从背锅侠到砸锅侠,用实践案例教你正确的运维方法

作者介绍
田逸,某互联网上市公司IT运维负责人,开源软件的拥护者及推广者,负载均衡软件Keepalived官方中文文档贡献者。
系统出了故障,第一个挨板子的就是运维人员:“不管任何原因,先找运维,给他一口好锅。”
不得不说,运维好苦啊……
稳定运行时,似乎是多余的存在;一旦有问题,就要献身背锅。与其被动苦逼,不如主动一点,砸了锅,不做背锅侠!
怎么砸锅呢?先看几个例子,基本从亲身经历得来。
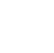

这个事情是当时有一个支付系统,前端负载均衡,中间Tomcat应用,后端Memcached加Oracle 11G rac两节点集群。遇上好的时机,公司的业务增长很快,但人手有限,跟不上业务的发展,只好尽可能的先上线,发现问题再修正。
某天,在西四环帮人排查宾馆wifi故障,楼里手机信号极差。还没查出什么原因,技术就打电话来质问:“你配的Oracle最大连接数,真有3000个么?怎么到300就卡死了?”。
于是我赶紧跑到室外,坐在地上用手机打开wifi热点,用笔记本连数据库,Load确实很高。没等查出原因,老板也来电话催促,说业务无法交易。我想,反正无法交易,不如把Tomcat停一下,看数据库负载是不是会降下来。在征得同意以后,就关掉killall -9 java,关闭Tomcat,片刻Oracle负载下降明显;再启动时,负载狂飙,最高达600多。
对Oracle的一些配置进行了检查,性能未能得到任何改善。于是就跟开发人员进行沟通,问他们近期是否做了项目更新?答复是肯定的,但无法确定是哪里的问题引起了性能上的问题,所以我建议在应用服务器上安装某性能监控探针。获得许可,很快就部署完毕,这样又等待了10来分钟,数据就出来了。
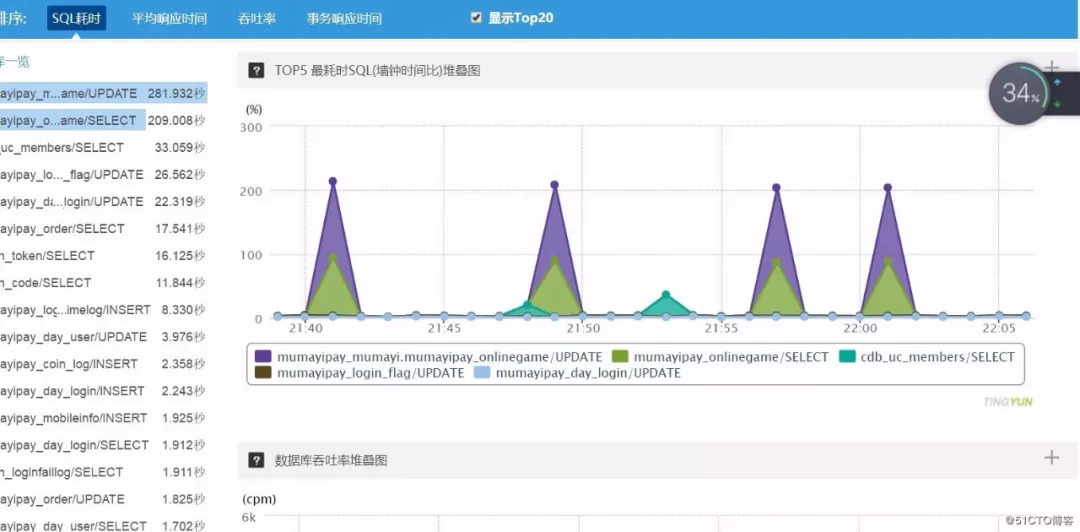
说明:本图不是事发时截取的,仅仅是为了方便读者了解。
然后一帮人赶紧紧急召集到一块,从性能探针的管理页面找出最耗资源的SQL语句进行代码还原(程序员来查这个代码是什么功能)。一番动作之后,被告知是后台管理操作——运营人员及代理商查询当日交易数据,由于产品设计上的缺陷,只要数十人同时进行此项操作,数据库就会直接挂起。
这个后台设计上的缺陷主要有以下几点:
管理后台登陆时,会查询所有代理商的数据,代理商会查询下级代理商的数据。然而,不管是哪一级的登陆,都会顺带查询其下最终用户的数据。如此叠加就将产生巨大的数据查询量。
数据的统计,不是字段值做数学运算,而是以select count()的方式进行。这比单独做一个表,把字段值做数学运算要耗资源。
不管有无需要,都抓取最终用户的交易详情。总用户数有300多万,运营人员一打开统计,就会去查询这些记录;代理商也是这样,只不过记录数会少一些,但多人操作,就会重复查询,给数据库造成巨大的压力。
负责技术的老总坦承,其实大部分管理最关心的是总额,很少去挨个查看详情。如果是需要查看,再按一定条件去执行这个操作。
弄清了问题,程序员马上去落实,更新代码以后,问题得以彻底的解决。
第二个事情发生在夏初的时候,我们上线了一个区块链媒体项目。预估到流量会比较可观,不仅采购的云主机配置高,而且还是多台,并且购买了负载均衡服务。
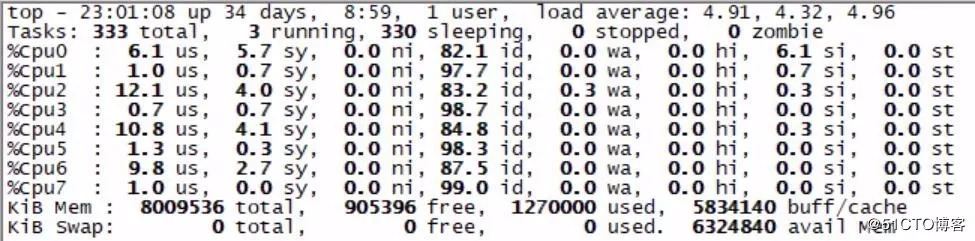
可万万没想到,项目一上线,还没做任何宣传,集群中所有服务器的负载都飚得老高,Load接近1000,还好没死机,还能远程SSH登陆。
这不,一有问题,一口锅就飞来了,非说是系统配置上的问题。好吧,先把锅背上,忍辱负重检查各种配置:
查php配置php-fpm.conf,各种参数都改一下。
查数据库状态,mysql > show full processlist; 好多连接呢,不懂业务,不知道这些SQL是啥用途,不管了,先保留下来吧。
查web访问日志,滚得飞快,似乎有马达在拉着转。看来问题在这里了。当时的心理活动是,这么频繁的请求,会不会是受到了×××?从日志与网络层面分析,又不像是这种情况。
问题得不到有效的缓解,只好跟相关人员进行沟通,要了app的下载地址,然后在手机上进行安装。安装好以后,打开app,底部有三个菜单项“快讯、行情、我的”。其中“快讯”菜单有四个栏目。
我试着往上滑,信息倒是一直能显示出来,而且看不到那种正在加载的转圈存在。结合web访问日志,我大致可以判断,应该是因为一次性把所有的信息都从数据库里进行抓取,不管这样是否合理(一般只看前1-2屏);另外,也可推断其它菜单或者栏目的内容,很可能也是一下子全抓取出来,管它需不需要展示。
有了这个发现,就立即联系开发人员,询问是不是数据抓取一抓到底,而且是一秒钟抓好多次(好多个板块一起抓)?答复:“确实如此,因为急着上线,没做太多考虑”。
这中间,我也曾对Nginx的并发数做限制,每秒限制5次;负载是降低了不少,但app却基本不能访问。结合访问日志及这次限制,可以肯定同一个app同一秒钟要抓二十几次,逻辑上肯定不合理。
至此,终于可以把这口锅扔给开发,让他们改进,问题得以最终解决。
第三个事情发生在昨天夜里,天气凉爽,想着能睡个好觉。到了晚上10点左右,有哥们突然呼叫,说某个项目又罢工了。这个项目是一个在线租赁服务,由Nginx + Tomcat构成,运行了两个Tomcat实例。一直以来,经常出现502故障,公司花了钱做推广,老出问题影响不好,所以之前曾经登上系统,做过如下处理:
修改Tomcat内存限定;
修改Tomcat启动账号为www(以前是root启动);
设置crontab计划任务,让Tomcat每天凌晨4点重启一次;
监控网站url。
在做了这些处理以后,稳定了好一阵。
听到项目又罢工,心里一惊。赶紧登上去,手工重启Tomcat,进程是存在了,但系统日志catalina.out却抛出异常,用浏览器访问,仍然是502错误。
执行w指令,发现还有别的人登陆到系统,就在微信群问是不是有人在干活。有人回答:“正在发新版”。
……
你发版提前打个招呼啊!出问题了,不吱声,让我在那里白费劲。
接下来,因为怀疑新发的包有问题,重复传了几次,问题依然存在。于是开发扔一句话:“可能Tomcat坏了”。这判断有点武断,Tomcat没人乱动,一般不会坏的。
我耐着性子,进入到项目的目录webapps,下边有三个目录,程序员说他上传的文件在ROOT下:

既然如此,我试着把除ROOT外的两个目录移走,打算这样万一有问题,再恢复回来也是可以的。
重启Tomcat,恢复正常,Tomcat日志也不抛出异常。
我仔细检查目录ROOT及yzuqin-m目录里边的配置,特别是应用连接数据库的字串,发现两个项目连接的数据库各不相同,就询问程序员哪个是正确的。得到答案之后,再分析日志,可知每次启动,关联的项目却不是ROOT目录下的。
看完这三个忍辱负重的砸锅案例,不知大家是否有些感觉?我思考的结果是,干运维的不仅要对系统、应用有较好的把控,而且还需要了解业务。
曾经有很长一段时间,我自己也是不喜欢关注业务,连服务器上运行的是什么都不知道(最多知道是网站而已,具体是什么性质的,一概不关心)。但其实如果花时间了解一下业务逻辑,再结合系统,从几个方面进行排查,处理故障的效率会高很多。而且很多情况下,把那口不属于自己的锅给砸碎,变成咱们去帮助其它技术人员解决问题,且不快哉?
作者:田逸(sery)
来源:http://blog.51cto.com/sery/2162642
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn

更多运维实战尽在2018 Gdevops全球敏捷运维峰会北京站!峰会议题覆盖AIOps演进、DevOps落地、数据库选型、SQL优化、技术管理等多方面实战,全方位助你满血前进!
↓↓↓ 点击链接了解更多详情 ↓↓↓