个分割结果。
具体到网络结构上看,首先是这里的VAE和莫奈不一样。
莫奈的是普通VAE (下图左) ,碘的是多物体VAE (下图右) :
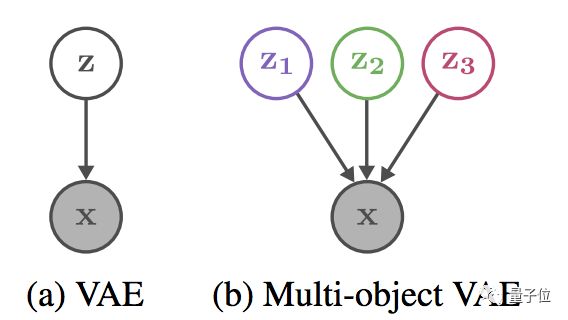
多物体VAE每一次工作,都会把画面里的所有物体,从背景里分割出来。
然后,怎样从一开始纯猜的各种后验参数λ,进化到最终的精确分割呢?
需要一个迭代推理过程:
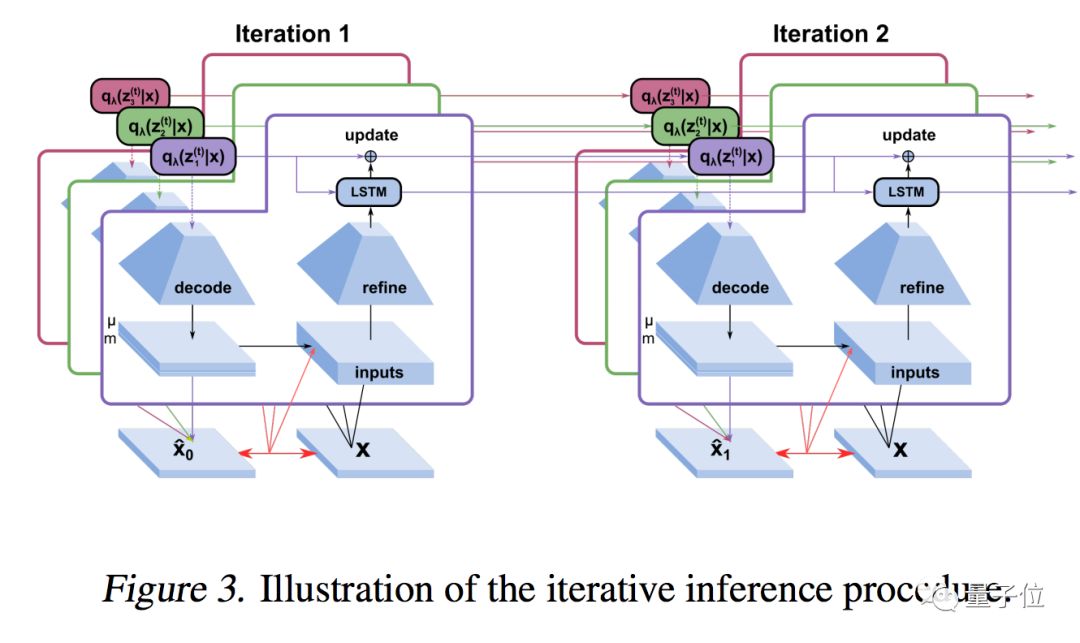
思路是来自Marino等人2018年发表的迭代摊销推理 (Iterative Amortized Inference) 方法,这里先不详细介绍了 (文底有传送门) 。
不过,团队说这样的方法,可以让模型解锁多重稳定性 (Multi-Stability) ,和人类的感知相近了。
你看,就算只给出“一坨“俄罗斯方块,AI也能把它分成几块独立的形状:

有了莫奈和碘的分解大法,AI的表征学习 (Representation Learning) 便可得心应手。
瑟瑟发抖
团队说,一开始想做这样的网络,就是要给强化学习AI打游戏用的。
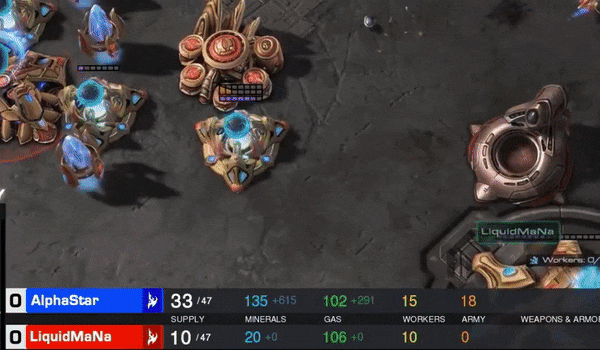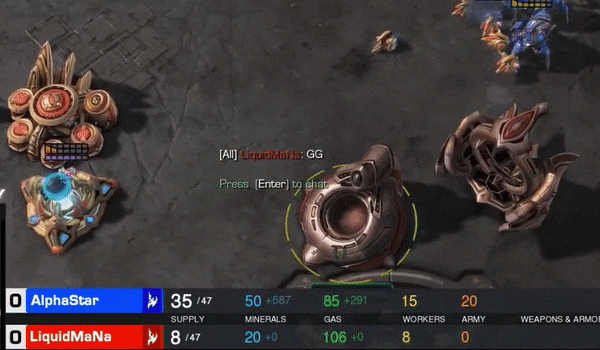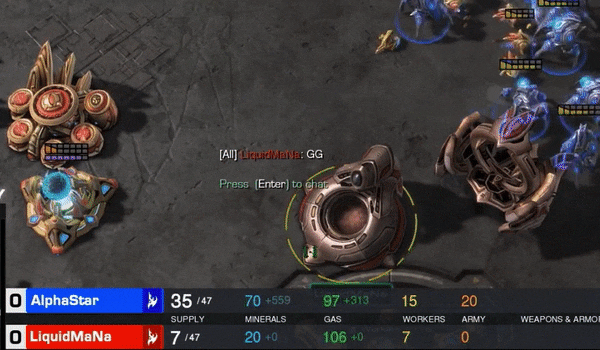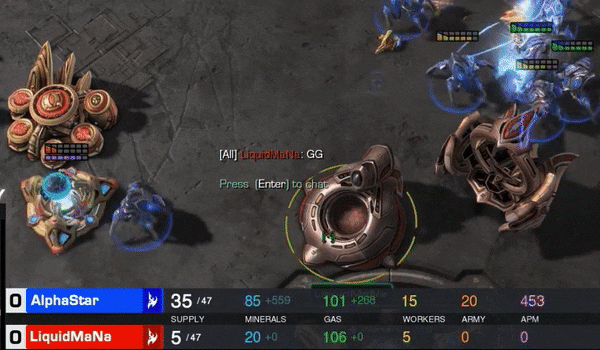
曾经在星际II的战场上,神族最强十人之一的LiquidMaNa,与DeepMind人工智能选手AlphaStar对战五局,双方都是神族。
MaNa全部GG。最短的一局,只有5分36秒。
而DeepMind每一日都在进化自家的算法,每一日都在开发新的算法。
人类下一个瑟瑟发抖的日子,可能很快就要来了。
MONet论文传送门:
https://arxiv.org/abs/1901.11390
IODINE论文传送门:
https://arxiv.org/abs/1903.00450
Iterative Amortized Inference论文传送门:
https://arxiv.org/abs/1807.09356
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
订阅AI内参,获取AI行业资讯

加入社群
量子位AI社群开始招募啦,量子位社群分:AI讨论群、AI+行业群、AI技术群;
欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“微信群”,获取入群方式。(技术群与AI+行业群需经过审核,审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !


