百度实体链接比赛后记:行为建模和实体链接(含代码分享)

作者丨苏剑林
单位丨追一科技
研究方向丨NLP,神经网络
个人主页丨kexue.fm
前几个月曾参加了百度的实体链接比赛 [1],这是 CCKS 2019 的评测任务之一,官方称之为“实体链指”,比赛于前几个星期完全结束。笔者最终的 F1 是 0.78 左右(冠军是 0.80),排在第 14 名,成绩并不突出(唯一的特色是模型很轻量级,GTX1060 都可以轻松跑起来),所以本文只是纯粹的记录过程,大牛们请一笑置之。
赛题介绍
所谓实体链接,主要指的是在已有一个知识库的情况下,预测输入 query 的某个实体对应知识库 id。也就是说,知识库里边记录了很多实体,对于同一个名字的实体可能会有多个解释,每个解释用一个唯一 id 编号,我们要做的就是预测 query 中的实体究竟对应哪一个解释(id)。这是基于知识图谱的问答系统的必要步骤。
数据格式
实体链接是为基于知识图谱的问答来准备的,所以首先我们要有一个知识库(kb_data),样例如下:
{"alias": ["胜利"], "subject_id": "10001", "subject": "胜利", "type": ["Thing"], "data": [{"predicate": "摘要", "object": "英雄联盟胜利系列皮肤是拳头公司制作的具有纪念意义限定系列皮肤之一。拳头公司制作的具有纪念意义限定系列皮肤还包括英雄联盟冠军系列皮肤、MSI季中冠军赛征服者系列以及英雄联盟全球总决赛冠军系列皮肤。每到赛季结束时,拳头公司都会制作胜利系列皮肤作为赛季奖励来认可那些在排位赛中勇猛拼搏达到黄金段位的玩家。"}, {"predicate": "制作方", "object": "Riot Games"}, {"predicate": "外文名", "object": "Victorious"}, {"predicate": "来源", "object": "英雄联盟"}, {"predicate": "中文名", "object": "胜利"}, {"predicate": "属性", "object": "虚拟"}, {"predicate": "义项描述", "object": "游戏《英雄联盟》胜利系列限定皮肤"}]}
{"alias": ["张三的歌"], "subject_id": "10002", "subject": "张三的歌", "type": ["CreativeWork"], "data": [{"predicate": "摘要", "object": "《张三的歌》这首经典老歌,词曲作者是张子石。最早收录于李寿全的专辑《8又二分之一》当中。李寿全作为台湾民谣时代的推动人,在80年代中后期有着举足轻重的地位,而这首《张三的歌》出现在当时的背景之下,带来了无可比拟的社会效应,也为那个年代留下了无法抹去的回忆。随着时间的推移,陈翔、齐秦、吴宗宪、蔡琴、青鸟飞鱼等歌手都曾翻唱过。"}, {"predicate": "歌曲原唱", "object": "李寿全"}, {"predicate": "谱曲", "object": "张子石"}, {"predicate": "歌曲时长", "object": "3分58秒"}, {"predicate": "歌曲语言", "object": "普通话"}, {"predicate": "音乐风格", "object": "民谣"}, {"predicate": "唱片公司", "object": "飞碟唱片"}, {"predicate": "翻唱", "object": "齐秦、苏芮、南方二重唱等"}, {"predicate": "填词", "object": "张子石"}, {"predicate": "发行时间", "object": "1986-08-01"}, {"predicate": "中文名称", "object": "张三的歌"}, {"predicate": "所属专辑", "object": "8又二分之一"}, {"predicate": "义项描述", "object": "李寿全演唱歌曲"}, {"predicate": "标签", "object": "单曲"}, {"predicate": "标签", "object": "音乐作品"}]}
...
...
{"alias": ["胜利"], "subject_id": "10001", "subject": "胜利", "type": ["Thing"], "data": [{"predicate": "摘要", "object": "英雄联盟胜利系列皮肤是拳头公司制作的具有纪念意义限定系列皮肤之一。拳头公司制作的具有纪念意义限定系列皮肤还包括英雄联盟冠军系列皮肤、MSI季中冠军赛征服者系列以及英雄联盟全球总决赛冠军系列皮肤。每到赛季结束时,拳头公司都会制作胜利系列皮肤作为赛季奖励来认可那些在排位赛中勇猛拼搏达到黄金段位的玩家。"}, {"predicate": "制作方", "object": "Riot Games"}, {"predicate": "外文名", "object": "Victorious"}, {"predicate": "来源", "object": "英雄联盟"}, {"predicate": "中文名", "object": "胜利"}, {"predicate": "属性", "object": "虚拟"}, {"predicate": "义项描述", "object": "游戏《英雄联盟》胜利系列限定皮肤"}]}
{"alias": ["胜利"], "subject_id": "19044", "type": ["Vocabulary"], "data": [{"predicate": "摘要", "object": "胜利,汉语词汇。拼音:shèng lì胜利,指达到预期的目的。与“失败”相对。有“成功”的意思,古代打仗成功称胜利,比赛夺冠胜利称“成功”。其他寓意也很广泛(如:一件事坚持到了最后也称胜利)。胜利在英语中都为victory [Victory ]"}, {"predicate": "外文名", "object": "win"}, {"predicate": "反义词", "object": "失败"}, {"predicate": "拼音", "object": "shèng lì"}, {"predicate": "中文名", "object": "胜利"}, {"predicate": "释义", "object": "获得成功或达到目的"}, {"predicate": "义项描述", "object": "汉语词语"}, {"predicate": "标签", "object": "文化"}], "subject": "胜利"}
{"alias": ["胜利"], "subject_id": "37234", "type": ["Thing"], "data": [{"predicate": "摘要", "object": "《胜利》是由[英] 约瑟夫·康拉德所著一部讽喻小说,新华出版社出版发行。"}, {"predicate": "作者", "object": "[英] 约瑟夫·康拉德"}, {"predicate": "ISBN", "object": "9787516620762"}, {"predicate": "书名", "object": "胜利"}, {"predicate": "出版社", "object": "新华出版社"}, {"predicate": "义项描述", "object": "[英] 约瑟夫·康拉德所著小说"}], "subject": "胜利"}
...
...
{"text_id": "1", "text": "南京南站:坐高铁在南京南站下。南京南站", "mention_data": [{"kb_id": "311223", "mention": "南京南站", "offset": "0"}, {"kb_id": "341096", "mention": "高铁", "offset": "6"}, {"kb_id": "311223", "mention": "南京南站", "offset": "9"}, {"kb_id": "311223", "mention": "南京南站", "offset": "15"}]}
{"text_id": "2", "text": "比特币吸粉无数,但央行的心另有所属|界面新闻 · jmedia", "mention_data": [{"kb_id": "278410", "mention": "比特币", "offset": "0"}, {"kb_id": "199602", "mention": "央行", "offset": "9"}, {"kb_id": "215472", "mention": "界面新闻", "offset": "18"}]}
{"text_id": "3", "text": "解读《万历十五年》", "mention_data": [{"kb_id": "131751", "mention": "万历十五年", "offset": "3"}]}
{"text_id": "4", "text": "《时间的针脚第一季》迅雷下载_完整版在线观看_美剧...", "mention_data": [{"kb_id": "NIL", "mention": "时间的针脚第一季", "offset": "1"}, {"kb_id": "57067", "mention": "迅雷", "offset": "10"}, {"kb_id": "394479", "mention": "美剧", "offset": "23"}]}
...
...

模型细节
这里逐一介绍笔者的处理和建模过程。在笔者的实现里,实体标注和实体链接两个部分是联合训练的,并且共享了部分模块。模型的整体思想(包括训练方案)都跟基于DGCNN和概率图的轻量级信息抽取模型一文类似,读者也可以对比着来阅读。
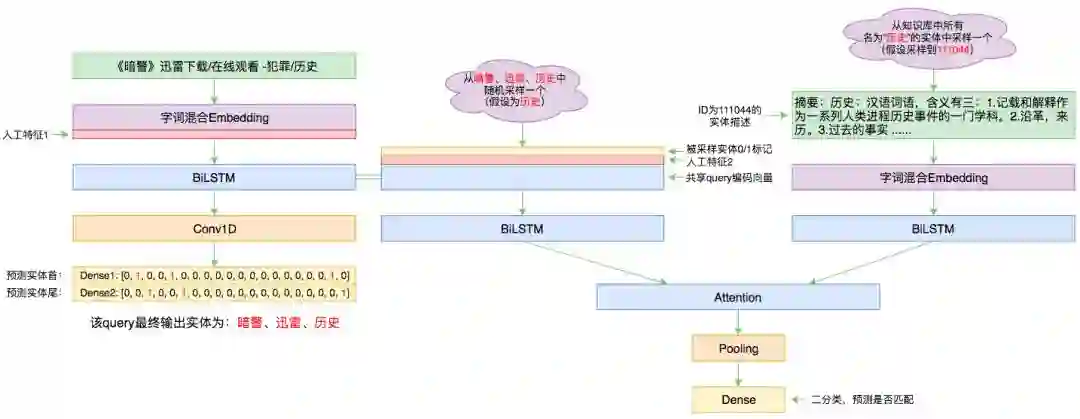
▲ 本文的实体链接模型总图
实体识别
首先是实体识别部分,分“基本模型”和“人工特征”两部分介绍。
基本模型
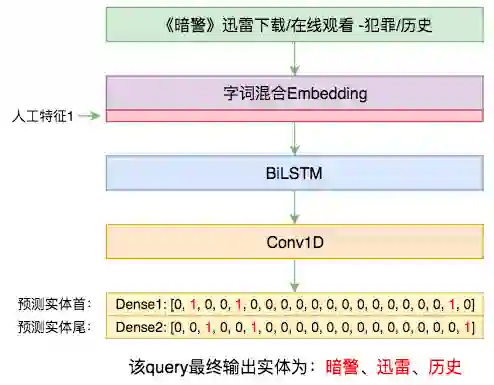
▲ 本文的实体识别模型
“基本模型”是指神经网络部分,通过传入的字词混合Embedding和人工特征来做字标注,标注结构依然是笔者之前构思的“半指针半标注结构”(参考这里和这里)。
不同于以往用全 CNN 的习惯,本次模型主要还是用到了双向 LSTM,因为这一次不打算将模型做得太深,而模型非常浅(只有一两层)的时候,双向 LSTM 往往比 CNN 和 Attention 都要好。
人工特征
由于已经给出了知识库,并且识别出来的实体名都是在知识库里边出现过的(知识库的 alias 字段,如果没出现过可以视为标注错误),所以实体识别的一个 baseline 是直接把知识库里边所有的 alias 拿出来,组成一个词库,然后根据这个词库做一个最大匹配模型。这样做实体的召回率为 92% 左右,但是精度不高,只有 30% 左右,总的 F1 约为 40%。
接着,我们可以观察到,在训练数据中,对实体的标注是相当“任性”的,总的来说就是主观因素相当大,可以说这根本就不是什么基于语义的实体识别,而更多的是“标注人员标注轨迹建模”,也就是说我们主要是在努力标注人员的标注习惯,而不是建立在语义理解基础上的实体识别。
比如,前面示意图中的 query“《暗警》迅雷下载/在线观看 -犯罪/历史”只标注出了“暗警”、“迅雷”、“历史”三个实体,事实上“下载”、“在线”、“观看”、“犯罪”都是知识库里边的实体,而且存在能够适配这个 query 的实体 id。
那为什么不标?只能说标注人员不喜欢标/不想标/没力气标了。还有一种情况是:比如“高清视频”,在有些 query 中“高清视频”是作为一整个实体被标注出来的,而有些 query 中则是作为“高清”、“视频”两个实体标注的(因为“高清视频”、“高清”、“视频”都是知识库里边的实体)。
所以,有很多实体识别结果是没有什么道理可言的,就是标注人员的习惯而已。而为了更好地拟合标注人员的标注习惯,我们可以通过训练集做一些统计,统计一下知识库的哪些实体被标注得多,哪些实体标注得少,这样就可以对知识库的实体做一个基本的过滤(过滤细节参考后面的开源代码),用过滤后的实体集做词典来构建最大匹配模型,最终的实体召回率在 91.8% 左右,但是精度可以达到 60%,F1 可以达到 70%+。
也就是说,只要通过简单的统计和最大匹配,就可以将实体识别这一步的 F1 做到 70%+,我们把这个最大匹配的结果转为 0/1 特征传入到基本模型中,相当于用基本模型在最大匹配的结果上作进一步的过滤,最终实体识别的 F1 约为 81%(具体值不记得了)。
实体链接
现在是实体链接这一步,依然分“基本模型”和“人工特征”两部分介绍,依然是一个相当朴素的基准模型基础上结合人工特征来提升。
基本模型
在实体链接的模型中,我们要做的事情是“判断 query 中的某个实体跟知识库中某个同名实体是否匹配”,为此,我们就需要随机采样:从 query 的所有识别出的实体中随机采样一个,然后从知识库里边所有同名实体中采样一个。
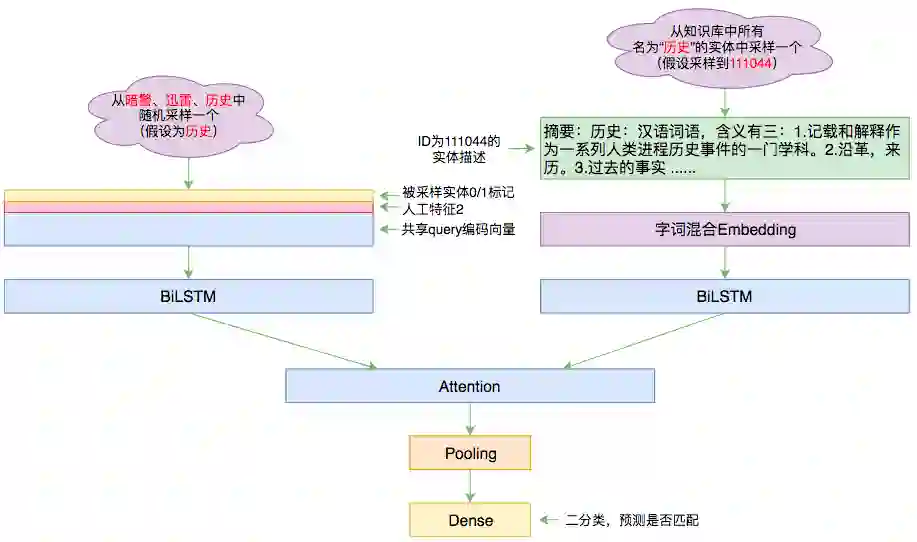
▲ 本文的实体链接模型
对于 query,我们先沿用实体识别这一步对 query 文本的编码序列,然后将采样到的实体用一个 0/1 序列来标记,拼接到这个编码序列中,同时拼接到编码序列的还有一些人工特征,拼接完成后再做一个 BiLSTM,得到最终的编码序列 Q;在同名实体这一边,把同名实体的描述拿出来后,经过 Embedding 层(跟 query 的 Embedding 共享)后再接一个 BiLSTM,就完成对实体描述的编码 D 了。
有了两者的编码序列后,就可以做 Attention 了,如一文读懂「Attention is All You Need」| 附代码实现所说,Attention 三要素就是 query、key、value,这里我们先用 Q 做 query、D 做 key 和 value 做一次 Attention,然后再用 D 做 query、Q 做 key 和 value 做一次 Attention,两次 Attention 分别用 MaxPooling 得到固定长度的向量,然后拼接起来,接一个全连接做 2 分类。
人工特征
实体链接中用到的人工特征是以 query 主体的,最终生成的是跟 query 一样长度的向量序列,拼接到 query 的编码结果中。在本文的模型中,用到的人工特征有三个:
1. query 的每个字是否在实体描述中出现过(对应一个 0/1 序列);
2. query 和实体描述都分词,然后判断 query 每个词是否在实体描述中出现过(对应一个 0/1 序列,每个词对应的标记要重复词的长度那么多次,以保证得到通常长度的序列);
3. query 中的每个词/片段,是否为该实体的某个 object(对应一个 0/1 序列,object 的含义参考文章开头给出的知识库样例)。
印象中这三个特征对实体链接的准确率提升还是比较明显的(但具体幅度忘记了)。
此外,在预测的时候,还用到了一个统计结果。前面已经强调过,实体识别这一步其实更像是“标注行为建模”而不是“语义理解”,而且带有相当多的随机性,事实上实体链接这一步也是如此。
我们可以统计发现,对于某些实体,它们在知识库中可能会有很多同名实体,但是被标注出来的可能只有其中几个,剩下的说不定标注人员看都没看,也就是说,本来可能是 50 选 1 的问题,在标注人员的标注习惯里边可能变成了 5 选 1。
于是我们可以对训练集所有出现过的实体及其对应的实体 id 进行统计,这样一来对于每个实体名我们都可以得到一个分布,这个分布描述的是当前名字的实体被标注的 id 的分布情况,如果分布相当集中在其中几个 id 中,那么我们干脆就只保留这几个 id 好了,剩下的同名实体全部去掉好了。事后发现,这样既提高了预测速度,也提高了准确性。
代码分享
小结
本文分享了一次实体链接比赛的参赛过程,从模型上看整体模型比较朴素,主要效果提升在于所提出的人工特征。这些人工特征主要是人工观察数据特点得出的统计特征,属于比赛的一些 trick,事实上这些 trick 有投机取巧之嫌,未必能在真正的生产环境中用到,但却紧密结合了赛题数据特点。
还是那句话,笔者更倾向于认为这更像是一次标注行为建模,而不是真正的语义理解竞赛,尤其是在实体识别这一步,主观性太强了,是整个比赛的主要瓶颈之一。为了提升最终分数,我们必须要花相当大的力气做好实体识别这一步,但是做好实体识别这一步,只能说你更好地拟合了标注人员的行为,而不是真正最好了语义上的实体识别,对比赛的初衷——实体链接——更没有太大帮助。
而且真的是生产环境的话,对实体识别往往是有标准方法的,所以通常只需要做好实体链接。这是笔者所认为的这次比赛的失策之处。
当然,标注数据来之不易,还是感谢百度大佬举办比赛以及提供标注数据。
相关链接

点击以下标题查看作者其他文章:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看作者博客


